 夜雨聆风
夜雨聆风





拆解Claude Code源码|02:模型每天失忆,它靠什么"记住"世界?
这是「拆解 Claude Code 源码」系列的第 2 篇。上一篇我们拆解了 Agent 的核心循环——一个 while(true) 就是 Agent 的心脏。这一篇,我们来看这颗心脏每跳一下,”血液”从哪来。
一个事实
上一篇说了,Agent 的本质是 while(true) 循环——每轮调用 API,模型看到对话历史后做出决策。
但这里有一个很多人没意识到的事实:
大模型没有记忆。
不是”记忆力差”,是完全没有。每次 API 调用,模型都是从零开始的。它能”记住”你之前说了什么,完全是因为——你把之前的对话历史一字不漏地重新发了一遍。
想象你有一个每天早上都会彻底失忆的同事。他能”记得”昨天的工作进展,是因为你每天早上把前几天的工作日志打印出来放他桌上。你放了什么,他就知道什么。你没放的,他完全不知道。
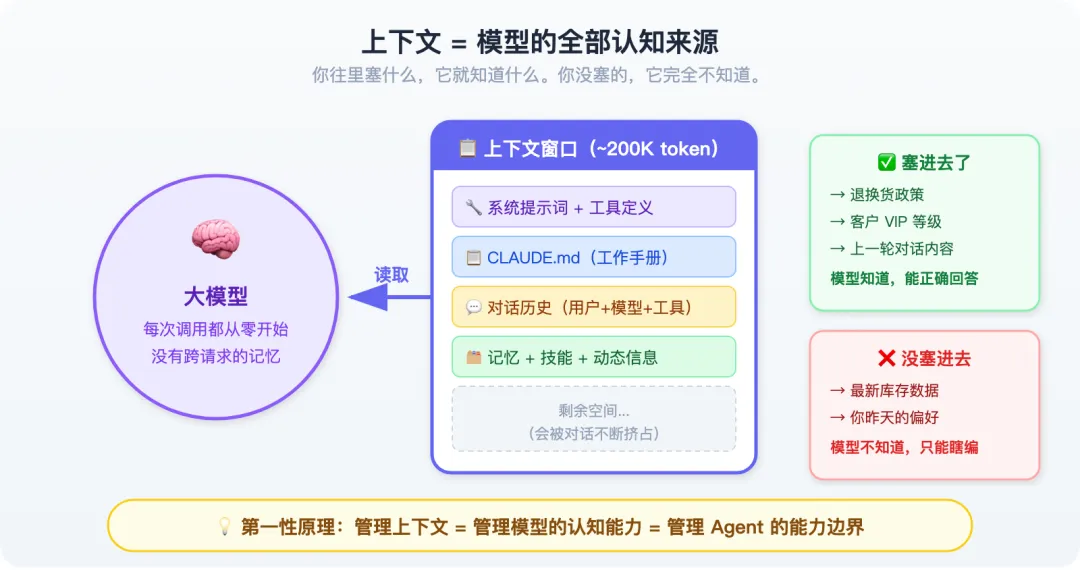
这就是上下文——模型的全部认知来源。
你往里面塞了退换货政策,它就知道退换货怎么处理。你没塞,它就只能瞎编。你塞了客户的 VIP 等级,它才会区别对待。你没塞,所有客户它都一视同仁。
管理上下文,就是管理模型的认知能力。
那系统怎么让它”记住”?
既然模型没有记忆,那 Claude Code 是怎么让它看起来”记得”之前发生的一切的?
答案其实很简单:每次对话时,系统把所有历史记录打包成一个大包裹,整个发给模型。
我们用一个具体的场景来走一遍这个过程。
假设你对 Agent 说:”帮我写一篇竞品分析报告。”
第 1 轮:
系统把你的请求打包成一个”包裹”发给 API。这个包裹里有:
-
系统指令(”你是一个 AI 助手,你能读文件、搜索……”) -
工具定义(你能用哪些工具) -
你的消息:”帮我写一篇竞品分析报告”
模型看到这个包裹,回复:”好的,我先帮你搜索一下主要竞品的信息。”然后调用了搜索工具。
第 2 轮:
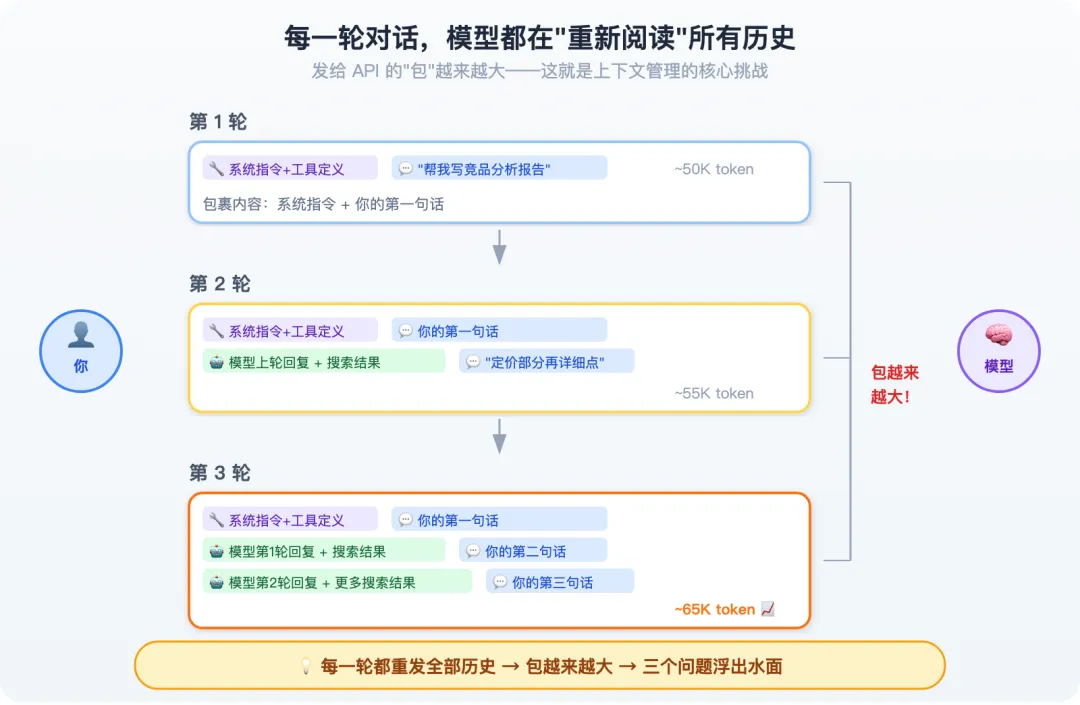
系统把所有历史重新打包——注意,不是只发新的部分,而是全部重发:
-
系统指令(和第 1 轮完全一样) -
工具定义(和第 1 轮完全一样) -
你的第一句话:”帮我写一篇竞品分析报告” -
模型上一轮的回复 -
搜索工具返回的结果 -
你的新消息:”定价部分再详细点”
模型收到这个更大的包裹,从头读一遍,然后继续工作。
第 3 轮:
包裹更大了——前面所有内容 + 第 2 轮的回复和工具结果 + 你的新消息。模型又从头读一遍。
发现规律了吗?
每一轮对话,模型都在”重新阅读”所有历史。包裹只会越来越大,永远不会变小。
就像那个失忆的同事——他每天早上桌上的工作日志会越来越厚。第一天 5 页,第二天 10 页,第三天 20 页……但他每天都得从第 1 页开始读,因为他不记得昨天读过什么。
等一下——所谓的”记忆”,到底存在哪里?
看到这里你可能会想:好,我知道模型每次都要重读所有历史。但”记忆”到底是怎么存下来的?怎么增加、怎么删除、怎么注入?
答案可能比你想象的简单得多:
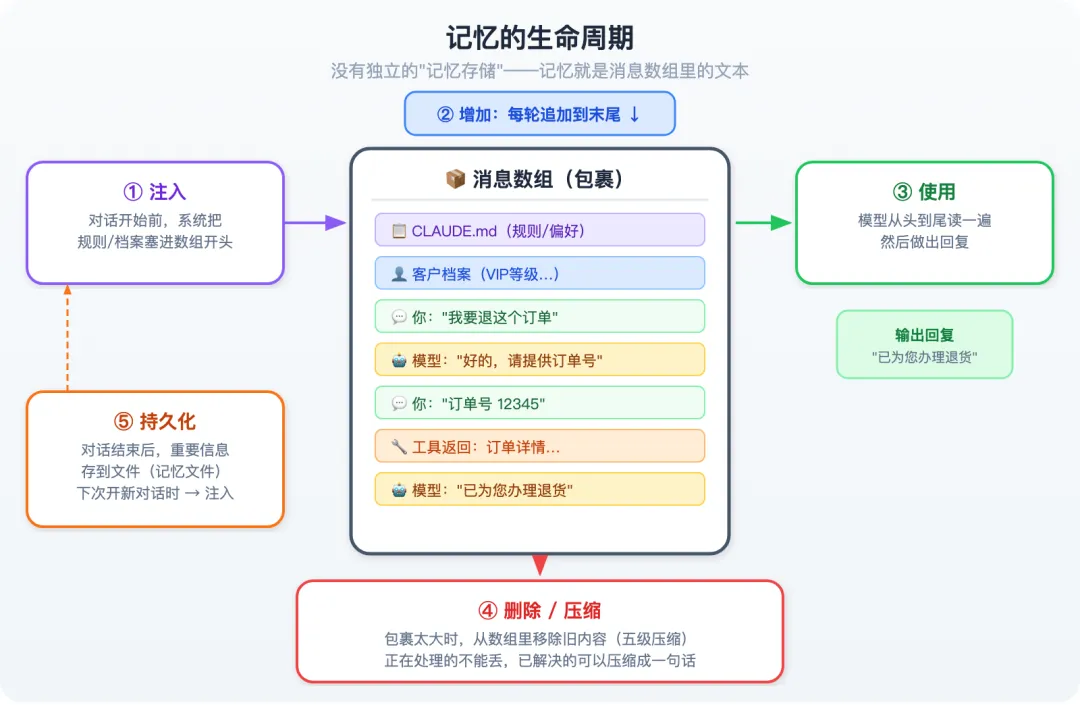
没有独立的”记忆存储”。所谓的记忆,就是消息数组里的一段段文本。
-
“记住”了 = 那段文本在数组里 -
“忘记”了 = 那段文本从数组里被删掉了 -
“注入”记忆 = 系统往数组里插入了新文本 -
“使用”记忆 = 模型从头到尾把数组读了一遍
就这么简单。我们用一个具体场景走一遍记忆的完整生命周期:
场景:客户来咨询退货。
① 注入(对话还没开始)
记忆存在哪里?就存在发给 API 的那个请求里。具体来说,这个请求有一个 messages 字段——它是一个数组(你可以理解为一个有序列表)。对话还没开始,系统就已经往这个数组里预填了内容。
比如电商客服 Agent:系统会在数组的最前面插入两段文本——退货政策(来自配置文件)和客户的 VIP 等级(来自客户数据库)。模型收到请求后,读到这两段文本,就”知道”退货规则和客户身份了。
就像那个失忆同事每天来上班,桌上已经放好了公司手册和客户档案——不是他记得,是有人提前帮他放好的。
这就是”注入”的本质:在调用 API 之前,往 messages 数组里插入预设文本。 你想让模型”先天知道”什么,就往里面塞什么。
② 增加(对话进行中)
客户说”我要退货”→ 系统把这句话作为一条新消息,追加到 messages 数组末尾。模型回复”请提供订单号”→ 这条回复也被追加到数组末尾。客户给了订单号 → 追加。模型调用工具查了订单详情 → 工具返回的结果也被追加。
每一轮交互,数组自动变长。系统做的事情非常机械:把每一轮的输入和输出,原封不动地 append 到数组末尾。 不需要你做任何事——这就是”增加记忆”。
③ 使用(每一轮都在发生)
下一轮 API 调用时,系统把整个 messages 数组打包发给模型。模型从数组的第一条消息开始,逐条往下读:
先读到退货政策(知道规则)→ 再读到客户档案(知道身份)→ 再读到对话历史(知道客户要退什么)→ 再读到订单详情(知道这单具体情况)→ 读完所有内容后,做出判断:”符合退货条件,为您办理退货。”
这就是”使用记忆”——把整个数组从头到尾读一遍,然后基于所有信息做决策。 模型不会”跳着读”,也不会”只看最新的”,它每次都完整地读一遍全部内容。
④ 删除 / 压缩(对话变长后)
聊了 30 轮,数组里已经有上百条消息了。系统发现数组总长度快超过模型的窗口上限——再塞就塞不下了。于是系统开始清理:把数组里不重要的旧消息直接移除(比如”您好””请稍等”之类的客套话),把已解决的问题压缩成一句话摘要替换原文。
本质就是对数组做”删除”和”替换”操作——把长数组变短,腾出空间给新内容。
⑤ 持久化(跨会话记忆)
这次对话结束了。下次客户再来,系统会创建一个全新的 messages 数组——模型什么都不记得。
但如果系统在对话结束时,把关键信息(比如”该客户上次退过货,退货原因是尺码不合适”)写入到外部存储(文件或数据库),下次新对话开始时,再把这段信息从存储中读出来,注入到新数组的开头——模型就”记得”上次发生了什么。
这不是真的记忆,是”上次临走前写了张纸条存到文件里,下次来的时候从文件里读出来放到桌上”。
理解了这五步,你就理解了 Agent 记忆的全部:没有魔法,就是对一个文本数组的增删改查。
但问题也跟着来了——
这个”包裹越来越大”的事实,引出了三个绕不开的问题。
三个绕不开的问题
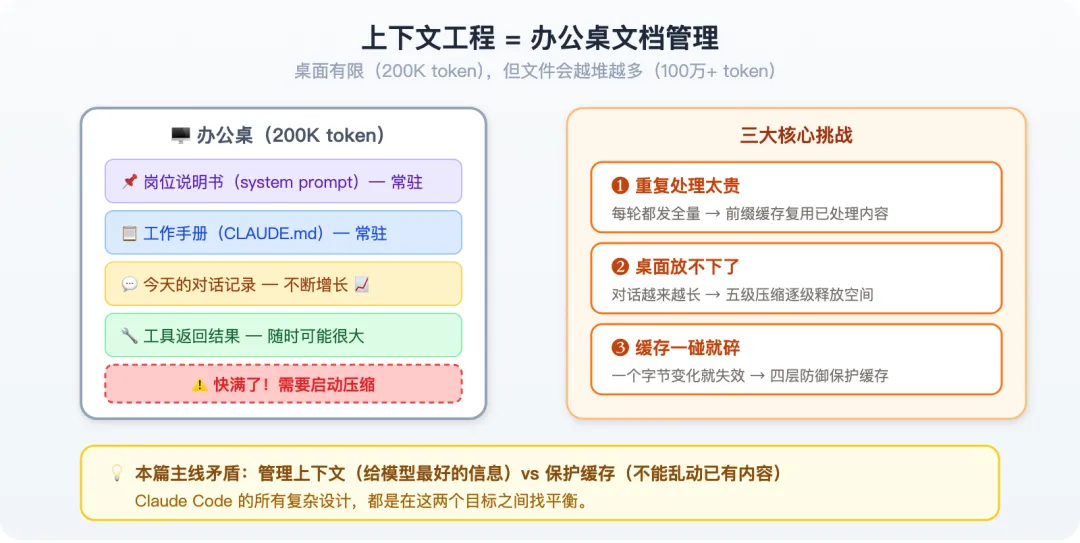
问题一:每次都重读全部内容,太贵了
包裹里光系统指令和工具定义就有 5 万字。每一轮对话都要从头处理这 5 万字,就像那个失忆同事每天早上都要重读公司制度手册——明明内容没变,但他不记得自己读过。
如果不解决这个问题,你的 API 账单会非常可怕。
问题二:包裹太大,塞不下了
模型的上下文窗口大约 200K token(大概 15 万字)。听起来很大?但一次真实的工作会话,产生的原始文本量轻松超过一百万字——对话历史、工具返回结果、读取的文件内容……
聊着聊着,包裹就塞不进窗口了。如果你让 Agent 帮你做一个大项目——比如写一份 50 页的报告——聊到后面它就”忘了”开头说的话。不是它变笨了,是前面的内容被挤出窗口了。
问题三:省钱的方法极其脆弱
问题一的解决方案是缓存——服务端记住之前处理过的内容,下次遇到相同内容就跳过。但这个缓存有一个残酷的规则:
前缀必须字节级完全一致才能命中缓存。
不是”差不多就行”,是任何一个字节变化,从该位置往后的所有缓存全部失效。
你每天上班桌上都有 100 页参考资料。如果你记住”前 95 页昨天就读过了、内容没变”,今天只需要读新加的 5 页——省了 95% 的工作量。但如果有人在第 10 页偷偷改了一个标点,你就不得不从第 10 页开始全部重读。
这三个问题互相纠缠——解决”塞不下”需要压缩,但压缩会改变内容破坏缓存;保护缓存又限制了你管理上下文的自由度。
这就是上下文工程的核心矛盾:管理上下文 vs 保护缓存,贯穿始终。
我们来看 Claude Code 怎么一层一层解决这些问题。
问题一怎么解:用缓存避免重复处理
解决思路很直观:既然每轮发的包裹前面大部分内容都没变,那就让服务端”记住”之前处理过的部分,后续只处理新增的内容。
这就是前缀缓存。
但要让缓存生效,包裹的结构必须精心设计——变化少的放前面,变化多的放后面。
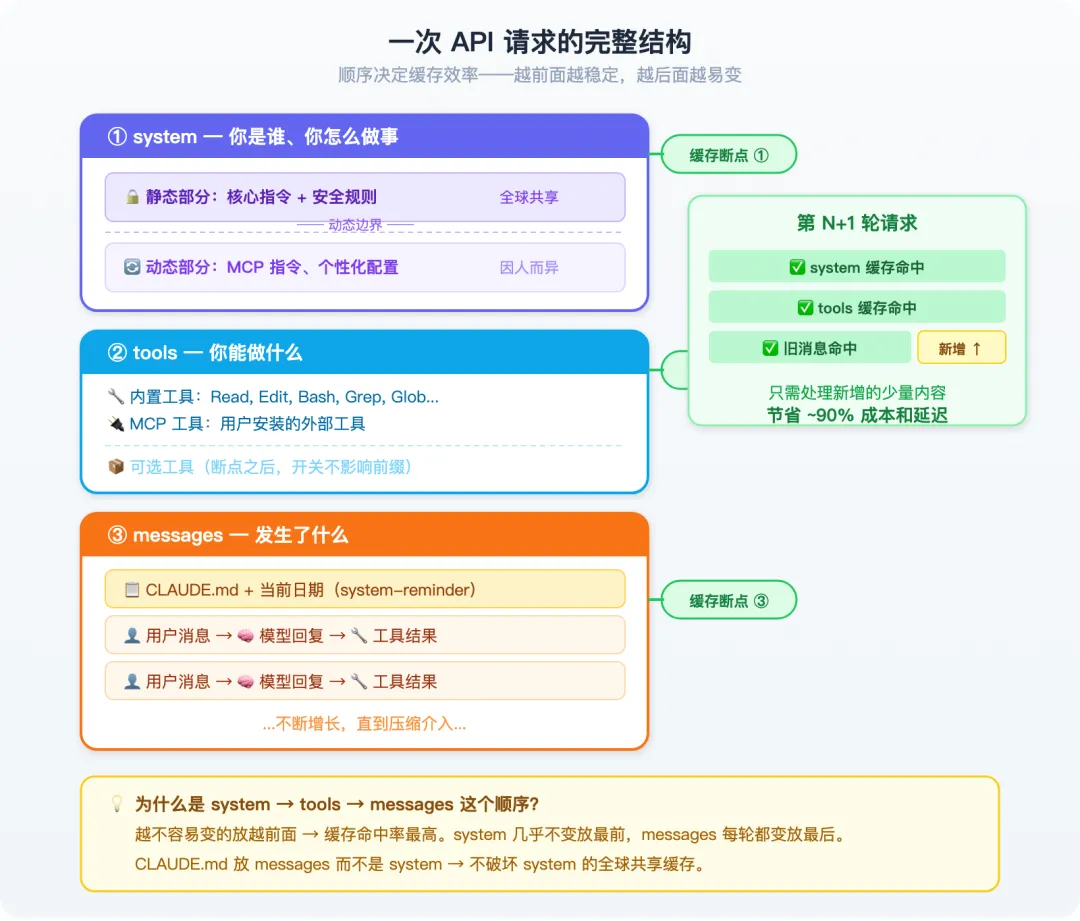
Claude Code 把发给 API 的包裹分成三部分:
- “你是谁”(系统指令)
——几乎不变,放最前面,缓存命中率最高 - “你能做什么”(工具列表)
——偶尔变,放中间 - “发生了什么”(对话记录)
——每轮都变,放最后
这个顺序不是随意的,完全是为了最大化缓存命中率。
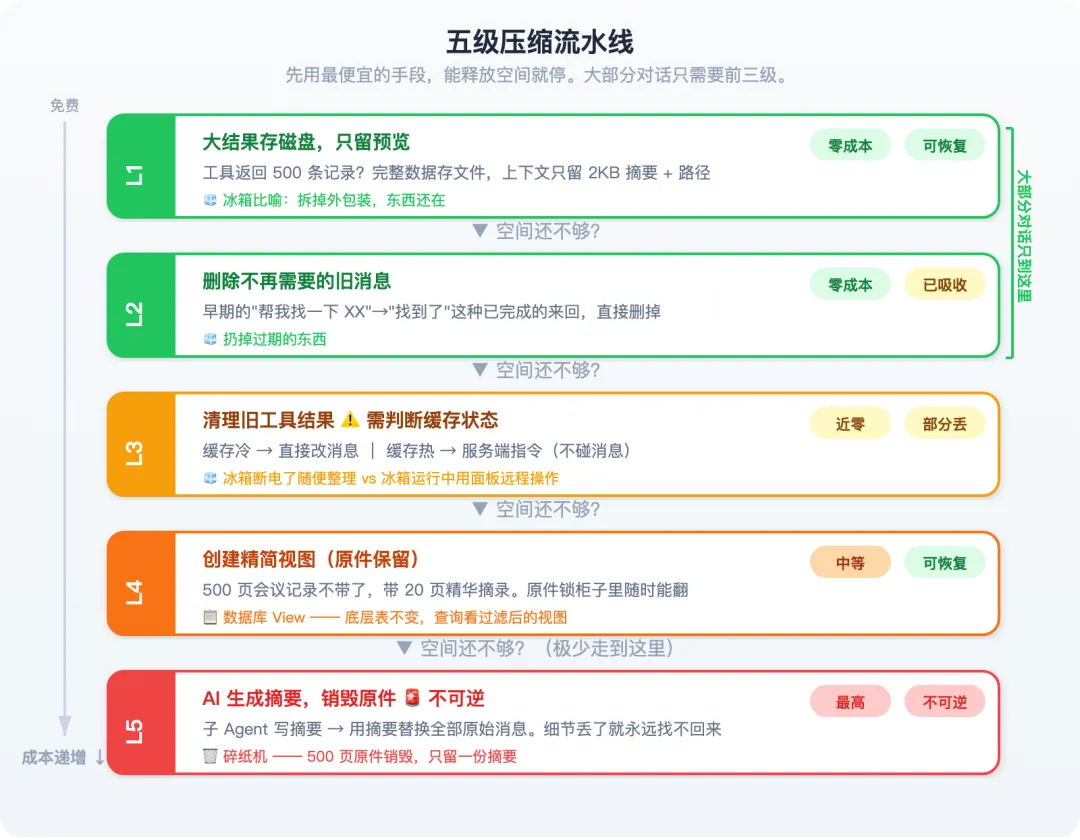
为了保护缓存不被意外打碎,Claude Code 还用了多层防御:
关键设计原则:先用免费的、无损的手段,能释放多少空间算多少。大部分对话只需要前三级就够了,走到 Level 5 的极少。而且 Level 3 还要小心——修改消息内容可能破坏缓存,所以系统会先判断缓存状态再决定怎么清理。
问题三怎么解:精心设计的结构 + 多层防御
前面已经穿插讲了——把不变的内容放前面、变化的放后面,用分割、锁存、排列、检测四层策略保护缓存。
这里再补充一个有意思的设计:
Agent 的”员工手册”——CLAUDE.md。
Agent 除了对话历史,还需要一类更基础的知识:规则、偏好和工作方式。比如”写代码用 Python”、”提交信息用中文”、”这个项目用 pnpm 不用 npm”。
新员工入职第一天要读公司规章制度。Agent 每次”上班”(收到新消息)都会重新读一遍这本手册。
有意思的是,CLAUDE.md 放在对话消息里,而不是系统指令里。为什么?因为每个人、每个项目的 CLAUDE.md 不同。如果放系统指令里,每个项目的缓存都不一样,全局共享的缓存就废了。放在消息里,系统指令保持统一,缓存跨用户共享。
又是一个”功能需求”给”缓存效率”让路的设计决策。
如果你在做 Agent 产品,这些跟你有什么关系?
聊了这么多 Claude Code 的设计,你可能会想:我又不写底层代码,知道这些有什么用?
其实用处很大。因为上面所有的技术复杂度,归根结底都在回答一个产品问题:
这个 Agent 应该”知道”什么?
以电商客服 Agent 为例,所有信息归根结底只有四类:
- 常驻知识
(退换货政策、话术规范)→ 放系统指令,人人一样,尽量少改——改一次缓存就废 - 因人而异
(VIP 等级、历史客诉)→ 放对话消息,别放系统指令——否则全局缓存失效 - 用到再查
(订单详情、物流状态)→ 不放上下文,通过工具按需调——数据量大、实时变化,塞进去包裹会爆 - 聊久可压缩
(早期已解决的问题)→ 按优先级清理——正在处理的客诉一个字不能丢,已解决的压缩成一句话就够
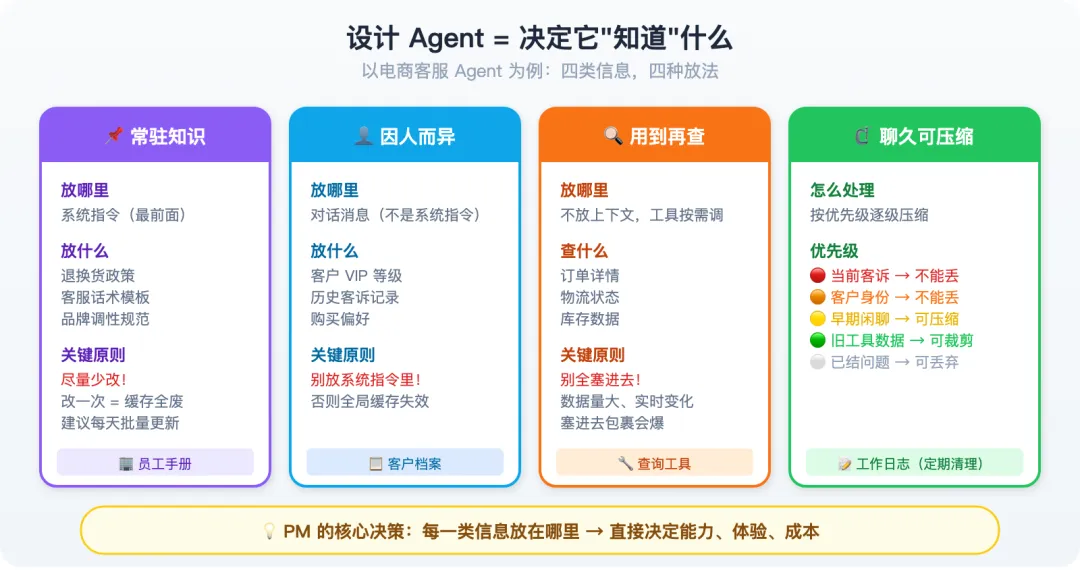
你作为 PM 要做的,就是决定每一类信息放在哪里。 这个决策直接决定 Agent 能做多好(能力)、用户等多久(体验)、每个月花多少钱(成本)。
这套架构会一直这样吗?
读到这里你可能会想:模型越来越强了,以后还需要这么费劲地管理记忆吗?
这个问题我也想过,所以特意去查了一圈最新的研究和业界动态。分享一下我的发现。
ChatGPT 的 Memory、Claude 的记忆文件,是真的”记忆进化”吗?
你可能听说过 ChatGPT 的 Memory 功能、Claude 的记忆文件——听起来好像模型已经能”跨对话记忆”了。
但仔细看底层机制,会发现它们跟我们刚才讲的其实是一回事。ChatGPT 的 Memory 就是把关键信息存到数据库,下次对话时注入到 system prompt 里。Claude 的记忆文件就是写到 MEMORY.md 文件里,下次会话时读出来塞进 messages 数组。
本质都是第⑤步”持久化”的产品化——写纸条存到文件,下次拿出来放桌上。模型本身依然是无状态的,依然每次从零开始读。 了解了底层原理之后,再看这些产品功能,你会发现它们并没有改变游戏规则——只是把手动操作自动化了。
那窗口越来越大呢?总能解决问题吧?
上下文窗口从几千 token 涨到了 200K,Gemini 甚至到了 200 万。直觉上觉得:窗口够大,把所有东西一股脑塞进去就行了——还管什么上下文?
我之前也这么想过。但 2025 年的几项研究让我改变了看法:
塞得下 ≠ 用得好。 Chroma 的研究测试了 18 个主流模型,发现每一个都随着输入变长而性能下降——即使是简单任务。斯坦福大学的”Lost in the Middle”研究发现,放在中间位置的信息,准确率下降超过 30%。原因是注意力机制本身的数学特性:离开头和结尾越远的内容,被”注意到”的概率越低。
塞得下 ≠ 塞得起。 Transformer 的计算量跟上下文长度的平方成正比——窗口大 2 倍,计算成本翻 4 倍。窗口从 4K 扩到 32K,推理时间增加 5 倍以上。
“有效窗口”远小于”标称窗口”。 在复杂任务上,13 个模型中有 11 个在仅 32K token 时就跌破了基准性能的 50%。GPT-4o 从 99.3% 的基准准确率直接跌到 69.7%。模型标称 200K 窗口,不代表在 200K 时还能正常工作。
Andrej Karpathy(前 Tesla AI 总监、OpenAI 联合创始人)在 2025 年明确提出:应该用”上下文工程”(Context Engineering)取代”提示词工程”。他的原话是——”上下文工程是一门精密的艺术与科学,核心是往上下文窗口里填入恰好正确的信息。”
这让我意识到一件反直觉的事:窗口变大不是让上下文管理变得不重要了,而是更重要了。 因为塞得越多,噪音越多,模型越容易在信息里”迷路”。关键不是塞得下多少,而是塞进去的是不是”恰好正确的信息”。
那真正的变化可能在哪里?
我觉得真正有可能改变”每次重发所有历史”这套模式的,不是更大的窗口,而是全新的模型架构。有两个方向值得关注:
第一个方向:给模型加一个”长期记忆模块”。 Google 在 2025 年底发布了 Titans 架构,在传统注意力机制旁边加了一个独立的神经网络记忆模块——不是把历史塞进窗口,而是让模型把重要信息”编码”进一个持久的记忆层,需要时从记忆层”回忆”。
还是那个失忆同事的比喻——Titans 相当于从”每天打印工作日志放桌上”进化成”员工真的把事情记在脑子里了”。
第二个方向:用全新架构替代 Transformer。 Mamba 等状态空间模型(SSM)用一个固定大小的”隐藏状态”替代了不断增长的历史数组。不管对话多长,记忆占用都是常数——不会越聊越大。2026 年 3 月发布的 Mamba-3 实现了线性时间推理:上下文越长,反而比 Transformer 越便宜。当然,代价是在某些任务上表现不如 Transformer。
不过要说清楚:这些都还在研究或早期阶段。 截至目前,所有主流产品——ChatGPT、Claude、Gemini——的底层都还是”无状态 Transformer + 外部注入”的模式。我们今天讲的”记忆 = 文本数组”的架构,在可预见的未来还会是主流。
那我们今天聊的这些,以后还有用吗?
我觉得有用,而且会一直有用。
因为不管底层技术怎么演进——窗口变大了、模型有了原生记忆、Transformer 被新架构替代了——有一个问题永远需要人来回答:这个 Agent 应该”知道”什么?
技术决定了”怎么让它知道”(塞进数组?原生记忆?状态空间?),但”该知道什么、不该知道什么、什么时候该忘记、什么信息值得跨会话保留”——这些判断,只有理解业务的人才能做。
今天你学会了怎么管理一个文本数组,明天即使这个数组消失了,你对”信息该怎么流动”的判断力,依然有用。
总结
回顾一下今天聊了什么:
- 模型没有记忆
——每次 API 调用都是从零开始,它能”记住”,完全靠你把历史重发一遍 - 记忆就是文本数组
——没有独立的记忆存储,所有”记住/忘记/注入/使用”都是对一个数组的增删改查 - 包裹只增不减
——每轮对话都在累积,塞不下了就要压缩,压缩就可能丢信息 - 管理上下文 = 管理认知
——你往包裹里放什么,模型就知道什么;你没放的,它完全不知道
最反直觉的洞察:Agent 看起来”聪明”,不是因为它真的理解了什么,而是因为有人精心安排了它每次能”看到”什么。设计 Agent,本质上就是设计它的认知输入。
下期预告上下文让模型”看见”了世界,但模型怎么”改变”世界?它只会生成文本——怎么变成真的能读文件、执行命令、搜索代码的”多面手”?下一篇我们聊工具系统——只会说话的 AI,怎么学会”动手做事”。
「拆解 Claude Code 源码」系列目录:
- 01:所有Agent的核心,竟然只有一行代码
- 02:模型每天失忆,它靠什么”记住”世界?(本篇)
- 03:只会生成文本的AI,怎么学会”动手做事”?
- 04:能执行任意命令的AI,你敢让它跑在你电脑上吗?
- 05:一个Agent不够用时,怎么”带团队”?
- 06:Agent越自主越危险,人类如何信任它?
- 07:512K行代码,最少只需要多少行就够?
- 08(完结):从第一性原理到产品落地的全景图