 夜雨聆风
夜雨聆风





为什么你的AI Agent把记忆当成了硬盘,而它本应是个分层大脑
两个月前,主流观点鼓吹markdown文档系统才是人类工作的基本块,是共识;于是给 Agent 做了一套还不错的长期记忆系统。
做法很简单:把所有的决策日志、用户偏好、历史对话摘要,全部写进一个 Markdown 文件。每次调用 Agent 的时候,把这个文件整个塞进系统提示词。文件越来越大,我就加标题、加分类、加时间戳,以为结构化之后问题就解决了。
用了两周,系统开始出问题。
同一个用户偏好,文件里存了三个互相矛盾的版本,没有任何一个被标记为”最新”。上个月记录的操作习惯和昨天记录的权重设置一模一样,明显是重复写入但没有去重。每次调用都要把几千字的历史全部塞进上下文,响应速度慢到离谱,偶尔还会因为上下文太长导致模型开始”串台”——把 A 用户的偏好用在 B 用户身上。
我花了很长时间排查,最后得出一个让自己有点难堪的结论:
我根本不是在做记忆,我只是在把 Prompt 当 RAM 用。
存档和记忆是两件完全不同的事。存档是静态的,你把东西写进去,它就在那里,不会变,不会衰减,不知道自己和其他东西有什么关系。记忆是动态的,它有结构,有关系,会演化,重要的东西越来越清晰,不重要的东西慢慢淡化。
我做的那套系统,本质上是一个只能追加、不能思考的流水账。它记住了我写过什么,但永远记不住这件事和那件事有什么关系,这个决策为什么被否决,上次遇到同样的问题我们是怎么解决的。
这个坑,让我开始认真研究 AI Agent 的记忆系统到底应该怎么做。
02 先把概念理清:记忆不是一件事
讨论 AI Agent 记忆系统的时候,最常见的混乱来源是把”记忆”当成一个整体来处理。这就像把”交通工具”当成一个整体来讨论,然后争论自行车和飞机哪个更好——问题本身就问错了。
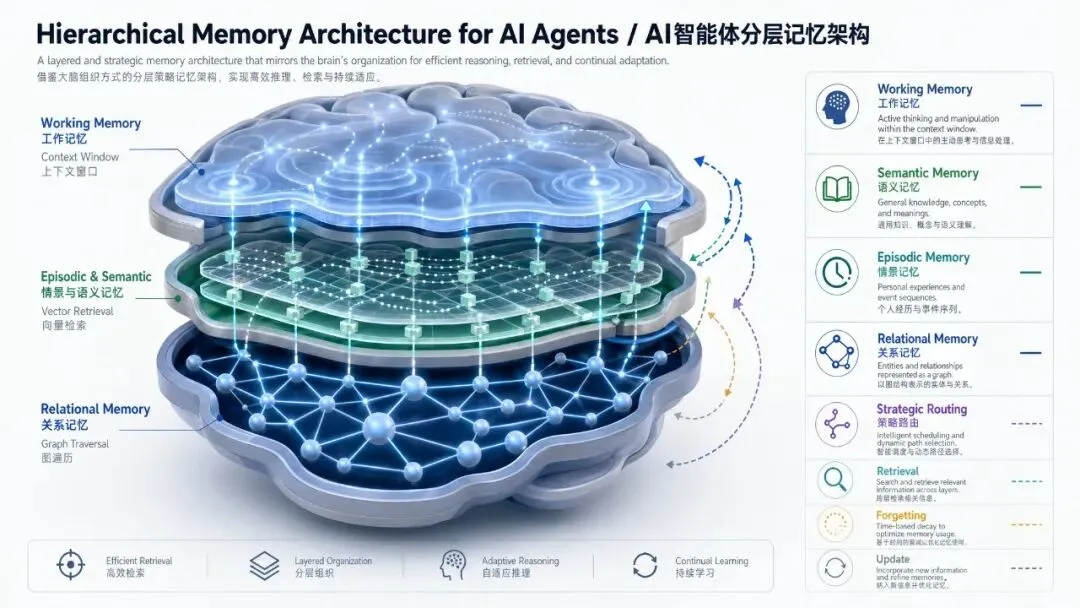
认知科学早就把人类记忆分层了,AI 系统的记忆也应该如此。
情景记忆(Episodic Memory)
记录发生过什么,什么时候发生的,在什么上下文里发生的。”上周三我们讨论过这个 bug,最后用方案 B 解决了”——这是情景记忆。它的特点是时序性强、细节丰富、但大量细节会随时间失去价值。
语义记忆(Semantic Memory)
稳定的事实、偏好、知识。”这个用户喜欢简洁的回答”、”这个项目用 Rust 写的”——这是语义记忆。它的特点是相对稳定、高频使用、需要去重和更新机制。
程序记忆(Procedural Memory)
怎么做事,技能和流程。”遇到这类数据库连接错误,先检查连接池配置”——这是程序记忆。它的特点是可执行、可复用、更新频率低但一旦更新影响面广。
这三种记忆类型,需要完全不同的存储方式、检索策略和更新机制。用同一套方案处理三种记忆,是大多数 Agent 记忆系统失败的根本原因。我当时踩的坑,本质上就是用一个 Markdown 文件同时承担了三件完全不同的事,然后期待它能全部处理好。
理解了这个分层,再来看现有的技术方案,就会清晰很多。
03 现有方案的真实能力边界
3.1 文件系统式记忆
最直觉的方案,也是最容易被滥用的方案。
它的核心逻辑是:把需要记住的东西写成文本文件,调用时读取并注入提示词。Markdown、JSON、纯文本,本质上都是这一类。
它能做什么: 实现简单,工程上零依赖,内容人类可读可编辑,适合存储少量稳定的语义记忆——用户的基本偏好、项目的核心配置、不常变化的规范。
它做不到什么: 没有原生的去重机制,同一个事实可以被写入多次;没有衰减机制,三年前的记录和昨天的记录权重相同;没有关系感知,文件里的每一行都是孤立的,彼此之间没有任何结构化的联系;超过一定规模之后,性能直接崩塌——把几千行历史全部塞进上下文,既慢又容易让模型失焦。
Hermes Agent 是目前把文件系统式记忆用得最克制、最正确的开源案例之一。它把持久记忆压缩在两个文件里:MEMORY.md 存储智能体笔记,上限 2200 字符;USER.md 存储用户画像,上限 1375 字符。加起来大约只有 1300 个 Token。
这个设计看起来很小气,但背后的逻辑非常清醒:文件系统式记忆只适合存储高频、稳定、精炼的语义事实,不适合存储历史、过程和关系。 把它用在正确的位置,它就是一个高效的工具;把它用来承担所有记忆职责,它就是一个定时炸弹。
文件系统式记忆的天花板很明确:它只能记住你写过什么,永远记不住这件事和那件事有什么关系。
3.2 向量检索
向量检索是目前 RAG 系统里最主流的记忆方案,它比文件系统式记忆聪明了一个层次。
它的核心逻辑是:把文本转换成高维向量,存入向量数据库。查询时,把问题也转换成向量,找出距离最近的几个向量,返回对应的文本片段。
它能做什么: 语义相似度匹配。”用户喜欢简洁”和”用户不喜欢啰嗦”在向量空间里距离很近,即使措辞完全不同,也能被识别为相关内容。这是文件系统式记忆做不到的。它适合做”找相似历史片段”、”快速召回相关上下文”这类任务,成本低,上线快。
它做不到什么: 向量检索能告诉你两段内容”长得像”,但不能告诉你它们之间”发生了什么”。它是相似度空间,不是因果空间。
“这个 bug 上次是怎么修的”——向量检索找不到,因为这是一个因果链,不是一个相似度问题。”这个决策为什么被否决”——向量检索找不到,因为这是一个推理过程,不是一个语义匹配问题。”上次遇到同样的情况,我们最终选了哪个方案,原因是什么”——向量检索找不到,因为这需要跨多个文档的关系推理。
向量检索的定位应该是”记忆系统的入口”,而不是”记忆系统的全部”。它负责快速找到相关的候选内容,但不负责理解这些内容之间的关系。
3.3 图遍历
图遍历是目前在关系感知这个维度上能力最强的方案,也是工程复杂度最高的方案。
它的底层数据结构是节点和边。节点是实体,边是关系,每条边都有类型、方向和属性。关系不是附属品,而是一等公民。
[用户] --喜欢--> [简洁风格]
[简洁风格] --冲突--> [详细注释]
[某次bug] <--导致-- [不写注释]
[某次bug] --解决方案--> [加类型注解]查询时,不是搜索关键词,而是从一个节点出发,沿着边一步步游走,把沿途经过的节点和关系全部收集起来,拼成一段有结构的上下文。这就是”沿边游走”。
它真正解决了四个文件系统式记忆和向量检索都解决不了的问题:
去重: 图里”简洁风格”只有一个节点,新信息是加一条边,不是再写一行。同一个事实天然只存一次。
衰减: 每个节点有时间戳和权重,越久没被访问的节点权重越低,遍历时优先走高权重的边,过时的信息自动被忽略。
因果推理: 从”某次 bug”这个节点出发,沿边往回走,能找到完整的因果链——不写注释导致了 bug,不写注释来自简洁风格偏好,简洁风格偏好来自用户本身。一次遍历,拿到的是一张关系网,而不是几行孤立的文字。
矛盾检测: 写入”用户喜欢详细注释”时,图发现已经存在”用户不喜欢注释”这个节点,可以触发冲突解决逻辑,而不是默默存入两条互相打架的记录。
但图遍历的工程成本是真实的负担,不能回避。实体解析需要从非结构化文本里准确抽取节点和关系,这一步的质量直接决定整个图的可用性;关系维护需要处理节点合并、边的版本控制、图的一致性;时间版本管理需要记录每条关系在什么时候建立、什么时候失效;推理路径调试在出问题时很难定位根因。
这些成本在简单场景下是过度设计,但在复杂场景下是必要投入。
3.4 参数化记忆
参数化记忆是一条和前三种完全不同的路线:不把知识存在外部系统里,而是通过微调或持续学习,把知识直接压进模型的权重。
它的优点: 推理时不需要外部检索,速度快,没有检索延迟,适合存储大量稳定的领域知识。
它的缺点: 更新极其困难,每次更新都需要重新训练;遗忘不可控,模型可能在学习新知识的过程中覆盖旧知识;版本控制复杂,很难精确追踪某条知识是什么时候写入的、是否已经过时。
参数化记忆更适合处理“稳定的、大规模的、不需要频繁更新的”知识,比如领域专业知识、语言规范、通用推理能力。它不适合处理动态的、个性化的、需要实时更新的 Agent 状态。
04 Hermes 做对了什么,还差什么
Hermes Agent 是目前开源社区里记忆架构设计最成熟的案例之一,值得单独拆解。
它做对的事情:
冷热分离是 Hermes 最核心的设计决策。高频、稳定的语义记忆(MEMORY.md 和 USER.md)常驻提示词,低频、历史性的情景记忆(SQLite 会话数据库)按需检索。这个分离直接解决了”把所有东西塞进上下文”的性能问题。
缓存优先是 Hermes 的工程哲学。它的提示词构建器有一个明确目标:让稳定的前缀部分尽可能长时间保持不变,以便充分利用大模型供应商的提示词缓存机制。频繁改动提示词会导致缓存失效,延迟上升,成本增加。Hermes 把这个工程约束内化成了架构原则。
记忆冲刷机制解决了长对话压缩时的信息丢失问题。在压缩之前,Hermes 会先触发一次额外的模型调用,让模型把值得保留的事实写入 MEMORY.md,然后再执行压缩。这确保了重要信息不会在对话被”洗掉”的过程中丢失。
Skills 层是程序记忆的雏形。技能存储在独立目录,提示词里只放索引,需要时才加载具体内容。这个”索引 + 按需展开”的逻辑,和图遍历的”节点 + 按需沿边展开”在思路上非常接近。
它还没触碰的层:
Hermes 的 session_search 是全文关键词搜索,它能找到”提到过这个词的会话”,但找不到”这件事和那件事之间的因果关系”。Skills 之间没有关系,你不知道技能 A 和技能 B 在什么情况下会冲突,技能 C 是从哪次失败里学来的。MEMORY.md 里的条目是平铺的,没有结构化的关系网络。
Hermes 把”工程上正确地使用文件系统式记忆”这件事做到了很高的水准,但它还没有触碰关系感知这个层次。Hindsight 作为 Hermes 的原生记忆提供者,已经在往这个方向走——它在每轮对话后抽取实体和关系,开始构建结构化的知识图谱。这是 Hermes 架构的自然演进方向。
05 混合架构:不是妥协,是正确答案
现在可以回答最核心的问题了:未来的 Agent 记忆系统应该是什么样的?
答案是分层混合架构,而且这不是一个”各退一步”的妥协方案,而是唯一在逻辑上自洽的答案。
原因很简单:不同的记忆类型,天然对应不同的技术特性需求。
情景记忆需要时序性、可搜索、按需加载,SQLite 加全文搜索是合理的选择。语义记忆需要去重、稳定、高频访问,精炼的文本加向量索引是合理的选择。关系记忆需要因果推理、矛盾检测、多跳遍历,图数据库是合理的选择。程序记忆需要可执行、可复用、版本可控,结构化文件加技能索引是合理的选择。
把这些层叠加起来,一个完整的混合记忆栈大致是这样的:
工作记忆层 上下文窗口 当前会话的实时状态
语义记忆层 精炼文本 + 向量索引 稳定偏好、用户画像、核心事实
情景记忆层 SQLite + 全文搜索 历史会话、过去的决策和结果
关系记忆层 图数据库 + 图遍历 实体关系、因果链、矛盾检测
程序记忆层 技能文件 + 规则文档 可执行知识、操作规范、经验沉淀关键不是”用哪一种”,而是”哪一层负责什么,何时触发哪一层”。
用一个具体场景串起来:Agent 遇到一个数据库连接报错。
工作记忆层提供当前的错误信息和对话上下文。语义记忆层告诉 Agent 这个用户的技术栈偏好和沟通风格。情景记忆层通过 session_search 找到上次遇到类似报错的会话摘要。关系记忆层通过图遍历,从”数据库连接错误”这个节点出发,找到”连接池配置”、”上次的解决方案”、”这个解决方案为什么有效”这条因果链。程序记忆层提供处理这类问题的标准操作流程。
五层协同,Agent 给出的不是一个孤立的答案,而是一个有上下文、有历史、有因果逻辑的完整响应。
这个架构的核心设计原则是:每一层只做自己最擅长的事,策略层负责决定何时调用哪一层。 向量检索负责找到入口,图遍历负责从入口展开关系网络,文件系统负责常驻高频事实,SQLite 负责归档历史,技能文件负责沉淀可执行知识。没有哪一层是万能的,但组合起来可以覆盖几乎所有的记忆需求。
反对图中心化的声音是有道理的:图系统的工程复杂度确实很高,实体解析的质量直接决定图的可用性,很多简单场景用向量检索就够了。但这个反对意见的正确结论不是”不用图”,而是”在需要关系推理的场景才引入图”。混合架构的优势恰恰在于此——你可以根据场景的复杂度,决定是否激活图这一层。
06 四类场景的落地建议
理论上的混合架构需要落地到具体场景。不同的应用场景,对各层的依赖程度差异很大。
个人助理
核心需求是跨会话的连续性和个性化。用户偏好、沟通风格、常用工具——这些是高频的语义记忆,适合 Hermes 模式:精炼文本常驻提示词,历史会话存 SQLite 按需检索。图遍历在这个场景下是增强模块而非核心模块,主要用于处理用户偏好之间的冲突和演化。时间衰减机制很重要,三个月前的偏好和昨天的偏好不应该有相同的权重。
推荐栈:文件系统式记忆(Hermes 模式)+ 向量检索 + 轻量图(处理偏好冲突)+ 时间衰减。
企业知识库
核心需求是审计可解释性、版本控制和跨部门的知识关联。这个场景对图遍历的依赖最强——谁做了什么决策、为什么做、这个决策和哪些其他决策有关联,这些都是典型的图查询问题。向量检索负责快速找到相关文档,图遍历负责展开文档之间的关系网络。
推荐栈:图数据库为核心 + 向量检索作为入口 + 强版本控制 + 审计日志。
多智能体系统
核心需求是多个 Agent 之间的记忆一致性。每个 Agent 有自己的工作记忆和程序记忆,但语义记忆和关系记忆需要共享。共享图谱是这个场景的关键基础设施——所有 Agent 读写同一张图,确保对同一个实体的认知是一致的。冲突解决策略需要在架构层面设计清楚,否则多个 Agent 并发写入会导致图的一致性问题。
推荐栈:共享图谱 + 独立上下文窗口 + 分布式一致性策略 + 冲突解决机制。
编程 Agent
核心需求是技能沉淀和代码库的演化状态追踪。程序记忆在这个场景下权重最高——CLAUDE.md、AGENTS.md 这类规则文件,加上 Skills 层的技能索引,是编程 Agent 最重要的长期记忆载体。图遍历用于存储代码库的演化状态:这个函数为什么被重构、这个架构决策的背景是什么、这个 bug 的根因链是什么。上下文窗口超过一定规模之后,纯上下文窗口不够用,图存演化状态加动态检索是唯一可扩展的方案。
推荐栈:程序记忆优先(规则文件 + 技能索引)+ 图存演化状态 + 向量检索作为辅助。
07 真正的问题不是存储,是策略
回到最开始的那个坑。
当时的问题不只是选错了存储方式。更根本的问题是:我根本没有想清楚”记忆是为了什么”。
我把所有东西堆进 Markdown,是因为我把”记住更多”当成了目标。但记忆的真正目标不是存储,而是在正确的时机,以正确的形式,提供正确的上下文。
一个真正有效的记忆系统,需要能回答三个问题:
这条信息应该存在哪一层? 是高频的语义事实,还是一次性的情景记录,还是可复用的程序知识,还是需要关系推理的结构化数据?不同的信息类型,应该进入不同的存储层。
什么时候应该被检索出来? 不是每次调用都把所有记忆全部加载,而是根据当前任务的性质,决定激活哪几层记忆。简单的偏好查询,语义记忆层就够了;复杂的因果推理,才需要激活图遍历层。
什么时候应该被遗忘或更新? 记忆系统如果只能增加不能遗忘,最终会被过时的信息淹没。衰减机制、矛盾检测、主动更新策略,是记忆系统长期可用的保障。
很多人还在争论上下文窗口越大越好,以为把窗口扩展到一百万、两百万 Token 就能解决记忆问题。但生产环境里真正致命的,永远是跨会话的记忆漂移和上下文污染——不是窗口不够大,而是没有机制保证窗口里的内容是正确的、一致的、有结构的。
图遍历、向量检索、Hermes 模式都不是银弹。没有任何单一技术能解决所有的记忆问题,因为记忆本身就不是一件事。
真正的诀窍不是记住更多,而是在正确的层级、以正确的成本,记住正确的事情。
能做到这一点的系统,才算真正做对了记忆。
本文参考了 Hermes Agent 开源代码库、Hindsight 技术文档、Mem0 2026 年记忆系统状态报告,
欢迎链接,V:wlyewan01 注明来意-数字编号:
1、围观朋友圈;2、讨论交流;3、进群。