 夜雨聆风
夜雨聆风





钢铁、芯片和打卡:AI 时代,价值到底流向哪里
在每一个技术时代,价值都不会流向“最好的产品”,而是流向那个占住关键一层的人,那一层,是所有东西都必须在上面运行的。
我在 Duolingo 上已经连续打卡 1338 天了。每天早上我都会打开它。有时候只用三十秒,有时候用十分钟。将近四年,一天都没断过。
但有个不太奇怪的事实是:ChatGPT 明明是更好的语言老师。它更灵活、更像对话、更有耐心,也更有可能真正帮我学会一门语言。可我还是没有离开 Duolingo,一次都没有,甚至没有认真动过这个念头。
“更好的产品”和“人们真正会用的产品”之间的这个差距,是现在技术里最重要的问题之一。而这个问题,也能解释今天 AI 经济里正在发生的很多事,为什么 Nvidia 明明可以多赚很多钱却没有这么做,为什么 Google 这一季的表现是所有超大规模公司里最好的,以及为什么很多 AI 应用公司在收入增长的同时,其实正在慢慢走向边缘化。
答案一直都是同一个,而且 150 年来都没变过:
价值不会流向最好的产品,而是流向那个占住关键一层的人。
这张“地图”其实已经存在 150 年了,只是材料变了。
一张理解 AI 的结构地图
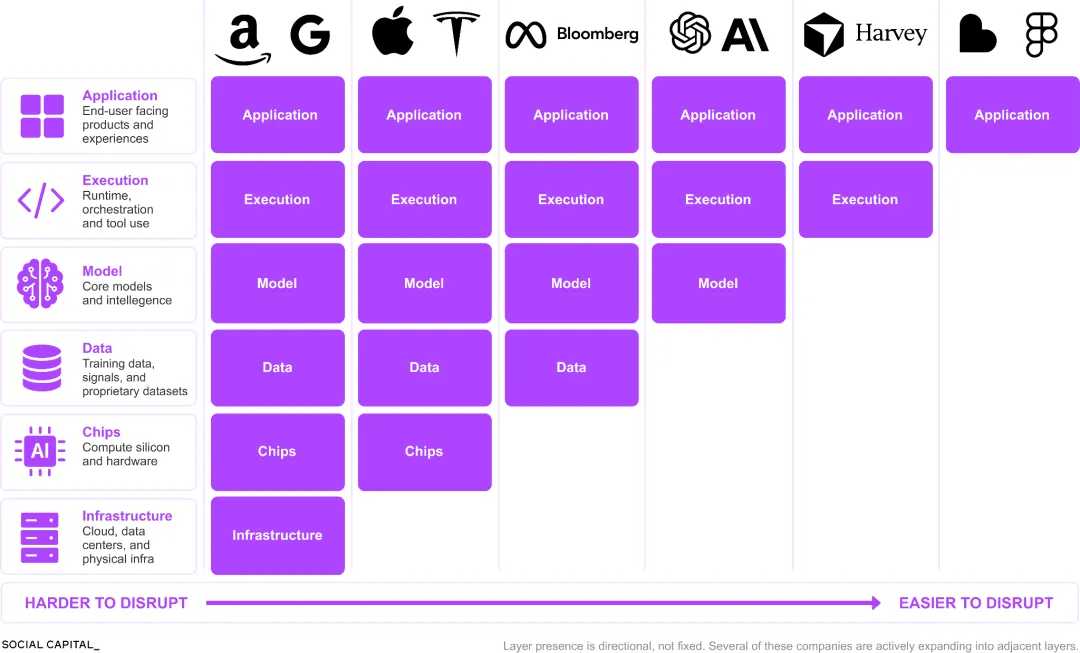
如果你想看清 AI 的价值是怎么流动的,你需要一张“结构图”
AI 的价值,必须经过六层:基础设施、芯片、数据、模型、执行、应用。
大多数人看到的是一张技术图,但我看到的是 1890 年的铁路。
卡内基把钢卖给所有修铁路的人。洛克菲勒通过控制关键节点,掌握了 90% 的炼油。摩根用资本把整个体系连在一起,不只是为了回报,更是为了协调,把彼此竞争的铁路公司绑在一起,避免无序竞争把资产价值拖垮。
今天 AI 里正在形成的,是同样的结构。
荷兰的 ASML 造出了所有先进芯片必须用的机器。台积电生产几乎所有 AI 模型运行所需的芯片。Nvidia 的 CUDA 成了开发者必须依赖的软件层,几百万开发者都在上面构建,一旦要迁移,成本极高,甚至几乎不可能。甚至北卡罗来纳州的一座矿,都在整个芯片生产链条里占着关键位置。
1880 年,洛克菲勒控制了 90% 的炼油,2000 年,思科控制了 85% 的路由。AI 底层的集中,也在走同样的路径,只是更快,也更隐蔽。
问题从来不是“会不会集中”,而是:
当它集中时,你在哪一层。
最强的位置,往往也是最克制的
在整个体系里,最有力量的玩家,反而最克制。
Nvidia 掌握着最稀缺的资源:GPU。所有 AI 实验室、云厂商、neocloud 都离不开它。需求远远超过供给。按最简单的经济逻辑,它完全可以把价格拉到极限,赚最多的钱。
但它没有。TSMC也是一样。
如果 Nvidia 把价格压到极限,就会逼 Google 加速 TPU,Amazon 投更多钱做 Trainium,Microsoft 加快自研芯片。短期收益,会换来长期的威胁。
这和当年摩根对铁路做的事情很像。他让各条铁路停止价格战,不是因为他慷慨,而是因为混乱正在摧毁他投进去的资产价值。
在任何一个体系里,最强的位置,不是那个榨取最多利润的,而是那个让自己成为“没人能绕开的那一层”的位置。然后用足够的克制,让别人没有动力去尝试绕开你。
应用层,看起来强,其实更像农民

现在很多人看 AI,关注的是:哪个模型更强,哪个公司会赢,哪个应用用户最多。
这些问题,其实都是在看“楼”。
真正该问的是:谁拥有“地”。
应用层看起来很强:它直接面对用户,有分发、有收入。
但如果你仔细看,它更像铁路时代的农民。
农民依赖铁路,但不掌控铁路。当铁路公司调整价格时,农民只能承担成本,因为他们没有别的选择,也没有谈判能力。
今天的结构也类似。
底层玩家之间是高度绑定的:云厂商投资模型公司,模型公司依赖算力,大家在同一个利益网络里。
但应用层,在这个网络之外。它依赖下面,却不在这个“协调体系”里。
市场其实已经开始反映这一点了:SaaS 估值压缩、软件贷款折价、这一季 Google 和其他公司的表现明显分化。
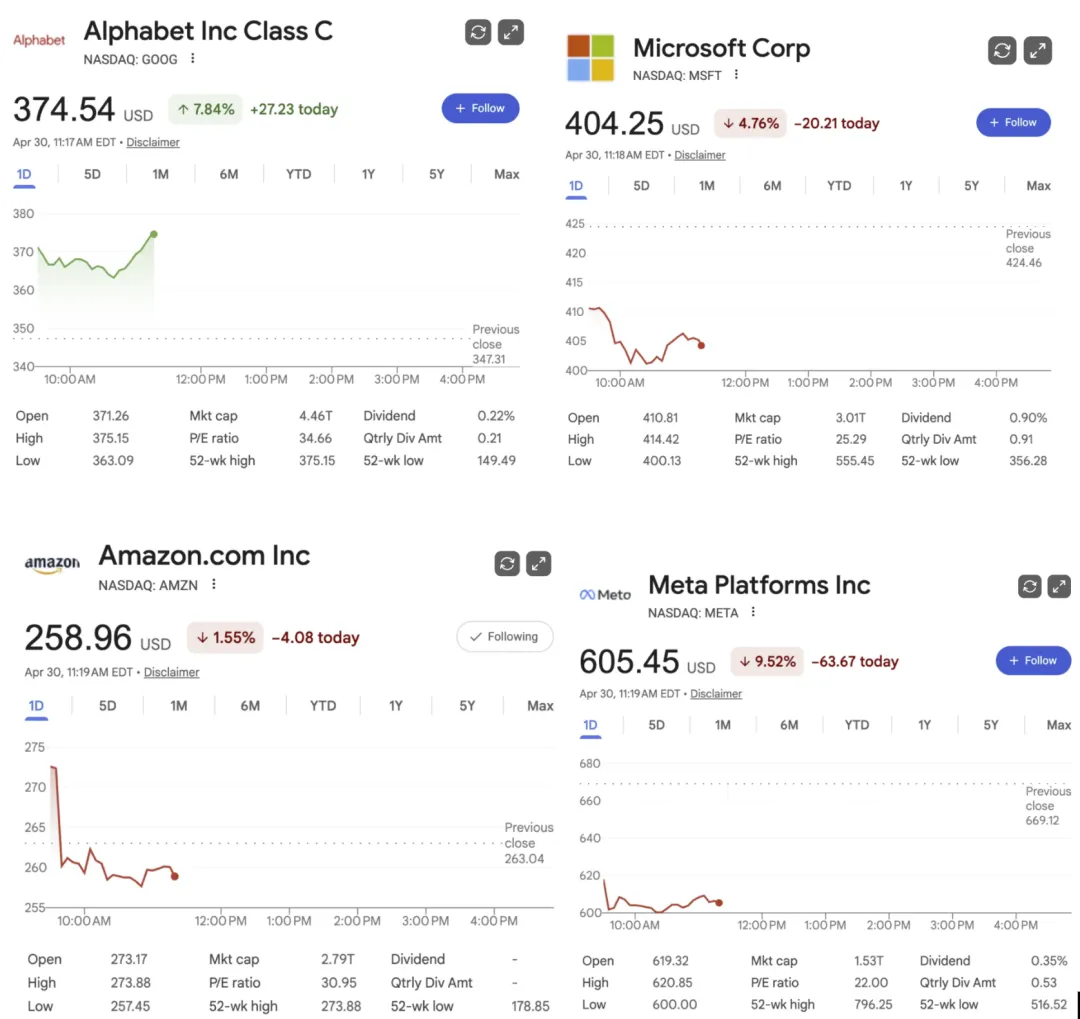
这不是简单的估值问题,而是护城河的问题。
市场正在区分两类公司:一类有真正的飞轮,一类只是从 OpenAI 租能力,再希望自己的界面足够粘人。
大多数应用公司,其实是后者,只是还没有完全意识到。
三个问题,帮你分清“飞轮”和“假护城河”
我通常会问三个问题:
第一,是什么具体的用户行为,产生了这些数据?这个行为,是不是只会发生在你的产品里?
关键不是你想收集什么数据,而是用户实际做了什么。如果这个行为在别的地方也能发生,那这些数据就不属于你。
第二,这些数据是本质上独有的,还是只是你来得早?
有些数据只有你的用户能产生,比如医疗场景中的影像和诊断数据,别人很难复制。有些数据只是时间问题,资金足够的竞争对手几年就能补上。
时间优势,不是飞轮。
第三,这些数据,会不会让产品对这个用户“明显变好”,还是只是整体上“稍微变好”?
很多公司会在这里误判。它们积累了很多数据,但只是让模型整体稍微提升,而不是对某个具体用户产生质的变化。
Duolingo 的护城河,是我帮它建的
再来看我这 1400 天的打卡。
真正产生价值的数据,不是我做了多少练习,而是这些细微的行为:我什么时候打开App,是累的时候还是有精力的时候,用了三十秒还是十分钟,哪些提醒把我拉回来,哪些语法让我卡住。
这种长期、连续的行为模式,在几亿用户、几十种语言、十年时间里积累下来,是非常深的“习惯”和“学习心理”的数据。
而且,这种数据是很难复制的。
你不是多投点钱,就能在两年内造出一个“十年用户行为”。
更关键的是
这不只是数据。这是一个身份。
这 1400 天的打卡,我带不走。如果我换平台,我失去的不只是一个工具,而是这个身份,“那个已经坚持了 1400 天的人”。
这个身份,是锁在 Duolingo 里的。
这才是真正的护城河。
Duolingo 的飞轮,不只是语言学习数据,而是个体层面的习惯心理数据,长期积累,并绑定在一个无法迁移的身份上。
所以,即使 ChatGPT 是更好的老师,也不会直接替代它。
赢的产品,不一定是最好的,而是那个让你离开时感觉“失去了一部分自己”的产品。
最稀缺的,一直是人类行为
整个结构会继续变化,瓶颈会不断移动。
在移动互联网时代,限制从基础设施转向对问题的理解和网络效应。
在 AI 时代,限制正在转向另一件事:基于人类行为的、长期积累的数据飞轮。
Google 这一季表现好,不是因为 Gemini 是最强模型,而是因为它在多个层同时占住了关键位置:Search、Android、Chrome 带来的分发,TPU 带来的算力,以及二十年积累的人类行为数据。
它不是在比赛的公司,它是比赛发生的那一层。
而大多数应用公司,没有分发,也没有飞轮。
它们有的是一个不错的界面,一些在增长的用户,以及一个从别人那里“租来的模型”。
铁路时代的农民也有土地,但这并不能保护他们。