 夜雨聆风
夜雨聆风





智能表格识别:从非结构化文档到精准结构化数据的桥梁
-
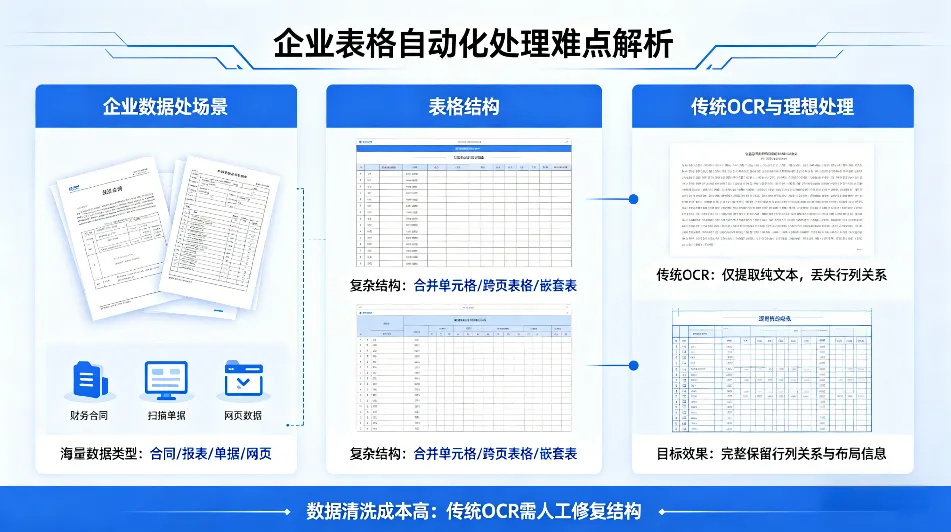
区域定位:自动区分文本区、图片区、线条区和表格区。 -
网格重建:针对复杂的表格,算法会尝试还原其潜在的网格结构,识别出行、列、合并单元格(Rowspan/Colspan)的边界。即使面对手绘线模糊、背景杂乱的情况,也能通过特征提取准确锁定表格范围。
-
多语种支持:能够同时识别中文、英文、日文、韩文、法文等多种语言,甚至混合排版的文字,无需人工切换模型。 -
复杂字形处理:针对手写体、印刷体、低分辨率扫描件中的模糊字迹,采用端到端的识别网络,显著提升识别率。 -
方向校正:自动纠正倾斜、旋转的文字,确保内容被正确读取。
-
语义关联:利用图神经网络(GNN),判断哪些文字属于同一行、同一列,从而构建出完整的二维数据结构。 -
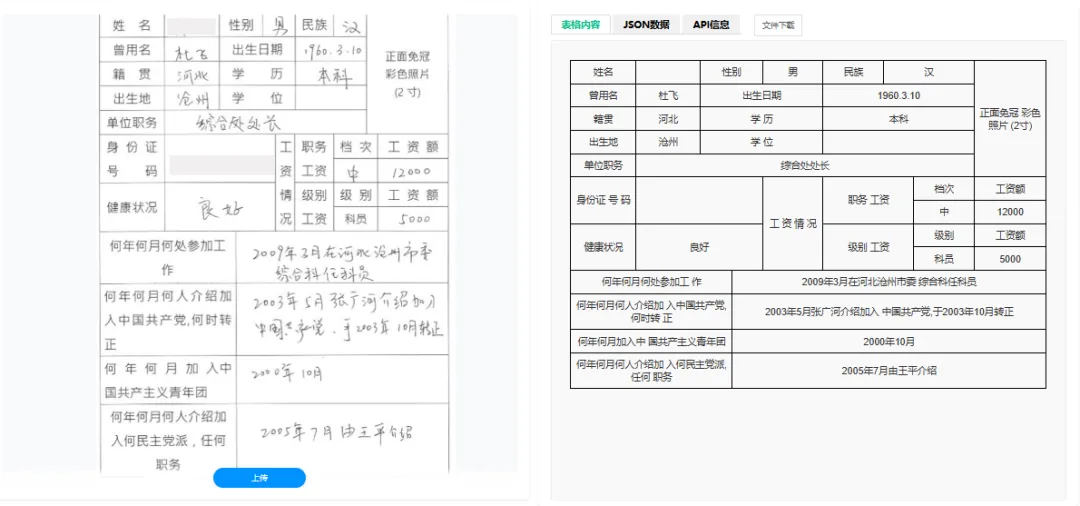
布局还原:不仅输出Excel或JSON格式的结构化数据,还能生成HTML或LaTeX代码,完美复刻原表的视觉样式(包括边框、对齐方式、合并单元格)。 -
异常处理:对于跨页表格,系统能根据上下文逻辑自动拼接;对于无边框表格,则通过文字间距和语义对齐推断结构。
-
全场景覆盖:无论是清晰的打印表格,还是模糊的复印件、高斯模糊、光照不均、甚至折痕严重的纸张,内置的增强预处理模块都能有效应对。 -
多语种无缝融合:打破语言壁垒,一套系统即可处理全球范围内的多语言混合表格,满足跨国企业的业务需求。 -
结构化输出:直接输出JSON、XML、CSV或Excel文件,保留原始布局信息(如合并单元格标记),让下游业务系统(如ERP、CRM)可直接调用,无需二次开发清洗逻辑。 -
自动化程度高:从上传文件到获取结构化数据,全程无需人工干预,显著缩短数据处理周期。
-
在处理银行流水单、财务报表、保险理赔单据时,系统能快速提取复杂的金额、日期及科目信息,自动匹配财务规则,大幅缩短人工录入时间,降低合规风险。
-
针对各类行政审批表、社保登记表、户籍档案等半结构化文档,技术可实现批量自动化归档与检索,提升政府办事效率,推动“一网通办”进程。
-
面对种类繁多、格式各异的运单、装箱单和发票,系统可快速提取货物名称、数量、重量及目的地信息,实现物流信息的实时追踪与库存管理自动化。
-
在学术论文、实验数据记录本的处理中,该技术能帮助研究人员快速整理历史数据,构建科研数据库,加速知识沉淀与分析。