 夜雨聆风
夜雨聆风





别再凭感觉下载本地大模型了:llmfit 会告诉你哪个真能跑
本地跑大模型,最痛苦的不是安装。
是选择。
你看到一个模型很火。
参数 70B,榜单很高,评论区都说强。
然后你下载。
几十 GB 下完,加载半天,最后发现:
显存不够。
速度太慢。
上下文一拉长就爆。
量化版本选错了。
这时候你才意识到,本地模型不是“哪个最强就下哪个”。
而是:
哪个模型适合你的硬件、你的用途、你的运行时。
今天这个开源项目,解决的就是这个问题:
AlexsJones/llmfitGitHub:
https://github.com/AlexsJones/llmfit一句话:
它会检测你的 RAM、CPU、GPU/VRAM,然后告诉你哪些本地模型真正适合这台机器。
它不是模型榜单,而是“模型试衣间”
llmfit 的 README 写得很直接:
Hundreds of models & providers. One command to find what runs on your hardware.
翻译成人话:
不是问“哪个模型最强”。
而是问“哪个模型在你的机器上最合适”。
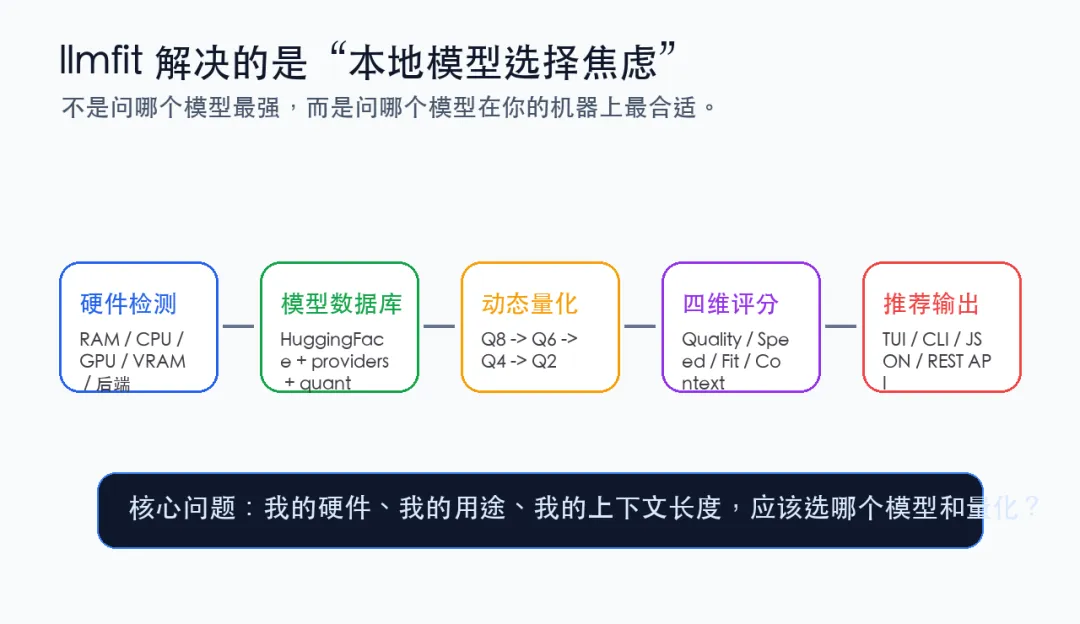
它会自动检测硬件,然后把模型按综合评分排序。
每一行会显示:
-
模型名 -
综合分 -
预估 tok/s -
最佳量化 -
运行模式 -
内存占用 -
fit 等级 -
用途分类
支持的本地运行时也很全:
-
Ollama -
llama.cpp -
MLX -
Docker Model Runner -
LM Studio -
vLLM
对 Apple Silicon、多 GPU、MoE 架构、动态量化也有专门处理。
先看它长什么样
默认启动就是 TUI:
llmfit项目自带的演示动图大概是这样的:

你可以像在 Vim 里一样操作:
j / k 上下移动/ 搜索模型f 切换 fit 过滤s 切换排序字段S 硬件模拟A 高级配置b 社区性能榜I 本机推理 benchmarkd 下载选中模型D 下载管理器这个设计很适合本地模型玩家。
因为选模型这件事,本质上就是不断过滤、对比、试算。
TUI 比一堆命令更顺手。
安装方式
macOS / Linux 推荐 Homebrew:
brew install AlexsJones/llmfit/llmfit或者:
brew install llmfit快速安装:
curl -fsSL https://llmfit.axjns.dev/install.sh | sh安装到本地目录,不需要 sudo:
curl -fsSL https://llmfit.axjns.dev/install.sh | sh -s -- --localPython / uv 用户:
uv tool install -U llmfit不安装直接跑:
uvx llmfitDocker:
docker run ghcr.io/alexsjones/llmfit源码构建:
git clone https://github.com/AlexsJones/llmfit.gitcd llmfitcargo build --release它怎么判断“适合”?
llmfit 不是只看显存够不够。
它会做四维评分:

四个维度分别是:
QualitySpeedFitContextQuality 看模型质量。
包括参数量、模型家族、任务匹配、量化损失。
Speed 看速度。
它会根据后端、模型大小、量化方式估算 tok/s。
Fit 看内存适配。
不是占得越满越好,而是寻找一个舒服区间。README 里写到的甜点区是 50%-80%。
Context 看上下文。
不同用途对上下文窗口的需求不同。
最后把四个维度按用途加权。
比如:
Chat 更看速度。
Reasoning 更看质量。
Embedding 更看吞吐和适配。
这比简单看“参数越大越好”靠谱多了。
动态量化:从 Q8 往下试
本地模型选择里,量化非常关键。
同一个模型,Q8、Q6、Q4、Q2 的体积、速度、质量都不同。
llmfit 的做法是:
从高质量量化开始试。
如果不适配,再往更压缩的量化下探。
README 里写的是:
Q8_0 -> Q2_K它会选择你的硬件能装下的最高质量量化。
如果完整上下文放不下,还会用半上下文再试。
这就是一个很实际的体验。
因为我们平时选 GGUF 时,最烦的就是:
Q4_K_M 能不能跑?Q5 会不会爆?Q8 值不值得?llmfit 把这件事自动算了一遍。
速度估算:不是玄学,是显存带宽
README 里有一段很关键。
LLM 推理的 token 生成,很多时候是 memory-bandwidth-bound。
也就是说,每生成一个 token,都要从显存里读一遍模型权重。
所以 llmfit 用一个很直观的公式估算速度:
(bandwidth_GB_s / model_size_GB) × efficiency_factor默认 efficiency factor 是:
0.55这个系数用来考虑 kernel overhead、KV-cache 读取、内存控制器等实际损耗。
如果你的 GPU 被识别,它会用显存带宽查表。
如果没识别,就按后端常数回退。
比如 README 里列了 CUDA、Metal、ROCm、SYCL、CPU ARM、CPU x86、Ascend 等后端常数。
这说明它不是随便拍一个 tok/s。
它至少把“模型大小”和“硬件带宽”这两个关键变量放进去了。
硬件模拟:买显卡前先试算
llmfit 里我最喜欢的是硬件模拟。
在 TUI 里按:
S就能打开模拟弹窗,覆盖 RAM、VRAM、CPU 核心数。
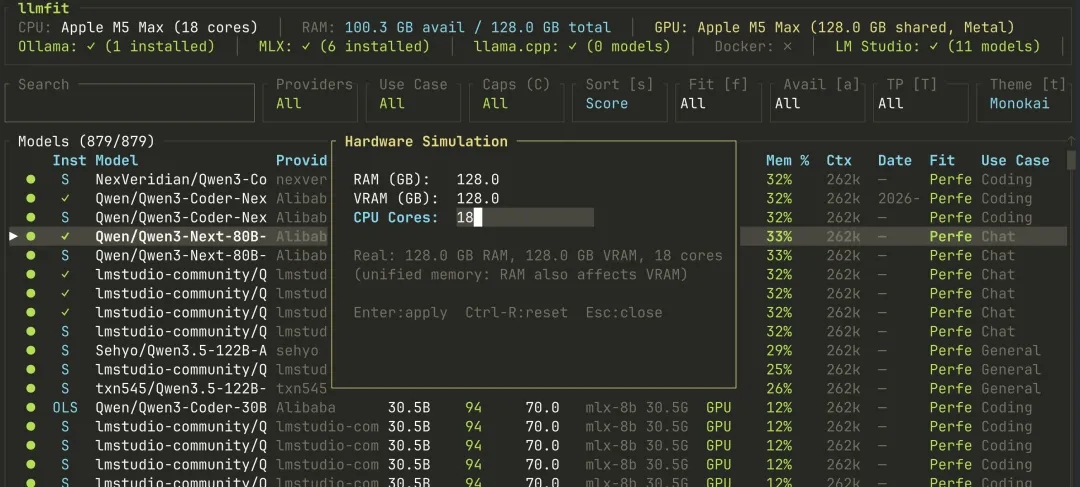
这件事很适合两个场景。
第一,你准备升级机器。
比如现在是 16GB 显存,想知道 24GB、32GB、48GB 会多跑哪些模型。
第二,你要给团队配置机器。
不用先买硬件再试。
先模拟一下目标配置,看看能否覆盖团队需要的模型和上下文。
这比在评论区问“4070 Ti Super 能不能跑 32B”高效很多。
社区榜单:看别人真实跑出来的数据
理论估算永远有偏差。
所以 llmfit 还加了 Community Leaderboard。
在 TUI 里按:
b可以看真实用户提交的性能数据:
-
tok/s -
TTFT -
peak VRAM -
engine -
quant -
context -
hardware
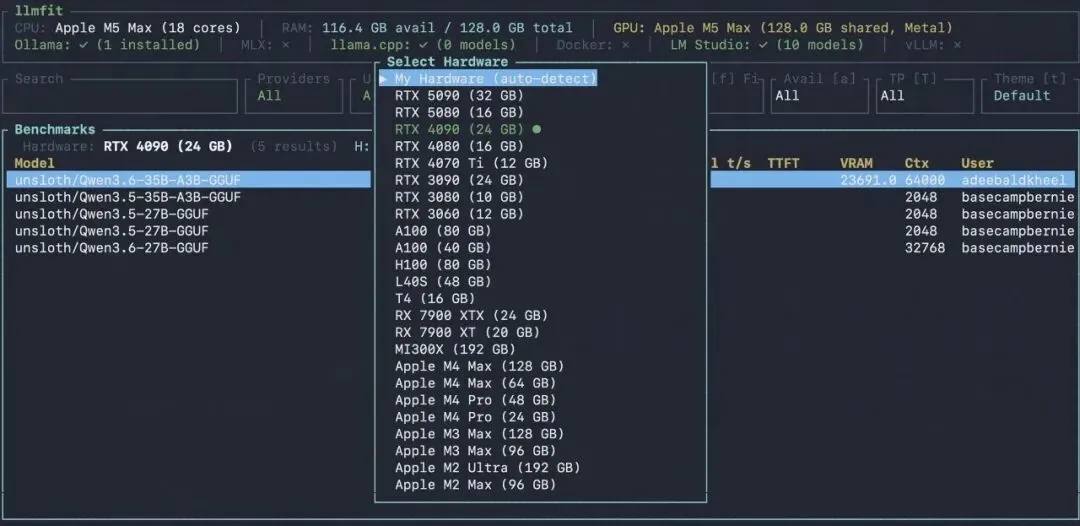
数据来源是 localmaxxing.com。
这很关键。
因为本地模型体验经常不是“能不能跑”这么简单。
同一个模型,不同引擎、不同量化、不同上下文、不同显卡,体验差异很大。
有社区真实数据,就能把理论估算和实际表现接起来。
还能跑本机 benchmark
除了看别人数据,llmfit 也能测你自己的本地提供商。
按:
I或者 CLI:
llmfit bench可以自动检测 Ollama、vLLM、MLX,跑真实推理 benchmark。
常用命令:
llmfit bench --allllmfit bench --provider ollama llama3.2llmfit bench --provider vllm --url http://localhost:8000llmfit bench --json结果会包含:
-
TTFT -
TPS -
total latency
还会缓存到:
~/.config/llmfit/bench-cache.json这就比较完整了。
先用估算筛掉明显不合适的模型。
再用本机 benchmark 验证候选模型。
适合脚本和 Agent 调用
llmfit 不只是 TUI。
它也支持 JSON 输出:
llmfit recommend --json --limit 5按用途过滤:
llmfit recommend --json --use-case coding --limit 3查看硬件:
llmfit --json system规划某个模型需要什么硬件:
llmfit plan "Qwen/Qwen3-4B-MLX-4bit" --context 8192 --json还可以启动 REST API:
llmfit serve --host 0.0.0.0 --port 8787查询节点硬件:
curl http://localhost:8787/api/v1/system拿 top 模型:
curl "http://localhost:8787/api/v1/models/top?limit=5&min_fit=good&use_case=coding"这对 Agent 很有用。
比如你有一台机器,Agent 想部署本地模型。
它可以先问 llmfit:
这台机器上 coding 用途最适合跑哪个模型?而不是硬编码一个模型名。
也要注意边界
llmfit 很实用,但它不是模型质量评测平台。
它回答的是:
在我的硬件和用途下,哪些模型更适合跑?不是:
哪个模型绝对最聪明?另外,速度估算依赖硬件识别、带宽表、模型参数、量化和上下文假设。
真实表现还会受:
-
prompt 长度 -
batch size -
KV cache -
runtime 版本 -
驱动版本 -
散热和功耗墙 -
后台负载
影响。
所以正确姿势是:
用 llmfit 做候选筛选再用 bench 做本机验证最后用真实任务做质量测试小结
llmfit 最打动我的地方,是它把一个混乱问题变成了工程问题。
过去我们选本地模型,靠榜单、帖子、评论、经验和试错。
现在它把硬件、模型、量化、上下文、速度、用途放到同一张表里。
这件事很朴素,但很必要。
本地大模型时代,真正的问题不是“能不能下载更多模型”。
而是:
在这台机器上,我应该跑哪个?llmfit 给了一个挺干净的答案。
参考资料:
-
llmfit GitHub: https://github.com/AlexsJones/llmfit -
localmaxxing: https://localmaxxing.com -
Crates.io: https://crates.io/crates/llmfit