 夜雨聆风
夜雨聆风





让文档解析大模型提速 4.89*:一种无需训练的推理加速方法
近年来,文档解析技术正在经历一场范式转变:从传统的 pipeline 方法,逐步走向基于视觉语言模型(VLM)的端到端方案。这类方法能够直接从文档图像生成结构化文本,在语义理解、复杂结构解析等方面表现出显著优势。
但与此同时,一个几乎不可避免的问题也逐渐凸显出来——速度变慢了。
问题的根源其实很简单:当前主流 VLM 采用的是自回归生成机制,也就是一个 token 一个 token 地往外生成。而文档解析任务本身往往包含大量文本、表格和公式,输出序列动辄成百上千 token。结果就是,推理时间几乎随着输出长度线性增长,长文档尤其明显。这也让高精度模型在真实场景中很难“跑得动”。
从“逐字生成”到“批量验证”

这篇工作给出的解决思路并不复杂,但非常巧妙:让模型少走弯路。
具体来说,它引入了一种叫做 speculative decoding 的机制。可以把它理解为一种“先猜后验”的策略:先由一个轻量模型快速生成一段“草稿”,然后再由大模型一次性对多个 token 进行验证。如果草稿是对的,就直接跳过这些生成步骤;如果有问题,再从错误位置继续生成。
这样一来,原本必须逐 token 进行的生成过程,就被改造成了“多 token 批量推进”。解码步数减少,整体速度自然就提上来了。
利用文档结构:从一维序列到二维并行
如果只是简单套用 speculative decoding,其实提升是有限的。真正让这篇工作变得有意思的,是它进一步利用了文档本身的结构特性。
作者提出了一种分层推测解码(Hierarchical Speculative Decoding)的设计,将推理过程拆成两个阶段。
在第一阶段,模型不再把整页文档当作一个整体,而是先通过版面分析,将页面划分为多个语义区域,例如段落、表格、公式等。每一个区域都可以被看作一个相对独立的小任务,于是可以并行执行 speculative decoding。这一步的关键价值在于:把原本串行的问题,变成了并行问题。
不过,仅靠区域级处理是不够的。因为每个区域缺乏全局上下文,很容易在阅读顺序、跨区域逻辑等方面出现不一致。
因此,第二阶段引入了一次全局校正。具体做法是,把第一阶段得到的所有结果重新拼接成页面级“草稿”,然后再进行一次整页级别的验证。这一步通常只需要很少的推理步骤,却能够有效修正前面阶段的误差,从而保证最终输出的整体一致性。
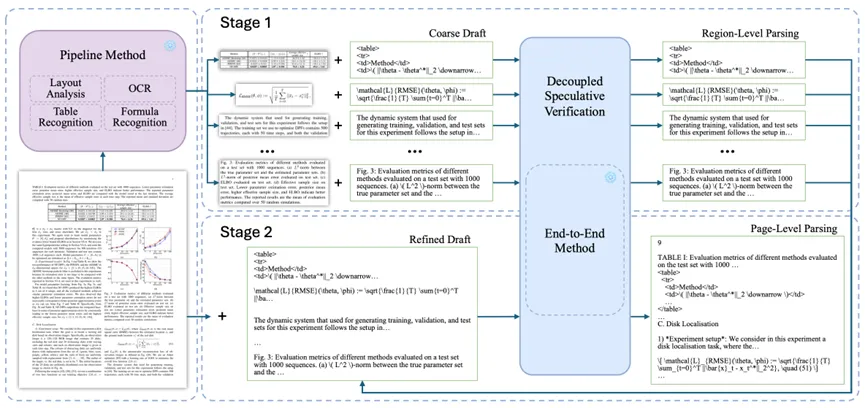 图 1端到端文档解析层级推测解码框架总览。轻量级流水线首先执行版面分析并生成固定的区域草稿;第一阶段通过解耦推测验证(DSV)对裁剪后的区域进行并行解析,得到验证后的输出结果;第二阶段将这些结果聚合为页面级草稿,并通过一次全页面 DSV 验证完成最终解析。DSV 融合了窗口对齐与树状结构验证,可在单个并行多令牌步骤中评估多个草稿候选方案。
图 1端到端文档解析层级推测解码框架总览。轻量级流水线首先执行版面分析并生成固定的区域草稿;第一阶段通过解耦推测验证(DSV)对裁剪后的区域进行并行解析,得到验证后的输出结果;第二阶段将这些结果聚合为页面级草稿,并通过一次全页面 DSV 验证完成最终解析。DSV 融合了窗口对齐与树状结构验证,可在单个并行多令牌步骤中评估多个草稿候选方案。
真正的难点:如何一次验证多个候选?
在实现层面,这个方法的关键不只是“猜和验”,而是如何高效地同时验证多个候选序列。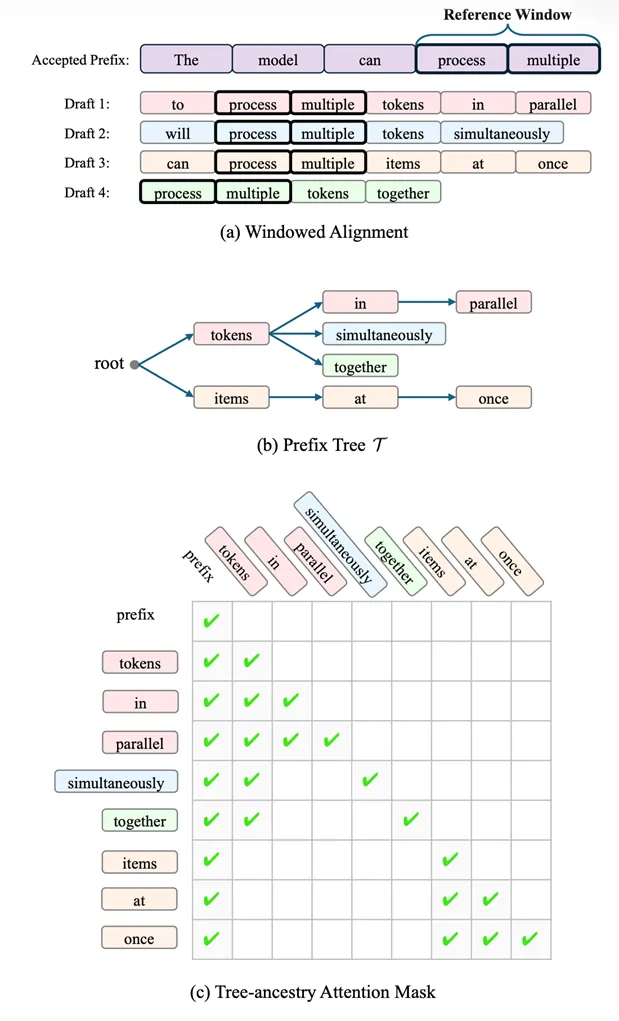 作者为此设计了一套非常精巧的机制。
作者为此设计了一套非常精巧的机制。
首先,通过一个滑动窗口,将当前已经生成的序列与草稿进行对齐,从而定位哪些位置可以继续验证。接着,将所有可能的候选序列组织成一棵前缀树,把共享的前缀合并在一起。这样一来,不同候选之间的重复计算就被消除了。在此基础上,再构造一种特殊的 attention mask,使得每个 token 只能关注当前前缀以及其“祖先路径”。这样就可以在一次前向计算中,同时验证整棵树上的多个候选路径,从而实现真正意义上的“并行验证”。
实验结果:不仅更快,而且几乎不降精度

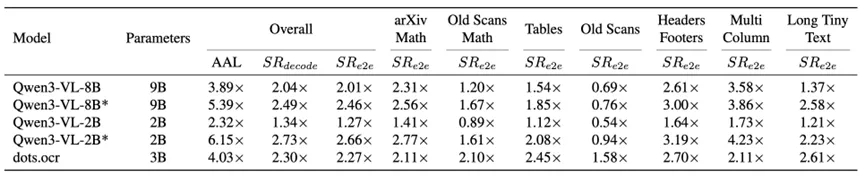
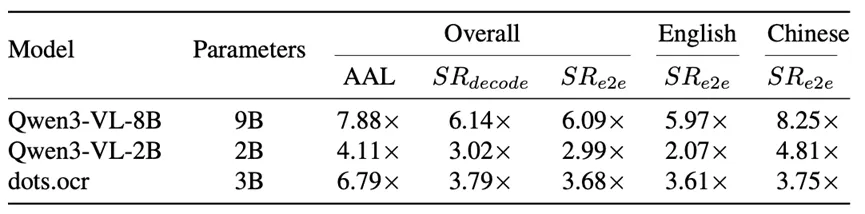 在三个主流文档解析基准(OmniDocBench、olmOCR-Bench 和 Ocean-OCR-Bench)上,这一方法都表现出了稳定而显著的加速效果。
在三个主流文档解析基准(OmniDocBench、olmOCR-Bench 和 Ocean-OCR-Bench)上,这一方法都表现出了稳定而显著的加速效果。
以 dots.ocr 这一当前主流模型为例,其端到端推理速度在不同数据集上分别达到了 2.42×、2.27× 和 3.68× 的提升,在长文档场景下甚至可以达到 4.89×。
更关键的是,这种加速几乎没有带来精度损失。实验表明,最终结果与 baseline 持平,甚至在部分指标上略有提升。这一点非常重要,因为很多推理加速方法往往以牺牲精度为代价,而这项工作基本做到了“又快又准”。
加速效果从哪里来?
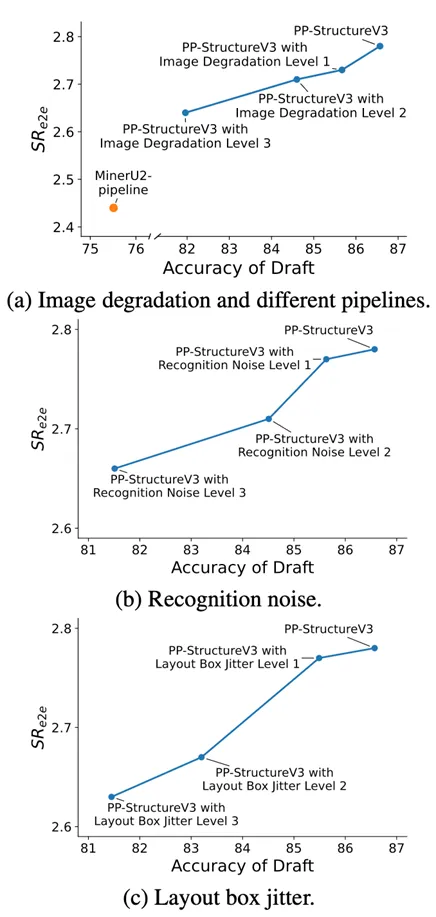 图2 不同扰动下草稿质量对加速比的影响。草稿质量通过其在 OmniDocBench v1.5 基准上的得分来衡量。
图2 不同扰动下草稿质量对加速比的影响。草稿质量通过其在 OmniDocBench v1.5 基准上的得分来衡量。
进一步分析可以发现,加速效果主要受到三个因素影响。
首先是草稿质量。草稿越准确,被大模型接受的 token 就越多,从而能够跳过更多生成步骤。不过即便在草稿质量下降的情况下,该方法仍然能够保持较高的加速比,表现出不错的鲁棒性。
其次是文档类型。结构规整的文档,例如财务报表或标准论文,往往更容易生成高质量草稿,因此加速效果更明显。而在手写文本或复杂排版场景下,加速收益会有所下降。 最后是文档长度。短文档由于前处理开销占比较高,加速空间有限;而长文档则可以充分发挥 speculative decoding 的优势,实现更明显的性能提升。
值得一提的是,该方法在中英文场景下表现一致,说明其具有良好的语言无关性。
精度分析
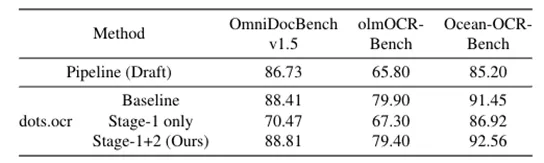 实验结果表明:Stage 1 单独使用会降低精度Stage 2 可恢复甚至提升性能 最终结果:与 baseline 持平甚至略优,说明该方法实现了:高效推理 + 准确解析 的统一。
实验结果表明:Stage 1 单独使用会降低精度Stage 2 可恢复甚至提升性能 最终结果:与 baseline 持平甚至略优,说明该方法实现了:高效推理 + 准确解析 的统一。
一个很“工程化”的好思路
从更高的视角来看,这篇工作的价值不只是提出了一个技巧,而是提供了一种思路:不改变模型结构,不依赖额外训练,仅通过推理策略优化性能。它本质上是在重新设计“生成过程”本身。
通过把串行生成变为并行验证,再结合文档天然的二维结构,这项工作成功绕开了自回归模型的核心瓶颈。这种思路不仅适用于文档解析,对于其他长序列生成任务也具有启发意义。
文章总结
这篇论文的核心贡献可以概括为一句话: 在不改模型的前提下,通过分层推测解码,将文档解析的推理效率提升到一个新的水平。
它证明了一件很重要的事情: 在大模型时代,性能优化不一定只靠更大的模型或更多的数据,对推理过程本身的设计,同样可以带来数量级的提升。
文章名称:Training-Free Acceleration for Document Parsing Vision-Language Model with Hierarchical Speculative Decoding
文章链接:https://arxiv.org/pdf/2602.12957
END
撰稿:万金鹏
编排:张雪莹
审校:刘禹良
发布:连宙辉
免责声明:
(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。
(2)本文观点不代表本公众号立场。
往期文章分享:
新一代多模态大模型OCR能力测评基准OCRBench v2,英文测试中58个模型仅2个达60分及格线,表明OCR任务仍是重大挑战

征稿启事:
本公众号将不定期介绍文档图像分析与识别及相关领域的论文、数据集、代码等成果,欢迎自荐或推荐相关领域最新论文/代码/数据集等成果给本公众号审阅编排后发布 (联系Email: eelwjin@scut.edu.cn)。
加入学会:
获取最新OCR资讯: