 夜雨聆风
夜雨聆风





深度解析:Claude Code 源码
本文以《深度解析:Harness Engineering》为理论支点,通过 codex 对 npm claude-code-2.1.88.tgz 压缩包中的 cli.js.map 逆向源码进行深度分析,整理成此文。
注:本文并不可作为 Agent 架构设计指导,源码解析仅供学习参考。对源码交流群感兴趣的朋友,可在公众号私信 cc 获取。

关于 Claude Code 源码泄漏的八卦这里就不讨论了,可以肯定的是这份源码很有分量,因为目前在 npm 发版历史中已经找不到 v2.1.88 了。
正式开始前,先来个小插曲,Andrej Karpathy 在最近的推文中提到 ”LLM 知识库“就是对 Harness 的一个侧面注解。比如:把状态持续沉淀成工件,on-the-loop 等。原推文:
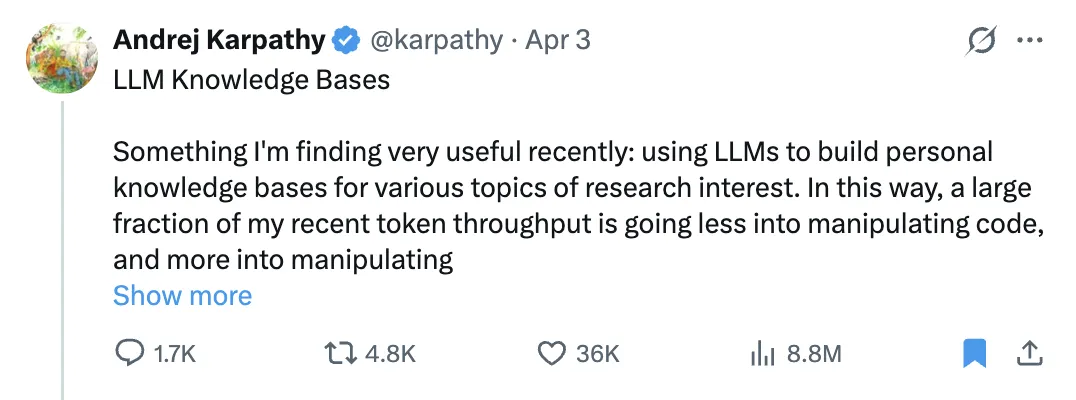
我最近发现一件非常有用的事:用 LLM 为自己感兴趣的研究主题构建个人知识库。这样一来,我最近消耗的大量 token,就不再主要用于处理代码,而是更多用于处理知识本身(以 markdown 和图片的形式存储)。最新一代的 LLM 在这件事上已经做得相当不错。所以:
数据摄取:我会先把源文档(文章、论文、仓库、数据集、图片等等)索引到一个 raw/ 目录里,然后再用 LLM 逐步“编译”出一个 wiki。本质上,它就是按目录结构组织起来的一组 .md 文件。这个 wiki 会包含 raw/ 中所有数据的摘要、反向链接,然后再把这些数据归类到不同概念之下,为这些概念撰写条目,并把它们彼此链接起来。把网页文章转成 .md 文件时,我喜欢用 Obsidian Web Clipper 扩展;同时我还会用一个快捷键,把相关图片全部下载到本地,这样 LLM 就能更方便地引用它们。
IDE:我把 Obsidian 当作 IDE 的“前端”,在里面查看原始数据、编译后的 wiki,以及衍生出的各种可视化结果。这里有一点很重要:wiki 中的所有数据,基本都是由 LLM 负责撰写和维护的,我自己很少直接去碰它。我也试过一些 Obsidian 插件,用不同方式来渲染和查看这些数据,比如用 Marp 来做幻灯片。
问答:真正有意思的是,一旦你的 wiki 足够大了(比如我最近某个研究主题的 wiki,大概有 100 篇文章、40 万字),你就可以让 LLM agent 围绕这个 wiki 回答各种复杂问题,它会自己去查找、研究并组织答案。原本我以为得上更复杂的 RAG 方案,但在这种“小规模”下,LLM 自己维护索引文件和各文档简要摘要的能力已经相当不错,也能比较轻松地读完所有关键相关数据。
输出:相比直接在文本界面或终端里拿答案,我更喜欢让它帮我生成 markdown 文件、幻灯片(Marp 格式)或者 matplotlib 图片,然后我再回到 Obsidian 里查看。当然,根据查询内容,也完全可以想象出更多别的可视化输出形式。很多时候,我最终还会把这些输出重新“归档”回 wiki 中,进一步增强它,以便支持后续查询。这样一来,我自己的探索和提问,都会不断沉淀进知识库里,形成积累。
Lint / 健康检查:我还会让 LLM 对整个 wiki 跑一些“健康检查”,比如找出不一致的数据、补全缺失的信息(借助网页搜索工具)、发现一些有趣的联系并建议可以新增哪些条目等等,从而逐步清理 wiki、提升整体数据完整性。LLM 在提示你还应该继续问什么、往哪些方向深入这件事上,也表现得相当不错。
额外工具:我发现自己也在不断开发一些额外工具来处理这些数据。比如,我随手 vibe code 了一个小而简陋的 wiki 搜索引擎,我既会直接用它(通过一个 web UI),但更多时候,我会把它作为 CLI 工具交给 LLM 调用,用于处理更大规模的查询任务。
进一步探索:随着仓库不断变大,一个很自然的想法就是:是否可以结合合成数据生成和微调,让 LLM 直接把这些数据“学进权重里”,而不仅仅是依赖上下文窗口来读取它们。
TL;DR:来自若干源头的原始数据先被收集起来,再由 LLM 编译成一个 .md wiki,随后 LLM 通过各种 CLI 工具对它进行问答和持续增强,而所有这些内容都可以在 Obsidian 中查看。你几乎不再需要手动撰写或编辑这个 wiki,它基本上成了 LLM 的工作领域。我觉得,这里面完全有机会长出一个惊人的新产品,而不只是现在这种拼拼凑凑、带点 hack 味道的脚本集合。
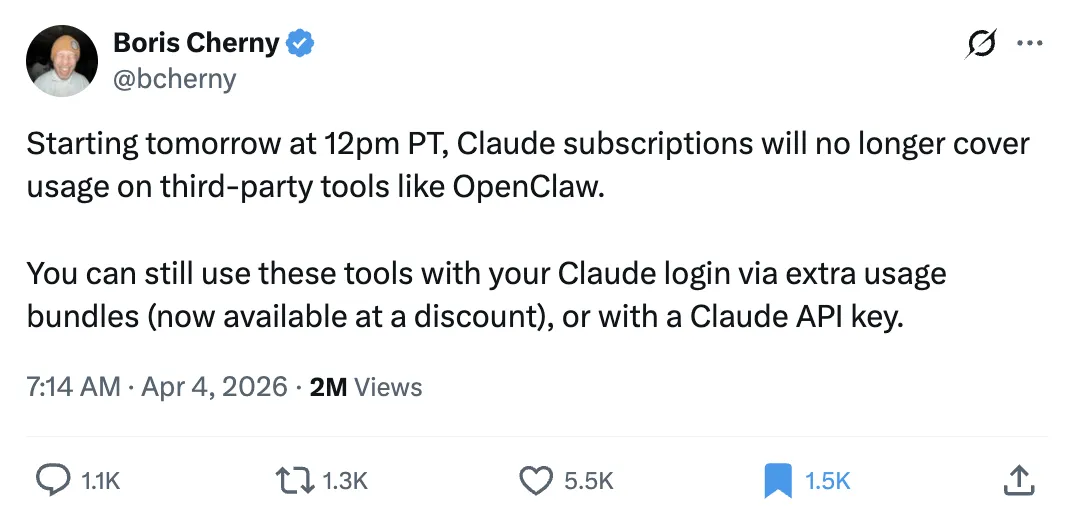
另外一条消息则是彻底封杀 OpenClaw:Anthropic 表示,从明天太平洋时间中午 12 点起,Claude 订阅将不再覆盖 OpenClaw 等第三方工具中的使用量;用户之后若仍想通过 Claude 账号在这些工具里继续使用服务,需要额外购买打折后的 usage bundles,或直接使用 Claude API key。官方同时说明,现有订阅用户会获得一次性补偿额度,金额等同于当月订阅费用;若不接受这一调整,也可通过次日邮件中的链接申请全额退款。Anthropic 给出的理由是,希望更有节制地管理增长,以便长期、可持续地服务客户。
阅读边界
这份材料来自 source map 反解后的源码,不是按作者架构意图整理过的正式文档。因此,阅读时最需要防止的,不是“看漏模块”,而是把生产系统为了兼容历史、修补断裂、维持线上可恢复性而追加的补偿机制,误抄成 agent runtime 的理想蓝图。
这份代码更适合被当成三类材料同时阅读:
- 约束样本:真正无法回避的 runtime 约束会反复浮现,例如
tool_use -> tool_result不能断、prompt cache prefix 不能漂、能力面不能一次性敞开、子代理必须可恢复。 - 病理切片:某些最“惊艳”的实现,首先说明底层边界已经破过一次,例如
progressBridge、applySnipRemovals、recoverOrphanedParallelToolResults、synthetic continuation、orphaned permission replay。 - 反证材料:当
attachments.ts演化成第二调度器、ToolUseContext过胖、continuity ownership 分散、恢复协议依赖 JSON 键顺序时,真正重要的信息不是“补得真巧”,而是这些边界原本就不该如此耦合。
全文默认沿四个过滤器阅读源码:
principleworkaroundlegacy bridgedebt
真正值得迁移到未来 agent 设计里的,主要是 principle,以及少量已经被证明有效的 workaround;legacy bridge 与 debt 更适合作为警报,而不是模板。
理论支点:Harness Engineering
本文的底层分析框架并不是“按目录讲源码”,而是沿着 Harness Engineering 去识别一套 agent 外循环系统。
那份方法论里有两条判断,对这份源码尤其关键:
- 评估的对象不是模型单体,而是
model + harness:因此,这份报告关心的不是 Claude 自身多聪明,而是围绕它搭出来的外循环如何持久化状态、裁剪上下文、暴露能力、拦截风险、恢复轨迹、调度异步执行体。 - 真正的难点不在单步推理,而在 durable state、tool mediation、feedback loops、legibility、human boundary:这恰好对应到这份源码里最厚、也最容易被低估的几层:transcript 与 sidecar、Tool/ToolSearch/REPL、permissions/hooks/classifier、attachments/task output/SDK projection、coordinator/mailbox/remote agent。
因此,下面的“总/分”结构不是为了排版,而是为了让源码现象和 Harness Engineering 的几个核心构件对齐:
- 总篇:先把这套 harness 的总体蓝图画出来,明确有哪些控制面、状态载体和执行底座。
- 分篇:再逐层下潜到源码实现,看 durable state、tool mediation、policy plane、feedback loops、task substrate 在代码里分别落在哪里。
- 收束:最后再区分哪些属于 principle,哪些只是 workaround、legacy bridge、debt。
换句话说,这篇报告不是把 Harness Engineering 当成背景引文挂在角落,而是把它当成识别源码结构的理论支点。
总篇:Runtime Blueprint
1. 这份系统真正维护的是四条不变量
把 claude-code/src 源码按目录阅读,很容易被拆散成 query / compact / tools / memory / skills / agent 几个平铺模块。按这种方式阅读,得到的是功能清单;运行时秩序看不见。
真正把这套系统撑起来的,不是模块目录,而是四条同时成立的不变量:
- 轨迹拓扑不能破:一个 assistant 轨迹里,
tool_use不能悬空;thinking block 不能在错误的边界被切断;错误恢复不能把 SDK 暴露到半成品状态。 - 缓存前缀不能漂:一旦某段内容已经被模型看过,后续轮次里它的命运就被冻结了。该替换的永远以同一字节串替换,不该替换的永远不能补替换;工具顺序、子代理前缀、
cache_edits插入位置都围绕这条约束收敛。 - 能力面不能一次性敞开:工具、MCP、skill、REPL primitive、agent 能力都不是全部预加载,而是分层暴露、延迟发现、按路径/时机激活。能力可见性本身就是上下文治理的一部分。
- 连续性不能只寄托在 transcript 上:
messages只是连续性的一层。真正稳定的连续性分散在CLAUDE.md、nested memory、MEMORY.md、daily logs、session memory、task state、sidechain transcript、content replacement records 这些外化工件上。
这四条不变量分别由不同模块共同维护:
query.ts维护轨迹拓扑与恢复图。toolResultStorage.ts、microCompact.ts、tools.ts、fork 逻辑维护缓存前缀稳定性。Tool.ts、toolExecution.ts、ToolSearchTool、REPL、loadSkillsDir.ts维护能力面可见性。attachments.ts、claudemd.ts、memdir/*、SessionMemory/*、sessionStorage.ts、runAgent.ts维护连续性外化。
从这个角度再回看那些“亮点实现”,价值就更清楚了:值得迁移的不是某个函数,而是它在替哪条不变量付账。
2. 总体结构:一个循环外套着多个调度面
最外层结构可以先抽成下面这张图:
用户输入 -> attachments 聚合 -> query while(true) -> context shaping -> model streaming -> tool mediation -> recovery / continue / stop -> transcript / sidechain / tasks 持久化并行存在的调度面:1. capability surface tools / deferred tools / REPL virtual tools / skills / agent definitions2. continuity surface CLAUDE.md / nested memory / MEMORY.md / session memory / sidechain logs3. cache surface contentReplacementState / cached microcompact / tool ordering / fork prefixquery.ts 是编排中心,但不是唯一调度器。真正的运行时控制同时散布在:
query.tsattachments.tstoolExecution.tstoolResultStorage.tsmicroCompact.tsrunAgent.tssessionStorage.ts
如果继续拆细,它至少又能分出七条一等控制面:
- 宿主控制面:
QueryEngine.ts、CLI/SDK/REPL 入口,负责 turn 之外的会话寿命、投影、结果封装、headless 行为。 - turn 控制面:
query.ts,负责一轮 agentic turn 内部的状态机、恢复图、错误分流、工具回合推进。 - 能力控制面:
Tool.ts、tools.ts、ToolSearch、REPL、skills、agent definitions,负责模型“此刻能看到什么能力”。 - 策略控制面:permissions、hooks、policy limits、classifier,负责模型“即使想做,也是否允许这样做”。
- 连续性控制面:
CLAUDE.md、nested memory、MEMORY.md、daily logs、session memory、transcript、sidechain transcript,负责过去如何带到下一轮。 - 缓存控制面:
toolResultStorage.ts、microCompact.ts、工具排序、fork 前缀复制,负责 prompt cache prefix 稳定性。 - 执行底座:task registry、coordinator、subagent、remote agent、mailbox,负责异步执行体如何存在、被追踪、被恢复、被终止。
也正因为如此,这套系统的亮点和缺陷都不在单模块内部,而在跨模块耦合处。
3. 主流程不是“问模型一次”,而是“不断修正同一条轨迹”
系统的主流程可以压成下面这条线:
用户输入 -> processUserInput -> transcript 先落盘 -> attachments / context injection -> query loop -> 采样 -> 工具 -> permission / hook / classifier -> compact / retry / continue -> result projection -> transcript / sidechain / task output 持久化这条线里最重要的不是模型“采样”,而是每一步都在维护几个不变量:
tool_use不能悬空- 已见内容的命运不能反悔
- 能力面不能暴露过量
- 连续性不能只压在 transcript 上
- 异步执行体必须能被追踪、恢复、终止
这条线在运行时又落到四类核心状态载体上:
mutableMessages/messages:当前会话视图。不是唯一真相,但仍是大部分 turn 逻辑的主干。AppState:跨模块共享的宿主总线。UI、tasks、permissions、MCP、plugins、agent definitions、todo、diagnostics 都会落到这里。ToolUseContext:tool runtime 的能力总线。工具池、read file cache、AppState bridge、notification、task hooks、memory triggers 都从这里渗透进工具执行。- 持久化 sidecar:transcript JSONL、task output files、remote agent metadata、content replacement records、memory files。真正的续航不靠单一
messages数组,而靠这批外化工件。
这四类载体之间没有清晰一对一 owner。这既是系统的生产性来源,也是后文结构债的源头。后面的“分篇”就围绕这几条线索展开。
分篇一:宿主与主循环
1. QueryEngine.ts 不是内核,它是会话宿主
query.ts 解决的是“一轮 turn 如何推进”,QueryEngine.ts 解决的是“这套 turn engine 如何成为 SDK/headless 可用的会话接口”。
源码开头的类定义已经把职责写得很明确:
exportclass QueryEngine { private mutableMessages: Message[] private abortController: AbortController private permissionDenials: SDKPermissionDenial[] private totalUsage: NonNullableUsage private hasHandledOrphanedPermission = false private readFileState: FileStateCache private discoveredSkillNames = new Set<string>() private loadedNestedMemoryPaths = new Set<string>()}这几个字段说明 QueryEngine 拥有的不是“当前一步推理”,而是 conversation host:
- 跨 turn 的消息视图
- 累计 usage
- file cache
- orphaned permission 状态
- nested memory / skill discovery 的宿主持有
真正关键的是,它坚持在进入 query() 前先把用户消息落进 transcript:
// Persist the user's message(s) to transcript BEFORE entering the query loop.if (persistSession && messagesFromUserInput.length > 0) {const transcriptPromise = recordTranscript(messages) ...}这一步保证的是宿主级不变量:用户消息一旦被接受,就先进入可恢复轨迹,哪怕 API 还没开始返回。
真正进入 query() 之前,QueryEngine 还会把宿主壳一次性装好:
constprocessUserInputContext: ProcessUserInputContext = { canUseTool: this.config.canUseTool, getUpdatedContext: () => ({ commands, tools, agents, mcpClients,discoveredSkillNames: this.discoveredSkillNames,loadedNestedMemoryPaths: this.loadedNestedMemoryPaths, ... }),}const systemPrompt = asSystemPrompt([ ...(customPrompt !== undefined ? [customPrompt] : defaultSystemPrompt), ...(memoryMechanicsPrompt ? [memoryMechanicsPrompt] : []), ...(appendSystemPrompt ? [appendSystemPrompt] : []),])这说明它真正负责的是会话级装配:
processUserInput- system prompt parts
- memory mechanics prompt
- plugins cache-only preload
- nested memory / discovered skills 的跨 turn 持有
也就是说,QueryEngine 不只是把 prompt 转给 query.ts,而是在不同宿主模式下,拼出一份真正可运行的 runtime surface。
同一层还负责 orphaned permission 的 delayed continuation。收到外部 permission response 后,逻辑不是直接执行工具,而是先把原始 assistant tool_use 补回 mutableMessages / transcript,再继续执行:
if (!alreadyPresent) { mutableMessages.push(assistantMessage)if (persistSession) {awaitrecordTranscript(mutableMessages) }}这里的关注点不是权限 UI,而是轨迹拓扑。如果 tool_result 落地时前面的 tool_use 没被补回去,resume 得到的会是一条悬空结果。
2. QueryEngine 同时也是宿主协议适配器
query() 内部产出的消息很多,QueryEngine 并不原样透传,而是做宿主投影:
- 内部
Message投成 SDK 事件 - 内部 system message 挑选后再暴露
- terminal result 在这一层统一收口
这一层的投影逻辑本身也很具体:
switch (message.type) { case 'assistant':this.mutableMessages.push(message)yield* normalizeMessage(message)break case 'progress':this.mutableMessages.push(message)if (persistSession) { messages.push(message)voidrecordTranscript(messages) }yield* normalizeMessage(message)break case 'system':if (message.subtype === 'compact_boundary') {yield {type: 'system',subtype: 'compact_boundary',compact_metadata: toSDKCompactMetadata(message.compactMetadata), } }break}注意这里的“投影”不是 cosmetic 层:
- progress 既进入本地可变消息,又可能被持久化
- compact boundary 会被翻译成 SDK 专用结构
- terminal result 只在这一层收口,
query.ts本身并不懂 SDK envelope
headless 模式还有一个 REPL 没有的差异:snip replay 会真的裁掉本地 mutableMessages,而不是只做 UI 投影。这意味着 SDK 路径优先控制长会话内存,而 REPL 路径优先保留 scrollback。
对应实现是:
// Snip boundary: replay on our store to remove zombie messages and// stale markers. The yielded boundary is a signal, not data to push —// the replay produces its own equivalent boundary. Without this,// markers persist and re-trigger on every turn, and mutableMessages// never shrinks (memory leak in long SDK sessions). The subtype// check lives inside the injected callback so feature-gated strings// stay out of this file (excluded-strings check).const snipResult = this.config.snipReplay?.( message, this.mutableMessages,)if (snipResult !== undefined) { if (snipResult.executed) {this.mutableMessages.length = 0this.mutableMessages.push(...snipResult.messages) } break}这条分叉很重要,因为它说明宿主差异不只体现在 UI,而体现在本地状态模型本身:REPL 保住 scrollback,headless 保住内存占用。
structured output 也不是普通工具增强,而是宿主输出契约。
QueryEngine 先注册 Stop hook:
addFunctionHook( setAppState, sessionId,'Stop','',messages =>hasSuccessfulToolCall(messages, SYNTHETIC_OUTPUT_TOOL_NAME),`You MUST call the ${SYNTHETIC_OUTPUT_TOOL_NAME} tool to complete this request. Call this tool now.`, { timeout: 5000 },)再把外部 JSON schema 编译成 AJV 校验过的 SyntheticOutputTool。这里的结构不是“最后 parse 一下 JSON”,而是:
- 宿主先声明“必须结构化结束”
- 再把 schema 编译成一次性工具契约
- query loop 在这个契约之下继续运行
这比“模型直接输出 JSON,再赌解析成功”严格得多。
合成工具的关键实现也值得直接看:
const validateSchema = ajv.compile(jsonSchema)async call(input) { const isValid = validateSchema(input) if (!isValid) {throw new TelemetrySafeError_I_VERIFIED_THIS_IS_NOT_CODE_OR_FILEPATHS(`Output does not match required schema: ${errors}`, ..., ) } return {data: 'Structured output provided successfully',structured_output: input, }}这里把“输出必须满足 schema” 前移成了工具执行期约束,而不是后置解析约束。对于生产接口来说,这是本质差别。
3. query.ts 不是 linear pipeline,而是恢复图
query.ts 的形状并不是“采样 -> 工具 -> 返回”。
typeState = { messages: Message[] toolUseContext: ToolUseContext autoCompactTracking: AutoCompactTrackingState | undefined maxOutputTokensRecoveryCount: number hasAttemptedReactiveCompact: boolean maxOutputTokensOverride: number | undefined pendingToolUseSummary: Promise<ToolUseSummaryMessage | null> | undefined stopHookActive: boolean | undefined turnCount: number transition: Continue | undefined}真正关键的字段不是 messages,而是 transition。它把“上一轮为什么继续”提升成显式状态,整个 turn engine 因此更接近一张恢复图:
first_turn -> next_turn -> collapse_drain_retry -> reactive_compact_retry -> max_output_tokens_escalate -> max_output_tokens_recovery -> stop_hook_blocking -> token_budget_continuation顺着这张图读代码,比顺着文件从上到下读更接近真实运行路径。
显式状态机的另一个重要信号,是它把很多通常会藏进局部变量的东西提升成了一等状态:
pendingToolUseSummarystopHookActiveautoCompactTrackingmaxOutputTokensRecoveryCounthasAttemptedReactiveCompact
这不是写法偏好,而是在承认:这些东西都跨 iteration 生效,必须被当成恢复图的一部分。
4. 这条主循环维护的不是文本输出,而是合法轨迹
query.ts 里最硬的约束不是“尽量拿到回答”,而是“轨迹不能断”。
首先,任何已发出的 tool_use 都必须得到匹配的 tool_result,哪怕是 synthetic error:
function* yieldMissingToolResultBlocks( assistantMessages: AssistantMessage[], errorMessage: string,) { for (const assistantMessage of assistantMessages) {const toolUseBlocks = assistantMessage.message.content.filter(content => content.type === 'tool_use', ) as ToolUseBlock[]for (const toolUse of toolUseBlocks) {yield createUserMessage({content: [{type: 'tool_result',content: errorMessage,is_error: true,tool_use_id: toolUse.id, }],sourceToolAssistantUUID: assistantMessage.uuid, }) } }}其次,thinking block 不是任意剪裁的富文本,它受 trajectory 约束:
/** * The rules of thinking are lengthy and fortuitous. They require plenty of thinking * of most long duration and deep meditation for a wizard to wrap one's noggin around. * * The rules follow: * 1. A message that contains a thinking or redacted_thinking block must be part of a query whose max_thinking_length > 0 * 2. A thinking block may not be the last message in a block * 3. Thinking blocks must be preserved for the duration of an assistant trajectory (a single turn, or if that turn includes a tool_use block then also its subsequent tool_result and the following assistant message) * * Heed these rules well, young wizard. For they are the rules of thinking, and * the rules of thinking are the rules of the universe. If ye does not heed these * rules, ye will be punished with an entire day of debugging and hair pulling. */这解释了很多后面看似“多余”的恢复行为。系统要维护的不是 assistant 文本,而是一个带工具、thinking、fallback、recovery 的合法消息拓扑。
错误分流也因此不是普通异常处理,而是轨迹保护:
prompt_too_long- withheld media oversize
max_output_tokens- fallback trigger
- 真正不可恢复的 API error
有些 error 必须被 SDK 暂时看不见,直到系统确认恢复路径已经失败。这就是 isWithheldMaxOutputTokens(...) 那类逻辑真正存在的原因。
5. prompt_too_long 和 max_output_tokens 都不是错误处理,而是上下文调度
prompt_too_long 的路径不是“失败就 compact”,而是两级恢复:
- 先走 context collapse drain
- 再走 reactive compact
顺序不能反,因为 collapse 仍保留细粒度结构,reactive compact 一旦发生就进入全局摘要化。
max_output_tokens 也是同样的思路:
- 先试放大单次输出上限
- 再试 meta continuation 续写
- 超过恢复上限才真的落错误
这条主循环真正做的,是不断修正同一条轨迹,而不是反复发起彼此独立的模型请求。
这里还有一个容易漏掉的点:pendingToolUseSummary 与 stopHookActive 都说明 loop 不是“本轮全做完再说”,而是在为跨轮回收与防死循环留显式锚点。 这已经是成熟 runtime 才会出现的形状,而不是 demo agent loop。
分篇二:提示词 & 系统指令栈
1. system prompt 在这里不是前言,而是第一控制面
这份源码里,system prompt 不是一段静态文案,而是一层真正参与运行时治理的控制面。它决定:
- 当前会话究竟以什么身份运行
- 哪些行为被当成硬约束
- 哪些能力应被优先暴露
- 哪些宿主模式会直接替换整套默认规则
最关键的入口不是 constants/prompts.ts,而是 utils/systemPrompt.ts 里的优先级组装器:
/** * Builds the effective system prompt array based on priority: * 0. Override system prompt * 1. Coordinator system prompt * 2. Agent system prompt * 3. Custom system prompt * 4. Default system prompt */export function buildEffectiveSystemPrompt({...}): SystemPrompt { if (overrideSystemPrompt) {return asSystemPrompt([overrideSystemPrompt]) } if (coordinatorModeActive) {return asSystemPrompt([getCoordinatorSystemPrompt(), ...(appendSystemPrompt ? [appendSystemPrompt] : []), ]) } ...}这段代码的重要性在于,它把 prompt 明确建模成了宿主协议的一部分:
- loop mode / REPL override 可以整套替换默认 prompt
- coordinator mode 不是“多加几句 delegation 建议”,而是直接换成另一套系统法则
- agent prompt 在 proactive mode 下甚至不是 replace,而是 append 到 default prompt 上
这说明 prompt 在这里不是文案层,而是 runtime law。 哪个 prompt 赢,直接决定了后续能力面、任务边界、消息协议、输出语义。
2. system prompt 还是一个带缓存边界的结构化对象
这套系统不只是“拼一段长字符串”。它显式区分了 static prefix 与 dynamic tail:
/** * Everything BEFORE this marker in the system prompt array can use scope: 'global'. * Everything AFTER contains user/session-specific content and should not be cached. */exportconstSYSTEM_PROMPT_DYNAMIC_BOUNDARY ='__SYSTEM_PROMPT_DYNAMIC_BOUNDARY__'getSystemPrompt() 也围绕这个边界来组织内容:
return [ // --- Static content (cacheable) --- getSimpleIntroSection(outputStyleConfig), getSimpleSystemSection(), getSimpleDoingTasksSection(), getActionsSection(), getUsingYourToolsSection(enabledTools), getSimpleToneAndStyleSection(), getOutputEfficiencySection(), ...(shouldUseGlobalCacheScope() ? [SYSTEM_PROMPT_DYNAMIC_BOUNDARY] : []), // --- Dynamic content (registry-managed) --- ...resolvedDynamicSections,].filter(s => s !== null)这意味着 system prompt 在这里同时具有两种属性:
- 它是行为法则
- 它还是 prompt cache 的可计算对象
配套的 section registry 进一步把 prompt 变成结构化资产,而不是随手字符串拼接:
exportfunctionsystemPromptSection( name: string, compute: ComputeFn,): SystemPromptSection {return { name, compute, cacheBreak: false }}exportfunctionDANGEROUS_uncachedSystemPromptSection( name: string, compute: ComputeFn, _reason: string,): SystemPromptSection {return { name, compute, cacheBreak: true }}这里最值得 agent 开发者记住的,不是 API 形状,而是设计态度:
- prompt section 默认应该 memoize
- 只有真正会跨 turn 漂移、且无法 attachment 化的内容,才允许进入
DANGEROUS_uncachedSystemPromptSection /clear与/compact不只是清消息,也会清 prompt section 状态
比如 mcp_instructions 就被单列成危险 section,因为 MCP server 可能在会话中途连上或断开;如果仍放在 per-turn sys-prompt append 里,会直接打碎 prompt cache。
3. 值得单独学习的几段 system prompt,不是文风,而是架构意图
默认主 prompt 里有几段非常有价值,因为它们不是“写得漂亮”,而是在弥补模型默认行为的工程偏差。
第一类是 任务执行法则:
In general, do not propose changes to code you haven't read....Don't create helpers, utilities, or abstractions for one-time operations....Report outcomes faithfully...这三句分别在纠正三类常见 agent 失真:
- 没读就改
- 过度抽象
- 把不完整结果包装成完成
第二类是 风险边界法则:
Carefully consider the reversibility and blast radius of actions....for actions that are hard to reverse ... ask for confirmation before proceeding这不是礼貌提醒,而是 autonomy boundary 的 prompt 版表达。权限系统在代码层再兜一遍,但默认 system prompt 已经先把“高风险动作需要确认”写成了行为规范。
第三类是 工具使用法则:
DoNOT use the Bash tool when a relevant dedicated tool is provided....You can call multiple tools in a single response.If there are no dependencies between them, make all independent tool calls in parallel.这两句看似普通,实际上把两种非常关键的 runtime 设计提前灌进了模型:
- dedicated tools 优先于自由 shell
- 并行工具调用是鼓励项,但要服从依赖关系
第四类是 团队通信法则。它不在默认 prompt 主体里,而在 teammate addendum:
IMPORTANT: You are running as an agent in a team....Just writing a response in text is not visible to others on your team - you MUST use the SendMessage tool.这段 prompt 的价值不在“提醒发消息”,而在把 actor mailbox 的协议直接写进模型的世界观。
第五类是 延迟能力法则。ToolSearch prompt 直白地告诉模型:
Until fetched, only the name is known — there is no parameter schema,so the tool cannot be invoked.这是非常少见、但非常成熟的能力暴露语义。它把“名字已可见、schema 未加载”的半激活状态明确写给模型,避免模型把 deferred capability 当成 fully-loaded capability。
4. system-reminder、critical reminder、attachment 提醒,构成第二条指令通道
这套 runtime 的指令不只存在于顶层 system prompt。 它还通过 meta user message 与 attachment 在运行中持续注入约束。
utils/api.ts 里会把额外上下文包装成 <system-reminder> user meta message:
return [createUserMessage({content: `<system-reminder>\nAs you answer the user's questions, you can use the following context:\n...`,isMeta: true, }), ...messages,]与此同时,attachments.ts 还能补一类更硬的 reminder:
functiongetCriticalSystemReminderAttachment( toolUseContext: ToolUseContext,): Attachment[] {const reminder = toolUseContext.criticalSystemReminder_EXPERIMENTALif (!reminder) return []return [{ type: 'critical_system_reminder', content: reminder }]}这说明系统提示词在这里有两个层次:
- 顶层 system prompt:定义长期法则
- 运行中 reminder / attachment:补充当前 turn 的临时约束、上下文和能力提醒
这对 agent 开发者很重要。很多约束不应该永久写进 system prompt;它们更适合在真正相关的 turn 被短暂、强提示地注入。
5. 这套 runtime 里不止一个 prompt,还有一群“辅助模型 worker”
如果只盯着主对话模型,会漏掉一个很重要的架构事实:这套系统内部已经有多类专用 prompt worker,在替主 loop 做窄任务判断。
第一类是 memory selector:
const result = awaitsideQuery({model: getDefaultSonnetModel(),system: SELECT_MEMORIES_SYSTEM_PROMPT, ...output_format: { type: 'json_schema', schema: ... },})它不是让主模型自己从一堆 memory 文件里挑,而是先用 side query 做 relevance filtering。
第二类是 auto mode classifier。它甚至有一套独立的 system prompt 和 XML 协议:
constXML_S1_SUFFIX = '\nErr on the side of blocking. <block> immediately.'constXML_S2_SUFFIX ='\n... explicit user confirmation is required ... Use <thinking> before responding with <block>.'这里的 classifier 已经不是启发式判断,而是一个小型二阶段 policy judge。
第三类是 tool use summary worker:
constTOOL_USE_SUMMARY_SYSTEM_PROMPT = `Write a short summary label ...it truncates around 30 characters, so think git-commit-subject`它负责把工具批次压成移动端友好的短标签,服务的是宿主展示,而不是主 loop 推理。
第四类是 session memory updater:
YourONLY task is to use the Edit tool to update the notes file, then stop....NEVER modify, delete, or add section headers这其实是在用一个专门 prompt 驱动“结构化工作卡维护器”,而不是把记忆更新混在主 loop 里让它顺便做。
对于 agent 开发者,这里最有启发的一点是:不要把所有智能都塞给主对话模型。把 recall、policy judgment、UI summary、memory maintenance 这些窄任务分配给专用 prompt worker,主 loop 才能保持干净。
分篇三:能力、工具与策略
1. Tool.ts 把工具定义成能力契约,不是函数接口
Tool 抽象里真正重要的不是 call(),而是它同时携带:
- 输入 schema
- 并发语义
- 读写 / destructive 语义
- permission check
- UI 渲染
- result mapping
- 最大结果长度
- defer loading 语义
默认值在 buildTool() 里集中定义,隐含的架构态度很清楚:
- 并发安全默认否定
- 读写语义必须显式声明
- 权限既可由工具自己处理,也可落到通用 permission system
这使工具层更像“能力登记处”,而不是松散 handler 集合。
默认值本身也很能说明这份 runtime 的工程倾向:
constTOOL_DEFAULTS = { isEnabled: () => true, isConcurrencySafe: (_input?: unknown) => false, isReadOnly: (_input?: unknown) => false, isDestructive: (_input?: unknown) => false, checkPermissions: (...) =>Promise.resolve({ behavior: 'allow', updatedInput: input }), toAutoClassifierInput: (_input?: unknown) => '', userFacingName: (_input?: unknown) => '',}这里最重要的并不是“默认 allow”,而是其余语义都要求显式声明:
- 并发安全默认不成立
- 只读默认不成立
- 破坏性默认不成立
这意味着工具作者必须显式告诉 runtime 这把工具在调度和安全上应如何被对待。
2. ToolUseContext 是工具 runtime 的总线
ToolUseContext 暴露的不是几个工具参数,而是几乎整个 runtime:
- 工具池与 MCP clients
- AppState getter/setter
- file cache
- notifications
- memory triggers
- agent definitions
- permission bridge
- task hooks
- telemetry
它带来极高的执行力,也带来一个直接后果:工具很容易“顺手”跨边界访问宿主状态。
这就是后文结构债里 AppState 与 ToolUseContext 双重总线的来源。
源码里的定义比文字更直观:
exporttype ToolUseContext = { options: {commands: Command[]mainLoopModel: stringtools: ToolsmcpClients: MCPServerConnection[]mcpResources: Record<string, ServerResource[]>isNonInteractiveSession: booleanagentDefinitions: AgentDefinitionsResult refreshTools?: () => Tools } abortController: AbortController readFileState: FileStateCache getAppState(): AppState setAppState(f: (prev: AppState) => AppState): void ...}这就是典型的“高能力总线”形态:一旦某个子系统被塞进 ToolUseContext,它几乎立即获得了被所有工具访问的资格。
3. toolExecution.ts 是完整流水线,不是 tool.call(input)
工具调用真正的形状是一条多阶段流水线:
const parsedInput = tool.inputSchema.safeParse(input)...const isValidCall = await tool.validateInput?.(...)...startSpeculativeClassifierCheck(...)...runPreToolUseHooks(...)...resolveHookPermissionDecision(...)...tool.call(...)...runPostToolUseHooks(...)...processToolResultBlock(...)这条流水线里真正先进的地方,是权限、hooks、classifier、result rewrite 都和工具调用同构。系统不是“工具跑完后再考虑安全和上下文”,而是把这些控制点写进执行路径本身。
并发调度也不是“能并发就都并发”,而是显式区分执行与提交:
for (const { isConcurrencySafe, blocks } of partitionToolCalls(...)) {if (isConcurrencySafe) {const queuedContextModifiers: Record<string, ((context: ToolUseContext) => ToolUseContext)[] > = {}for await (const update of runToolsConcurrently(...)) {if (update.contextModifier) { ... }yield { message: update.message, newContext: currentContext } }for (const block of blocks) {const modifiers = queuedContextModifiers[block.id] ... currentContext = modifier(currentContext) } }}这一步非常关键:读工具可以并发执行,但上下文副作用必须按原工具顺序提交,否则后续模型状态会被乱序污染。
4. ToolSearch、REPL、skills 解决的是同一个问题:能力面控制
这三套机制表面差别很大,底层目标其实一致:
ToolSearch解决 MCP schema 不能一次性暴露- REPL 把大量 primitive tools 虚拟化到一个入口里
- skills 让 prompt artifact 也变成按路径/时机出现的能力面
这意味着 runtime 真正管理的不是“有哪些工具”,而是“模型当前能看到多少可执行表面”。
这里的关键不只是节省 token,而是维持能力面稳定性与 cache prefix 稳定性。一旦工具池、schema 描述、skills 说明在每轮都剧烈漂移,模型的工作面就失去连续性了。
这一层在实现上有三种不同手法:
tools.ts对 built-ins 与 MCP 工具分区排序,保持 cache-stable prefixToolSearch先暴露名字,后暴露 schema- REPL 把大量 primitive tools 收束进一个虚拟化入口
它们表面不同,实际上都在回答同一个问题:模型本轮应该看到多大的 capability surface。
tools.ts 里的排序逻辑其实已经把 cache 语义写在注释里:
// Sort each partition for prompt-cache stability, keeping built-ins as a// contiguous prefix.constbyName = (a: Tool, b: Tool) => a.name.localeCompare(b.name)returnuniqBy( [...builtInTools].sort(byName).concat(allowedMcpTools.sort(byName)),'name',)这不是美化输出顺序,而是在保护 system prompt 的稳定前缀。一旦 MCP 工具插进 built-ins 中间,后面的缓存键整体漂移,系统提示的复用价值会迅速下降。
REPL 则在执行面上做了另一层虚拟化。工具池组装阶段就会把 primitive tools 从模型直视面中拿掉:
// When REPL mode is enabled, hide primitive tools from direct use.// They're still accessible inside REPL via the VM context.if (isReplModeEnabled()) {const replEnabled = allowedTools.some(tool =>toolMatchesName(tool, REPL_TOOL_NAME), )if (replEnabled) { allowedTools = allowedTools.filter(tool => !REPL_ONLY_TOOLS.has(tool.name), ) }}这说明 REPL 在这里不是“多一个工具”,而是一个虚拟化层:
- 模型表面上看到的是一个收束后的执行入口
- 内层仍可重用 Bash / Read / Edit / Glob / Grep 等原始能力
- 权限系统继续在内层细粒度生效,而不是被 REPL 绕开
skills 再往前走了一步,把 prompt artifact 也纳入 capability surface 管理。loadSkillsDir.ts 里 skill 并不是一段 markdown,而是一个结构化 command:
exportfunction createSkillCommand({...}): Command { return {type: 'prompt',name: skillName, description, allowedTools, whenToUse, model, disableModelInvocation,context: executionContext, agent, effort, paths, ... }}也就是说,skill 同时携带:
- 可调用工具约束
- 推荐模型
- 是否 fork 执行
- 绑定 agent
- path 条件与 effort
它已经不是“快捷提示词”,而是 capability artifact。
条件激活逻辑也并不是抽象配置,而是明确按工作面触发:
const skillIgnore = ignore().add(skill.paths)for (const filePath of filePaths) {const relativePath = isAbsolute(filePath) ? relative(cwd, filePath) : filePath ...if (skillIgnore.ignores(relativePath)) { dynamicSkills.set(name, skill) conditionalSkills.delete(name) activated.push(name)break }}这和 deferred tools 的 discovered-set 延续其实是一类机制。toolSearch.ts 里把 compaction 之后仍要保留的工具发现状态显式挂到 compact boundary 上:
// Compaction replaces tool_reference-bearing messages with a summary, so it// snapshots the discovered set onto compactMetadata.preCompactDiscoveredToolsif (msg.type === 'system' && msg.subtype === 'compact_boundary') {const carried = msg.compactMetadata?.preCompactDiscoveredToolsif (carried) {for (const name of carried) discoveredTools.add(name) }}把这几处放在一起看,能力面治理就不再只是“少给几个工具”这么简单,而是一个持续演化的 surface:
- 初始只给稳定前缀
- REPL 隐藏 primitive entrypoints
- deferred tools 名字先出现,schema 按需展开
- skills 随路径和工作面激活
- compaction 后 discovered set 继续带过去
这才是这套 runtime 的 capability continuity。
5. 权限系统已经是独立的 Policy Control Plane
源码里的 permissions 不是工具执行前的一层确认框,而是一条独立的策略栈。
它至少同时包含四层来源:
-
组织级 policy limits:从 API 拉取、ETag 缓存、后台轮询,默认 fail open,但在特定隐私等级上对个别 policy fail closed:
* Fetches organization-level policy restrictions from the API and uses them* to disable CLI features.* (fail open, ETag caching, background polling, retry logic)constESSENTIAL_TRAFFIC_DENY_ON_MISS = newSet(['allow_product_feedback']) -
多来源规则层:user settings、project settings、local settings、cli arg、session rule、managed rule 共同进入
ToolPermissionContext,并且支持 replacement sync,而不是简单追加。 -
tool 自身的
checkPermissions():工具可以声明更细粒度的安全检查。 -
auto mode classifier:这不是“提示词小技巧”,而是权限系统内部的二级模型裁决链。
permissions.ts 里最说明问题的是这段:
if (feature('TRANSCRIPT_CLASSIFIER') && (appState.toolPermissionContext.mode === 'auto' || (appState.toolPermissionContext.mode === 'plan' && (autoModeStateModule?.isAutoModeActive() ?? false)))) { ... const acceptEditsResult = await tool.checkPermissions(... mode: 'acceptEdits') ... if (classifierDecisionModule!.isAutoModeAllowlistedTool(tool.name)) { ... } const action = formatActionForClassifier(tool.name, input) classifierResult = await classifyYoloAction(...)}这说明 auto mode 不是单一开关,而是一条次级决策链:
- 先看安全检查是否允许进入 classifier
- 再看 accept-edits fast path
- 再看 allowlist
- 最后才跑 classifier
- denial tracking 再把历史结果反馈回下一次决策
因此,权限系统真正负责的是 agent autonomy boundary。它决定模型此刻能否代表用户继续行动,而不只是“工具按钮要不要点确认”。
还有一条更隐蔽、但很有生产味道的设计:规则同步不是简单追加,而是 replacement sync。
exportfunction syncPermissionRulesFromDisk( toolPermissionContext: ToolPermissionContext, rules: PermissionRule[],): ToolPermissionContext { ... for (const diskSource of diskSources) {for (const behavior of ['allow', 'deny', 'ask'] as PermissionBehavior[]) { context = applyPermissionUpdate(context, {type: 'replaceRules',rules: [], behavior,destination: diskSource, }) } } const updates = convertRulesToUpdates(rules, 'replaceRules') return applyPermissionUpdates(context, updates)}这说明权限上下文被当成一份需要长期同步的一等状态,而不是临时 prompt 附件。否则删除一条规则时,旧规则会幽灵般残留在 runtime 里。
分篇四:连续性、缓存与恢复
1. attachments.ts 是上下文路由器,不是附件工具
attachments.ts 是整个 runtime 里最容易被误判的文件之一。它已经不是“给消息补几个附件”,而是在多个控制面之间做路由:
- user input attachments
- nested memory
- relevant memories
- dynamic skills
- task attachments
- teammate messages
- date change
- deferred tools delta
- IDE selection / diagnostics
- todo reminders
- system reminders
换句话说,attachments.ts 不是一个边缘辅助模块,而是主循环前的 context router。这也是它同时成为亮点与结构债的原因。
这一层已经在做次级调度,而不是静态拼装。相关记忆注入的路径就很典型:
const allResults = await Promise.all( dirs.map(dir =>findRelevantMemories( input, dir, signal, recentTools, alreadySurfaced, ).catch(() => []), ),)const selected = allResults .flat() .filter(m => !readFileState.has(m.path) && !alreadySurfaced.has(m.path)) .slice(0, 5)return [{ type: 'relevant_memories' as const, memories }]这里不是“扫目录然后全塞进去”,而是:
@agent-x时切到 agent 自己的 memory dir,保持隔离alreadySurfaced在 selector 前就过滤,避免 Sonnet 浪费 5 个名额去重选旧记忆readFileState再拦一次,避免模型刚读过文件又被 attachment 重复注入
更细的一笔在于,surfaced memory 的去重预算不是挂在某个长寿命对象上,而是从消息本身反扫:
if (m.type === 'attachment' && m.attachment.type === 'relevant_memories') {for (const mem of m.attachment.memories) { paths.add(mem.path) totalBytes += mem.content.length }}这意味着 compact 之后旧 attachment 消失,记忆允许重新浮现。去重范围因此天然和“当前仍在上下文中的历史”绑定,而不是和整个进程寿命绑定。
它甚至还要处理任务通知注入带来的调度副作用:
constINLINE_NOTIFICATION_MODES = newSet(['prompt', 'task-notification'])// During proactive agentic loops, task-notification commands would otherwise// stay in the queue permanently ... causing Sleep to wake immediately// with 0ms duration in an infinite loop.这已经不是附件构造,而是 loop liveness 的一部分。所以说 attachments.ts 是“第二调度器”,并不是修辞。
2. 这套系统没有单一 memory 子系统
如果硬找 “memory 模块”,会得到错误答案。这份代码里的连续性至少分成四类:
- instruction continuity(指令连续性):
CLAUDE.md、rules、conditional rules - capability continuity(能力连续性):discovered tools、dynamic skills、agent definitions
- semantic continuity(语义连续性):
MEMORY.md、topic files、daily logs、relevant memories - operational continuity(操作连续性):transcript、session memory、task state、sidechain transcript、content replacement records
这就是为什么 “memory” 在这里不能被理解成某个目录,而应该被理解成一组外化机制。
最容易被低估的一点是:query-time recall 也不是“向量库召回”,而是一次专用 side query。findRelevantMemories.ts 的实现很直接:
const result = await sideQuery({ model: getDefaultSonnetModel(), system: SELECT_MEMORIES_SYSTEM_PROMPT, skipSystemPromptPrefix: true, messages: [ {role: 'user',content: `Query: ${query}\n\nAvailable memories:\n${manifest}${toolsSection}`, }, ], max_tokens: 256, output_format: {type: 'json_schema',schema: {type: 'object',properties: {selected_memories: { type: 'array', items: { type: 'string' } }, },required: ['selected_memories'],additionalProperties: false, }, }, signal, querySource: 'memdir_relevance',})它的关键设计不是“又调了一次模型”,而是:
- 只扫 frontmatter / header manifest,不预读整篇正文
- 用小模型做 relevance selection,把主模型前缀预算留给当前任务
recentTools会显式传进 selector,避免“当前正在用 spawn 工具,于是又召回 spawn 文档”这种伪相关
所以这里的 memory 不是一个大而化之的 recall 黑箱,而是几种不同时间尺度的外化物,再加几条不同精度的召回路径。
3. MEMORY.md、daily logs、session memory 是三种不同工件
MEMORY.md 与 daily logs 更像 log/index 分离:
- 高频写入进 append-only 日志
- 低频蒸馏成 topic files 与
MEMORY.md
session memory 又是另一种工件。它不是摘要日志,而是 compaction 之后的工作卡,关注:
- 当前状态
- 当前任务规格
- 关键文件与函数
- 工作流
- 错误与修正
- next step
这三者混在一起会很乱,但分开看就清楚:MEMORY.md 管长期语义入口,daily logs 管原始积累,session memory 管断点续航。
memdir.ts 对 MEMORY.md 的边界也给得非常明确:
exportconstENTRYPOINT_NAME = 'MEMORY.md'exportconstMAX_ENTRYPOINT_LINES = 200exportconstMAX_ENTRYPOINT_BYTES = 25_000同一文件里又把 daily log 的语义写成 append-only:
// append-only to a date-named log file rather than maintaining MEMORY.md as// a live index. A separate nightly /dream skill distills logs into topic// files + MEMORY.md.这就是典型的 log/index 分离思路:
- 高频写入进入 date-named append-only daily log
- 低频蒸馏生成 topic files 与
MEMORY.md MEMORY.md是受预算限制的入口页,不是实时写热点
session memory 的粒度要求在模板里写得很死,不是随意摘要:
# Current State# Task specification# Files and Functions# Workflow# Errors & Corrections# Codebase and System Documentation# Learnings# Key results# Worklog更新 prompt 还额外规定了几条硬约束:
- 不能改 section header,也不能改斜体说明行
Current State必须永远反映“最近一次工作现场”Key results要写“用户要求的完整结果”,不是抽象总结- 超 budget 时优先压缩旧内容,但尽量保住
Current State与Errors & Corrections
这说明 session memory 在这里并不是“可有可无的笔记文件”,而是 compact 之后的工作卡。它的任务是让 runtime 在失去大量原始 turn 细节后,仍保留足够强的 continuation anchor。
nested memory 注入还带着很强的读写一致性防护。当注入内容和磁盘原文不一致时,runtime 不会假装“模型已经看过完整文件”,而是把原始磁盘字节缓存成 partial view:
toolUseContext.readFileState.set(memoryFile.path, {content: memoryFile.contentDiffersFromDisk ? (memoryFile.rawContent ?? memoryFile.content) : memoryFile.content,timestamp: Date.now(),offset: undefined,limit: undefined,isPartialView: memoryFile.contentDiffersFromDisk,})这一步的价值在于:如果注入时剥掉了 frontmatter、裁掉了大文件尾部、或去掉了某些不可见内容,后续 Edit/Write 工具不会误以为自己持有的是完整文件视图,而会先要求真实 Read。 这是一种很少被显式讨论、但对 agent 改文件安全性非常重要的 continuity guard。
4. 缓存控制面管理的不是 token 总量,而是 prefix 命运
toolResultStorage.ts 里最硬的状态不是预算数字,而是:
exporttypeContentReplacementState = {seenIds: Set<string>replacements: Map<string, string>}注释点得很准:
// Once seen, a result's fate is frozen for the conversation.这条不变量意味着:
- 某个
tool_use_id一旦被看过,它之后是否替换就被冻结 - 已替换的永远复用同一个 replacement string
- 未替换的以后也不能补替换
这里真正被管理的不是“总共多少 token”,而是“历史前缀不能反悔”。
配套的持久化记录也不是可推导元数据,而是把“模型实际看到了什么字串”直接写盘:
exporttypeContentReplacementRecord = {kind: 'tool-result'toolUseId: stringreplacement: string}源码注释把原因说得很直白:replacement 要直接存 exact string,而不是 resume 时重算;否则一旦 preview 模板、大小格式、路径布局改了,prompt cache 就会静默失配。
cached microcompact 进一步把本地消息视图与 API 前缀视图拆开:本地消息不改,API 层通过 cache_edits 缩上下文。
这个分层在 microCompact.ts 和 services/api/claude.ts 里非常明确:
// Return messages unchanged - cache_reference and cache_edits are added at API layerreturn { messages,compactionInfo: {pendingCacheEdits: {trigger: 'auto',deletedToolIds: toolsToDelete, ... }, },}真正把 deletion 编辑钉到 API 消息上的,是后面的注入层:
for (const pinned of pinnedEdits ?? []) {const msg = result[pinned.userMessageIndex] ...insertBlockAfterToolResults(msg.content, dedupedBlock)}if (newCacheEdits && result.length > 0) { ...insertBlockAfterToolResults(msg.content, dedupedNewEdits)pinCacheEdits(i, newCacheEdits)}这里有两个很少在通用 agent 设计里被认真处理的问题:
cache_edits必须固定插回原用户消息位置,否则后续 wire prefix 还是漂- 已 pin 的删除块要每轮重送,而且要跨 block 去重,否则 API 层会反复删除同一
cache_reference
这条链加上工具排序、fork prefix 复制、resume gap fill,一起构成了整个系统最稀缺的一层:prompt cache 被当成一等架构约束,而不是部署细节。
5. sessionStorage.ts 维护的不是 JSONL,而是可修补的因果链
sessionStorage.ts 的真正对象不是日志文件,而是一条 parentUuid 因果链。
第一步,是把 progress 从持久链里明确踢出去:
exportfunction isTranscriptMessage(entry: Entry): entry is TranscriptMessage { return ( entry.type === 'user' || entry.type === 'assistant' || entry.type === 'attachment' || entry.type === 'system' )}export function isChainParticipant(m: Pick<Message, 'type'>): boolean { return m.type !== 'progress'}第二步,是加载旧 transcript 时不能只过滤 progress,还要桥接旧链:
const progressBridge = newMap<UUID, UUID | null>()...if (entry.parentUuid && progressBridge.has(entry.parentUuid)) { entry.parentUuid = progressBridge.get(entry.parentUuid) ?? null}第三步,是 snip 之后恢复时必须重放“删中段并 relink”:
functionapplySnipRemovals(messages: Map<UUID, TranscriptMessage>): void { ... messages.set(uuid, { ...msg, parentUuid: resolve(msg.parentUuid) })}第四步,是并行 tool_use 把拓扑从链退化成 DAG,读侧必须恢复 orphaned sibling assistant 与 tool_result:
returnrecoverOrphanedParallelToolResults(messages, transcript, seen)还有一条非常硬的恢复约束:大 transcript 的反向扫描依赖 parentUuid 作为序列化后的首键。这说明序列化对象键序本身都进入了恢复协议。
源码甚至把这个假设单独写成 invariant:
* 1.Transcript messages always serialize with parentUuid as the first key. * JSON.stringify emits keys in insertion order and recordTranscript's * object literal puts parentUuid first. So `{"parentUuid":` is a stable * line prefix that distinguishes transcript messages from metadata.这背后的含义很重:恢复路径并不是“把 JSONL 全读出来再慢慢整理”,而是先靠 append-only 与前缀扫描找到参与链的候选,再走 parentUuid 逆向回溯。所以 progress bridge、snip relink、parallel tool result orphan recovery 这些补丁,都不是读盘装饰,而是链式恢复的必要条件。
6. conversationRecovery.ts 的目标不是反序列化,而是重回 API 合法状态
从 transcript 读出消息之后,还要再过一轮 conversationRecovery.ts:
const filteredToolUses = filterUnresolvedToolUses(migratedMessages)const filteredThinking =filterOrphanedThinkingOnlyMessages(filteredToolUses)const filteredMessages =filterWhitespaceOnlyAssistantMessages(filteredThinking)这一步不是“忠实读盘”,而是把已经无法继续送 API 的残片先剥掉。
中断恢复更进一步:
createUserMessage({content: 'Continue from where you left off.',isMeta: true,})interrupted turn 会被归一化成 synthetic continuation。如果最后一条有效消息是 user,还会补 synthetic assistant sentinel,确保会话在不立刻恢复时依然 API 合法。
这个 sentinel 不是抽象概念,而是真正插回消息数组:
filteredMessages.splice( lastRelevantIdx + 1,0,createAssistantMessage({content: NO_RESPONSE_REQUESTED, }) asNormalizedMessage,)这说明恢复目标不是“把文件原样吐出来”,而是“把系统重新放回可继续运转的状态”。
分篇五:任务、子代理与远程执行
1. task framework 是异步执行底座,不是 UI 面板配套
读源码时很容易把 task system 低估成了 UI 层配套。实际上 utils/task/framework.ts 已经是 runtime substrate。
Task.ts 先定义了统一的任务类型与状态:
exporttypeTaskType = | 'local_bash' | 'local_agent' | 'remote_agent' | 'in_process_teammate' | 'local_workflow' | 'monitor_mcp' | 'dream'framework.ts 再提供统一的任务注册、替换、SDK 事件、增量输出、终态 GC:
exportfunction registerTask(task: TaskState, setAppState: SetAppState): void { let isReplacement = false setAppState(prev => {const existing = prev.tasks[task.id] isReplacement = existing !== undefinedconst merged = existing && 'retain' in existing ? { ...task,retain: existing.retain,startTime: existing.startTime,messages: existing.messages,diskLoaded: existing.diskLoaded,pendingMessages: existing.pendingMessages, } : taskreturn { ...prev, tasks: { ...prev.tasks, [task.id]: merged } } }) if (isReplacement) return enqueueSdkEvent({type: 'system',subtype: 'task_started',task_id: task.id, ... })}这层真正管理的是:
- 异步执行体的 identity
- 它的 output file
- SDK
task_started/ terminated bookend - retain / evict / GC
- 增量 output attachment
所以它不是“后台面板实现细节”,而是 agent runtime 里承载异步工作的主底座之一。
这里最有生产味道的一点,是 re-register 不会把 UI 态和未落盘态洗掉。resumeAgentBackground 替换 task 时,用户刚 append 的 prompt、当前 detail panel 的 retain、pending teammate messages 都会被带过去。
这类细节如果没有 task substrate 统一兜住,就只能在每个任务类型里各自打补丁。
2. coordinator mode 不是 prompt 变体,而是消息协议变体
coordinatorMode.ts 最大的架构意义,不在 prompt 更长,而在它重新定义了 worker 完成消息怎样进入主会话:
<task-notification><task-id>{agentId}</task-id><status>completed|failed|killed</status><summary>{human-readable status summary}</summary><result>{agent's final text response}</result></task-notification>源码明确规定:
- worker 结果以 user-role 消息送回 coordinator
- coordinator 不能把它当 conversation partner
- 每个
<task-notification>都是独立 turn 之间插入的外部信号
这使 coordinator mode 不再只是“一个更善于 delegation 的 prompt”,而是 turn topology 本身变了。主会话已经不再只接收用户输入,也接收任务系统注入的外部 completion event。
源码甚至明确提醒 coordinator:这些看起来像 user message,但不是普通 user turn:
Worker results arrive as user-role messages containing <task-notification> XML.They look like user messages but are not.再加上 prompt 里规定的 phase 切分,coordinator runtime 的真实形状就出来了:
- 研究阶段可以并行起 worker
- 综合判断必须回到 coordinator
- 实现和验证再下发
- worker 完成后以
<task-notification>作为外部事件回灌
所以 coordinator mode 实际上是 “message protocol + task substrate + prompt law” 三件事一起成立。
3. 本地子代理已经是 actor,不是函数调用
fork 子代理最重要的不是分叉,而是 cache-safe prefix 复制。forkSubagent.ts 复制完整 assistant message,再补 placeholder tool_result,不是为了语义自然,而是为了尽量复用父线程前缀缓存。
相关实现几乎把意图写在注释里:
exportfunction buildForkedMessages( directive: string, assistantMessage: AssistantMessage,): MessageType[] { const fullAssistantMessage: AssistantMessage = { ...assistantMessage,uuid: randomUUID(),message: { ...assistantMessage.message,content: [...assistantMessage.message.content], }, } const toolResultBlocks = toolUseBlocks.map(block => ({type: 'tool_result'asconst,tool_use_id: block.id,content: [{ type: 'text'asconst, text: FORK_PLACEHOLDER_RESULT }], })) const toolResultMessage = createUserMessage({content: [...toolResultBlocks, { type: 'text'asconst, text: buildChildMessage(directive) }], }) return [fullAssistantMessage, toolResultMessage]}关键不是“子代理拿到了上文”,而是:
- 保留 parent assistant 的全部
thinking / text / tool_use - 用统一 placeholder 补全所有
tool_result - 只让最后一段 directive 文本随 child 变化
这正是 cache-friendly fork 的典型写法:最大化共享前缀,最小化分叉尾部。
createSubagentContext() 也不是简单 clone,而是一张共享矩阵:
- abort 默认隔离
- AppState 默认 no-op/只读
- permission prompt 默认规避
- replacement state 默认克隆
- task registration 仍回根 store
这表明子代理在这里不是普通函数调用,而是带隔离边界的执行体。
其中最重要的一行是 content replacement state 的继承策略:
contentReplacementState: overrides?.contentReplacementState ?? (parentContext.contentReplacementState ? cloneContentReplacementState(parentContext.contentReplacementState) : undefined),这里默认 clone 而不是 fresh state,不是历史包袱,而是缓存语义要求。fork child 会继续处理 parent 已经出现过的 tool_use_id;如果 replacement 决策重新洗牌,wire prefix 就变了,cache hit 也跟着消失。
真正让子代理获得 operational continuity 的,不只是 fork 输入,还有 sidechain transcript。runAgent.ts 在 query loop 开始前就先把初始消息和 agent metadata 异步写盘:
// Record initial messages before the query loop starts, plus the agentType// so resume can route correctly when subagent_type is omitted.voidrecordSidechainTranscript(initialMessages, agentId).catch(...)voidwriteAgentMetadata(agentId, {agentType: agentDefinition.agentType, ...(worktreePath && { worktreePath }), ...(description && { description }),}).catch(...)letlastRecordedUuid: UUID | null = initialMessages.at(-1)?.uuid ?? null随后每条 recordable message 都按正确 parent 继续接进 sidechain:
if (isRecordableMessage(message)) {awaitrecordSidechainTranscript( [message], agentId, lastRecordedUuid, ).catch(...)if (message.type !== 'progress') { lastRecordedUuid = message.uuid }yield message}这里不是简单“把子代理输出写日志”,而是在维护:
- sidechain 独立 transcript
- 正确的
parentUuid连续性 agentType/worktreePath/description等 resume 路由信息
所以 sidechain transcript 是子代理可恢复性的骨架,不是 debug artifact。
还有一条很容易漏掉的宿主语义:不是所有子代理都默认保留 toolUseResult。
只有带可查看 transcript 的子代理才会显式打开这项能力:
// Preserve tool use results for subagents with viewable transcriptsif (preserveToolUseResults) { agentToolUseContext.preserveToolUseResults = true}这说明 transcript 保真度在这里是按可恢复/可查看需求分层的。临时 explore 型子代理可以省掉部分 result 负担;需要被单独查看、回放、恢复的执行体,则必须把 toolUseResult 留住。
4. mailbox 是 swarm 的真实总线
teammate 协作并不靠 shared transcript,而靠 mailbox 协议。
permissionSync.ts 直接把流程写明:
* Workers send permission requests to the leader's mailbox * Leaders send permission responses to the worker's mailboxteammatePromptAddendum.ts 又把这件事写进 prompt 规约:
Just writing a response in text is not visible to others on your team - you MUST use the SendMessage tool.这意味着 SendMessage 不是协作糖衣,而是显式 RPC。纯文本回复只存在于本 agent 本地轨迹里,不会天然变成团队共享状态。
LocalAgentTask.tsx 更进一步把这条总线和 runtime 边界绑在一起:teammate 消息不是随发随达,而是先进入 pendingMessages,在 tool-round 边界 drain,再并入下一轮 API 输入。
具体实现也非常直接:
exportfunction queuePendingMessage(taskId: string, msg: string, setAppState: ...): void { updateTaskState(taskId, setAppState, task => ({ ...task,pendingMessages: [...task.pendingMessages, msg] }))}export function drainPendingMessages(taskId: string, getAppState: ..., setAppState: ...): string[] { const task = getAppState().tasks[taskId] if (!isLocalAgentTask(task) || task.pendingMessages.length === 0) {return [] } const drained = task.pendingMessages updateTaskState(taskId, setAppState, t => ({ ...t, pendingMessages: [] })) return drained}这意味着 teammate message 的投递边界是“下一轮工具回合开始前”,不是任意时刻中断当前推理。这是一种非常务实的 actor mailbox 语义:牺牲即时性,换取 turn 内部状态不被异步注入打穿。
更关键的是,in-process teammate 和外部 transport teammate 在模型看到的通信表面上被强制对齐成同一协议。inProcessRunner.ts 会把消息包装成统一的 XML:
functionformatAsTeammateMessage(from: string, content: string, color?: string, summary?: string,): string {const colorAttr = color ? ` color="${color}"` : ''const summaryAttr = summary ? ` summary="${summary}"` : ''return`<${TEAMMATE_MESSAGE_TAG} teammate_id="${from}"${colorAttr}${summaryAttr}>\n${content}\n</${TEAMMATE_MESSAGE_TAG}>`}这一步的含义非常大:无论 teammate 实际跑在同进程、tmux、还是其他宿主里,模型侧看到的协作协议都尽量保持同构。这样 prompt 规约、消息解析、权限同步、回放逻辑就不需要各写一套方言。
5. inProcessRunner.ts 不是子调用包装,而是本地 actor loop
inProcessRunner.ts 的重要性,不在“能起一个 teammate”,而在它自己拥有:
- 独立
allMessages - actor 级别 compaction
- replacement state reset
- abort 生命周期管理
- mailbox message wait loop
换句话说,in-process teammate 和普通本地函数已经不属于同一种执行模型。
最关键的 while-loop 里,既在维护 actor 自己的 allMessages,也在维护自己的缓存连续性:
let teammateReplacementState = toolUseContext.contentReplacementState ? createContentReplacementState() : undefinedwhile (!abortController.signal.aborted && !shouldExit) { const userMessage = createUserMessage({ content: currentPrompt }) let contextMessages = allMessages const tokenCount = tokenCountWithEstimation(allMessages) if (tokenCount > getAutoCompactThreshold(toolUseContext.options.mainLoopModel)) {const compactedSummary = await compactConversation(...) contextMessages = buildPostCompactMessages(compactedSummary)resetMicrocompactState()if (teammateReplacementState) { teammateReplacementState = createContentReplacementState() } allMessages.length = 0 allMessages.push(...contextMessages) }}注意这里 reset 的不是一个东西,而是两套状态:
microcompact状态,因为 full compact 后旧tool_use_id已经不在新消息里teammateReplacementState,因为 replacement 绑定的是“当前仍在 actor 历史里的候选结果”
这正说明 in-process teammate 已经是完整 actor loop,而不是“帮主线程再调一次 query”。
6. RemoteAgentTask 说明执行底座已经跨到云端
RemoteAgentTask 不是产品边缘功能,而是 runtime 把执行底座扩展到远端 session 的完整路径。
注册远程任务时,它会:
- 初始化 output file
- 注册
remote_agenttask state - 把远程 session identity 持久化到 sidecar
- 启动 poller
consttaskState: RemoteAgentTaskState = { ...createTaskStateBase(taskId, 'remote_agent', session.title, toolUseId), type: 'remote_agent', remoteTaskType, status: 'running', sessionId: session.id, command, title: session.title, ...}registerTask(taskState, context.setAppState)void persistRemoteAgentMetadata({ taskId, remoteTaskType, sessionId: session.id, title: session.title, command, spawnedAt: Date.now(), ...})恢复时:
const persisted = await listRemoteAgentMetadata()for (const meta of persisted) { try {const session = await fetchSession(meta.sessionId) remoteStatus = session.session_status } catch (e) {if (e instanceof Error && e.message.startsWith('Session not found:')) {void removeRemoteAgentMetadata(meta.taskId) }continue } if (remoteStatus === 'archived') {void removeRemoteAgentMetadata(meta.taskId)continue } registerTask(taskState, context.setAppState) startRemoteSessionPolling(meta.taskId, context)}终止时:
if (killed) {emitTaskTerminatedSdk(taskId, 'stopped', { toolUseId, summary: description })if (sessionId) {voidarchiveRemoteSession(sessionId).catch(...) }}这条路径说明 durable execution boundary 已经不再局限于本地 transcript。而且恢复逻辑把 404 和 recoverable auth/network error 区分开了:前者说明远端 session 真没了,应删除 sidecar;后者说明远端可能还活着,只是当前客户端暂时接不上,不应贸然丢失本地跟踪。
这比“远程跑一个任务,定时 poll 一下”要厚得多。系统维护的对象已经扩展成“本地 session + 本地 task registry + 远程 session handle” 的组合。
收束:结构债、可迁移原则
1. 这份代码最值得继承的,不是模块拆分,而是几个硬约束
真正值得进入未来 agent runtime 设计文档的,是下面这些约束:
tool_use -> tool_result必须闭合- thinking trajectory 不能被任意切断
- once seen, fate frozen
- 能力面必须按时机、路径、模式渐进展开
- 连续性必须外化成多种 durable artifact
- 策略系统必须独立于 tool handler
- 异步执行体必须有统一 task substrate
这几条比任何一个具体 API 都更重要。
2. 结构债不在“功能太多”,而在 owner 模糊
这份 runtime 的主要问题,不是 feature 太多,而是若干一等约束没有单独 owner:
query.ts已经是 God Loopattachments.ts变成第二调度器ToolUseContext过胖- cache invariants 散落在多文件
- continuity surface 太多,但没有统一 taxonomy
- permissions / tasks / remote execution 已经上升成控制面,却还分散在多个模块里
一旦 owner 不清晰,后续演化就只能继续靠补偿机制维持。
3. 这份源码里最亮眼的部分,常常首先是疤痕
最能打动人的地方往往也是最危险的地方。像 progressBridge、snip relink、orphaned permission replay、synthetic continuation、remote resume reconnect,这些都极具工程含量,但它们首先证明的是系统曾经在边界上破过一次。
它们当然重要,但更适合作为:
- 边界识别器
- 约束提炼器
- 重构切口提示器
而不宜直接抄成下一代系统的默认结构。
4. 更稳的下一代形态,会把这些控制面显式拆开
从这份代码可以直接反推出一套更清晰的未来形态:
ConversationHostTurnEngineCapabilityManagerPermissionControlPlaneContextManagerCacheManagerTaskRuntimeMemoryRuntime
眼下这份代码已经在事实层面拥有这些层,只是它们还没有完全在模块边界上显形。
5. 这份源码真正稀缺的价值,在它已经开始为“长时间工作”付账
它和大量只够支撑 demo 的 agent 框架之间,真正的差别不在工具数、模型数、UI 丰富度,而在这些已经付掉的账:
- 工具结果太大时,不是简单截断,而是冻结命运、持久化 replacement、跨 resume 重放
- 子代理恢复时,不是只有 transcript,而是补 content replacement gap
- 工具太多时,不是平铺 schema,而是延迟发现与渐进暴露
- 长会话 memory 不是单一摘要,而是 log / index / session card / transcript 并存
- 错误恢复不是单纯 retry,而是保护轨迹拓扑与宿主观察语义
- 异步工作不是“后台线程”,而是有 task identity、notification、resume、GC、remote handle 的执行底座
这恰好构成了这份材料最值得继承的部分:它已经不再假设“模型足够聪明就会自然收束”,而是在外层持续维护结构不变量。这也是生产级 agent runtime 和 demo agent loop 的真正分界线。
6. 还有一条不该忽略的控制面:可观测性
对照源码再看,文章还有一条之前没有单列、但对生产 agent 非常关键的架构层:observability。
queryProfiler.ts 不是简单计时器,而是在把 query pipeline 拆成可诊断阶段:
* - query_context_loading_start/end * - query_microcompact_start/end * - query_autocompact_start/end * - query_tool_schema_build_start/end * - query_api_request_sent * - query_first_chunk_received * - query_tool_execution_start/end这意味着系统不满足于“这轮慢了”,而是要知道慢在:
- system/context 装配
- microcompact / autocompact
- tool schema 构造
- API 往返
- 工具执行
promptCacheBreakDetection.ts 又在另一层回答“为什么这轮缓存失效了”:
parts.push(`system prompt changed${charInfo}`)parts.push(`tools changed${toolDiff}`)parts.push('fast mode toggled')parts.push(`global cache strategy changed (...)`)这类诊断在 agent runtime 里非常少见,但非常必要。只要 prompt、tools、betas、cache scope 任一层发生漂移,性能与成本都会发生非线性变化;如果系统不能指出 root cause,开发者就只能凭感觉调。
analyzeContext.ts 则把“上下文到底被谁吃掉了”做成了可计算问题。它不是粗算 message token,而是重建 effective system prompt,再分别统计:
- system prompt sections
CLAUDE.md/ memory 文件- built-in tools / deferred tools / MCP tools
- agent definitions
- slash commands
- message breakdown
对 agent 开发者来说,这一层的启发非常直接:
- 没有可观测性,就没有可演化的 harness
- 要能解释慢在哪、贵在哪、cache 为什么断、上下文被谁吃掉
- 主 loop、prompt 栈、tool surface、memory surface 都应该有自己的诊断面
一旦把这层也加回整体蓝图,agent runtime 的轮廓就更完整了:它不只是一个会跑的系统,还是一个能解释自己为何这样跑、何时开始跑坏、坏在何处的系统。
7. 工程化收尾:把状态显式化,尽量少靠 vibe coding
如果把这份源码当成下一代 runtime 的反向需求文档,最直接的一条工程建议就是:不要再让关键流转主要靠布尔变量、注释、约定和“开发者脑内状态机”维持。
query.ts 现在已经事实上是一台状态机,只是它的状态分散在:
transition.reasonstopHookActivependingToolUseSummaryhasAttemptedReactiveCompactmaxOutputTokensRecoveryCount- 外围 attachment / permission / task queue 副作用
这种形态还能跑,但很难局部验证,也很难安全演化。对下一代实现来说,最值得认真考虑的是把高风险流转改成显式状态图,比如用 xstate[1] 这类状态机/状态图框架,或至少采用同类建模方法。
最适合状态机化的,不是全系统,而是下面几条最复杂、最容易出错的流:
- turn engine
- 把
sampling -> tool mediation -> continuation -> compact retry -> recovery exhausted -> completed画成显式 machine。 prompt_too_long、max_output_tokens、stop hook、fallback、permission wait 都应该是事件,而不是 scattered branches。- permission flow
requested -> classifier_precheck -> waiting_user -> approved/denied -> replay_tool_use -> continue。- 现在 orphaned permission replay 之所以显得“巧”,本质是状态所有权不清。状态机化之后,这条 replay 会自然变成一条合法迁移,而不是异常补丁。
- task / remote-agent lifecycle
created -> running -> idle-but-not-finished -> completed | failed | killed | archived。- 远程 session 的
404 / recoverable auth failure / archived差异很适合放到 machine guards 里,而不是散落在 poller 分支里。 - mailbox / teammate delivery
queued -> drained -> injected -> acknowledged。- 现在
pendingMessages已经在做这件事,但语义还埋在 task helper 里。显式化之后,协作协议会更容易测试和可视化。
这里不是说 “用了 XState 就会自动变好”,而是说这类 runtime 已经到了该用显式状态图取代隐式流程拼接的阶段。是否选 XState 可以讨论,但“把主循环、权限恢复、任务生命周期、协作协议都建成可视化、可穷举、可测试的状态图”这件事本身,已经不太像可选优化,而更像必要的工程升级。
如果真要落地,比较稳的方式不是一次性把全系统迁进去,而是:
- 先从
query的恢复图抽 machine - 再把 permission replay 和 remote task poller 抽出来
- 让旧逻辑做 invoked services,新 machine 先只接管状态与迁移
- 配套补 event log、snapshot tests、failure matrix
这样可以逐步把 God Loop 切开,而不是做一次高风险重写。
另一条同样重要的工程建议,是尽量避免 agent/runtime 开发里的 vibe coding 通病。这类系统最容易出现的坏味道,不是代码丑,而是 “局部补丁持续成功,于是全局结构悄悄失控”。
最常见的几种通病大概是:
- 把补丁误当架构:一次 orphaned replay、一次 synthetic sentinel、一次 attachment 注入都能修问题,于是系统最后变成补丁编排器。解决方式不是禁止补丁,而是每补一次就追问:这在修哪条不变量?owner 是谁?以后该收敛到哪个控制面?
- 把字符串 prompt 当自由文本,而不是协议:一句 “IMPORTANT:” 看起来加得很快,但久而久之 system prompt、attachment prompt、tool prompt、classifier prompt 会互相打架。解决方式是把 prompt section registry、cache boundary、priority order、attachment channel 明文化,并做 prompt diff 测试。
- 把共享上下文当万能胶:
AppState和ToolUseContext一旦什么都能放,就会什么都想放。解决方式是区分只读查询、事件提交、状态所有权,不要让所有子系统都能直接 mutate 同一片状态。 - 只验证 happy path,不验证恢复图:生产 agent 最难的不是首轮成功,而是中断、拒绝、续写、compact、resume、fork、remote reconnect。解决方式是把 failure matrix 当一等测试对象,而不是只测“普通提问 -> 普通回答”。
- 只追求功能上线,不追踪 cache / token / latency 退化:agent 系统很容易功能越来越强,但每轮越来越贵、越来越慢、越来越不稳定。解决方式是把 prompt cache、context usage、tool schema size、TTFT、恢复次数都当成 release 指标,而不是 debug 时临时看看。
可以把这几条压成一句更硬的工程纪律:agent runtime 不适合靠“先写起来,后面再收”推进;任何会跨 turn、生存于恢复路径、影响 cache 或影响权限边界的逻辑,都应该先有状态模型、约束说明和诊断面,再谈实现细节。
这也是这份源码给人的最终启发。真正成熟的 agent 工程,不是功能堆得多快,而是是否能持续把“聪明行为”压回到可推理、可恢复、可测、可观测的结构里。
要是做不到这一点,系统迟早会从 agent runtime 退化成一团勉强还能工作的 prompt middleware。
References
xstate:https://github.com/statelyai/xstate