 夜雨聆风
夜雨聆风





第二大脑不是装个插件就行:Obsidian + Claude 正确打开方式
Karpathy 又发推了。
这次不是代码,不是教程,而是一套他正在自己用的”第二大脑”工作流。
4月3日,OpenAI 联合创始人 Andrej Karpathy 在 X 上分享了他用 LLM 管理个人知识库的完整方案。推文发出去不到12小时,配套的 GitHub Gist 狂揽了 2900+ stars、559 次 forks(数据截至发稿时)。
说实话,这个数字比我预想的还要夸张。
先说他的核心思路。
Karpathy 把个人知识管理做成了一个四阶段循环:Data Ingest → Compile → Query & Enhance → Lint & Maintain。
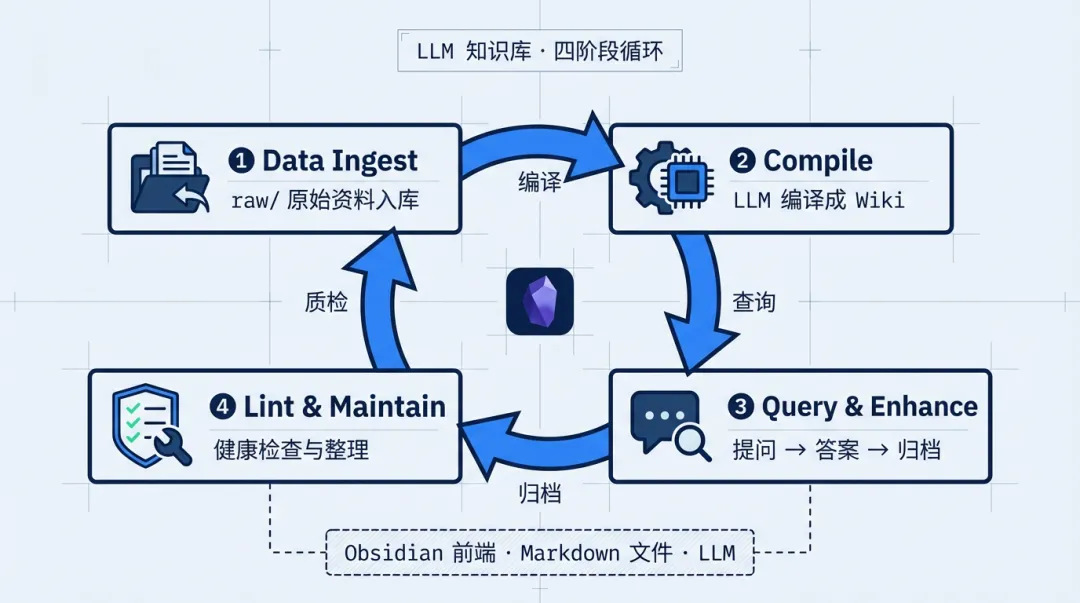
具体怎么跑?他用了一个 raw/ 目录存放所有原始资料——文章、笔记、网页剪藏,什么都行。然后让 LLM 把这些 raw 材料”编译”成 Wiki,也就是 Obsidian 里的 .md 文件集合。
有意思的是这个编译器类比:raw/ 是源代码,LLM 是编译器,Wiki 是可执行文件,Health Checks 相当于测试套间,而 Query 就是运行时。
他还特别强调了一个反直觉的点:不需要 RAG。他的知识库规模大约是100篇文章、40万词,直接塞进上下文窗口处理,效果反而更好。
工具栈极其简单:Obsidian + Web Clipper + Marp + Markdown。没有复杂的向量数据库,没有 Embedding 调参,就是朴素的 Markdown。
但真正让我多看了两眼的部分,来自 Obsidian CEO Steph Ango(@Kepano)。
他在 Karpathy 的推文下面直接插了一句:”污染防护”(Contamination Mitigation)。
什么意思?Kepano 的建议是:保持个人 vault 干净,把 AI 生成的内容隔离在单独的”脏 vault”里,只把提炼后的洞察合并到核心笔记库。
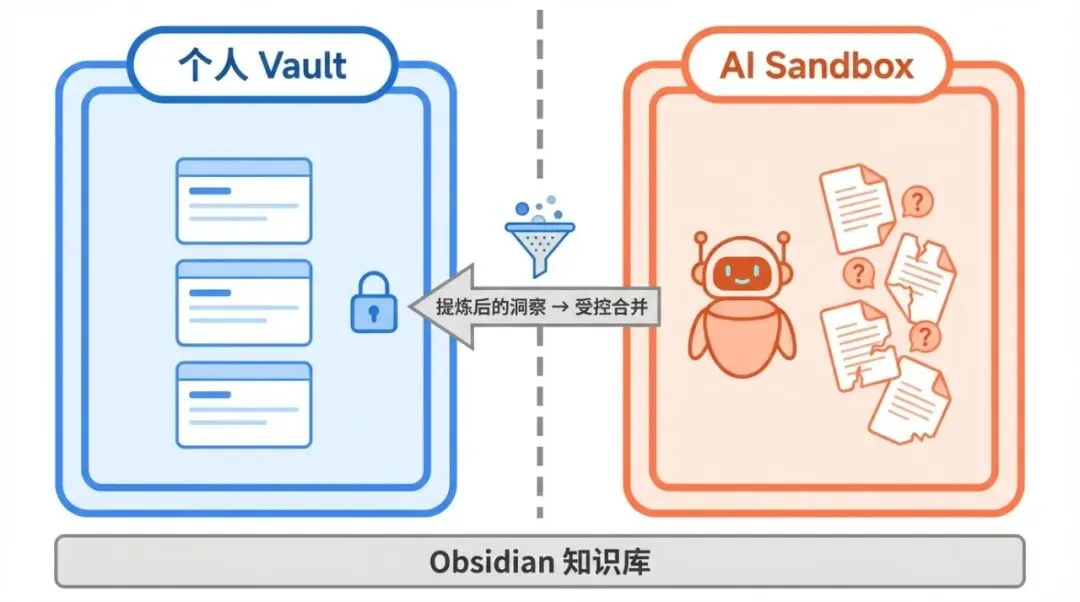
这个类比很妙——像数据分析里的数据分级。让 AI 在沙箱里自由探索,把进入核心知识库的步骤做成受控环节。LLM 会产生大量中间产物,但不是所有产物都值得进入你的长期记忆。
这是 Obsidian CEO 对 Karpathy 工作流的直接背书,加上了一个很关键的设计建议。
现在问题来了:这东西普通人能跑通吗?
Reddit r/ObsidianMD 板块里有个帖子拿到了163票、39条评论(数据截至发稿时)。有人现身说法:
“我们用这套工作流,让 Claude Code 一夜之间从一个内容创作者的完整目录里编译出了 1150+ 条笔记、4700+ 个关系类型。Obsidian 做前端,LLM 管理所有数据。”

不是演示,是真实规模。这个数字让我重新审视了这套方案的可行性边界。
GitHub 那边也已经有人在跟进:rvk7895/llm-knowledge-bases 是一个 Claude Code 插件,实现了 compile → query → lint → evolve 全流程。Obsidian Seed 则通过对话来个性化搭建 vault 结构,自动生成 reader-context.md。
不是概念了,已经有工具可以用了。
但我必须说点不好听的。
独立开发者 Glen Rhodes 的批评相当到位:
“他描述的本质上是一套 CLI 工具 + 自己 vibe code 的搜索引擎 + 各种 Obsidian 插件 + 大量 prompt engineering。有效,但需要你是 Andrej Karpathy 才能搭建这套东西。”
这话有点刻薄,但不算冤枉。Karpathy 的工作流依赖大量隐性的工程判断——什么时候该合并、什么时候该拆、哪些关系值得建立。这些在他脑子里,不在文档里。
Reddit 上还有一条更具体的质疑:
“我没有验证 Karpathy 到底有没有自己去核实放进 .md 文件里的那些信息。”
LLM 生成的内容会有幻觉,这个问题是真实存在的。
如果我们把时间线拉长一点看,Karpathy 这条路径其实非常清晰。
2025年2月,他在搞”Vibe Coding”。2025年12月,他说 AI 是程序员的”9级地震”。2026年2月,他提出”Agentic Engineering”,人写不到1%的代码。现在,2026年4月,他的关注点正式跳出了代码领域。
背后有个更大的叙事:Markdown 正在成为 AI 时代的”编程语言”。代码是 Markdown,笔记是 Markdown,文档是 Markdown,LLM 能读能写的东西,最后都沉淀成 .md 文件。
如果这个判断是对的,那 Karpathy 这套工作流就不只是一套笔记方法论,而是某种基础设施的雏形。
所以问题来了:
你愿意把自己的”第二大脑”完全交给 LLM 管理吗?边界在哪里?
你试过类似方案吗?