 夜雨聆风
夜雨聆风





一文读懂AI Agent子代理的创建与编排
第 8 章 子代理的创建与编排
作者:李学恒、林建浩、严翊歆
本文节选自《经济金融智能体:入门与实战》。该书正在编写修订中,面向经管学生、金融从业者和对 AI 智能体感兴趣的任何大众读者,教你用 Claude Code / Opencode / Codex 等工具来设计和管理 AI 智能体系统。全书覆盖从环境搭建、Skills和子代理等智能体基础概念、到业务和科研应用案例的完整路径,敬请关注。
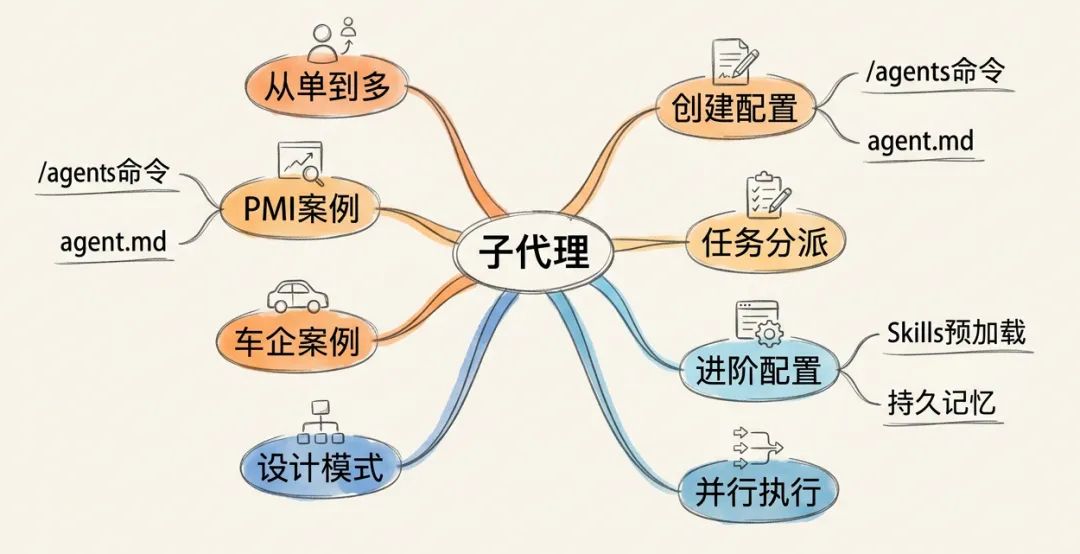
本章核心概念速查
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
agent.md |
|
|
|
|
|
|
|
|
|
|
|
|
|
/agents
|
|
|
|
@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Skill 解决的是单任务复用。子代理解决的是分工、并行和整合。 当一项工作需要多个执行者在独立上下文中分别完成任务,再把结果汇总到一起时,单个 Skill 就不够了。
这一章围绕子代理(subagents)回答五个问题:为什么要创建子代理,怎么创建子代理,任务怎么拆给子代理,子代理的边界怎么划,主代理与子代理之间怎么高效传递信息而不浪费上下文窗口。
8.1 从单智能体到多智能体
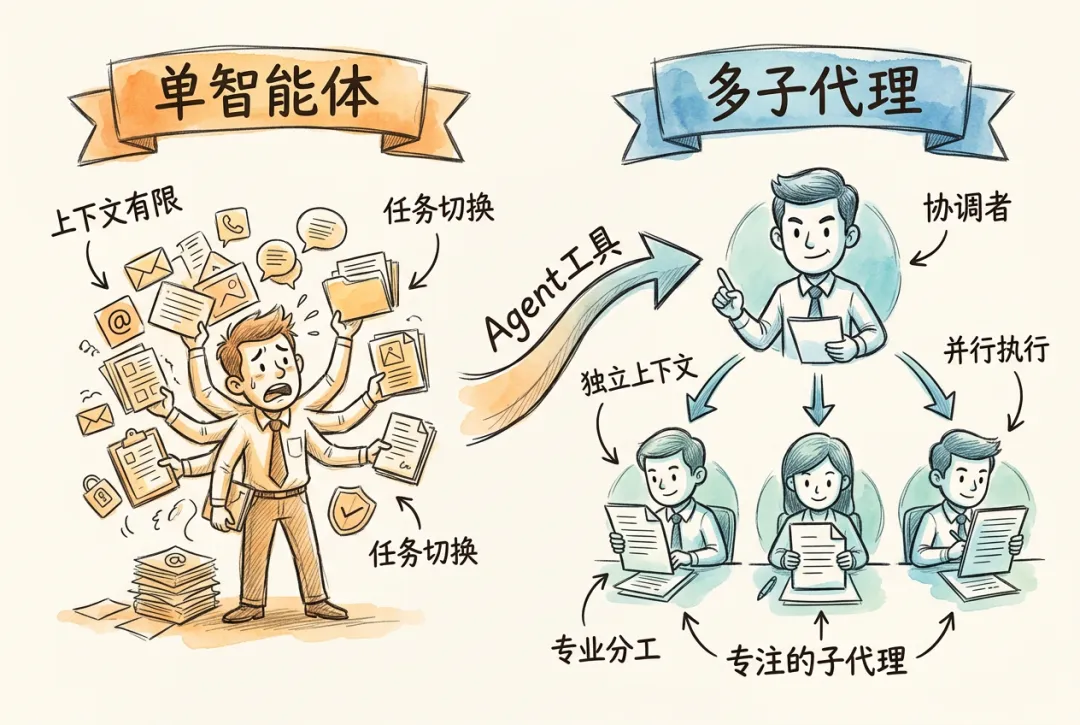
在日常使用中,一个 Claude Code 智能体已经能处理很多工作。但任务复杂到一定程度后,单个智能体的表现会明显下降。原因主要有三点:
-
• 上下文窗口有限:所有中间结果堆在同一个窗口里,窗口占满后前面的信息会被压缩甚至丢失 -
• 任务切换成本高:不同任务的信息会互相干扰,产生上下文污染(Context Contamination) -
• 串行执行效率低:分析三家公司的财务报表只能逐一进行,但三家公司的分析彼此并无依赖
子代理不是为了把任务拆得更碎,而是为了拆得更稳。 主代理负责分派目标和整合结果,子代理负责在独立上下文里完成各自的工作。这样既能并行推进,也能减少不同子任务之间的相互干扰。
多智能体的实证效果与成本
Anthropic 在 2025 年公开了多智能体研究系统的实测数据。在 BrowseComp 基准测试中,token 使用量解释了 80% 的性能差异。多智能体的核心优势,是让系统能在同一问题上投入更多 token 和更多并行搜索。
以 Claude Opus 做主代理、Claude Sonnet 做子代理的配置,在内部研究评估中比单个 Claude Opus 高出 90.2%。模型本身的升级也会放大 token 的使用效率——从 Sonnet 3.7 升到 Sonnet 4 带来的提升,比单纯把 token 预算翻倍还大。
多智能体系统的 token 消耗远高于单智能体。Anthropic 的数据显示,普通智能体任务大约消耗聊天的 4 倍 token,多智能体系统约为 15 倍。从经济性看,多智能体更适合任务价值足够高、值得为更高质量付费的场景。
并非所有任务都适合拆成多智能体。以下场景目前更适合单智能体处理:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
成本意识
在金融分析场景中,分析一家上市公司的年报可能就要消耗数万 token。如果同时分析十家公司,多智能体的开销会迅速增长。决定是否采用多智能体之前,先评估任务价值是否匹配成本。
子代理的核心特征
子代理(Subagent)是由主代理按需生成的独立智能体实例,具有四个核心特征:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
子代理和传统的函数调用(Function Call)都能完成特定工作,但本质区别在于:函数调用是确定性的,给定输入就会得到固定输出;子代理具有自主性,给定目标后可以自行决定使用什么工具、采用什么顺序,以及如何处理意外情况。任务一旦涉及判断、选择和适应,子代理通常更合适。
知识卡片
独立上下文是子代理最关键的特性。 主代理发起子代理时,子代理会获得新的上下文空间,其中只有任务指令和必要信息。这种隔离既能减少无关信息干扰,也能避免主代理被子任务细节占满。
Claude Code 自带一组内置子代理,主代理会在合适的时机自动调用它们:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
除了内置子代理,你还可以通过 agent.md 文件创建自定义子代理,配置专属的系统提示词、工具权限和 Skills。
一个直观的例子
假设你要分析贵州茅台、比亚迪和宁德时代三家公司的最新财务报表,并生成一份对比报告。
单智能体方式:一个智能体依次分析三家公司,所有财务数据、计算过程和分析结论都堆积在同一个上下文窗口中。到第三家公司时,前两家的关键数据就可能被遗漏。
多子代理方式:主代理把任务拆成四个环节,三个子代理分别负责一家公司的财务分析,最后由主代理整合三份报告并生成对比结果。三个分析子代理可以同时运行,各自在独立上下文中专注分析。
请创建 3 个财务分析子代理,并行分析贵州茅台、比亚迪和宁德时代三家公司的最新年报。主代理职责:- 只负责创建子代理、跟踪进度和整合结果- 不自己展开单家公司分析- 待 3 个子代理全部完成后,读取各自输出文件并生成横向对比报告子代理 1:负责贵州茅台子代理 2:负责比亚迪子代理 3:负责宁德时代每个子代理都要:- 只分析自己负责的公司- 计算盈利能力、偿债能力和运营效率指标- 将结果保存到 `output/{股票代码}-analysis.md`- 只返回一句状态摘要,不返回完整分析内容最终由主代理生成 `output/comparison-report.md`。这类写法把子代理数量、职责和主代理边界都说清楚了,主代理只做调度和整合。主代理保留干净上下文,最后只做整合。
8.2 子代理的创建与配置
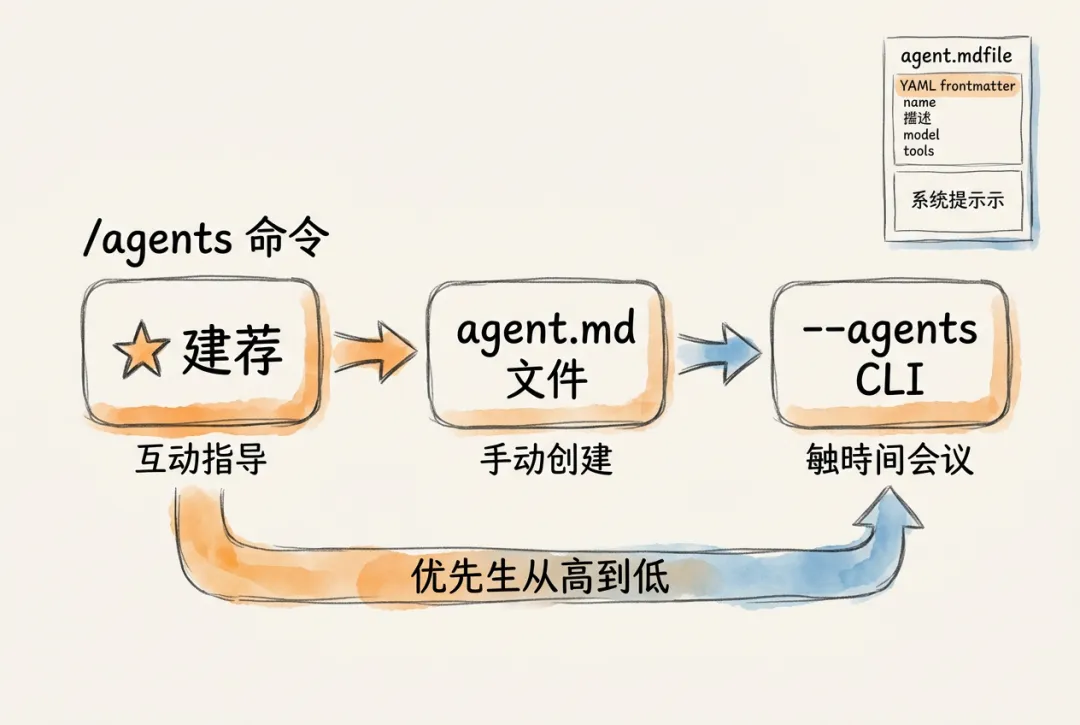
Claude Code 提供三种创建子代理的方式。三者各有适用场景,下表概览:
|
|
|
|
|
|---|---|---|---|
/agents
|
/agents |
|
|
|
|
.claude/agents/ 下创建文件 |
|
|
--agents
|
|
|
|
使用 /agents 命令创建
/agents 是管理子代理最直接的入口。在 Claude Code 对话中输入 /agents,会打开一个交互式界面,支持查看、创建、编辑和删除子代理。
创建流程分 8 步:
-
1. 运行 /agents,选择 Create new agent -
2. 选择存储位置:Project( .claude/agents/,仅当前项目)或 Personal(~/.claude/agents/,所有项目可用) -
3. 选择 Generate with Claude,用自然语言描述子代理的用途 -
4. 选择工具权限:只读工具 或 全部工具 -
5. 选择运行模型:Sonnet / Opus / Haiku -
6. 选择背景颜色(用于在界面中区分不同子代理) -
7. 配置记忆:User scope / Project scope / None -
8. 按 s或Enter保存,或按e在编辑器中打开微调
以创建一个财报分析师子代理为例:
/agents→ Create new agent → Project→ Generate with Claude描述:A financial statement analyzer that reads annual reports,calculates profitability ratios (gross margin, net margin, ROE),solvency ratios, and operating efficiency metrics.It should cross-validate figures and flag anomalies above 20%.→ 选择工具:Read-only tools + Bash(python *)→ 选择模型:Sonnet→ 选择颜色:蓝色→ 记忆:Project scope→ 按 s 保存Claude 会根据描述自动生成 name、description 和系统提示词,保存为 .claude/agents/financial-analyzer.md。保存后子代理立即可用,不需要重启会话。
命令行快速查看
在终端运行
claude agents(注意没有斜杠),可以在不启动交互会话的情况下列出所有已配置的子代理,按来源分组显示,并标注同名时哪个处于活跃状态。
手动编写 agent.md 文件
对于需要精确控制每个配置字段的场景,可以直接在 .claude/agents/ 或 ~/.claude/agents/ 目录下创建 Markdown 文件。文件格式是 YAML frontmatter + Markdown 正文,frontmatter 定义元数据和配置,正文就是子代理的系统提示词。
以财报分析师为例:
---name: financial-analyzerdescription: > Analyzes financial statements and calculates key ratios. Use when the user asks to analyze financial reports, calculate financial ratios, or evaluate company financial health.model: sonnettools: - Read - Grep - Bash(python *)memory: project---## 角色定位你是一位财务报表分析专家。## 核心职责1. 提取三大财务报表关键指标2. 计算盈利能力(毛利率、净利率、ROE)、偿债能力(资产负债率、流动比率)和运营效率(总资产周转率)3. 进行同比/环比分析,识别异常波动4. 将分析结果保存到指定路径## 输出格式分析结果以 Markdown 表格形式呈现,包含:- 指标名称、当期值、上期值、同比变化- 异常指标的文字说明- 整体财务健康评估## 质量标准- 所有数值交叉验证(资产 = 负债 + 所有者权益)- 计算保留两位小数- 异常波动(>20%)必须标注并给出可能原因子代理只接收 agent.md 中的系统提示词和基本环境信息(如工作目录),不会继承主对话的完整系统提示。但它会自动遵循项目的 CLAUDE.md 规则。
手动添加的文件需要重启会话才能加载,或者运行 /agents 立即刷新。
关于 description 字段
description是 Claude 决定是否委派任务的核心依据。写法上建议用英文,清晰描述该子代理处理什么类型的任务、在什么场景下应该被调用。模糊的描述会导致委派不准确,过于宽泛的描述会导致不该触发时也触发。
完整字段参考
以下是 agent.md frontmatter 支持的全部字段。只有 name 和 description 是必填的,其余均为选填。
|
|
|
|
|
|---|---|---|---|
name |
|
|
|
description |
|
|
|
model |
|
|
sonnet、opus、haiku、完整模型 ID(如 claude-opus-4-6)或 inherit。默认 inherit |
tools |
|
|
|
disallowedTools |
|
|
|
permissionMode |
|
|
default、acceptEdits、dontAsk、bypassPermissions、plan |
maxTurns |
|
|
|
skills |
|
|
|
memory |
|
|
user(跨项目)、project(项目级,可版本控制)、local(项目级,不入版本控制) |
background |
|
|
true 则始终作为后台任务运行。默认 false |
effort |
|
|
low、medium、high、max(max 需 Opus 4.6 或更高版本支持) |
工具控制:白名单与黑名单
白名单方式(tools) 明确列出子代理可以使用的工具,未列出的一律不可用:
tools: Read, Grep, Glob, Bash黑名单方式(disallowedTools) 从继承的工具集中排除特定工具,其余照常使用:
disallowedTools: Write, Edit这种写法适合只需禁止写操作的场景,比列举所有允许的工具更简洁。如果两者同时设置,Claude Code 先应用 disallowedTools 移除黑名单中的工具,再从剩余工具中解析 tools 白名单。
工具权限的最小化原则
如果子代理的任务只需要读取文件和搜索代码,就不要给它写入权限。工具权限越少,误操作风险越低。一个常见做法是先用只读权限测试,确认需要写入时再放开。
–agents CLI 标志与存储优先级
--agents 标志允许在启动 Claude Code 时通过 JSON 临时定义子代理,仅在当前会话有效,不会写入磁盘。适用于快速测试或自动化脚本:
claude --agents '{ "earnings-checker": { "description": "Validates earnings data extraction", "prompt": "你是财报数据校验专家。检查提取的财务数据是否与原始报表一致。", "tools": ["Read", "Grep", "Bash"], "model": "haiku" }}'子代理的存储位置决定了可见范围和优先级。当多个位置存在同名子代理时,高优先级的生效:
|
|
|
|
|---|---|---|
|
|
--agents
|
|
|
|
.claude/agents/ |
|
|
|
~/.claude/agents/ |
|
|
|
agents/ 目录 |
|
模型选择策略
不同任务对模型能力的需求不同,合理选择可以在质量和成本之间取得平衡:
|
|
|
|
|---|---|---|
|
|
opus
claude-opus-4-6 |
|
|
|
sonnet
claude-sonnet-4-6 |
|
|
|
haiku |
|
|
|
inherit
|
|
模型选择不是越强越好,而是要和任务难度匹配。一个常用做法是先用 sonnet 测试,输出质量不足时再切换到 opus。
模型选择技巧
金融数据提取(从年报中抽取特定数值)用 haiku 即可。财务指标的趋势分析和异常识别适合 sonnet。综合多维度数据做投资建议或撰写深度分析报告时,考虑用 opus。
8.3 任务分派与输入输出设计
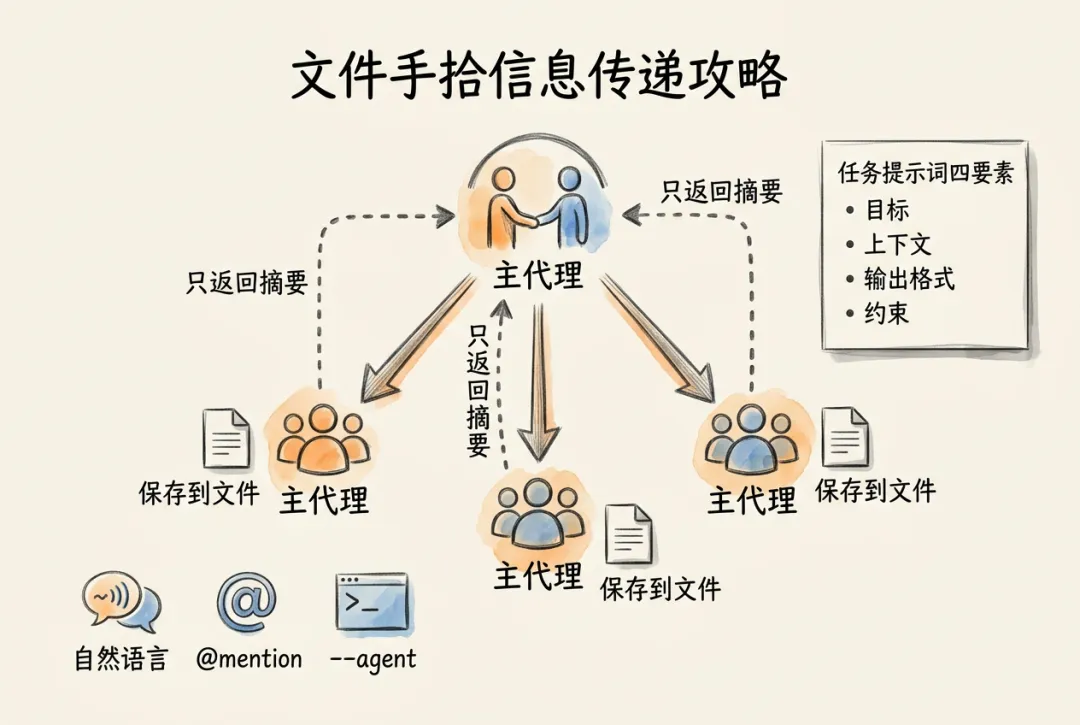
任务要说清楚,信息要传对,输出要约定好。
调用子代理的三种方式
Claude Code 提供三种不同粒度的子代理调用方式:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
@"agent-name (agent)" |
|
|
--agent
|
claude --agent agent-name |
|
|
自然语言调用是最常见的方式。在提示词中提到子代理的名称或描述其职责,Claude 会根据已有子代理的 description 字段判断是否委派:
用 financial-analyst 子代理分析贵州茅台的盈利能力@ mention 提供了更强的控制力。输入 @ 后从 typeahead 列表中选择子代理,可以确保指定的子代理一定会被调用:
@"financial-analyst (agent)" 分析贵州茅台 2024 年三项盈利能力指标如果子代理名称不含空格,可以直接手动输入 @financial-analyst;含空格时必须用引号包裹。
--agent 会话级运行将整个 Claude Code 会话替换为该子代理的系统提示词、工具限制和模型配置。适合把某个专属子代理作为独立工作台使用。
子代理每次调用都会创建新实例。如果需要继续已完成的子代理的工作,Claude 可以通过 SendMessage 工具向已完成的子代理发送新消息,子代理自动在后台恢复运行,保留之前所有的工具调用记录和推理过程。
任务提示词的写作要领
子代理收到的提示词会直接影响执行质量。一个好的任务提示词包含四个要素:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一个完整的任务提示词示例:
请创建 1 个财务分析子代理,专门分析贵州茅台 2024 年度财务报表的盈利能力。主代理职责:- 只负责发起子代理和接收状态摘要- 不自己展开财务指标计算输入数据:data/maotai-2024.csv参考说明:data/financial-metrics-guide.md 中有指标定义子代理任务:1. 计算毛利率、净利率、ROE 三项指标2. 与 2023 年数据对比,计算同比变化3. 对异常波动(变化超过 20%)给出可能原因输出要求:- 将完整分析报告保存到 output/maotai-profitability.md- 报告包含数据表格和文字分析- 数值保留两位小数- 完成后只返回一句话摘要说明结果委派精确度
好的委派应把五个要素写清楚:清晰目标、输出格式、工具建议、来源范围和任务边界。对比两种写法:❌ 分析一下新能源行业;✅ 从 Wind 数据库提取 2024 年国内前五大新能源车企的季度营收数据,计算同比增长率,结果保存为 JSON 到
temp/ev-revenue.json。精确度越高,执行质量越稳定。
文件化信息传递策略
File Handoff 是使用子代理时最重要的实践原则。 核心思想:子代理将结果保存到文件,只返回简短摘要。
子代理返回的内容都会进入主代理的上下文窗口。如果三个子代理各自返回一份 3000 字的分析报告,主代理就要额外承载 9000 字内容,这部分空间本应用于决策和整合。
核心原则:保护主代理的上下文
主代理的上下文窗口最稀缺。 子代理应把详细结果保存到文件中,只向主代理返回状态摘要,例如:分析完成,报告已保存到
output/maotai-profitability.md,ROE 为25.3%,同比下降2.1个百分点。
文件化传递分三个环节:
-
1. 输入文件:将任务说明和参考资料写入指定路径,让子代理自行读取,而不是把大段文本塞进 prompt -
2. 输出文件:要求子代理将结果保存到约定路径(如 output/maotai-profitability.md) -
3. 状态摘要:子代理完成后只返回 1-2句话的摘要
这种有意识地管理信息去向的做法,就是上下文工程(Context Engineering)的核心思想。每次决定一条信息该放进 prompt 还是写入文件,本质上都在做上下文工程的决策。
投入规模与任务复杂度匹配
智能体不擅长自己判断一项任务该花多大力气。Anthropic 的做法是直接在提示词里规定投入规模:
任务类型 子代理数量 金融场景举例 简单事实查询 不需要子代理 查询某只股票的最新收盘价 对比分析 2-4 个 对比三家公司的盈利能力指标 深度研究 5 个以上 行业深度报告、跨市场投资策略
输入输出的标准化设计
当多个子代理协作时,标准化的输入输出格式可以减少出错和返工。
JSON 结构化数据适合传递数值型结果:
{ "company": "贵州茅台", "period": "2024年度", "metrics": { "profitability": { "gross_margin": 0.915, "net_margin": 0.482, "roe": 0.253 } }, "anomalies": [ { "metric": "roe", "change": -0.021, "note": "受投资收益下降影响" } ]}Markdown 文档适合人类直接阅读的报告。先约定统一的文档结构,可以让不同子代理生成的报告保持一致:
# [公司名] [年度] 财务分析报告## 概要[2-3 句话的核心结论]## 数据表| 指标 | 当期值 | 上期值 | 同比变化 ||------|-------|-------|---------|## 分析[文字分析]约定输出路径的命名规则
建议采用
{任务类型}/{公司代码}-{分析维度}-{日期}.{格式}的命名方式,例如output/600519-profitability-20240331.md。统一的命名规则让主代理和后续流程能自动定位结果文件。
8.4 子代理的进阶配置
基础的 name、description、tools、model 四个字段已经能覆盖大部分场景。当子代理需要调用特定 Skill、积累跨会话知识或在后台并行运行时,就需要用到进阶配置字段。
以下是三个进阶字段的功能概览:
|
|
|
|
|---|---|---|
skills |
|
|
memory |
|
|
background |
|
|
Skills 预加载
子代理不继承主对话中已匹配的 Skills。如果子代理需要遵循某个 Skill 的指令,必须在 frontmatter 的 skills 字段中显式列出。列出后,Skill 的完整内容会在子代理启动时注入其上下文。
---name: report-writerdescription: 撰写行业研报初稿,遵循团队研报模板和文献引用规范model: opustools: Read, Write, Edit, Grep, Glob, Bashskills: - report-template - paper-lookup---你是研报撰写子代理。按照预加载的研报模板组织内容结构,使用 /paper-lookup 检索和引用学术文献。将初稿保存到 output/ 目录,只返回状态摘要。Skills 预加载 vs Skill 的 context: fork
两者底层机制相同,区别在于控制权。
skills字段由子代理的 agent.md 控制,子代理定义自己需要哪些 Skill;context: fork由 Skill 的 SKILL.md 控制,Skill 定义自己应该运行在哪个子代理中。根据管理偏好选择其中一种,避免两边重复配置。
持久记忆
默认情况下,子代理的知识随会话结束而消失。memory 字段让子代理拥有跨会话的持久目录。三种作用域:
|
|
|
|
|---|---|---|
user |
~/.claude/agent-memory/<name>/ |
|
project |
.claude/agent-memory/<name>/ |
|
local |
.claude/agent-memory-local/<name>/ |
|
启用后,子代理的行为会发生三个变化:系统提示中自动注入记忆目录下 MEMORY.md 的前 200 行;Read、Write、Edit 工具自动启用;当 MEMORY.md 超过 200 行时,子代理会收到整理提示。
随着使用次数增加,子代理会逐步积累对特定领域的认知。这些知识在无状态子代理中每次都需要从头建立。
记忆管理
官方推荐以
project为默认作用域。记忆目录不会自动清理,建议在子代理的系统提示中加入整理指令。project作用域的记忆会被提交到版本控制,注意不要在其中写入敏感信息。
后台运行
子代理默认在前台运行,阻塞主对话直到完成。设置 background: true 后,子代理在后台运行,主对话可以继续处理其他事务。
后台运行的权限机制
后台子代理无法中断你的工作来提问权限,所以 Claude Code 会在启动前一次性询问所有可能需要的权限。启动后,已批准的自动通过,未批准的自动拒绝。运行中的前台子代理也可以按 Ctrl+B 随时切换到后台。
8.5 并行执行与结果集成
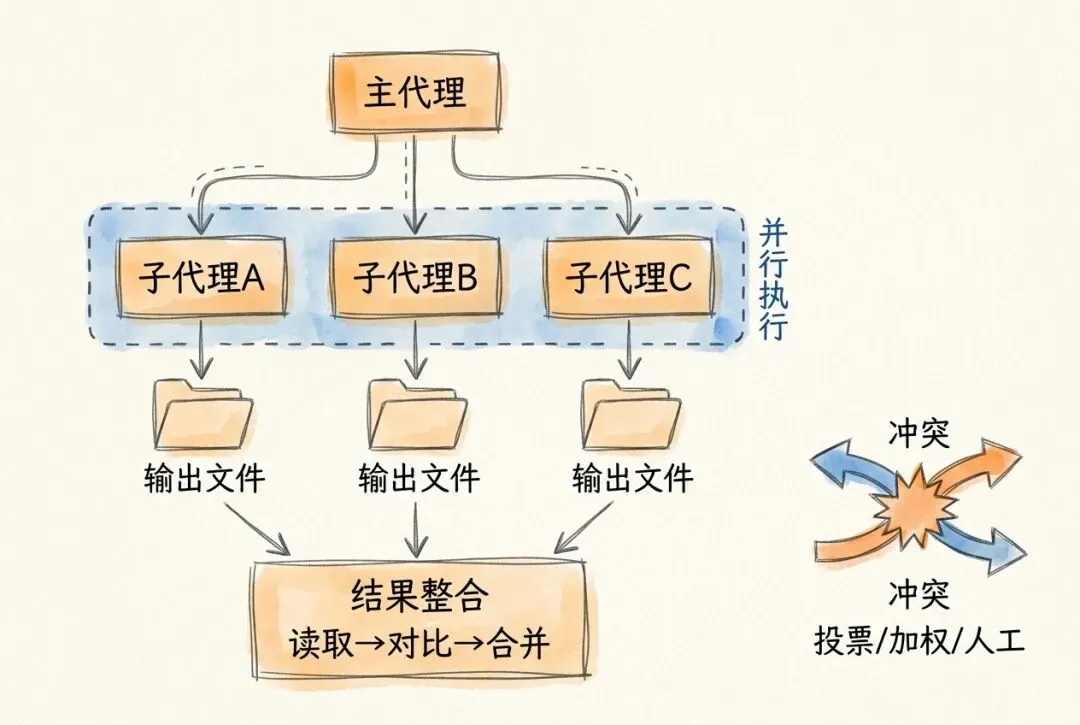
能并行的前提,不是任务多,而是任务彼此独立。
识别独立任务
并行执行的前提是任务之间相互独立——一个任务的输出不被另一个任务所需要。判断方法:如果去掉任何一个任务,其他任务仍然能正常执行,这些任务就是独立的。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|---|---|
|
|
|
|
|
|
并行分派与两层并行
在 Claude Code 中,并行分派通常是在一条指令中同时描述多个独立任务:
请创建 3 个财务分析子代理,并行分析以下三家公司的 2024 年度财务报表:1. 贵州茅台(600519)- 数据文件 data/600519-2024.csv2. 比亚迪(002594)- 数据文件 data/002594-2024.csv3. 宁德时代(300750)- 数据文件 data/300750-2024.csv主代理职责:- 只负责创建这 3 个子代理、等待完成并整合结果每个子代理的分析内容相同:- 计算盈利能力(毛利率、净利率、ROE)- 计算偿债能力(资产负债率、流动比率)- 计算运营效率(总资产周转率)- 只写入 `output/{股票代码}-financial-analysis.md`- 只返回一句状态摘要仅在主代理层面做并行,有时还不够快。Anthropic 把并行拆成两层:第一层,主代理同时拉起多个子代理,每个负责一个研究方向;第二层,每个子代理内部也并行发起多个工具调用。这种做法让复杂研究任务的耗时最多降低了 90%。
两层并行示例:新能源行业深度研究第一层并行(主代理调度):├── 子代理 1:负责比亚迪├── 子代理 2:负责宁德时代└── 子代理 3:负责理想汽车第二层并行(每个子代理内部):子代理 1 同时发起:├── 搜索 `比亚迪 2024 年报 盈利`├── 搜索 `比亚迪 海外市场 销量`└── 搜索 `比亚迪 电池技术 专利`启用两层并行
在给子代理的任务提示词中加一句:如果多个搜索之间互不依赖,请在同一轮中并行发起。这样可以鼓励子代理利用并行工具调用能力。
结果收集与整合
子代理完成后,主代理需要收集结果并完成整合。整合时主代理做三件事:统一格式(确保指标名称和计算口径一致)、横向对比(将相同指标放在一起比较)、综合判断(基于对比结果给出整体评估)。
# 三家公司财务对比报告(2024 年度)## 关键指标对比| 指标 | 贵州茅台 | 比亚迪 | 宁德时代 ||------|---------|-------|---------|| 毛利率 | 91.5% | 21.3% | 26.8% || 净利率 | 49.2% | 5.2% | 12.1% || ROE | 25.3% | 18.7% | 16.2% || 资产负债率 | 22.1% | 77.4% | 65.3% |处理结果冲突
当多个子代理的分析结果出现矛盾时,有三种常见处理策略:
-
• 投票制:多个子代理从不同角度分析同一问题,以多数结论为准。适用于判断类任务 -
• 加权制:根据子代理的专业领域赋予不同权重。财务分析师的盈利能力评估权重高于市场分析师 -
• 留存制:保留所有分析结果,标注来源和分歧点,交给人类决策者判断
金融分析中的冲突处理
在金融分析场景中,不同分析维度得出相反结论并不少见,例如基本面优秀但估值偏高。这不一定是错误,更可能反映了市场的复杂性。高风险决策里,留存分歧往往比强行统一更稳妥。
8.6 设计模式与常见误区
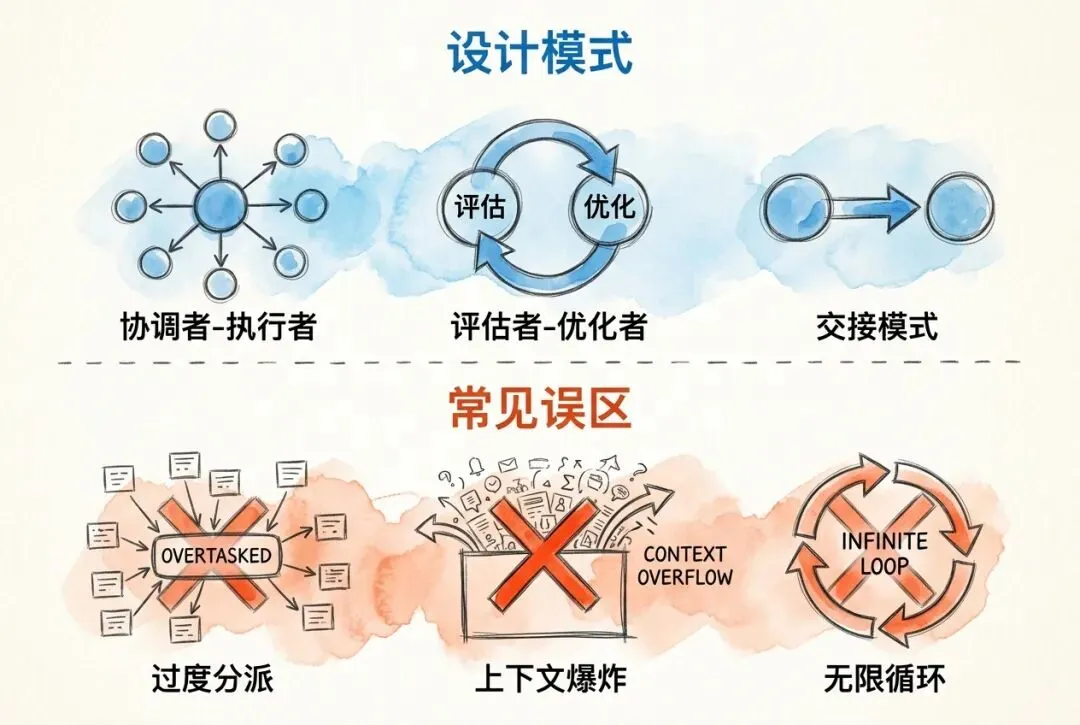
在子代理的实际应用中,已经形成了几种常见设计模式。设计模式的价值,不在命名,而在少走弯路。
协调者-执行者模式
协调者-执行者(Orchestrator-Workers)是最常见的多子代理模式。主代理作为协调者,负责拆分任务、分派工作和整合结果;多个子代理作为执行者,各自完成分配的子任务。
主代理(协调者)├── 拆分任务├── 分派给子代理├── 收集结果└── 整合报告子代理 A(执行者)→ 盈利能力分析子代理 B(执行者)→ 偿债能力分析子代理 C(执行者)→ 运营效率分析适用场景:任务可以自然拆分为多个独立的子任务,每个子任务的执行方法相似但输入不同。
金融应用:多公司对比分析、多市场数据采集、多维度风险评估。
评估者-优化者模式
评估者-优化者(Evaluator-Optimizer)模式中,一个子代理负责生成初稿,另一个负责评估并提出改进建议。两者交替工作,逐步提升输出质量。
循环流程:生成者子代理 → 产出初稿评估者子代理 → 审查并反馈生成者子代理 → 根据反馈修改评估者子代理 → 再次审查... (直到质量达标或达到最大轮次)适用场景:对输出质量有严格要求,需要多轮打磨才能达标。
金融应用:研究报告撰写(分析师写初稿、合规团队审查)、投资建议生成(策略组产出、风控组评估)。
知识卡片
没有停止条件的优化,不是打磨,而是空转。 常见做法是设置最大迭代次数,通常为
2-3轮,或定义可量化的通过标准。
交接模式
交接(Handoff)模式中,子代理之间按流水线方式传递任务。上游子代理的输出是下游子代理的输入,每个子代理完成一个阶段的工作后交给下一个。
子代理 A(数据采集) → 输出 temp/raw-data.json → 子代理 B(指标计算) → 输出 temp/calculated-ratios.json → 子代理 C(报告撰写) → 输出 output/final-report.md适用场景:任务由多个有依赖关系的阶段组成,每个阶段需要不同的专业能力。
金融应用:从年报 PDF 提取数据,再进行清洗和计算,最后生成分析报告。这三个阶段分别需要文档解析、数值计算和文本撰写能力。
交接模式和协调者 – 执行者模式的区别在于,前者是串行推进,后者通常用于并行分工。选择哪种模式,取决于子任务之间是否存在依赖关系。
隔离高频操作模式
子代理最直接的用途之一,是把产生大量输出的操作隔离到独立上下文中。运行测试套件、抓取网页文档、处理日志文件,这些操作的原始输出可能占据数千 token,但你真正需要的往往只是几行摘要。
用子代理运行完整的测试套件,只报告失败的测试及其错误信息把这类操作委派给子代理后,冗长的原始输出留在子代理的上下文里,主对话只收到精炼的结果。这对金融数据处理场景尤其有用:批量解析上百份公告、清洗大规模交易日志、跑回测报告,都适合用这种方式隔离。
链式子代理模式
对于多步骤工作流,可以让主代理按顺序调用多个子代理,前一个子代理的输出作为后一个的输入上下文。
先用 code-reviewer 子代理找出性能问题,然后用 optimizer 子代理修复这些问题在 CLAUDE.md 中定义工作流步骤,主代理会按顺序依次创建子代理执行。每个子代理完成后将结果返回主代理,主代理再把相关上下文传给下一个。
这种模式适合需要多种专业能力接力完成的任务:先用数据采集子代理获取财报,再用分析子代理计算指标,最后用写作子代理生成报告。与交接模式的区别在于,链式子代理由主代理显式编排调用顺序,而交接模式更强调通过文件系统自动串联。
何时委派给子代理
不是所有任务都适合交给子代理。官方文档给出了明确的选择指南:
适合在主对话中完成的任务:
-
• 需要频繁来回沟通或迭代调整的工作 -
• 多个阶段共享大量上下文(规划 → 实现 → 测试属于同一流程) -
• 你需要全程监控每一步的执行
适合委派给子代理的任务:
-
• 有大量探索或搜索操作(避免污染主对话上下文) -
• 可以并行处理的独立工作 -
• 需要限制特定工具权限或执行模式 -
• 任务本身自成体系,能以摘要形式返回结果
快速判断
如果一个任务的完整输出你并不需要看到,只需要知道结论,那它就适合交给子代理。反过来,如果你需要在执行过程中随时调整方向,就留在主对话里做。
还有两个容易混淆的替代方案:如果你想要可复用的提示词或工作流、但不需要隔离上下文,用 Skills 更合适;如果只是对当前对话中已有内容提一个快速问题,可以用 /btw 命令(”by the way”的缩写)——它能看到完整上下文但不调用任何工具,回答也不会写入对话历史,是最轻量的一次性询问方式。
禁用特定子代理
如果需要阻止某个子代理被调用,可以在
settings.json的permissions.deny中添加"Agent(subagent-name)",或在启动时传入--disallowedTools "Agent(name)"。
反模式警示
以下做法在实践中被证明效果不佳:
过度生成子代理
将每个微小步骤都交给独立的子代理处理,会导致子代理数量膨胀。创建和协调子代理本身有成本,当子任务过于简单时,如读取一个文件、转换一个格式,直接在主代理中执行更高效。
只有真正消耗上下文、或能并行推进的任务,才值得拆成子代理。
上下文爆炸
让子代理返回完整分析结果而不是状态摘要,会让大量内容回流到主代理的上下文里,导致上下文窗口被迅速占满。这是上下文工程中最常见的失误:没有在信息流入主代理之前做好过滤。解决方法很直接,严格执行文件化传递策略,把详细结果写入文件,只返回 1-2 句话的摘要。
无限循环
在评估者-优化者模式中,没有设置停止条件,两个子代理反复迭代,永远达不到完美状态。
解决方法:设置最大迭代次数,并定义可衡量的通过标准。
子代理之间过度协调
Anthropic 在早期版本中遇到过一个问题:多个子代理之间频繁互相更新状态,结果互相拖慢。子代理之间每多一层通信,延迟和出错概率都会增加。 设计原则是让子代理各自独立完成任务,通过文件系统交换结果,而不是在运行中互相等待。
为不存在的信息无休止搜索
子代理有时会对一条不存在的数据反复搜索,换不同关键词尝试,消耗大量 token 却没有结果。Anthropic 的做法是在提示词中设置搜索轮次上限:如果连续 3 次搜索都没有找到目标信息,就停下来报告未找到,而不是继续尝试。在金融数据采集中,这种情况尤其常见:某些非上市公司或早年数据根本不在公开数据库里,子代理需要学会及时止损。
设计检查清单
在设计多子代理工作流时,用这份清单确认每个关键环节:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
评估多子代理系统
多智能体系统不像传统程序那样总会走同一条路径。面对同一个输入,不同子代理可能查不同数量的来源、走不同路线,但最终都给出合理答案。所以评估的重点不是检查每一步是否按预设执行,而是看最终结果对不对、过程是否合理。
Anthropic 在构建多智能体研究系统时总结了三条评估经验:
尽早做小规模评估
在早期阶段,很多提示词调整的效果很大,可能一下把成功率从 30% 拉到 80%。这时候不需要上百题的大型测试集,20 个能代表真实使用场景的问题,往往已经足够判断改动有没有效果。
用 LLM 做评委
研究类产出通常是自由文本,很难用规则程序判断质量。Anthropic 用另一个 LLM 作为评委,根据评分标准检查事实准确性、引用准确性、完整性和来源质量。
在金融分析场景中,可以让一个独立的评估子代理检查分析报告:数据是否正确引用、计算是否交叉验证、结论是否有依据支撑。
注意涌现行为
多智能体系统会出现涌现行为:主代理的提示词稍做修改,所有子代理的行为都可能一起变化。最好的提示词不是一连串死命令,而是清楚的协作框架、分工方式和质量标准。
知识卡片
涌现行为(Emergent Behavior)指系统整体表现出单个组件不具备的行为特征。在多智能体系统中,主代理的一个小改动可能通过任务分派链路放大,导致所有子代理的行为模式同时偏移。这不一定是坏事,但需要通过评估来监控。
从简单开始
设计多子代理系统时,可以先从
2个子代理开始验证核心流程,确认正常后再逐步增加。一次性构建包含十余个子代理的复杂系统,调试成本会很高。
8.7 案例一:三家车企财务数据并行分析
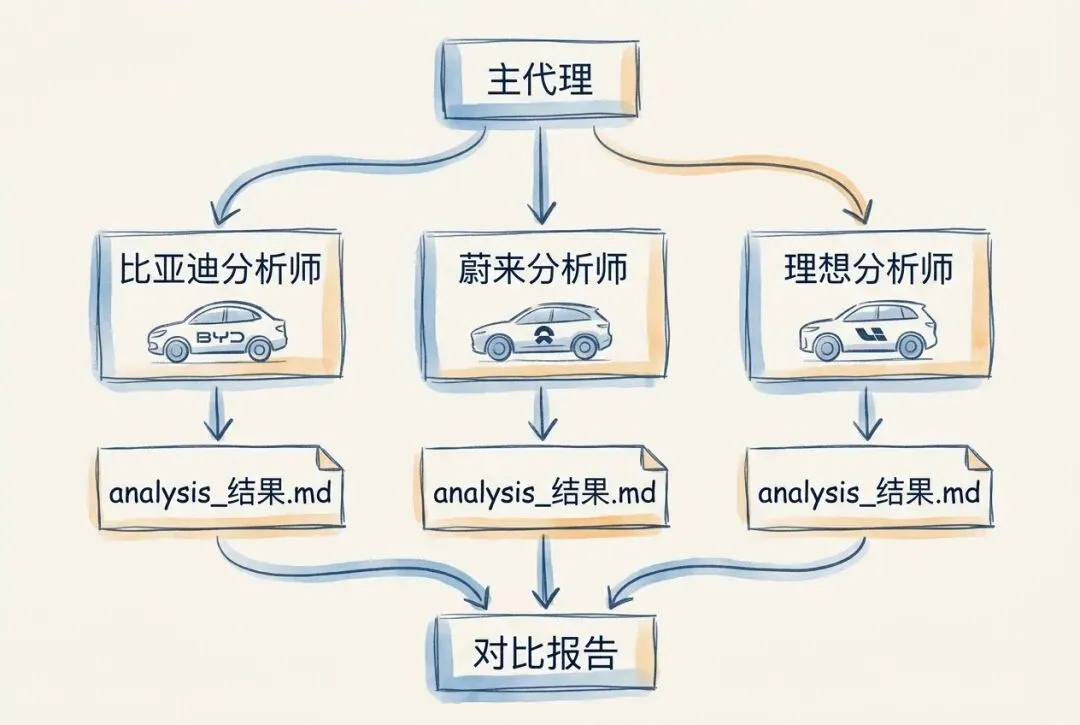
场景:你正在做一份新能源汽车行业横向对比分析,需要同时处理比亚迪(002594)、蔚来(NIO)、理想汽车(LI)三家公司的最新财务数据。逐家手动分析太慢,改用子代理并行处理会快得多。
项目目录
ev-comparison-202603/├── data/│ ├── 002594_比亚迪_2025Q4.csv│ ├── NIO_蔚来_2025Q4.csv│ └── LI_理想_2025Q4.csv├── output/ # 各子代理的分析结果│ ├── 002594_analysis.md│ ├── NIO_analysis.md│ ├── LI_analysis.md│ └── comparison_summary.md # 主代理汇总的横向对比└── CLAUDE.mddata/ 存放三家公司的原始财务数据,每个文件对应一家。output/ 是所有产出的统一出口,子代理各自写入单家分析,主代理最后写入汇总对比。
配置文件
CLAUDE.md 的重点是约束子代理的分工方式和输出规范。
## 项目新能源汽车行业 2025Q4 横向财务对比分析。## 目录约定- data/:三家车企的原始财务数据,只读不改- output/:所有分析结果写入此目录## 子代理分工- 每家公司的分析由独立子代理完成- 子代理直接将结果保存到 output/{股票代码}_analysis.md,只返回状态摘要- 主代理负责汇总对比,不自己做单家分析## 分析维度(四项统一)- 营收增速(同比)- 毛利率- 研发费用占比- 经营性现金流净额## 输出格式每份单家分析包含:- 四项指标的数据表格(数值保留两位小数)- 每项指标的简要解读(1-2 句)- 异常指标标注(同比变化超过 30%)这份规则文件做了两件关键的事:一是把分析维度固定为四项,确保三个子代理的产出口径一致;二是明确子代理只保存文件、只返回摘要。统一口径和摘要回传,是并行分析能稳定落地的前提。
用户操作
项目目录和规则文件就绪后,在 Claude Code 中用一条指令启动并行分析。
请创建 3 个财务分析子代理,并行处理 `data/` 目录下的三家车企数据。主代理职责:- 只负责创建子代理、等待完成和汇总结果- 不自己做单家公司分析子代理 A:只负责比亚迪,对应 `data/002594_比亚迪_2025Q4.csv`子代理 B:只负责蔚来,对应 `data/NIO_蔚来_2025Q4.csv`子代理 C:只负责理想汽车,对应 `data/LI_理想_2025Q4.csv`每个子代理都必须:- 只读取自己负责公司的 CSV 数据文件- 分析四个维度:营收增速、毛利率、研发费用占比、经营性现金流- 将分析结果保存到 `output/{股票代码}_analysis.md`- 只返回完成状态,不返回完整内容3 个子代理全部完成后,主代理再汇总三家公司的指标,生成横向对比表格,写入 `output/comparison_summary.md`。这条指令把主代理职责、子代理数量和文件边界都写明了。三个子代理会在独立上下文中读取各自的数据文件、完成四项指标分析并保存结果;全部完成后,主代理再读取三份报告并整合为横向对比表格。
三家公司的分析互不依赖时,并行就是最直接的提速方式。 主代理只做调度和汇总,子代理各自处理单家公司,整体流程就更稳。并行执行只需等待最慢的那个完成,每个子代理也都能在独立上下文中专注工作,主代理的上下文负担也更轻。
统一分析口径
对比分析的维度必须在 CLAUDE.md 中提前约定。如果三个子代理各自决定分析哪些指标,产出的表格列名和计算口径可能不一致,主代理整合时就需要额外的格式对齐工作。本案例把分析维度固定为四项,正是为了避免这个问题。
8.8 案例二:三大经济体 PMI 数据采集与对比
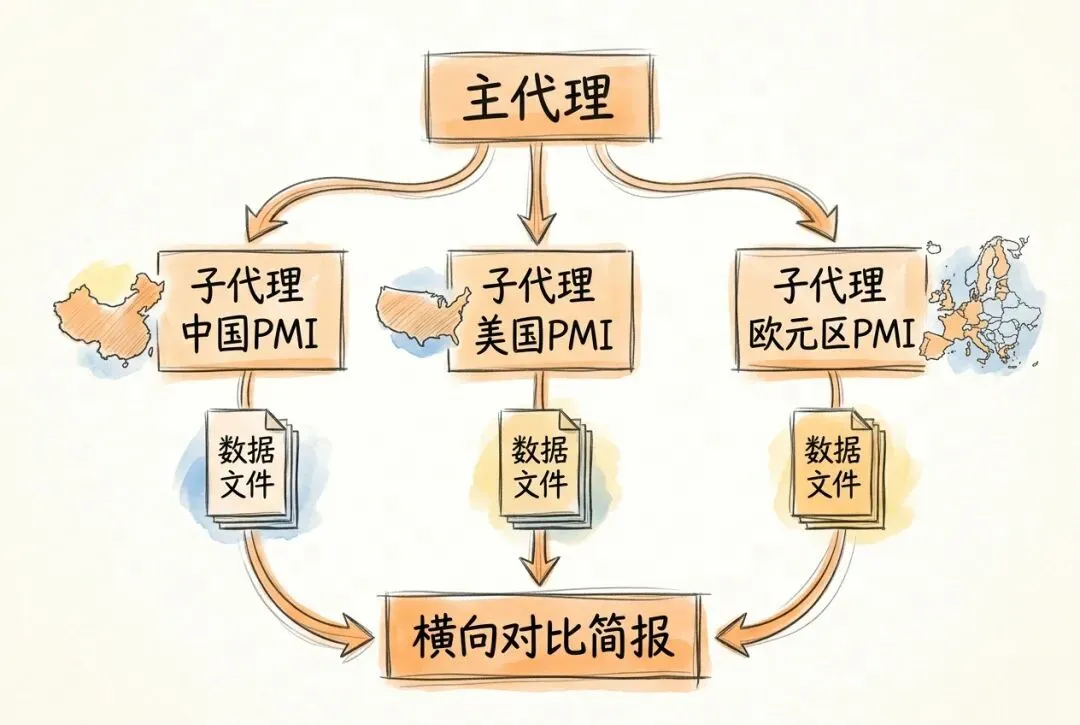
场景:你在准备一份全球宏观经济月度简报,需要同时采集中国、美国、欧元区三大经济体的制造业 PMI(Purchasing Managers’ Index,采购经理指数)数据,并生成横向对比。三个经济体的数据来源和格式各不相同,很适合用子代理分头处理。
项目目录
pmi-monitor-202603/├── sources/│ ├── china_caixin_pmi.csv # 财新中国制造业 PMI│ ├── us_ism_pmi.csv # ISM 美国制造业 PMI│ └── eu_markit_pmi.csv # S&P Global 欧元区制造业 PMI├── output/│ ├── china_pmi_brief.md│ ├── us_pmi_brief.md│ ├── eu_pmi_brief.md│ └── global_pmi_comparison.md # 主代理汇总├── .claude/│ └── agents/│ └── pmi-analyst.md # 子代理配置└── CLAUDE.mdsources/ 存放三个经济体的 PMI 原始数据。每个子代理读取一份文件,产出写入 output/。
配置文件
.claude/agents/pmi-analyst.md 定义了通用的 PMI 分析子代理。主代理调度时,只需通过任务描述指定具体经济体。
---name: pmi-analystdescription: 分析单个经济体的制造业 PMI 数据,输出月度简报model: sonnettools: - Read - Write---你是一个宏观经济数据分析助手。## 任务读取指定经济体的 PMI 数据文件,完成以下分析:- 最新月份 PMI 数值及荣枯线判断(50 为分界)- 近 6 个月趋势(上行/下行/震荡)- 关键分项指标:新订单、产出、就业- 与上月对比的边际变化## 输出要求- 保存到 output/{经济体}_pmi_brief.md- 数值保留一位小数- 只返回完成状态和 PMI 读数,不返回完整报告用户操作
请创建 3 个 `pmi-analyst` 子代理,并行分析 `sources/` 目录下的 PMI 数据。主代理职责:- 只负责创建子代理、等待完成和整合结果- 不自己展开单个经济体的 PMI 分析子代理 A:只负责中国,读取 `sources/china_caixin_pmi.csv`子代理 B:只负责美国,读取 `sources/us_ism_pmi.csv`子代理 C:只负责欧元区,读取 `sources/eu_markit_pmi.csv`每个子代理都必须:- 只读取自己负责经济体的 CSV 数据- 分析 PMI 走势、分项指标和边际变化- 保存结果到 output/ 目录- 只返回 PMI 读数和趋势判断3 个子代理完成后,主代理再汇总三大经济体的 PMI 数据,生成横向对比表格和全球制造业景气度判断,写入 `output/global_pmi_comparison.md`。这个案例与车企分析的结构相同:三个子代理各自独立工作,主代理负责调度和汇总。区别在于,这里通过 .claude/agents/ 目录预定义了子代理配置,但真正执行时,仍然要在提示词里把本轮要创建几个子代理、各自负责哪个经济体写清楚。角色一旦固定下来,预定义子代理就能把重复调度成本降下来。 当分析对象从三个扩展到五个或十个时,只需增加数据文件,调度逻辑基本不用改动。
子代理配置的复用
pmi-analyst.md的设计思路是通用化:配置文件定义分析能力和输出规范,具体分析哪个经济体则由调用时的任务提示词指定。这种”配置定义能力,提示词指定参数”的模式,让同一个子代理配置可以被不同场景反复调用,无需为每个经济体单独写一份agent.md。
要点小结
从单智能体到多智能体:单智能体受限于上下文窗口、任务切换和串行执行。子代理通过独立上下文和并行执行缓解这些问题,但 token 消耗约为普通任务的 15 倍,适合高价值场景。
子代理的创建与配置:三种创建方式——/agents 交互式创建、手动编写 agent.md、--agents CLI 临时定义。存储位置决定可见范围和优先级,模型选择应与任务难度匹配。
任务分派与输入输出设计:好的任务提示词包含目标、上下文、输出格式和约束条件。File Handoff 是核心原则——子代理将结果保存到文件,只返回状态摘要,保护主代理上下文。
子代理的进阶配置:skills 字段预加载特定 Skill,memory 字段支持三种作用域的持久记忆,background 字段支持后台运行不阻塞主对话。
掌握这项能力之后,Skill 就可以进一步升级,不再只是一组静态指令,而是一个能在内部编排多个子代理的调度中心,完成多阶段、多维度的工作流。