 夜雨聆风
夜雨聆风





别再乱烧Token!一文搞懂 AI 计费规则 怎么算、怎么扣、怎么省?

为什么企业 API 调用量明明可控,月度Token账单却频繁超标?
为什么简单业务场景,Token消耗远超预估?
为什么多模态接入后,成本曲线陡增?
这些几乎是所有使用大模型的企业都会遇到的真实困扰。对大模型厂商而言,精准计费是商业化基础;对开发者与企业客户,透明可控的Token消耗直接决定产品毛利、服务稳定性与规模化可行性。本文用大白话+接地气比喻,把Token计量、计费逻辑、隐性消耗、降本方案一次性讲透,让你告别无效消耗、不再莫名扣费。

Token
就是AI的“计量单位”
“Token”就是AI处理信息的“最小单位”,相当于咱们人类说话、写字时的“字或词”,也可以把Token想象成AI世界的“货币”——你要让AI干活,就得用Token“付费”,干的活越复杂,消耗的Token就越多。
具体计算规则不用记复杂,重点记这3点:

举个简单例子:某SaaS公司用大模型做合同审核,单次输入合同文本约2000汉字(≈1300 Token),输出审核结果约800汉字(≈550Token),单轮合计≈1850Token。
按企业API价0.01元/ 1K Token计算,单次成本≈0.0185 元;日调用10万次,月成本≈5.5万元。
扣费真相
不止“字数×单价”那么简单
很多人用AI有个误区:觉得计费就是“输入字数×单价+输出字数×单价”,其实这只是表面,真实计费逻辑更精细。
核心计费公式:

3个关键要点,帮你避开扣费坑:
· 输入输出单价不同:输入只是让AI读懂你,便宜;输出要AI思考、生成,算力消耗大,价格通常是输入的2~5倍
· 附加功能单独计费:图片识别、音频转写、视频分析、联网搜索、代码运行、插件调用等功能,都会额外计算Token
· 上下文历史会重复计费:AI 没有真正的长期记忆,每次提问都会把历史对话重新发送一遍——对话轮次越多,单次费用越高
Token 都去哪儿了?
四大高消耗场景盘点
理解计费逻辑后,再看具体哪些动作消耗Token,尤其是隐性消耗,帮你精准“止损”:
· 指令越长消耗越高:字数多,Token 自然多
· 一个窗口聊所有话题:历史对话全是 “包袱”,无关内容也会被重复计费,换话题一定要开新对话
·“ 深度思考”消耗高:多轮推理、自我校验,Token 消耗是普通模式的 5–20 倍
· 设定角色和借助工具:设定“律师、老师、工程师” 等角色,预设文本会长期占用输入 Token;联网搜索会经历“思考→搜索→读取→总结”四步,Token 消耗极易破万

图片/音频/视频
计费方式完全不同
很多人因不懂多媒体Token消耗规则,白白花冤枉钱,图片、音频、视频的扣费方式差异很大,重点看这3点:
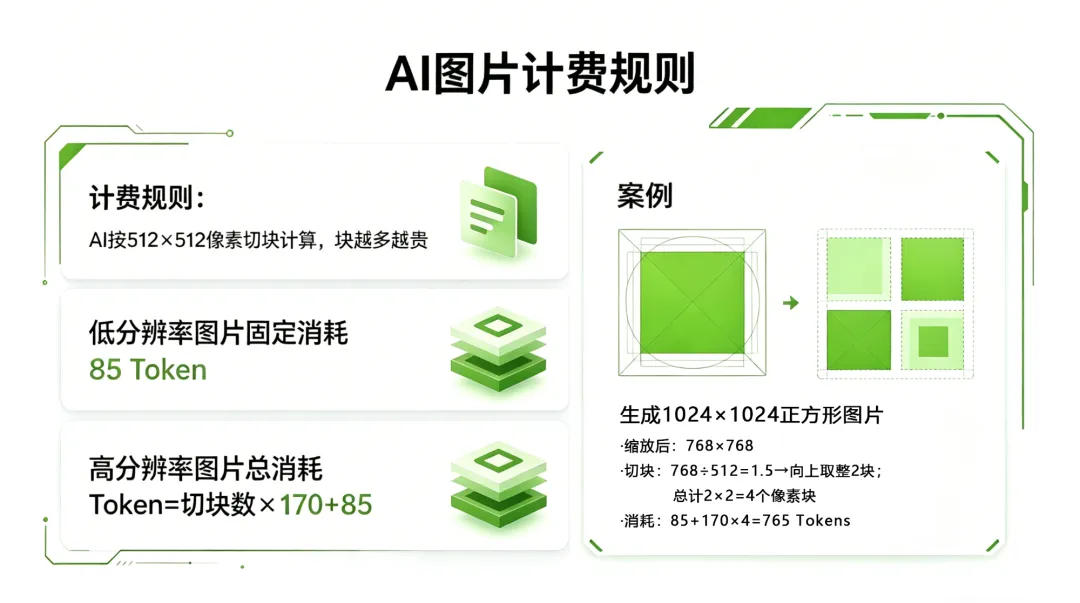
1. 图片:按“像素块”收费
AI 将图片切分为512×512像素块,块越多越贵:
·低分辨率:固定85Tokens
·高分辨率:总Token=切块数×170+85
示例:
1024×1024 → 缩放后768×768,切块4个 → 消耗约765Tokens
1920×1080 →缩放后约1356×768,切块6个 → 消耗约1105Tokens
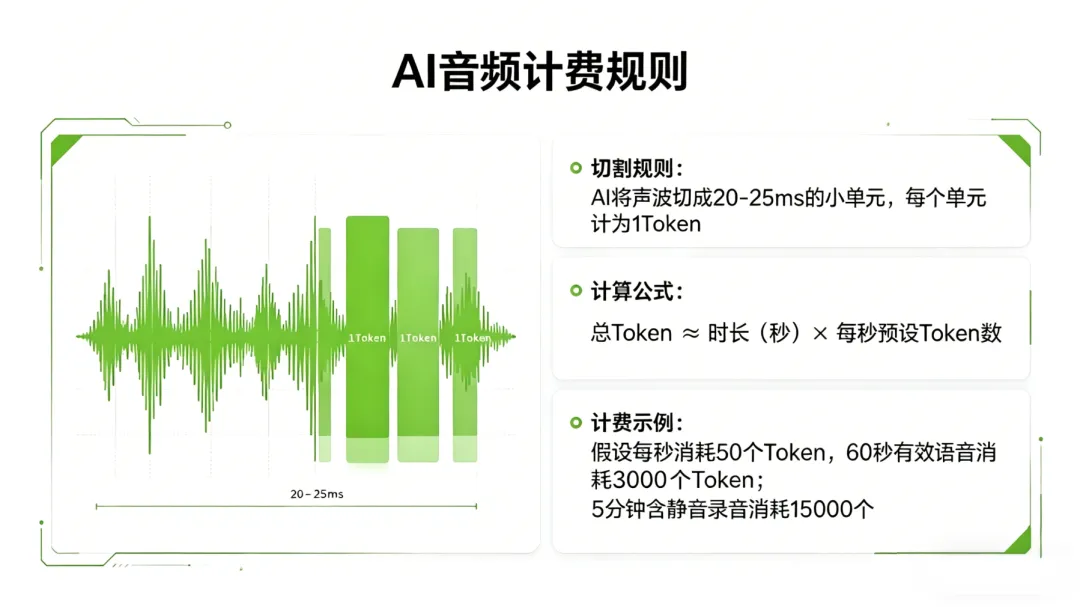
2. 音频:按秒计费 静音也算钱
AI将声波被切成20~25ms的小单元,每个单元计为1Token:
总 Token ≈时长(秒)× 每秒预设 Token 数
示例:
60秒语音 → 消耗3000Tokens
5分钟含静音录音 → 消耗15000Tokens
3.视频:最昂贵的“烧钱大户”
图片 + 音频成本叠加,默认每秒抽1帧分析:
总Token = (时长×帧率×每帧成本)+(时长×音频每秒成本)
示例:
60秒1080p视频(1fps) → 消耗约18600Tokens

省钱攻略
几招搞定AI成本控制
结合前文知识点,总结实用降本技巧,普通用户和深度用户都能用上:
· 指令精简:去掉客套话,直奔主题,减少 AI 自由发挥
· 对话隔离:不同话题开新对话,切换话题清零历史,甩掉“历史包袱”
· 模式选择:常规问题用快速模式,复杂问题再开深度思考,不浪费Token
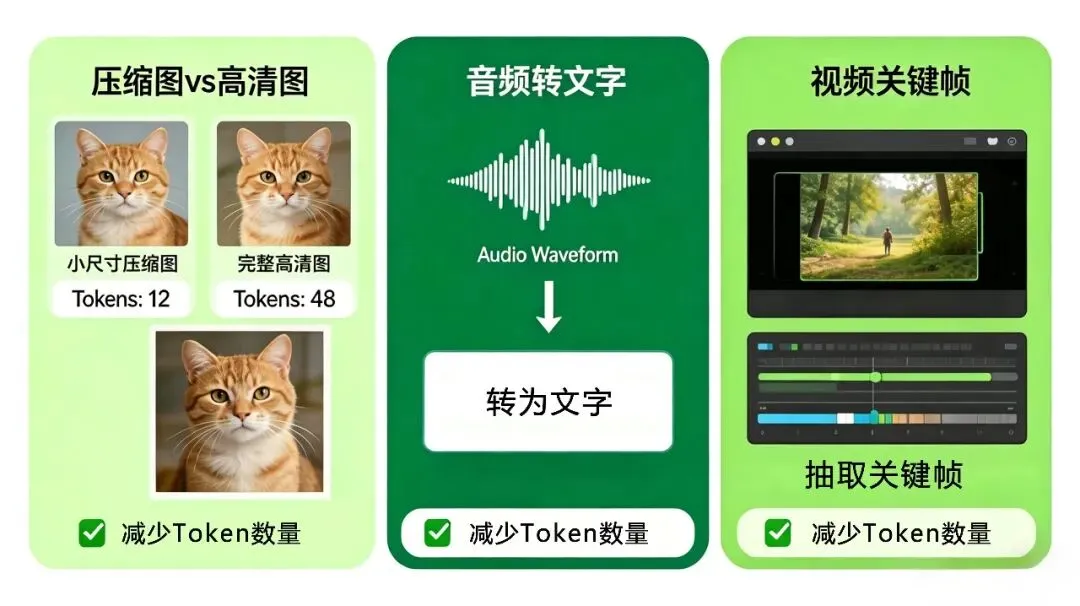
· 多媒体预处理:图片压缩、截取局部;音频转文字;视频截关键帧或分离音频
· 批量处理+模型选择:相似问题集中提问,减少系统预设消耗;按场景选专业模型,不盲目用大模型“一刀切”
行业实战
医疗金融行业Token应用与成本控制
1.医疗行业
医疗行业Token 的高消耗主要来自长文本病历、多轮问诊上下文累积、多模态影像解析,以及长病程档案带来的持续隐性消耗。
Token 省钱方案
·电子病历辅助书写:用结构化模板替代自由长文本,仅输入关键体征、诊断、用药
·医学文献解读:先提取摘要与核心数据再提问,禁用非必要深度思考
·检查报告智能核对:结构化输入异常指标,输出仅保留提示与建议,适配门诊高频调用
·患者咨询自动回复:标准话术存入向量库,模型仅做匹配润色,不重新生成
2.金融行业
金融行业Token 的高消耗主要来自长文档研报解析、深度推理研究、智能体多步执行,以及批量文档预处理带来的大额开销。
Token 省钱方案
·财报 / 公告分析:抽取核心财务数据与风险提示后再分析,限定输出要点
·信贷合同与风控审查:规则存入向量库,仅检索匹配条款,小模型初筛 + 大模型复核
·客户画像与营销话术:仅输入客户标签与风险等级,模板化输出话术
·合规敏感信息过滤:轻量模型前置初筛,大模型仅复核可疑内容,高频校验更可控

智绘绿洲聚焦Token需求
打造全覆盖的算力矩阵
Token 是 AI 处理信息的基本单位,也是我们使用 AI 服务的核心计量依据。从基础换算、计费规则,到隐形消耗、多媒体计费,再到实用省钱技巧,只要掌握方法,就能有效避开不必要的 Token 消耗,告别盲目扣费。愿大家都能看懂规则、用对方法,让每一次 AI 交互都更划算、更高效。
如今Token成为数字经济硬通货,每瓦Token吞吐量已然成为科技企业的核心竞争力。智绘绿洲聚焦Token核心需求,打造全覆盖的算力矩阵,包含X7系列、M系列、iPRO系列、明星产品系列,兼顾高密度算力、极致散热、高能效与全场景适配,从单机部署到集群搭建,全方位满足不同规模企业的智算需求,为高Token吞吐场景保驾护航。

想了解详细参数或定制算力方案?欢迎联系智绘绿洲团队,让专业算力助你的业务加速升级。
关注智绘绿洲

