 夜雨聆风
夜雨聆风





液冷:AI基础设施规模化的热管理前提

目 录
-
一句话摘要
-
热墙 -
冷却技术比较 -
CDU架构转变 -
微通道盖板转折点 -
采用时间表:与 GPU 路线图挂钩 -
设施经济学:规模化 TCO -
TAM 瀑布图:协调范围差异 -
与 800 VDC 的融合:协同设计的数据中心 -
公司评分卡:全栈评估 -
整合浪潮 -
催化剂追踪 -
风险与可能改变我们看法的因素 -
数字变动需要发生什么 -
对投资者的启示
液冷:AI基础设施规模化的热管理前提
一句话摘要
液冷已成为AI基础设施规模化的关键制约因素,其重要性远超市场普遍认知的组件升级范畴。GPU功耗的快速攀升是核心驱动力:GB200机架功耗已达120千瓦,远超风冷经济性阈值,而后续Vera Rubin及Rubin Ultra平台将推动机架功耗进一步升至500-700千瓦甚至兆瓦级,使液冷成为唯一可行的主散热架构。
这一转变正重塑整个供应链格局:机架级液冷内容物价值已超过电力内容物2-3倍,CDU架构从侧挂式转向列间式,微通道盖板(MCL)技术作为新竞争领域出现,行业整合浪潮已超150亿美元。液冷与800 VDC电力转型相互依赖,未来AI数据中心将围绕两者作为单一集成基础设施协同设计。
一、核心论点
我们认为,液冷已成为新一代AI计算部署的又一系列关键制约因素。GPU功耗路线图是这一转变的最大驱动力。二十年来,服务器机架功耗在5至20千瓦之间,空调即可轻松处理散热。单个GB200 NVL72机架功耗约为120千瓦,是历史基准的6到20倍,远超约40至50千瓦的门槛——超过此阈值,若无混合或液冷辅助,风冷的经济性将急剧下降。当前GPU世代已运行在液冷是唯一可行主散热架构的区间。Vera Rubin更进一步,采用了全液冷、无风扇的托盘设计。我们的供应链核查表明,后续平台将使机架功耗显著更高。GPU散热需求与风冷能力之间的差距正逐代扩大。
市场多数仍将液冷视为组件升级,我们认为这种看法低估了实际制约。液冷是决定下一代计算部署规模的热管理制约因素。如果冷却基础设施未就绪,GPU就无法安装。这一单一依赖关系改变了TAM(总可寻址市场)的规模估算方式、供应链的估值方式,以及哪些公司能拥有影响盈利持久性的关键地位。
我们的发现
机架级液冷的经济性已发生转变,而大多数模型尚未吸收这一变化。我们估计,GB200级机架的液冷内容物价值现已超过电力内容物价值约2到3倍,扭转了历史上电力基础设施是数据中心建设主要成本项的关系。订阅者部分详细分解了这一估算的构成要素,从托盘级冷板内容物到共享CDU(冷量分配单元)和管道基础设施,并将我们的全栈TAM框架与Dell’Oro等公司的行业设备预测进行了协调。TAM的故事比大多数投资者预期的要大,但前提是必须正确定义范围。
除了规模增长,三个结构性转变正在同时重塑竞争格局。CDU架构正从侧置式转向列中式,改变了数据中心的管道拓扑结构以及受益的供应商。一个新的技术层——微通道盖板——正在芯片封装层面出现,并创造了一个12个月前不存在的竞争领域。一场已披露和估计交易价值超过150亿美元的整合浪潮席卷了整个行业,传统HVAC(暖通空调)和电气基础设施公司正在收购它们无法在市场所需时间内通过内部研发建立的液冷能力。我们在订阅者部分详细阐述了这些转变、处于其核心的公司,以及会改变我们看法的具体里程碑。
电力-冷却融合
液冷转型与我们第一部分分析的800 VDC转型是相互依赖的。更高效的电力输送减少了冷却系统必须处理的废热。更密集的液冷机架证明了高压直流配电资本投资的合理性。未来的AI数据中心正围绕这两个系统作为单一集成基础设施进行协同设计,能够同时提供电力和冷却解决方案的公司相比单一产品供应商拥有结构性优势。订阅者部分量化了这种融合,并识别出横跨这两个层面的公司。
订阅者将在完整报告中获得:
-
冷却技术比较。从可行机架密度、PUE(电能使用效率)和GPU路线图对齐等六个维度对风冷、后门热交换器、直接-to-芯片液冷和浸没式液冷进行评级。
-
GPU路线图采用时间表。从GB200到Vera Rubin再到Rubin Ultra的三阶段框架,包含密度阈值、CDU架构转变和MCL(微通道盖板)采用里程碑。
-
设施级TCO(总拥有成本)分析。每兆瓦资本支出、运营成本节约、投资回收期,以及完整的机架级内容物桥梁,分解托盘内容物、共享CDU/管道分配以及每机架电力与冷却支出。
-
分层TAM瀑布图。2024年至2030年机架级与全栈规模对比,附有明确的范围说明,以协调我们的估算与Dell’Oro及其他行业预测。
-
全栈公司记分卡。涵盖三个层级(组件专家、系统供应商、基础设施集成商)的九家公司,包含份额估算、利润率概况、关键风险以及会导致每家公司估算修正的具体条件。
-
并购追踪器。八笔交易,已披露和估计价值总计超过150亿美元,包含交易结构、战略逻辑以及剩余的私人收购目标。
-
催化剂追踪器。我们正在监测的八个具体里程碑,从Vera Rubin量产爬坡和MCL认证时间,到CDU交货周期正常化和首批大型棕地改造项目。
-
风险框架。会改变我们看法的四种情景,从冷板商品化和CDU供应瓶颈,到浸没式液冷颠覆和运营可靠性故障,每种情景都附有具体触发条件。
-
800 VDC融合分析。液冷转型如何与我们第一部分涵盖的电力架构转变相互依赖,以及哪些公司拥有横跨这两个层面的地位。
热墙
迫使我们在第一部分中涵盖的电气架构重新设计的相同密度升级,正同时迫使散热架构重新设计。二十年来,服务器机架功耗在5至20千瓦之间,精密空调即可轻松处理热负荷。风扇冷却之所以有效,是因为单位占地面积的热通量足够低,通过散热器移动空气并利用架空地板送风即可将硅片温度维持在规格范围内。其经济性简单,故障模式清晰,没有理由将液体引入计算环境。
GPU计算改变散热数学的方式与其改变电气数学的方式同样具有决定性。单个120千瓦的GB200 NVL72机架产生的热量,风冷无法足够快地移除,以将芯片结温保持在降频阈值以下。物理定律不可改变:按体积计算,水传递热量的效率约为空气的3000倍。在每机架120千瓦的情况下,约70%至80%的热负荷现在需要通过循环流经直接安装在处理器上的冷板的液体来移除,仅剩余部分由空气处理。在Rubin Ultra和Feynman所暗示的机架密度下,这一液体比例接近100%。
边界并非一条单一界线,而是一个梯度。在每机架约40千瓦以下,通过适当的设施设计,传统风冷仍然有效,尽管效率越来越低。在40至80千瓦之间,先进风冷和混合方法(包括后门热交换器和补充性液冷辅助)可以管理负荷;该领域的专家访谈指出,根据设施设计,此范围支持混合了先进风冷、混合和液冷散热方案。在每机架约80千瓦以上,若无液冷辅助,风冷变得越来越不经济且不足,直接-to-芯片液冷成为主导架构。在200千瓦以上,系统设计转向完全液冷、无风扇的托盘。Vera Rubin计算托盘被设计为无风扇、全液冷单元,这是所涉及功率密度下的物理要求。
未来三代GPU的密度轨迹使这一方向成为新的基准。GB200机架功耗约为120千瓦。Vera Rubin配置通过更高的每GPU TDP(热设计功耗)和每托盘GPU数量的增加,进一步推高了功耗。我们的供应链消息来源预计,目标于2027年量产的Rubin Ultra,将把机架功耗推至500至700千瓦范围,需要800 VDC电力输送和全液冷热管理。NVIDIA的公开路线图指向后续世代的兆瓦级机架架构。该路线图上的每一步都增加了单位占地面积的热负荷,并缩小了可行冷却架构的范围。到Rubin Ultra达到批量部署时,将不存在任何可行的风冷配置。
冷却技术比较
下表比较了四种主要冷却架构,依据决定它们在不同功率密度下可行性的维度。结论列反映的是我们对每种架构在路线图中位置的评估,而非绝对排名。
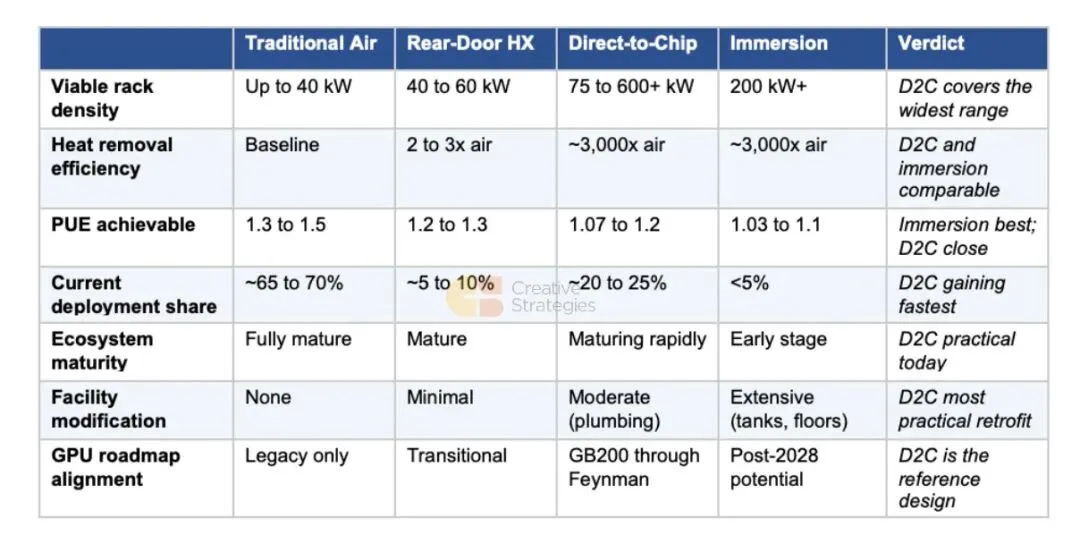
直接-to-芯片液冷主导了当前的部署浪潮,因为它处于热能力、生态系统就绪度和GPU供应商对齐度的交汇点。NVIDIA的GB200参考设计在GPU上使用冷板,通过CDU进行液体循环,目前所有主要超大规模云服务商都在基于该架构进行建设。我们的供应链核查表明,大多数新建液冷数据中心部署正采用液-液二次回路,这意味着CDU在设施水回路和机架级冷却液回路之间交换热量,而无需在机架处涉及空气。液-气配置(CDU将热量排放到空气中)对于某些改造场景仍然可行,但在更高密度下容量受限且效率较低。
浸没式液冷(将服务器浸入介电液体中)实现了最佳理论PUE,但面临显著的采用障碍。设施改造范围广泛:用于盛放液体的加固地板、专门的硬件兼容性要求、大多数运营商人员配备不足以处理的维护复杂性,以及仍然高昂的液体成本。我们不预期浸没式液冷在2030年前会取代直接-to-芯片成为主要架构,尽管它可能在冷板无法处理的最高密度边缘场景中找到针对性用途。更可能的情况是,MCL技术将直接-to-芯片液冷的可行范围扩展到足够远,以至于浸没式液冷在本十年末仍将是一个利基解决方案。
CDU架构转变
冷却液分配单元是连接设施级水基础设施与机架级冷却的核心组件。它调节从设施冷却站出发的主回路与流经处理器冷板的次级回路之间的流量、温度和压力。CDU 是系统级控制发生的地方,其设计正在快速演进。
目前,已安装的 CDU 以侧挂式为主:即独立单元,位于一排机架旁边,通常一个单元服务 8 到 12 个机架。侧挂式配置在当前功率密度下表现良好,曾是 GB200 部署的参考设计。但随着机架功率攀升,且每个设施内高密度机架数量增加,侧挂式模式会带来管路距离和压降方面的挑战,从而降低冷却性能。
我们从供应链工作中了解到,架构正转向列间式 CDU,即冷却单元直接位于其服务的服务器机架之间,通常每四到八个机架配一个 CDU。亚马逊正在推行集成液冷 CDU 系统的列间式热交换器。谷歌正在内部开发自己的液冷到 CDU 平台,该项目被称为 Deschutes。列间式方法缩短了管路距离,减少了压降,并允许对每个机架组进行更精细的热控制。这是一张来自 HPE 的冷却侧挂式单元图片,支持 1.6 MW 的列间冷却。请注意,Vertiv 公布的参考设计平台面向 4 MW 的列间冷却,并正成为 NVIDIA 机柜的标准配置。

对于供应商而言,架构转变改变了单位经济性。侧挂式 CDU 体积更大、容量更高,每个设施的部署点更少。列间式 CDU 体积更小、数量更多,并且与机架基础设施集成更紧密。每个设施的总冷却容量可能相似,但部署的 CDU 单元数量增加,服务复杂性发生变化,竞争态势有利于那些能够提供紧密集成的机架加冷却解决方案的公司,而非销售独立冷却箱的公司。目前,台达在气冷式侧挂 CDU 中估计占据约 70% 的市场份额 [CS 供应链估计]。随着架构向列间式转变,这一份额能否保持,取决于台达调整其产品线的速度,以及超大规模云服务商是标准化专有设计还是开放设计。
微通道盖板转折点
液冷供应链中最重要的技术发展是微通道盖板的出现。要理解其原因,需考虑在传统的直接到芯片设置中,热量如何从硅芯片传递到冷却系统。芯片产生热量。热量通过第一层导热界面材料 (TIM 1) 进入金属盖板,即集成散热器。从盖板,热量通过第二层导热界面材料 (TIM 2) 进入冷板,由循环液体带走。每一层都增加了热阻。TIM 2,即盖板和冷板之间的连接处,是主要的瓶颈。它限制了冷板提取热量的效率,并产生温度梯度,迫使运营商将进水温度运行得比系统原本要求的更低。
微通道盖板完全消除了 TIM 2。MCL 不是将冷板螺栓固定在平坦的金属盖板上,而是将微小的水道直接集成到盖板本身中。冷却液流经盖板,以最小的热阻在封装级别带走热量。改进是可衡量的:使用传统冷板和 TIM 2 堆叠时,热阻约为每瓦 0.15 摄氏度,而使用 MCL 则降至约每瓦 0.10 摄氏度。在 GPU TDP 目前接近 1000 瓦、两代内将达到 3600 瓦的情况下,热阻降低 33% 显著改变了运行范围。
我们的供应链核查表明,MCL 的采用将在 2026 年底开始小批量,可能用于超频的 Vera Rubin 配置,并随着下一代平台将 TDP 推至 3000 至 4000 瓦范围而走向主流应用。我们估计 MCL 的 TAM 在 2026 年约为 3 亿至 4 亿美元,2027 年为 10 亿至 15 亿美元,到 2030 年将达到 20 亿至 30 亿美元。从竞争角度来看,有趣的是 MCL 制造需要传统冷板制造所不具备的精度。将微通道结构以数百万单位可靠热接触所需的公差焊接到芯片封装上,是与冲压和钎焊铜冷板不同的制造挑战。目前有资格批量生产 MCL 的公司,并非主导冷板供应的那些公司。
根据我们的供应链核查,Jentech Precision 是先进 AI GPU 散热器的主要独家供应商,也是目前唯一一家与领先半导体代工厂测试 MCL 设计的供应商 [CS 供应链核查]。他们在精密金属加工、粘合和表面处理方面的专业知识,使其处于这一转折点的中心。AVC,作为占主导地位的冷板供应商,正在适应一个市场,在这个市场中,价值最高的热组件可能在未来两到三年内从冷板转移到 MCL。竞争问题在于,MCL 制造是会整合到少数精密专家手中,还是会随着技术成熟而扩大范围。
采用时间表:与 GPU 路线图挂钩
与 800 VDC 过渡一样,液冷采用时间表由 NVIDIA 的 GPU 路线图决定,而非数据中心运营商的自愿升级计划。其节奏机制是 GPU TDP。每一代新的 GPU 都会提高每个机架的热负荷,并缩小可行冷却架构的范围,直到在特定功率阈值下,液冷成为唯一选择。下面的时间表将三个阶段映射到 GPU 平台过渡。
第一阶段:2024 年至 2026 年。以 GB200 和早期 Vera Rubin 部署为特征。采用侧挂式 CDU 的直接到芯片液冷是参考架构。AI 数据中心中的液冷渗透率已从 2024 年的大约 10% 到 15%,上升到 2025 年估计的 30% 到 35%,液冷机架数量的增长速度超过总机架部署。这一阶段集中在超大规模云服务商:AWS、谷歌、微软和 Meta 都在大规模部署液冷 AI 集群。GB200 和 GB300 的出货量,根据我们的供应链核查,在 2026 年将在 60,000 到 90,000 台之间 [CS 估计],是数量驱动因素。具体的强制因素是:120 千瓦的 GB200 机架在这些密度下无法有效风冷,因此每个 GB200 部署默认都是液冷部署。
第二阶段:2027 年至 2028 年。Vera Rubin 和 Rubin Ultra 推动了热要求的阶跃变化。Vera Rubin 托盘设计为全液冷、无风扇单元,每个机架运行功率为 250 千瓦。Rubin Ultra,我们的核查表明其可能将机架功率推至 500 到 700 千瓦范围,将需要 800 VDC 电力输送和先进的液冷,并可能采用 MCL。CDU 架构从侧挂式转向列间式。MCL 市场开始规模化。随着组件生态系统成熟且 OCP 规范标准化机架级管路接口,二级云提供商和托管运营商开始采用液冷。ASIC 客户,特别是 AWS 和谷歌及其定制芯片项目,成为液冷需求的主要来源。我们的供应链核查表明,领先超大规模云服务商的主要 ASIC 训练器部署将从 2026 年中期开始,并持续到下半年,两者都需要与 GPU 平台相当或更复杂的液冷。
第三阶段:2029 年及以后。超越 Rubin Ultra 的下一代平台将推动兆瓦级机架配置。液冷成为所有新建 AI 数据中心的默认规格。随着运营商改造现有设施以支持液冷(作为风冷的补充或替代),改造市场开始发展。MCL 成为高 TDP 处理器的标准热接口。每台 CDU 的容量大幅增加,已安装的液冷基础设施基础创造了一个服务和更换市场,为这个主要是资本支出驱动的业务增加了经常性收入层。我们的估计,综合多个行业数据源,液冷到 2030 年将在全球达到 65% 到 80% 的渗透率,高于目前的大约 20% 到 30%。
设施经济学:规模化 TCO
液冷的资本成本高于风冷。这是我们最常听到的反对意见,它准确但不完整。一个传统的超大规模风冷设施建造成本约为每兆瓦 700 万至 1200 万美元。一个采用液冷的 AI 优化设施接近每兆瓦 2000 万美元。当计入完整的灰色空间基础设施(包括电力系统、冷却系统、土地、外壳、网络和管理软件)时,专门的高密度 GPU 集群每兆瓦成本可达 3000 万至 4000 万美元。在一个典型的 300 兆瓦 AI 数据中心,仅冷却系统就占 30 亿美元总基础设施投资中的约 7.5 亿美元,即灰色空间资本支出的 25%。
尽管前期成本较高,但 TCO 情况有利于液冷,并且投资回收期足够短,不会阻碍超大规模云服务商的采用。来自同时运行两种架构的设施的运营成本数据显示,液冷在中密度下可将能耗降低 10% 到 30%,在更高机架功率下降低更多。PUE 从传统风冷的 1.3 到 1.4 改善到液对液冷却的 1.07 到 1.2,直接转化为每单位计算交付的电力支出降低。与传统蒸发冷却相比,用水量下降 31% 到 48%,因为闭环液体系统不需要持续供水来排热。
在总拥有成本基础上,一旦计入运营成本,数字就有利于液冷。我们对多个运营商数据集的设施级经济学分析表明,在完全计入能源、维护和水成本后,冷板液冷相对于传统风冷具有 12% 到 18% 的 TCO 优势。仅能源节省就可在大约 2 到 3 年内实现增量冷却资本支出的盈亏平衡,并且随着机架密度增加,该回收期会缩短,因为能源节省与热负荷成比例增长,而增量资本支出每机架基本固定。
对于一个专门用于 GB200 级 AI 负载、每个机架约 120 千瓦的 300 兆瓦设施,隐含的机架数量约为 2500 个。该数字假设几乎所有设施电力都分配给 GB200 级计算;一个包含网络、存储和低密度工作负载的混合用途设施,每兆瓦的 AI 机架数量会更低。在纯 GB200 级基础上,我们估计白色空间电力和冷却内容约为 3.5 亿至 4.5 亿美元 [CS 估计]。我们估计每个机架的电力价值为 40,000 至 50,000 美元,冷却价值为 100,000 至 142,000 美元,其中机架内冷却组件约占 45,000 至 72,000 美元(按每个机架 18 个托盘,每个托盘 2,500 至 4,000 美元计算),以及分配给机架组的共享 CDU、歧管和管道基础设施占 55,000 至 70,000 美元。在中点,每个机架的电力和冷却内容总和约为 140,000 至 192,000 美元,或对于一个 2500 机架的设施约为 3.5 亿至 4.8 亿美元。每个机架的冷却内容超过电力内容约 2 到 3 倍,这与历史关系相反。在传统数据中心,电力基础设施是主要的成本类别。在 AI 原生设施中,热管理是更大的支出项。
TAM 瀑布图:协调范围差异
液冷 TAM 估计因范围不同而差异很大。这种差异并非分析分歧的标志;它反映了您是在计算机架级组件,还是整个设施级冷却站。我们综合了多个行业数据集和我们自己的每机架内容框架,构建了一个分层 TAM 来区分这些类别。以下所有数字均为 CS 基于我们对公开数据、供应链核查和每兆瓦内容框架的综合分析得出的估计。
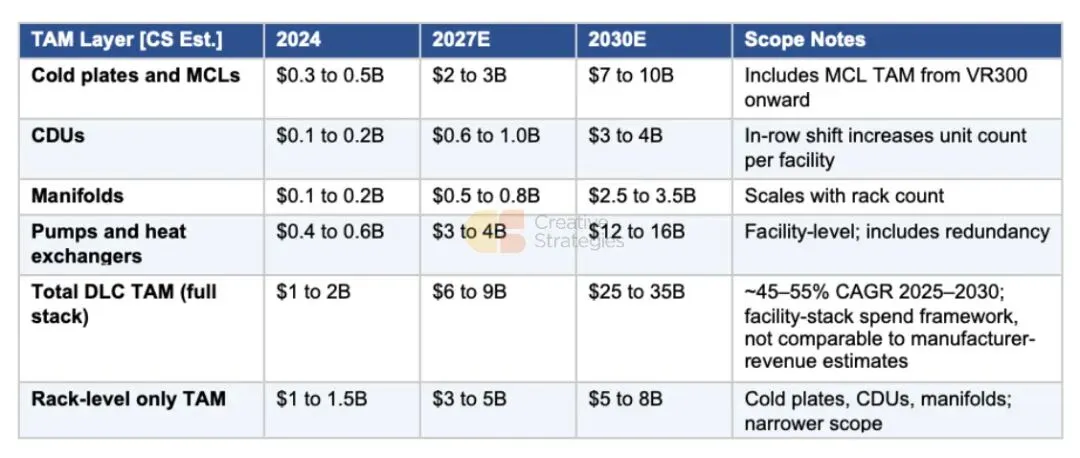
协调行业估计广泛差异的关键在于范围,我们希望明确说明为什么我们的数字与标准行业预测不同。Dell’Oro 的液冷市场预测(被广泛引用之一)将设备市场规模定为到 2029 年约 70 亿美元。该估计衡量的是更窄的制造商收入范围:冷却 OEM 出货的冷板、CDU 和歧管。我们到 2030 年 250 亿至 350 亿美元的全栈数字是一个设施级支出框架,而非制造商收入市场估计。它在 Dell’Oro 和类似公司跟踪的机架级组件基础上,增加了设施级泵、热交换器、管道基础设施和冷却站。这两个数字并不矛盾,不应直接比较;它们衡量的是同一堆栈的不同层级。对于投资分析,相关问题是特定公司参与哪个层级。冷板和 MCL 供应商,如 AVC、Auras 和 Jentech,参与 70 亿至 100 亿美元的组件层级。CDU 和集成系统供应商,如台达、Vertiv 和伊顿,同时参与组件和设施层级。全栈供应商的总可寻址机会跨越整个 2500 亿至 3500 亿美元。
与 800 VDC 的融合:协同设计的数据中心
在第一部分中,我们描述了 800 VDC 如何通过减少电力输送损耗和铜材负担来提高数据中心的计算上限。液冷通过消除热约束来提高相同的上限。这两个转变并非独立。它们是相互依赖的,未来的 AI 数据中心正围绕两者同时进行设计。
800 VDC 将电力输送链中的转换级数从五到六级减少到两到三级。每消除一个转换级就消除一个废热源。在 100 兆瓦时,通过转向 800 VDC 实现 3 个百分点的效率提升意味着减少了 3 兆瓦不需要冷却的热负荷。这 3 兆瓦的冷却能力可以重新分配给计算负载本身,或者意味着不需要建造 3 兆瓦的冷却基础设施。对液冷经济性的影响是,电力输送链效率越高,设施冷却预算中可用于 GPU 的部分就越多,而不是用于补偿电力系统损耗。
反过来,液冷实现了更密集的机架配置,这使得 800 VDC 在经济上变得必要。运营商从 48 伏转向 800 伏的原因是机架功率已攀升到较低电压下的铜材负担和转换损耗成为约束条件的程度。但只有当设施能够冷却由此产生的热负荷时,机架功率才能攀升到那么高。没有液冷,运营商将被迫将计算分散到更多地板空间以保持在风冷热范围内,这将降低机架密度并削弱高压直流配电的理由。这两种技术相互赋能。
实际结果是,目前正在设计的最高密度 AI 集群将配电、液冷、母线槽几何结构、机架布局和可维护性作为一个系统进行集成。我们在第一部分中描述的侧挂式模型,即运营商在现有设施旁边建造新的 AI 专用电力基础设施,现在越来越多地将专用冷却站作为同一建设项目的一部分。一个围绕 GB200 级机架建造的 300 兆瓦 AI 数据中心,估计需要 10 亿至 13 亿美元的电力系统和 6 亿至 8 亿美元的冷却系统。这些不是独立的资本项目。它们是一个基础设施决策。
对于供应商而言,这种融合为横跨电力和冷却领域的公司创造了优势。台达在 AI 服务器电源中估计占据 60% 到 70% 的份额 [CS 供应链估计],在气冷式侧挂 CDU 市场中估计占据 65% 到 75% 的份额 [CS 供应链估计]。Vertiv 将 UPS、热管理、配电和监控作为集成系统销售。伊顿收购 Boyd 为其在配电、开关设备和 UPS 的现有地位增加了液冷业务。能够向建造 300 兆瓦园区的超大规模云服务商提供电力加冷却组合解决方案的公司,相对于那些向独立询价流程销售单个组件的公司,具有采购优势。
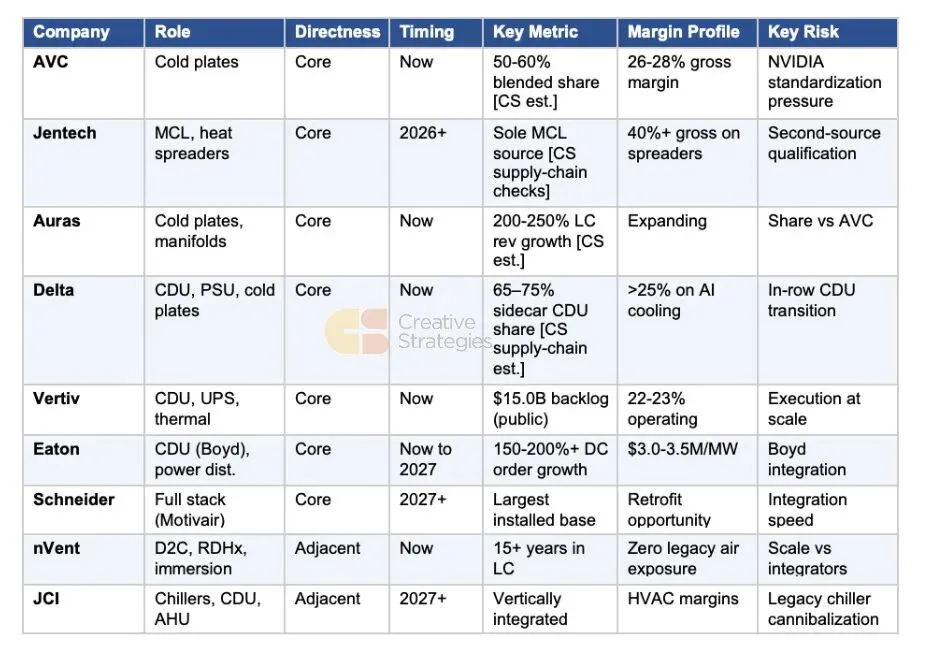
公司评分卡:全栈评估
我们根据公司风险敞口的性质将其分为三个层级:制造芯片上或芯片附近部件的组件专家,构建 CDU、歧管和机架级冷却基础设施的系统供应商,以及将冷却与电力输送和设施级系统相结合的基础设施集成商。这种区分很重要,因为竞争动态、利润率状况和收入影响的时间在不同层级间有所不同。
组件专业厂商
奇鋐科技 (3017.TW) 是液冷冷板的主导供应商,在AI GPU和ASIC平台上的综合市场份额估计为50%至60%,在旗舰AI服务器托盘冷板上的份额估计为65%至75%。营收从2024年到2026年大约增长了两倍,几乎完全由液冷内容驱动。我们关注到的是其正在进行的客户多元化:到2026年底,AI ASIC客户预计将占奇鋐液冷营收的40%至50%,而一年前这一比例几乎为零。这一转变意义重大,因为它减少了对英伟达GPU周期的依赖,并创造了第二个需求来源。我们估计,每个Vera Rubin计算托盘的冷板和歧管价值为2,500至3,000美元,每个机架有18个托盘。包括共享CDU和管道分配在内的总机架级冷却内容,每个机架达到100,000至142,000美元。奇鋐正在越南扩大产能,2026年增幅约为40%至60%,以支持产能爬坡。
双鸿科技 (3324.TW) 目前估计仅占直接液冷冷板总可寻址市场 (TAM) 的3%至5%,但正在积极扩张。2025年液冷销售额同比增长约200%至250%,公司正在越南和泰国将产能扩大50%至100%。双鸿为美国主要服务器客户供应冷板和歧管,并有望在2030年前达到10%或更高的冷板市场份额。公司的散热模组业务也受益于GPU TDP的提升,这与液冷转型无关,提供了一个相邻的增长驱动力。
晟铭电子 (3653.TW) 是我们目前在微通道冷板 (MCL) 领域最关注的公司。他们目前是先进AI GPU散热片的主要独家供应商,也是唯一一家与领先半导体代工厂测试微通道盖板设计的供应商。MCL的机会彻底改变了晟铭的增长前景:我们估计MCL销售额将从2024年的几乎为零增长到2030年的20亿至30亿美元,复合年增长率接近200%。散热片和加强片业务在2024年提供了约5亿至6亿美元的稳定基础,但推动估值逻辑的是MCL的爬坡。风险在于集中度。在第二供应商获得认证之前,独家供应商地位很有价值,随着TAM的扩大,代工厂和OEM开发替代MCL供应商的动力将会增强。
系统供应商
台达电子 (2308.TW) 在电源和冷却领域均有布局,这是亚洲供应链中任何竞争对手都无法比拟的。在冷却方面,台达在液-气侧车CDU中估计占有65%至75%的份额,并且是Vera Rubin平台合格的冷板模块供应商。台达正在内部开发微通道盖板设计和包括两相冷却在内的替代解决方案。我们估计,到2026年,液冷营收将增长至总营收的约8%至12%,而AI服务器电源业务同比增长超过一倍。电源加冷却的综合优势使台达在构建集成AI基础设施的超大规模计算公司面前拥有采购优势。我们在第一部分详细介绍了台达的电源资质,并将其确定为核心持仓。其冷却业务地位强化了这一观点。
CoolIT(被艺康以约45亿至50亿美元收购)估计占据直接芯片级冷却市场8%至12%的份额,并已为全球许多领先的超级计算机冷却了数百万个GPU。艺康的收购标志着向冷却即服务模式的转变,其商业模式从设备销售转向集成了流体化学监测、压力稳定性和流量平衡的经常性热管理服务。这种服务模式很有趣,因为它将资本支出销售转化为具有更高转换成本的经常性收入流。
基础设施集成商
维谛技术 (VRT) 报告2025年第四季度订单超过80亿美元,有机同比增长超过200%,积压订单达150亿美元。我们在第一部分讨论电力基础设施时引用了这些数字,但维谛的热管理业务同样为转型做好了准备。维谛已将液冷制造产能扩大了约40至50倍,并正在共同开发英伟达GB200参考冷却设计。2026财年营收指引为132.5亿至137.5亿美元,调整后营业利润率为22%至23%,这反映了电力和冷却内容。我们估计,维谛每兆瓦数据中心容量的内容价值为250万至350万美元,涵盖UPS、热管理、配电和监控。服务业务约占营收的20%至25%,增加了纯组件供应商所缺乏的经常性收入层。
伊顿公司 (ETN) 通过其约90亿至100亿美元收购Boyd直接进入液冷市场,此次收购带来了CDU制造、冷板能力以及已建立的超大规模计算公司关系。我们估计,在收购前,Boyd 80%至90%的营收来自超大规模计算客户。我们在第一部分估计,伊顿的电气内容价值为每兆瓦300万至350万美元。收购Boyd为此内容增加了热管理层,使伊顿向台达和维谛已经拥有的全栈地位迈进。伊顿的数据中心订单在最近几个季度同比增长约150%至200%或更多,积压订单增长25%至35%支撑了其爬坡轨迹。
施耐德电气 (SU.PA) 以约8.5亿美元收购了Motivair 75%的控股权,剩余权益预计将于2028年完成交易。该交易使施耐德获得了CDU和流体管理能力,使其成为少数几家拥有涵盖冷板、CDU、歧管和设施级系统的完整液冷能力的公司之一。施耐德在现有数据中心中拥有庞大的电气基础设施安装基础,这创造了一个竞争对手难以匹敌的改造渠道。施耐德面临的问题是执行速度:该公司的优势在于广度与安装基础,但液冷市场发展迅速,收购的初创公司需要整合和扩大规模。
记分卡
整合浪潮
过去十二个月液冷领域并购的速度和规模表明了一个具体信号:传统数据中心基础设施公司认为热架构即将发生转变,他们正在购买那些无法通过内部有机方式快速构建的能力。这些交易值得记录,因为支付的价格以及每笔交易背后的战略逻辑揭示了这些收购方如何看待这一机会。
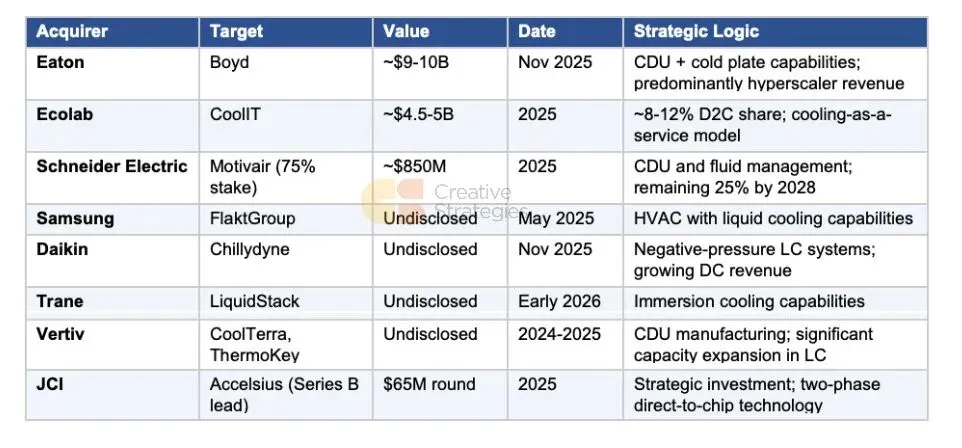
已披露和估计的总交易价值超过150亿至160亿美元。收购方包括传统HVAC公司(大金、特灵、江森自控)、传统电气基础设施公司(伊顿、施耐德)以及工业集团(三星、艺康)。在已披露交易条款的情况下,估值倍数因结构而异。施耐德将Motivair的估值描述为预计营收的中个位数倍数。伊顿和艺康分别披露了基于EBITDA的Boyd和CoolIT估值倍数。其他几项交易价值仍未完全披露。这些交易中一致的是,战略上愿意为收购方在市场需求时间内无法内部构建的能力支付溢价。液冷领域剩余的私人收购目标正在减少。CoolerMaster和少数几家较小的专业公司仍然独立,但战略买家以合理估值收购差异化液冷能力的窗口正在关闭。
催化剂追踪
以下里程碑涵盖了生态系统层面的发展和公司特定的触发因素。我们将追踪每一项,并在证据积累时更新我们的观点。
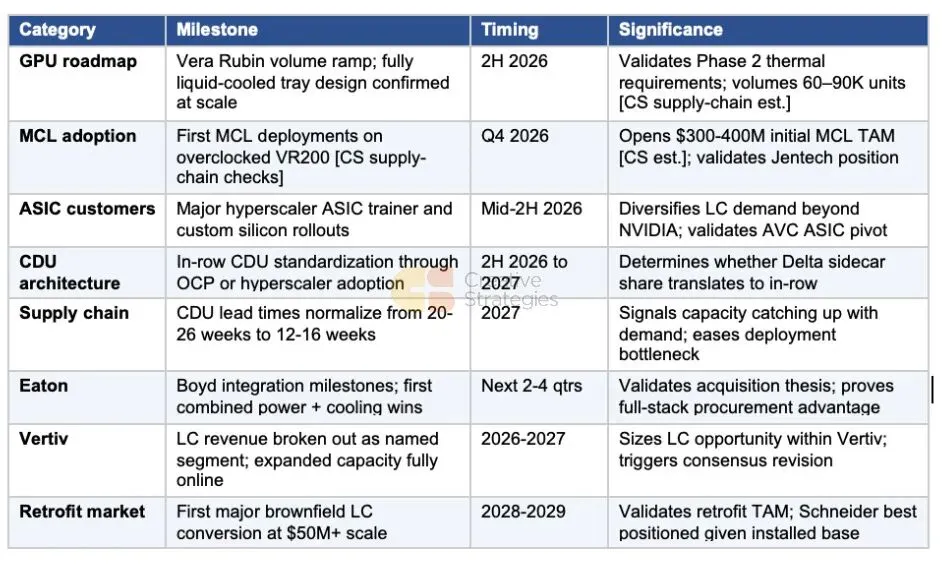
风险与可能改变我们看法的因素
我们针对每项风险,列出了会导致我们修正评估的具体条件。
来自英伟达L10标准化的冷板商品化。英伟达向标准化冷板规格(称为L10)的转变可能会降低单价并压缩冷板供应商的利润率。使这成为重大担忧的条件是:在一个GPU代际内,冷板平均售价下降超过25%,而每个机架的内容价值增长不足以抵消单价下降。我们正在关注奇鋐和双鸿在季度电话会议上的定价评论。缓解因素是,即使单价趋于平稳,每个机架的内容价值仍在持续增加,因为组件数量和热系统的复杂性都在增长。我们目前的观点是,至少在2028年之前,销量增长和内容升级将抵消标准化带来的价格压力。
CDU供应链瓶颈成为部署制约因素。CDU的交货时间已从历史上的12至16周延长至目前的20至26周,用于防泄漏的快速断开接头也出现供应紧张。如果交货时间在2027年年中之前未能恢复正常,CDU的可用性可能成为液冷机架部署的刚性制约因素,类似于变压器交货时间目前制约新设施建设的情况。会改变我们看法的条件是:主要供应商未宣布产能扩张计划,且CDU交货时间超过30周。我们正在追踪主要CDU供应商(包括维谛和台达)的产能扩张时间表。
浸没式冷却进展快于预期。如果浸没式冷却在直接芯片级冷却达到其热极限之前解决了其部署障碍(特别是设施改造成本、硬件兼容性和流体成本),市场轨迹将会改变。条件是:一家主要超大规模计算公司在2029年之前宣布部署一个超过100兆瓦的浸没式冷却项目,且总拥有成本与直接芯片级冷却持平。特灵收购LiquidStack以及江森自控对Accelsius的战略投资表明,两家公司都在为这种可能性做准备。我们判断到2030年这种可能性较低,因为MCL技术正在足够快地扩展直接芯片级冷却的可行范围,以保持在密度曲线的前沿。
计算环境中液体带来的运营风险。液冷引入了风冷所没有的故障模式:冷却液泄漏、需要更换冷板的藻类或细菌大量繁殖导致的生物污染、管道路径中不同金属引起的电偶腐蚀,以及压力谐波引起的空化。行业消息来源表明,在主要托管设施中,因冷却故障导致的SLA罚款,即使是短暂中断也可能达到1000万美元或更多。如果高调的液冷故障累积并导致运营商放缓部署,则采用时间表将会延长。条件是:多家一级运营商在18个月内报告液冷可靠性低于99.99%的可用性。我们正在关注运营商关于可靠性的评论以及冷却即服务模式(如艺康通过CoolIT集成的3D TRASAR)的发展,这些模式将运营风险转移给了供应商。
数字变动需要发生什么
主题逻辑已经足够有力。买方读者需要的是从机架密度假设到具体公司营收和盈利的更紧密的桥梁。下面我们列出,对于每家关键公司,将推动重大估计修正的具体条件和时间。除非另有说明,所有营收数据均为CS估计。
组件专业厂商
奇鋐科技:近期催化剂是2026年下半年的ASIC客户爬坡。如果亚马逊云服务和谷歌的自定义芯片项目按计划达到大规模液冷部署,奇鋐的客户多元化将加速,并减少对英伟达周期的依赖。我们估计,到2027年,奇鋐的液冷营收可能占总营收的40%至50%,而2025年约为20%至25%。推动向上修正的条件是:每个托盘的ASIC冷板内容价值证明与GPU托盘内容相当或更高,我们早期的调查表明情况确实如此,因为设计复杂性更高。可能导致失望的条件是:英伟达L10标准化压缩冷板平均售价的速度快于内容增长所能抵消的程度,我们认为这在2028年之前不太可能发生,但值得通过奇鋐的季度利润率披露来监测。
晟铭电子:这是一个与MCL认证时间相关的二元情景。如果MCL生产如我们调查所示在2026年底开始,晟铭的营收状况将完全改变,因为每单位MCL的内容价值是散热片内容的数倍。2027年的盈利修正取决于VR300级平台是否大规模采用MCL。上行条件是:MCL量产确认为2027年平台发布做好准备,且晟铭保持独家或主导供应商地位。下行条件是:第二家MCL供应商比预期更早获得认证,或者由于制造良率挑战,MCL的采用推迟到2027年之后。我们正在关注代工厂关于MCL集成准备情况的评论。
双鸿科技:从小基数扩张意味着高百分比增长率,但绝对营收贡献取决于双鸿能否在旗舰GPU冷板上从奇鋐手中夺取份额,或者其增长是否主要来自ASIC平台和二线服务器OEM。估计修正取决于未来两到四个季度披露的客户订单。如果双鸿在主要的下一代平台上获得主要的冷板供应商地位,那么2027年的营收轨迹将发生重大变化。
系统供应商与集成商
台达:其营收增长桥梁由两部分构成。首先,AI服务器电源供应营收,我们估计在2026年因GB300的批量出货将增长超过一倍[CS估计]。其次,液冷营收,其百分比增长较为温和,但能增加利润率。当前估计之外出现实质性上行的条件是:800 VDC方案在2026年下半年被多家超大规模客户提前采用,这将使台达每机柜的电源价值量相比当前代配置增加20%至30%。我们的供应链核查表明,至少有两到三家美国超大规模客户正与台达合作,为2026年下半年开始的ASIC部署开发HVDC机柜架构。如果这些项目达到量产规模,台达2027年的业绩数字需要上调。行级CDU的转型是中期变量。如果台达将其侧置CDU定位适配到行级架构,冷却营收的轨迹将变得更加陡峭。如果超大规模客户标准化采用专有的行级设计,即使市场总量增长,台达的CDU份额也可能受到挤压。
维谛:150亿美元的积压订单提供了近期可见性,但盈利预测修正取决于其中有多少能在2026年(而非2027年)转化为营收,以及该积压订单中液冷的组合比例。维谛目前并未将液冷作为单独命名的营收项目披露。当其披露时,市场共识将有一个锚点来建模。具体的催化剂是:如果维谛在未来两到四个季度内将液冷营收作为一个独立细分市场披露,且该数字显著高于市场此前隐含的预期,那么盈利预测将发生变动。我们认为,到2027年,液冷可能占维谛热管理营收的15%至20%[CS估计],而两年前仅为低个位数百分比。更广泛的风险在于,维谛当前的估值已经反映了大规模基础设施建设的预期,因此盈利修正的幅度必须足够大,才能推动一只市场已在支付溢价的股票。
伊顿:收购Boyd创造了一条12个月前不存在的营收桥梁。问题在于伊顿能以多快的速度将Boyd的液冷能力整合到其现有的超大规模客户采购关系中,以及其“电源+冷却”组合方案能否赢得更多客户份额。我们估计,托管和企业市场会在大约18至24个月的滞后时间后跟随超大规模客户的步伐,这意味着伊顿的液冷营收贡献可能在2028年而非2027年出现拐点。近期的盈利预测修正取决于Boyd的整合里程碑,以及伊顿是否会在未来两到四个季度内报告“电源+冷却”组合方案的订单胜利。
对投资者的启示
液冷领域的共识差距,其结构与我们在800 VDC分析中发现的相似:市场已经认识到发展方向,但尚未完全定价每机柜价值量升级的幅度,也未完全定价ASIC客户需求正以多快的速度使市场多元化,从而超越英伟达GPU周期。
双鸿的液冷营收正以大约每年两到三倍的速度增长,而ASIC客户组合在一年内从接近零转变为占液冷营收估计40%至50%,这是一个大多数模型尚未吸收的数据点。健策的MCL机会创造了一条共识预期中不存在的增长曲线,因为该产品类别在12个月前几乎不存在。台达的“电源+冷却”组合地位赋予其采购优势,随着超大规模客户围绕集成基础设施合作伙伴整合其供应商关系,这应能转化为市场份额的增长。
基础设施集成商——维谛、伊顿和施耐德——提供了另一种机会。它们的订单簿和积压订单已经反映了需求信号,但在我们所见的任何地方,这些数字中的液冷内容并未作为单独命名的营收项目被拆分出来。当维谛、伊顿或施耐德开始将液冷营收作为一个独立细分市场披露时,市场将拥有一个衡量该机会规模的锚点,届时市场共识模型将需要调整。
最广泛的启示与我们在第一部分阐述的主题相关联:未来的数据中心正由其在单位占地面积、单位输入功率和单位冷却能力下能集中多少算力来定义。电源架构和热管理是决定这一上限的两个基础设施层。我们现在已经涵盖了这两个方面。在每个层面控制关键节点,尤其是那些横跨两个层面的公司,正被置于科技行业历史上资本最密集的基础设施建设的中心。
