 夜雨聆风
夜雨聆风





AI视频生成观察|阿里这匹”欢乐马”把字节按住了,豆包的人脸却越长越像同一个人
昨天傍晚阿里把 HappyHorse 1.0 推到了灰测,从今天起开始送积分。这匹马背后到底是什么货色,我玩了一下,几个点是真的有点炸——但比”炸”更值得说的,是它逼着所有人重新看一眼这两年AI视频走过的路。这事放到2026年4月的视频生成赛道里看,分量不小。
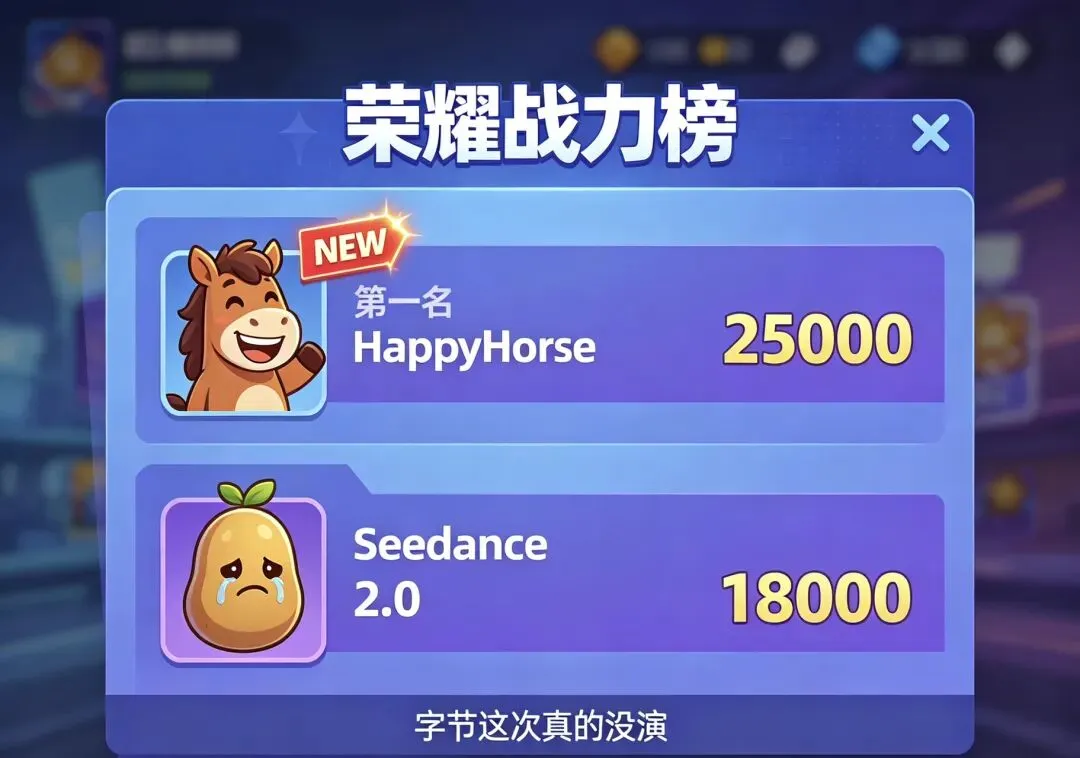
先说 HappyHorse 这名字怎么来的。今年4月初,Artificial Analysis 的盲测榜单上突然冒出来一个匿名模型,叫 HappyHorse,没人认领,没发布会,没技术博客,就那么直接把字节的 Seedance 2.0 从 i2v 第一名的位置上拽了下来。在文本转视频赛道用 Elo 1333 到 1357 的分数压过 Seedance 2.0 的 1273 分,领先近 60 分;图生视频赛道更是刷到了 1391 到 1406 。官网的语言排序里普通话和粤语排在英语前面 ,懂的人立刻就明白了——这是中国队的活儿。后来阿里认领,说这是 ATH 创新事业部主导,联合通义实验室搞出来的 。带队的是张迪,原快手副总裁,可灵的技术负责人,2025年底跳到了阿里。人是从隔壁挖来的,但活儿是新做的。
AI视频这条路,过去三年简直是一部”先吹牛、再翻车、再吹牛”的连续剧。
三年AI视频生成史,骨子里就一句话
2024年2月,OpenAI 把 Sora 的 demo 视频放出来那天,整个行业像被人捅了马蜂窝。一段海岸边小狗追海浪的视频,60秒,画面稳得像院线片。那之后所有人都在等 Sora 公测,结果等到的是——它一直在等。技术 demo 漂亮,落到产品手里费劲。
那段时间最重要的一个技术词是 DiT。就是把过去画图用的扩散模型(Diffusion)和写字用的 Transformer 拼到一起,让模型既会”涂鸦”又会”上下文”。这个思路是 William Peebles 和谢赛宁两个人在 2022 年的论文里提出来的,DiT 后来被广泛认为是 Sora 背后的技术基础之一 。说白了就是 AI 不再像画家一样从白纸往上涂,而是先给你一张全是噪点的电视雪花屏,然后一遍一遍地”擦”,擦到你要的画面浮出来。
这条路一通,全行业就跟着钻进同一个洞里。
字节的 Seedance、快手的可灵、生数的 Vidu、爱诗的 PixVerse,技术路径全收敛到 DiT 扩散 Transformer 架构上 。中间也有人想走另一条路——比如 Sand AI 坚持用自回归(就是大语言模型那种”猜下一个 token”的思路)来做视频,但坦白说没跑出多大水花。原因也直白:高维连续的像素空间充满了幻觉的深渊,单纯的自回归往往导致画面崩塌 ——一个像素一个像素往后猜,猜着猜着就猜歪了,跟一个微醺的人说话越说越离题是一个道理。
到了 2025 年下半年,DiT 这条路开始遇到天花板:画面是好看了,但音画对不上、人物动作飘、超过10秒就开始”脸跑了”。然后就是今年2月,字节的 Seedance 2.0 一上线就把社群冲爆,小云雀APP里生成15秒视频排队8小时,A股相关概念股集体涨停 。冯骥发了那句”AIGC的童年时代结束了”。Seedance 2.0 的关键创新是把音视频联合生成做进了同一个模型里——以前是先出画面再贴音轨,现在是画面和声音一起长出来,自然就同步。
但 Seedance 2.0 有个让人扫兴的事。
那块”豆包脸”的玻璃,越擦越雾
你要是用过豆包生成视频,肯定有过这个感觉:生成出来的人,长得都像同一个表姐的同学。塌鼻梁微调过的、双眼皮像贴出来的、肤色统一带点滤镜光、笑起来嘴角弧度都一致——一种”AI网红脸”。男的也是同一套模板,浓眉、瘦脸、带点哭腔的眼神。

技术上的根子有两条。第一条是训练数据。研究发现 Stable Diffusion 在生成人脸时存在严重的”种族同质化”——同一个种族的人被画得彼此过于相似 。视频模型继承了图像模型的底子,这些偏差来自训练数据本身、算法设计和最终用户对输出的解读 。中国互联网上喂给模型的”人脸”,大多数是抖音、小红书、淘宝模特照——本来就是经过滤镜、磨皮、拉鼻梁、瘦下巴标准化过一遍的脸。模型把这些当”美的样本”学,学出来的当然是同一张脸的不同角度。
第二条是平台主动做的安全约束。Seedance 2.0 上线后,即梦web端、小云雀等平台都明确提示暂不支持真人人脸作为参考素材;只有在即梦App和豆包App里完成活体认证后才能制作数字分身 。意思就是:你想喂一张”具体的真人脸”进去?不行。你只能用模型脑子里”长得像某种人”的模板。这是为了防深度伪造,方向当然对——但代价就是模型只敢往最大公约数的脸上去靠。一张不会出事的脸,必然是一张谁都不像、谁也都像的脸。
这就好比让一个画家画肖像,但不准他看任何人。他画出来的所有人,最后都长得像他自己。
HappyHorse 这次的炸点,恰好就在这里。我玩的时候试了几张人脸图,真人感比 Seedance 2.0 强一个档次——不是说 Seedance 不好,是 HappyHorse 在”这是一个具体的人,不是一种人”这件事上更稳。技术上它用了纯自注意力单流架构,前后各4层模态特定层,中间32层共享参数;这种设计让音画对齐更天然,避免了多管道拼接带来的割裂感 。再加上文本输入直接同步生成视频和音频,不需要单独的音频处理管道 ,从根上就跟 Seedance 不在同一个玩法里。
更关键的是——它开源。完整模型权重、蒸馏版本、视频超分辨率模块和全套推理代码都已通过 GitHub 公开发布,附带商业友好的授权许可 。这就是为什么海外那些做出海短剧的团队这两天集体起夜——他们终于不用再求字节给内测码了,自己就能本地跑一份。
几个让我觉得”这下能搞事”的点
我在 happyhorse.cn 上玩了一晚上,以下几个细节是真的有点意思:
人脸不再”一眼假”。同一张参考图,HappyHorse 出的视频里这个人在不同镜头里还是这个人,不会”开头是表姐结尾变堂妹”。做海外真人短剧的兄弟们,这是你们等了一年的工具。
音视频联合生成,台词口型自动对,连环境音都给你做好。以前做一个5秒短视频,得分别处理画面、配音、音效、对口型——四道工序,至少一个下午。现在丢一段台词进去,出来就是齐活的成品。这不是省时间,这是把视频制作从一个工种变成一句话。
中英混说也能对口型。这点是真离谱。Seedance 2.0 的口型同步在纯中文或纯英文里做得不错,但中英夹杂的口播——比如出海广告里常见的”今天给大家recommend一款”——基本就废了。HappyHorse 在这块明显训过专门的数据。
最离谱的是榜单。在 Artificial Analysis 的 i2v 带音频排行榜上,HappyHorse 已经超过 Seedance 2.0,目前第一 。一个开源模型把闭源商业模型按到地上,这事在大语言模型领域见过(DeepSeek),在视频生成领域是头一遭。
所以这事到底说明什么
说明 AI 视频生成这条路,从今天开始进入了开源跟闭源贴身肉搏的阶段。Seedance 2.0 还会继续好用,可灵也不会立刻死,但开源效果可以媲美闭源这个共识一旦立住,整个商业模式就要重新算账。你卖0.9元一秒的接口,对面同样的效果免费给你 GitHub 仓库——这门生意还做不做?
至于豆包那张”AI网红脸”,HappyHorse 不能根治,但至少证明了一件事:问题不是技术做不到,是有人选择不做。中国的视频模型平台过去几个月集体加严了真人人脸的约束,方向是对的,可代价就是每个人生成出来的视频都长着一张相似的脸。这是合规成本,不是技术上限。
现在阿里认领了 HappyHorse,开源了权重,你想怎么微调就怎么微调。保安总算把钥匙挂回了门口。能不能进去,看你自己想干嘛。
就在我写这篇的时候,HappyHorse 的官网积分系统刚刚开始送,刊例价 720P 视频生成 0.44 元/秒。对比一下 Seedance 2.0 的 0.9 元/秒,价格直接砍到一半。千问 App 更新到最新版,点首页下方”HappyHorse”按钮就能体验 。
你今晚就能试。
长按关注,聊点硬核的。
往期推荐:微信里养小龙虾的时代正式开始
作者:AI临界点 · 用普通人听得懂的话聊AI
#AI视频生成 #HappyHorse #开源大模型 #AI工具 #普通人的AI指南