 夜雨聆风
夜雨聆风





拆解Claude Code源码|03:只会生成文本的AI,怎么学会"动手做事"?
这是「拆解 Claude Code 源码」系列的第 3 篇。上一篇我们拆解了 Agent 的”记忆”系统——它靠一个文本数组来”记住”世界。这一篇,我们来看一个更本质的问题:光能”记住”,有什么用?如何让模型帮助我干活?
一个看起来理所当然、但细想很奇怪的事
你对 Claude Code 说”帮我把这份会议纪要整理成表格”。
几秒钟后,它真的读了你的文件、整理好了内容、写了一份新文件。
你对它说”帮我搜一下竞品最近的融资信息”。
它真的去搜了、读了结果、给你整理了一份摘要。
等等——它怎么做到的?
上一篇我们说过,大模型本质上就是一个文本生成器。它的全部能力就是:读进去一段文字,生成下一段文字。 它不能打开文件、不能执行命令、不能访问网页、不能操作任何外部系统。
那”读文件””写文件””搜索代码”这些动作,到底是怎么发生的?
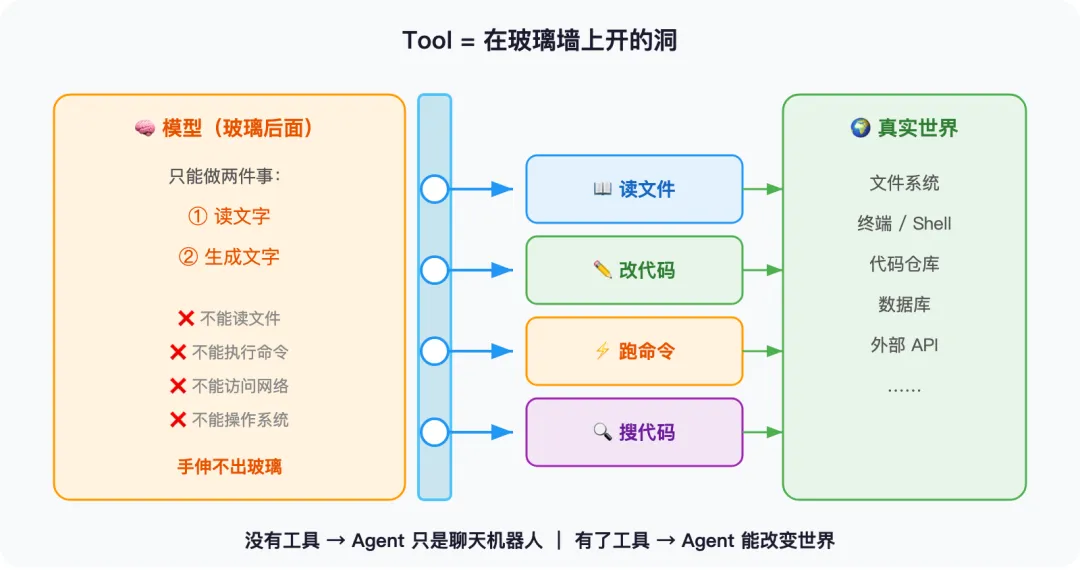
想象一个坐在隔音玻璃后面的专家。他能看到你递进来的资料(上下文),能写下分析和建议(生成文本),但他的手伸不出玻璃——他碰不到你桌上的任何东西。
要让他”做事”,你得在玻璃上开几个洞,每个洞旁边装一个按钮,贴上标签:”读文件”、”改代码”、”跑命令”。专家想做什么,就按对应的按钮,你这边的机器会替他执行。
这些”按钮”,就是工具(Tool)。
没有工具,Agent 就只是一个聊天机器人。
Tool = Agent 与世界交互的唯一通道。你给 Agent 接了什么工具,它就能做什么;没接的,它做不了。
知道了工具是”按钮”,你可能会好奇:模型是怎么”按”按钮的?它明明只会生成文字啊。
一次工具调用,到底发生了什么?
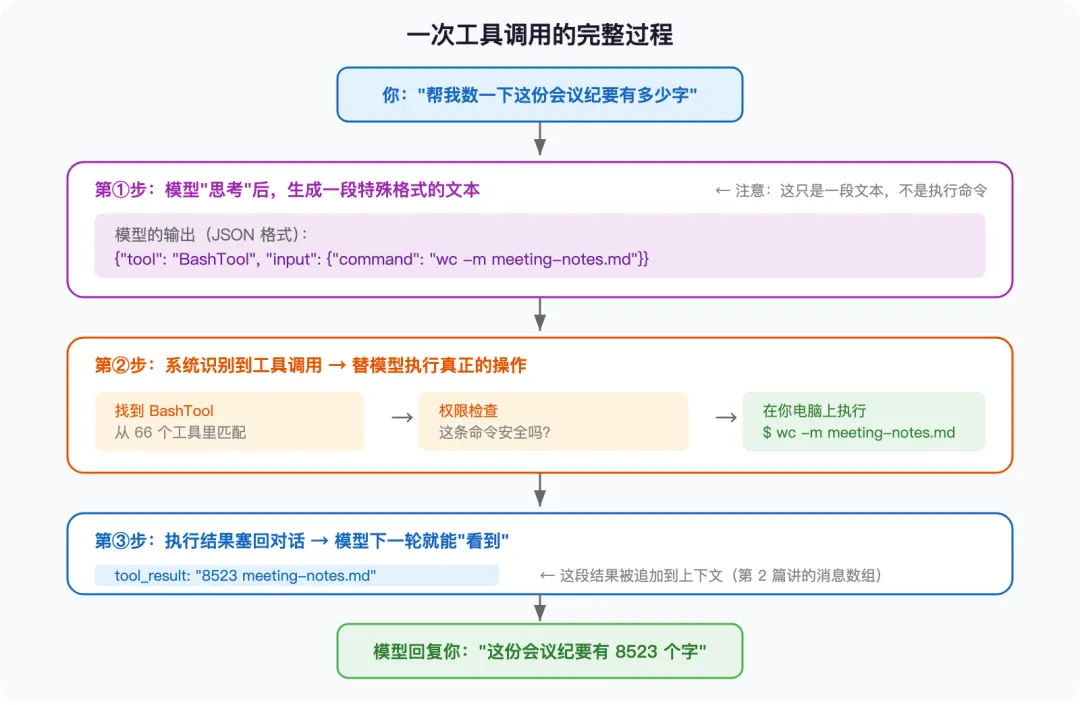
拿一个真实场景走一遍。你对 Claude Code 说:”帮我数一下这份会议纪要有多少字。”(假设文件叫 meeting-notes.md)
模型做了什么?
咱们上一篇聊过——模型其实有点”两眼一抹黑”:它既看不见你的文件,也不知道自己手上有什么本事。它需要被”告知”。
所以你跟模型说话的同时,系统在背后悄悄做了三件事——递菜单、扫菜单、写订单。
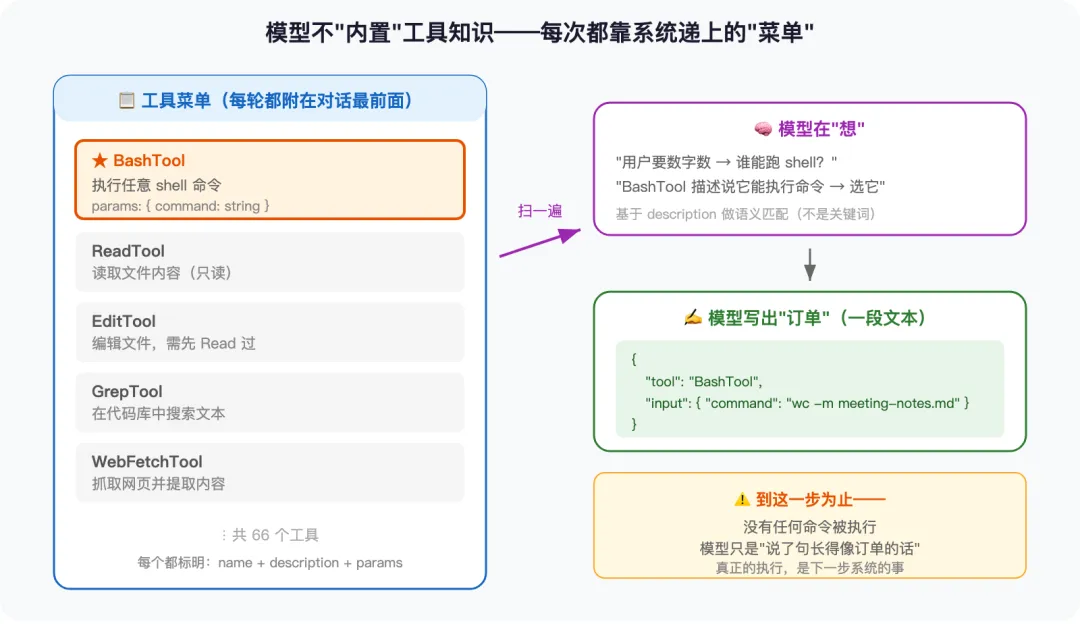
① 系统先递上一份”工具菜单”
每次找模型说话,系统都会把一份“工具菜单” 塞进对话里。这份菜单上写着 66 个工具,每个都明明白白标着:叫什么名字、能干什么、需要哪些参数。它是上一篇讲的那个”消息数组”开头的固定内容——模型每次开口前,菜单都摆在它面前。
就像你坐进一家餐厅,服务员第一件事是把菜单递到你手上。不是你脑子里”装着”这家店有什么菜,是每次坐下来菜单都重新摆一次。模型也一样——它本身不”内置”BashTool 的知识,每轮对话开始时,菜单都被重新摆到它面前。
这个机制看着不起眼,但它是 Agent 工具系统能不停扩展的根基——给模型加新本事,不用重新训练它,递一张新菜单就行。 后面讲 MCP 的时候,你会看到这个特性把工具生态撑得有多大。
② 模型扫一眼菜单,挑一个
接下来才是模型真正”思考”的那一步。它扫一眼菜单,根据每个工具的 description(描述) 做语义匹配:
“用户要数字数 → 哪个工具能跑命令?→ BashTool 的描述说它能执行 shell → 就选它了。”
注意:这不是规则匹配,也不是关键词检索,是模型基于上下文做的判断。所以工具的描述写得好不好,直接决定模型选不选得对——这也是为什么 Anthropic 反复强调,给 Agent 设计工具时,description 几乎和 code 一样重要。描述写得含糊,模型挑工具就跟你瞎点菜一样。
③ 选好了,怎么”告诉”系统?写一张订单
模型只会输出文本,所以它表达”我要用某个工具”的方式,也只能是文本——但是一种约定好的结构化格式:
{"tool": "BashTool", "input": {"command": "wc -m meeting-notes.md"}}
这就是所谓的”工具调用”。说穿了它还是模型”说了一句话”——只是这句话长得像一张订单,系统能识别出来。
到这一步为止,什么都还没发生。没有命令被执行,没有文件被读取。模型从头到尾只做了三件事:看菜单 → 挑了一个 → 写出订单。
系统做了什么?
系统拿到这张订单,做了三件事:
① 找按钮。 从 66 个工具里找到名叫 BashTool 的那个——就像在一面有 66 个按钮的面板上,找到贴着”执行命令”标签的那个。
② 检查安全。 这条命令安全吗?wc -m meeting-notes.md 只是数字数,是只读操作,没问题,放行。(如果模型想执行 rm -rf /,这一步就会被拦下来。)
③ 替模型执行。 在你的电脑上真正跑了 wc -m meeting-notes.md,拿到结果:”8523 meeting-notes.md”。
然后,系统把执行结果塞回对话——追加到上一篇讲的那个消息数组里。模型下一轮就能”看到”这个结果。
结果回到模型
模型读到 “8523 meeting-notes.md” 这个结果后,再生成一段普通文本回复你:”这份会议纪要有 8523 个字。”
完整过程串起来就是这样:
这里面最关键的一个认知
模型自始至终只在做一件事——读文本、生成文本。
它不知道工具长什么样,不知道命令真的被执行了,甚至不知道你的电脑里有没有 meeting-notes.md 这个文件。它只是在一张菜单上挑了个名字,写了张订单,然后等系统把结果”念”给它听——再相信这张返回的”小纸条”上写的是真的。
回到隔音玻璃的比喻:专家从玻璃外侧拿到一份”我能干哪些活”的清单,圈了一项写在纸条上递出去。你这边的助手照着办,把结果再写在纸条上递回去。专家全程没碰过你桌上的任何东西,他只是相信纸条上的字。
这也解释了为什么第一篇的 while(true) 循环这么重要——每一轮循环,模型都可能生成零个、一个或多个工具调用。 一个复杂任务(比如”帮我写一份竞品分析报告”)可能需要模型连续看十几次菜单、写十几张订单:先搜资料、再读文件、再创建新文件、再写入内容……每一次工具调用都是一轮循环,循环不停,Agent 就能持续”做事”。
💡 看到这你可能会冒出一个问题:好,模型这次知道用 BashTool 数字数了——那下次同样的事,它还得我从头教一遍吗? 是的——所以下一篇咱们拆 Claude Code 的 Skills 系统,让 Agent 把”做过的事”沉淀成下次能直接用的能力。顺手关注一下公众号,下篇更新你就能第一时间看到。先把工具篇看完。
理解了一次工具调用的完整过程,自然想问:Claude Code 有 66 个这样的工具——它们从哪来?怎么管?
先看全景:这么多工具从哪来?
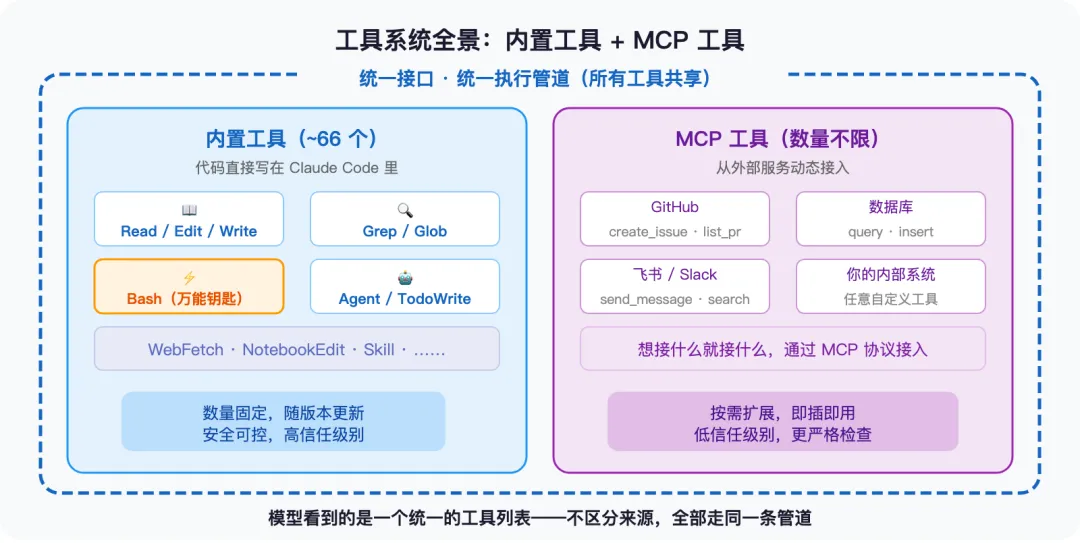
Claude Code 的 66+ 个工具分两类来源:内置工具(代码直接写在 Claude Code 里,比如读文件、搜索、执行命令)和 MCP 外接工具(通过协议从外部服务动态接入,比如 GitHub、数据库、飞书)。
关键点:不管从哪来,所有工具都遵守同一套标准、走同一条执行管道。 模型不知道也不需要知道一个工具是”自家的”还是”外面接进来的”——它只看到一个统一的工具列表。
这套”统一管道”是 Claude Code 从 20 个工具扩展到 66+ 个而不崩溃的关键。每个工具都要声明自己叫什么、做什么、是只读还是有写入、能不能并行执行。系统只维护一条管道——验证 → 权限检查 → 执行 → 结果处理——所有工具共用。加第 67 个工具?开发者只需要写”这个工具具体做什么”,其他的管道全包了。
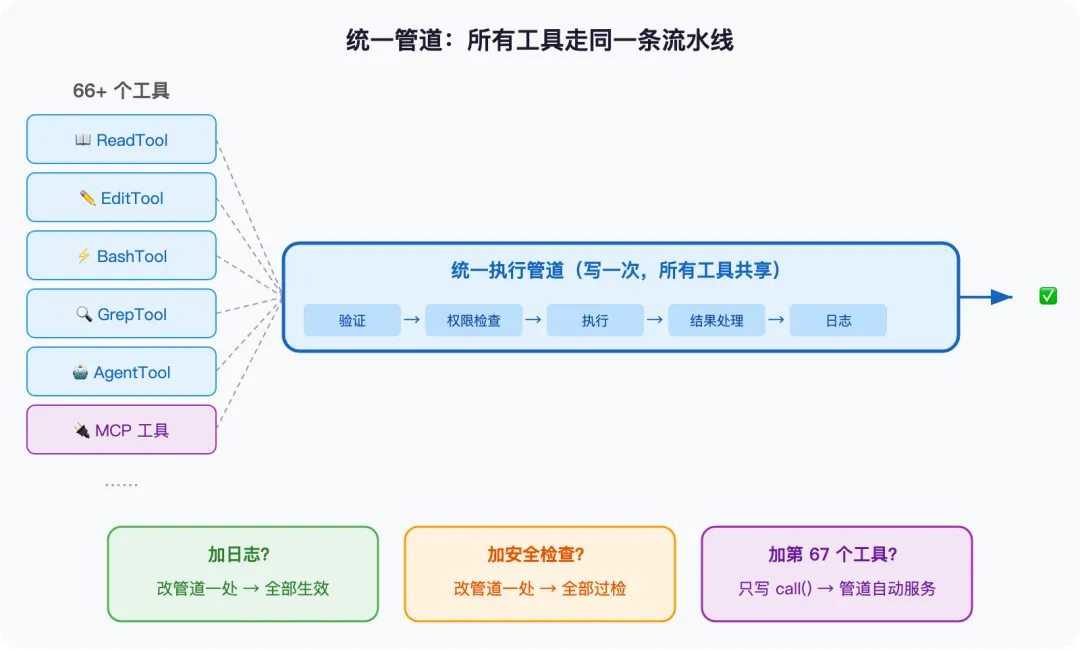
统一管道解决了”怎么管”的问题。但别忘了一个更根本的前提——使用这些工具的不是人,是模型。
我们习惯了为人设计工具——人会看说明书、人能理解报错、人知道哪些操作危险。但 Agent 的工具使用者是模型。模型有一个独特的特性:它一定会犯错、一定会产生幻觉——但它也有一个人比不了的能力:它能在循环里不知疲倦地自我纠正。
Claude Code 的工具设计,就是围绕这个特性展开的。仔细看源码,有三个设计让我印象很深——而且都挺反直觉的。
发现一:工具出错了,不修——这才是对的
既然模型一定会犯错,那工具出错了怎么办?
大部分系统的做法很直接:出错 → 抛异常 → 程序崩溃。这是给人设计的逻辑——人看到报错后会去查日志、改代码、重新启动。
但模型不是人。它能做的是:看到错误信息后,在下一轮循环里自己调整。 Claude Code 正是利用了这一点——任何工具出错,都不让程序崩溃,而是把错误信息”打包”成一条普通消息,放回对话里,让模型自己看。
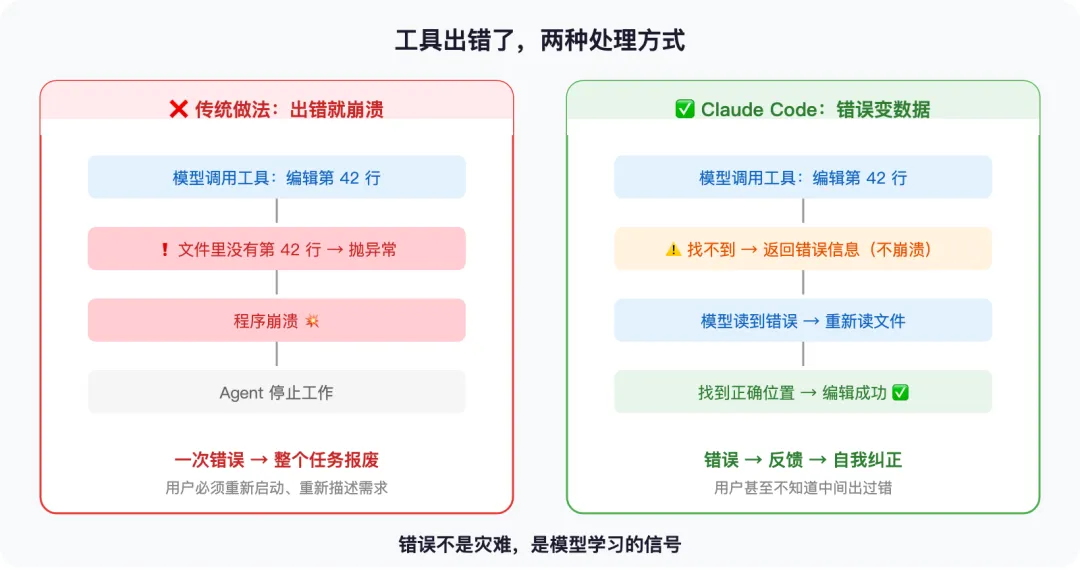
举个例子。模型想编辑一个文件的第 42 行,但文件只有 30 行。传统系统会直接报错停止。但 Claude Code 的做法是——把”找不到第 42 行”这个信息返回给模型。模型看到后,自己重新读一遍文件,发现只有 30 行,然后找到正确的位置,再试一次。用户甚至不知道中间出过错。
这跟第一篇讲的 while(true) 循环是一回事——循环的意义不只是”反复执行”,更是”出错了还能接着来”。 如果第一个工具出错就崩溃,循环就断了,Agent 的自主性也就没了。
错误不是灾难,是模型学习的信号。
如果你在设计 Agent 产品,这意味着一个具体的设计决策:工具的错误信息要像正常返回一样精心设计。 不是随便抛一个 “Error 500″,而是告诉模型”我在找 X,但找到的是 Y”——模型能读懂的错误,才能触发有效的自我纠正。
错误变成了数据,模型有机会自我纠正。但有没有可能,从设计上就让某些错误无处藏身?
发现二:”最笨”的方案,反而最合适
Claude Code 最核心的能力是帮你改代码。那它怎么改文件?
方案有很多:语法树编辑(AST)、diff 格式、全文重写、查找替换……如果让你选,你可能会觉得语法树编辑最”高级”。
但 Claude Code 选了最”笨”的那个——查找替换(Search-and-Replace)。就是你在 Word 里用的那个”查找并替换”。
为什么?因为模型一定会产生幻觉——它会”记错”代码。比如它记得某个函数叫 handleError(),但实际上早就被重命名为 processError() 了。
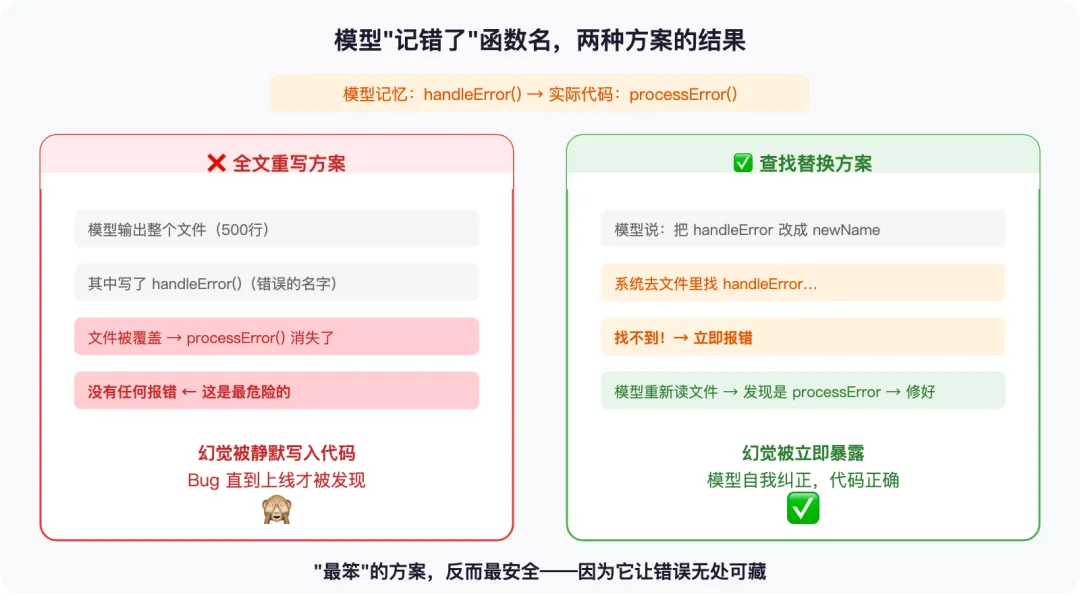
如果用全文重写,模型会把整个文件重新写一遍,顺手把 processError() 写成了 handleError()——文件被覆盖,没有任何报错,错误的代码就这么静悄悄地上线了。
但如果用查找替换呢?模型说”把 handleError 改成新名字”——系统去文件里找 handleError,找不到,立即报错。模型看到报错后重新读文件,发现正确的名字,修好了。
“笨”方案的妙处在于:它让幻觉无处藏身。 你给出的 old_string 必须在文件中真实存在——模型没法”编”一段不存在的代码来替换。
好的工具设计不是追求技术上最先进,而是匹配使用者的特性。 模型的弱点是幻觉,那就设计一个让幻觉立即暴露的方案。模型的强项是理解自然语言,那就让它用自然字符串而不是精确的行号来指定编辑位置。
前两个发现都是关于”犯错之后怎么办”。但还有一个更根本的问题:同一个工具,不同输入,危险程度天差地别——安全怎么做?
发现三:安全不是贴在工具上的标签
直觉上,给工具做权限管理,最简单的做法是:给每个工具贴一个标签——”这个安全””那个危险”。
Claude Code 不这么做。它的安全标记不是贴在工具上的,而是贴在每一次具体调用上的。
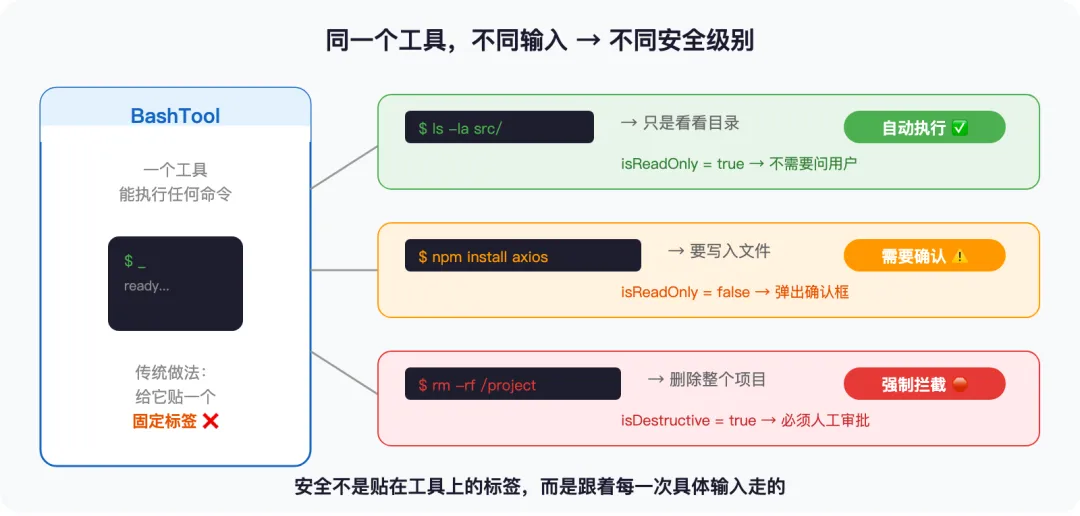
66 个工具里有一个最特殊的——BashTool,它能执行任意命令行指令,相当于一把万能钥匙。你输入 ls -la——只是看看目录,完全安全,直接执行。你输入 npm install axios——要往磁盘写东西了,弹出确认框。你输入 rm -rf /project——删除整个项目,强制拦截。
同一个工具,三种输入,三种安全级别。 源码里是这么实现的:isReadOnly(input) 和 isDestructive(input) 这两个函数都接收 input 参数——安全级别取决于你这次具体要做什么,不取决于工具本身。
而且系统的默认姿态是宁可多拦一次,也不放过一次危险操作——没标记是否只读?默认当成有写入。没标记能否并行?默认串行。万一开发者忘了配置,最差的情况是多弹一次确认框,而不是执行了危险命令。
如果你在设计 Agent 的权限系统,这意味着:不要只在”工具”维度做权限管控,要在”工具 × 输入”维度做。 一个”修改订单”的工具,改备注和改金额是两回事,不应该用同一个权限等级。
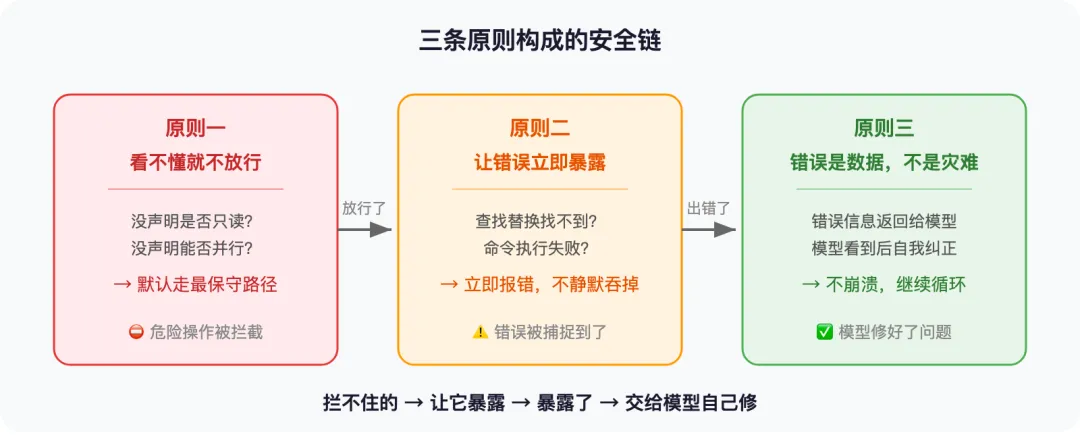
三个发现合在一起,构成了一个完整的安全网:出错不崩溃,交给模型自己修 → “笨”方案让幻觉无处藏身 → 安全级别跟着每一次具体输入走。
以上都是 66 个内置工具的故事。但如果你需要 Agent 连接飞书、Jira、公司的内部系统呢?
内置工具不够用?——MCP 让 Agent 连接一切
66 个内置工具覆盖了文件操作、代码编辑、命令执行等核心能力。但有一个根本问题:
内置工具再多,也不可能覆盖所有人的需求。
你公司用飞书沟通、用 Jira 管项目、用自建系统查数据。同事的公司用 Slack、Linear、Notion。每家公司的工具链都不一样——Claude Code 团队不可能预知并内置所有集成。
回到上一节讲的”工具菜单”——内置工具就是 Claude Code 预先印好的菜单。你公司用什么系统,Anthropic 不知道,所以菜单上没你那道菜。
有没有办法让你自己往菜单上加菜? 这就是 MCP 要解决的事。
MCP 是什么:LLM 调用工具的”USB”
一句话定位:MCP(Model Context Protocol)之于 Agent 工具生态,相当于 USB 之于硬件外设、HTTP 之于 Web。
USB 出现之前,每个新外设(鼠标、打印机、移动硬盘)都要专门写驱动、专门设计接口;USB 出现之后,所有外设按同一个标准接口造,PC 端只装一套驱动就能识别所有 USB 设备。
MCP 在 Agent 世界做的是完全同一件事:
- 之前
:Claude Code 想接飞书,要为飞书写一套对接代码;Cursor 想接飞书,又要重写一遍 - 现在
:飞书官方写一个”飞书 MCP Server”——Claude Code、Cursor、任何支持 MCP 的客户端都能直接用。写一次,到处接。
别把 MCP 理解成”插件”。插件是绑定的——为 VSCode 写的插件,IntelliJ 用不了。MCP 是协议——它定义的是一套通信规范,谁实现了规范谁就能互相对接。这就是 MCP 在 2025 年能被 OpenAI、Google、Microsoft 全部跟进的原因——它不属于任何一家公司,但所有人都能用。
三角色架构:Host / Client / Server
MCP 这套协议规定了三个角色和它们之间怎么通信。理解了这三个角色,就理解了 MCP 的全部物理结构。
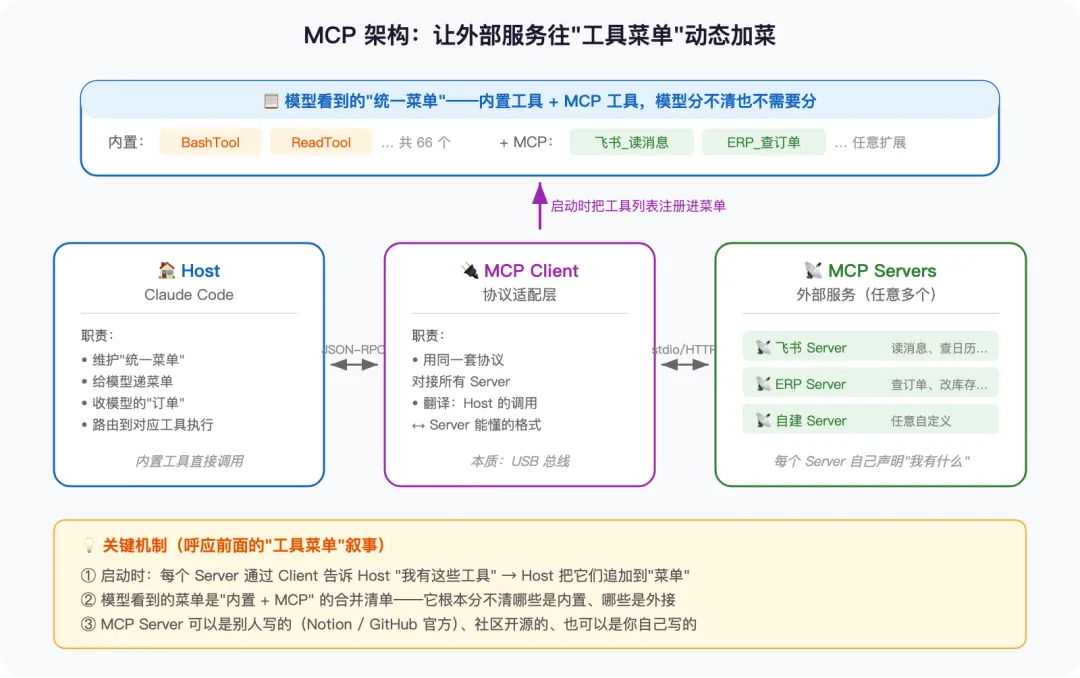
- Host(宿主)
:就是 Claude Code 自己。负责”维护菜单 + 给模型递菜单 + 收订单 + 路由执行”——前面讲的那一整套流程 - MCP Client(协议适配层)
:跑在 Host 内部的一个组件。负责用 MCP 协议跟外面的 Server 通信。模型看不到 Client 的存在,Host 也只跟 Client 打交道 - MCP Server(外部服务)
:飞书、ERP、Notion、你公司自建系统——每个 Server 自己声明”我有哪些工具、每个工具叫什么、参数是什么”
最关键的机制——启动时,每个 Server 把自己的工具清单通过 Client 告诉 Host,Host 把它们追加到那份”统一菜单”里。然后模型每轮看到的菜单,就是”内置 66 个 + 所有 MCP Server 提供的工具”——模型根本分不清哪些是 Anthropic 写的、哪些是你公司接进来的。
为什么必须是三层(不是两层、四层、单层)?
看到这套架构,你可能问的不是”它是什么”,而是”它为什么必须是这样“——少一层不行吗?多一层会更好吗?
其实这套架构不是设计师拍脑袋分的,而是被三个底层约束的必然。
约束 ①:模型只会读写文本 → 必须有 Host 替它执行
模型本身没有网络通信能力、没有文件系统访问、没有进程调度。你公司的 ERP 跑在内网某台服务器上,模型在 Anthropic 的 GPU 上——它够不到。所以 Host(一个跑在用户本地的程序)是必需的,由它代替模型去真正”做事”。
→ 这就排除了”单层”方案:模型不可能直接调 Server。
约束 ②:Host 和 Server 是 N × M 关系 → 必须有协议层
世界上 Host 有多少个?Claude Code、Cursor、Cline、ChatGPT Desktop、Gemini CLI…… N 个。Server 呢?飞书、ERP、Notion、GitHub、Postgres…… M 个。
如果让 Host 直接对接 Server,要写 N × M 套适配代码——飞书要分别给 Claude / GPT / Gemini 写 3 套对接,集成方累死。这就是 MCP 出现之前的世界。
加一层”协议层”,双方都只对接协议、不对接对方——复杂度从 N × M 降到 N + M。
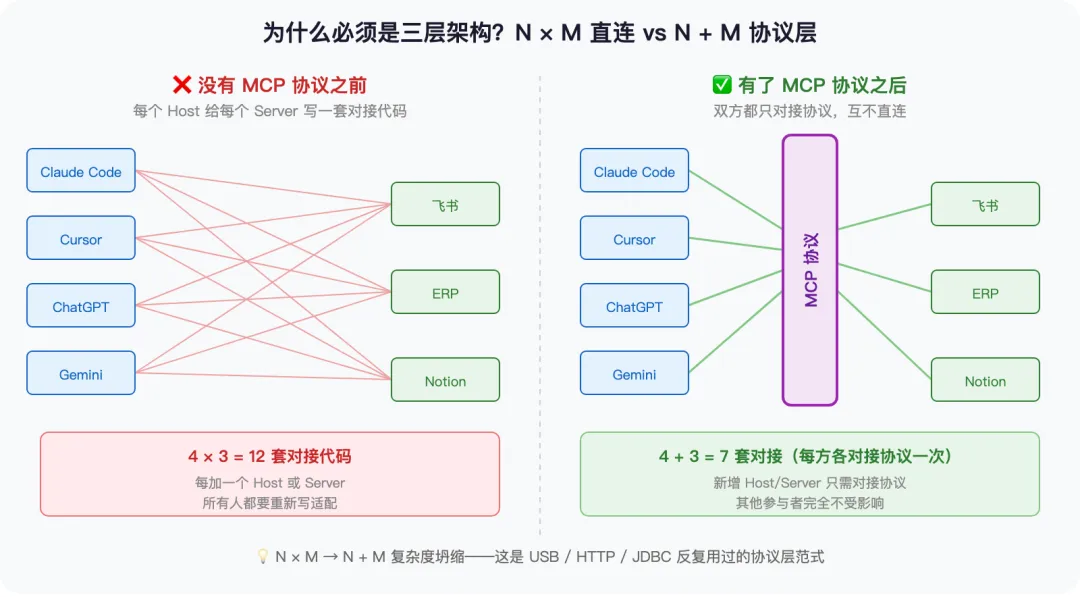
→ 这就排除了”两层直连”方案。
约束 ③:协议层必须贴近 Host → 不能是独立中介
那为什么 Client 不能是个独立服务(变成四层架构:Host ↔ 中央 Hub ↔ Client ↔ Server)?
-
Host 拿到 Server 的工具清单后要立刻塞进自己的”菜单”——这是高频近距离通信,多一跳延迟不可接受 -
多一个中央 Hub = 多一个故障点,还多一个”谁维护、谁付费”的商业问题 -
中央 Hub 还破坏了 MCP 的核心卖点——去中心化、厂商中立
→ 这就排除了”四层带中央 Hub”方案。
剩下的只能是:Host 内部嵌一个 Client,Client 用 MCP 协议跟外部 Server 通信。三层架构是这三个约束下的唯一解。
这套架构其实你早就见过
讲到这你可能已经隐隐有种”似曾相识”的感觉——三角色架构不是 MCP 独创的,而是计算机史上反复出现的范式:
|
|
|
|
|
|---|---|---|---|
| Web |
|
|
|
| USB |
|
|
|
| 数据库 |
|
|
|
| MCP |
|
|
|
任何要实现”一对多接入 + 跨厂商兼容”的场景,最优解都收敛到这个三角色结构。 MCP 不是发明了新架构,而是把这个被反复验证过的范式,套用到 LLM 工具生态——这也是它能被全行业接受的根本原因:所有人都用过类似的东西,没有学习曲线。
端到端:电商客服接 ERP MCP 时到底发生了什么
光讲架构还是抽象。拿一个具体的电商客服 Agent 走一遍——这一段把”配置 → 启动 → 运行”完整链路串清楚。
基于 cc 的简化版的流程,这里只保留”工具是怎么从 MCP 走到模型再走回来”的主链路。
配置阶段(一次性):你在 Claude Code 的配置文件里加一行——告诉它”启动时去连一个 ERP MCP Server,地址在这里”。
启动阶段(每次开 Claude Code):
-
Claude Code 通过 MCP Client 连上你的 ERP Server -
Server 自报家门:”我提供 3 个工具—— 查订单状态、查物流、处理退款,每个的参数是 xxx,描述是 xxx” -
Claude Code 把这 3 个工具追加到内部维护的”工具菜单”里——和内置的 66 个并列
运行阶段(用户提问时):
-
用户问:”我昨天的订单到哪了?订单号 12345″ -
Claude Code 把当前菜单(66 个内置 + 3 个 ERP MCP 工具)打包递给模型 -
模型扫菜单,看到 查物流的描述——”查询订单的物流状态”——选了它,写出订单:{"tool": "查物流", "input": {"order_id": "12345"}} -
Claude Code 收到订单,识别出这是 MCP 工具,通过 Client 转发给 ERP Server 执行 -
Server 真去查了你的 ERP 系统,把结果返回 -
结果原路回到模型,模型用自然语言回复用户
整条流程的时序长这样:
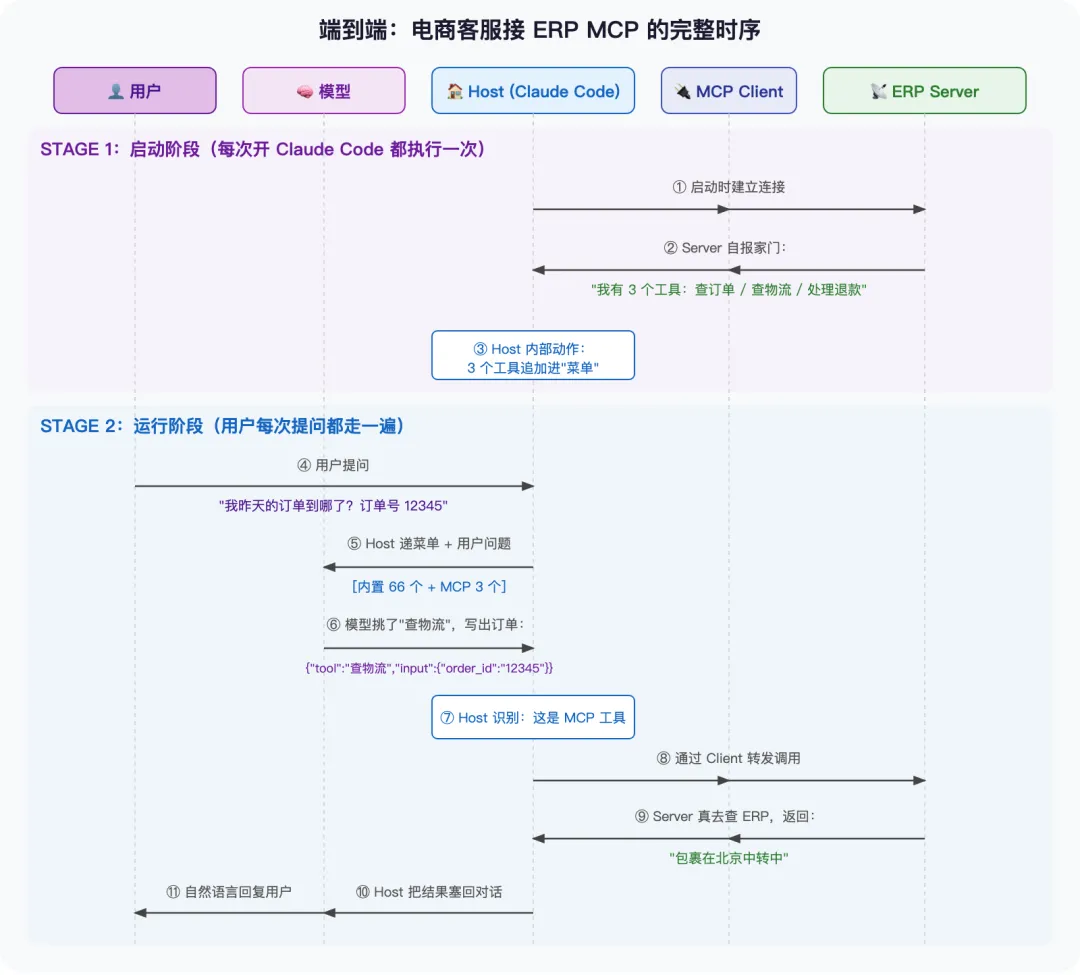
整条链路下来,模型只做了一件事——和上一节”BashTool 数行数”完全一样:看菜单、挑工具、写订单。 它不知道 查物流 是 MCP 工具,也不知道背后是你的 ERP——对模型来说,菜单上的每个名字都是平等的。
安全:MCP 走”零信任”接入
MCP 工具走的执行管道跟内置工具完全一致——验证、权限检查、结果处理一个不少。但有一个底层原则:MCP 工具默认按”零信任”对待。
自家厨师做的菜你放心吃,但外卖你会多看两眼——因为外卖餐厅的厨房你看不到。MCP Server 可能是你自己写的本地脚本(安全),也可能是从网上下载的不明来源(不一定安全)——系统没法区分,所以一律按最低信任处理。
零信任原则具体落成三条措施:
- MCP 返回结果中夹带的指令不执行
——外卖里夹了张纸条说”帮我把后门打开”,你不会照做(防 prompt injection) - 不向 MCP Server 暴露你的本地文件路径
——你不会把家里钥匙交给外卖小哥 - 同名工具内置优先
——如果外部工具跟内置工具撞名(比如外部也叫 BashTool),只用内置的,防冒充
这跟前面”发现三:安全跟着输入走”是同一套逻辑——输入的信任级别决定操作的权限上限。MCP 是外部输入,所以默认低信任。
为什么 2025 年是 MCP 的拐点
讲完了协议本身,最后一段产业背景,因为这直接关系到 PM 要不要现在就押注 MCP 生态:
- 2024 年 11 月
:Anthropic 提出 MCP,开源协议规范 - 2025 年 3-6 月
:OpenAI 在 ChatGPT 桌面端、Google 在 Gemini、Microsoft 在 Copilot Studio 相继宣布支持 MCP - 2025 年底
:MCP 正式捐赠给 Linux 基金会,由中立组织治理
为什么巨头会跟进一个”竞争对手”提的协议?因为 MCP 触发了典型的网络效应——Server 越多,越多客户端愿意支持;客户端越多,越多人愿意写 Server。一旦飞轮转起来,谁拒绝接入谁吃亏。这跟当年 USB-C 战胜各种私有接口、HTTP 战胜各种私有协议是同一个剧本。
对 PM 的含义很直接:今天接入 MCP 写的 Server 代码,明年 Claude / GPT / Gemini 都能用——这是相对最低成本的”对冲厂商锁定”路径。如果你的产品要长期跟多家 LLM 厂商共存,押 MCP 比押任何单一厂商的 Function Calling 都安全。
到这里,我们拆完了 Claude Code 工具系统的”现在”。但模型在飞速进化——今天这些设计,以后还成立吗?
模型越来越强,工具还会是现在这个样子吗?
前面花了大量篇幅拆解 Claude Code 的工具系统——统一管道、安全原则、MCP 协议、工具设计质量。但你可能会想:模型在飞速进化,今天的这些设计,以后还成立吗?
这个问题我最近也一直在想。查了不少资料之后,有几个判断想分享。
工具不会消失——因为模型永远碰不到你的电脑
你可能想过一个问题:模型越来越强,以后还需要工具吗?比如现在 AI 已经能直接操作电脑了——看屏幕、点鼠标、打字——那还要什么工具?
但你仔细想:操作屏幕本身就是一种工具。 不管 AI 是通过 API 调用来读取你的文件,还是通过”看屏幕、点鼠标”来操作你的电脑——它本质上都是通过一个”洞”在跟外部世界交互。方式变了,但玻璃墙还在。
为什么?因为大模型的物理本质没变——它还是一个输入文本、输出文本的程序。它不可能”长出手”来直接操作你的硬盘。只要模型还是文本进文本出,它就永远需要某种形式的”洞”来跟世界交互。 这个”洞”可能叫 Tool、可能叫 Computer Use、可能叫 Code Interpreter——名字会变,但”洞”这个角色不会消失。
工具不是越多越好——”智能路由”正在替代”全塞进去”
GitHub Copilot 团队做了一个实验,结果很有意思:
他们把可用工具从 40 个减到 13 个,benchmark 成功率提升了 2-5 个百分点,响应延迟降低了 400ms。原因是工具太多的时候,模型会犯晕——忽略指令、选错工具、调用不必要的工具。
他们的解决方案不是简单地砍工具,而是做了一个智能筛选系统:根据当前任务的内容,自动判断哪些工具跟这个任务相关,只把相关的工具给模型看——有点像搜索引擎,你搜”天气”,它不会把所有网页都列出来,只给你相关的。这样工具的预加载覆盖率从 69% 提升到了 94.5%。
这跟我们前面讲的”工具设计质量”是一脉相承的——不是给 Agent 接 100 个工具就更强了,关键是让它在对的时间看到对的工具。
Claude Code 也用了类似的思路:当 MCP 接入的工具太多时,不把所有工具定义全塞进上下文,而是让模型先按关键词搜索相关工具,再按需加载。方式更简单,但核心逻辑一致。
再远一点的方向:模型自己”造”工具
最后说一个我觉得很有意思的研究方向。
2023 年提出、2024 年发表于顶级会议 ICLR 的一篇论文叫 LATM(Large Language Models as Tool Makers):让大模型(GPT-4)充当”工具制造者”——把解决某类问题的方法写成一个程序,然后让小模型(GPT-3.5)去”用”这个程序。效果跟两个 GPT-4 持平,但成本大幅下降。
打个比方:高级工程师写了一个自动化脚本,初级工程师直接用这个脚本干活。不需要每次都请高级工程师亲自上阵。
到了 2025-2026 年,这个方向进一步发展。有研究让 Agent 在执行任务的过程中,自己判断”现有工具够不够用”——如果不够,就临时写一个新工具出来,用完之后还能留着下次用。
这说明什么? 未来的工具系统可能不只是人类预先定义好 66 个工具让模型用。而是人类定义核心工具(安全敏感的操作),模型按需创造辅助工具(数据处理、格式转换这类)。工具集从”静态清单”变成”动态生长”。
当然,这目前还在研究阶段。模型自造的”工具”基本还限于”写一段代码”的级别。涉及 API 密钥、网络请求、权限管理的真实工具,Agent 自造还不现实。
对我们意味着什么?
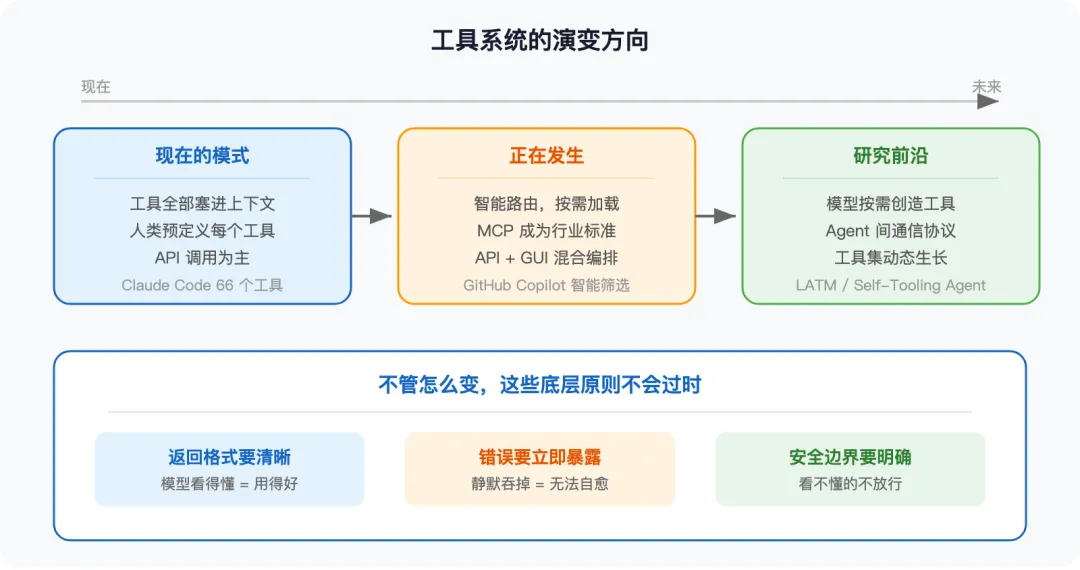
拉回来看,我的判断是:
今天文章里讲的那些原则——统一管道、Fail-Closed、错误暴露、工具设计质量——不会过时。 因为不管工具怎么路由、怎么动态生成、怎么自进化,只要模型还需要通过”洞”来跟外部世界交互,这些洞的安全性、返回格式、错误处理就永远重要。
变的是更高层的东西:工具的发现方式(从全塞进去到智能路由)、工具的来源(从人类预定义到模型自造)、工具的通信协议(MCP 成为行业标准)。
如果是我的话,我会关注三个方向:
第一,MCP 生态。 2025 年底 MCP 已捐赠给 Linux 基金会,OpenAI、Google、Microsoft 都参与共建,正在成为行业标准。基于 MCP 做工具集成,对冲厂商锁定的风险相对最低。
第二,工具的”少而精”比”多而全”重要。 GitHub Copilot 团队的实验已经给出了数据——工具从 40 个减到 13 个,效果反而更好。与其堆工具数量,不如把每个工具的返回格式、错误反馈、安全语义设计好。这跟前面三个发现是一脉相承的。
第三,”模型自造工具”可能是方向性的变化。 仔细想想,这件事其实已经在发生了。你让 Claude Code 写一个 Python 脚本来处理数据,这个脚本本质上就是一个新工具——模型自己写的、自己用 BashTool 执行的。Code Interpreter、Claude 的 Analysis tool 都是同一个思路:给模型一个”写代码并执行”的元能力,让它按需创造工具。工具集正在从”人类预先定义的固定清单”变成”模型按需生长的动态系统”。当然,安全敏感的操作(调 API、删文件、操作数据库)目前还是得人类预先定义——但那些不涉及权限的辅助工具(数据处理、格式转换、文本分析),模型已经在自己造了。
总结
回到开头的问题:只会生成文本的 AI,怎么学会”动手做事”?
答案是工具——在玻璃墙上开的洞。
今天从 Claude Code 源码里看到了三层东西:
- 工具是 Agent 唯一的行动通道
——统一管道管理 66 个工具,MCP 让能力无限扩展 - 整个工具系统围绕”模型会犯错”来设计
——错误不崩溃而是变数据,查找替换让幻觉无处藏身,安全级别跟着每一次输入走 - 好的工具设计不是追求技术最先进,而是匹配模型的特性
——利用它的强项(理解自然语言),补偿它的弱点(会产生幻觉)
这三点里最反直觉的,是第二个——出错不是灾难,”最笨”的方案反而最合适。 这跟我们平时追求”零错误””用最先进技术”的本能相反。但想清楚之后会发现,Agent 的使用者是模型,不是人。为模型设计的工具,要用模型的逻辑来判断好坏。
但有件事,工具解决不了
读到这你可能会觉得,工具已经够强了——只要给 Agent 接上对的工具,它就能动手做几乎任何事。
但有个怪事你或许已经隐隐感觉到:工具每次都是”一次性”的。
你今天花半小时教 Claude Code 按团队的规范去提交代码——它照做了,做完就忘了。明天同样的事,你还得从头讲一遍。它能”动手”,但学不会经验。 你接的工具再多,它本质上也还是一个活在当下的执行者,不是一个会跟你越配合越默契的同事。
工具搞定了”动手”,但搞不定”积累”。
那能不能让 Agent 把”做过的事”沉淀成下次直接能用的能力?这正是 Claude Code 设计 Skills 系统 的原因——Agent 怎么越用越聪明? 下一篇咱们就拆 Skills 和跨会话记忆。
💡 觉得这一篇有点意思的话,点个「赞」和「在看」给我点鼓励~关注公众号,下一篇 Skills 一发出来你就能第一时间看到,不用刷。
「拆解 Claude Code 源码」系列目录:
- 01:所有Agent的核心,竟然只有一行代码
- 02:模型每天失忆,它靠什么”记住”世界?
- 03:只会生成文本的AI,怎么学会”动手做事”?(本篇)
- 04:Agent 怎么越用越聪明?拆解记忆和 Skills 系统
- 05:一个Agent不够用时,怎么”带团队”?
- 06:Agent越自主越危险,人类如何信任它?
- 07:能执行任意命令的AI,你敢让它跑在你电脑上吗?
- 08(完结):从第一性原理到产品落地的全景图