夜雨聆风
夜雨聆风





手把手教你用AI Agent做数据治理:清洗、标注、血缘追踪,全流程自动化(第04篇)



01
02
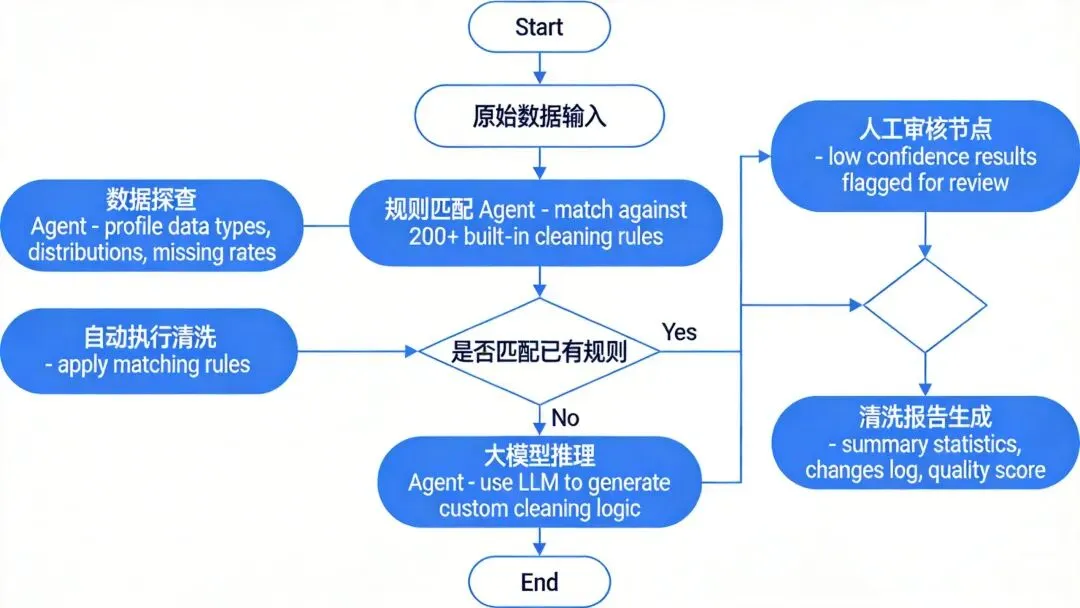
-
数据类型分布统计
-
空值率和缺失模式分析
-
唯一值枚举和频率分布
-
数值型字段的统计特征(均值、标准差、分位数)
-
字段间的相关性分析
-
时间序列的趋势和异常点检测
-
格式标准化(日期格式、手机号格式、身份证号格式等)
-
空值处理策略(删除、填充均值/中位数、插值、使用默认值)
-
重复数据处理(精确去重、模糊去重)
-
异常值处理(Z-score检测、IQR检测、业务规则约束)
-
编码统一(繁简转换、全半角转换、大小写标准化)
-
查询元数据管理系统,获取字段的业务注释 -
分析该字段与其他字段的关联模式 -
结合数据字典和历史清洗记录进行推理 -
如果仍然不确定,标记为”待人工确认”
03

-
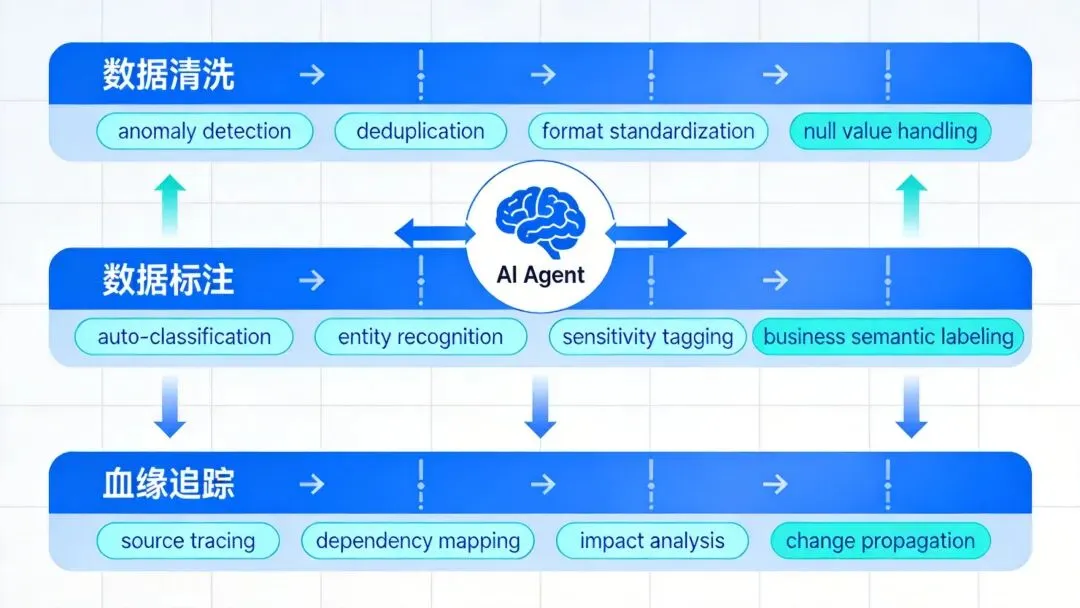
自动分类标注基于数据内容和元数据信息,AI Agent自动对数据资产进行分类。比如,自动识别某个表属于”客户域””交易域”还是”产品域”,自动判断某个字段是”敏感数据””个人隐私数据”还是”一般业务数据”。 -
实体识别与语义标注对于文本类数据,AI Agent利用NLP能力自动识别其中的实体信息。比如从客户反馈文本中自动提取产品名称、问题描述、情绪倾向等结构化标签。 -
敏感数据智能识别这是数据安全治理中的关键环节。AI Agent能自动扫描数据资产,识别出包含个人信息、财务数据、商业秘密等敏感内容的字段和表,并自动打上相应的安全标签。与传统的正则匹配方式不同,AI Agent能理解语义上下文,有效降低误报率。比如,它能区分”张三是VIP客户”中的”张三”是真实姓名,而”我像一个张三一样被忽略”中的”张三”只是泛指。 -
业务语义标注
04
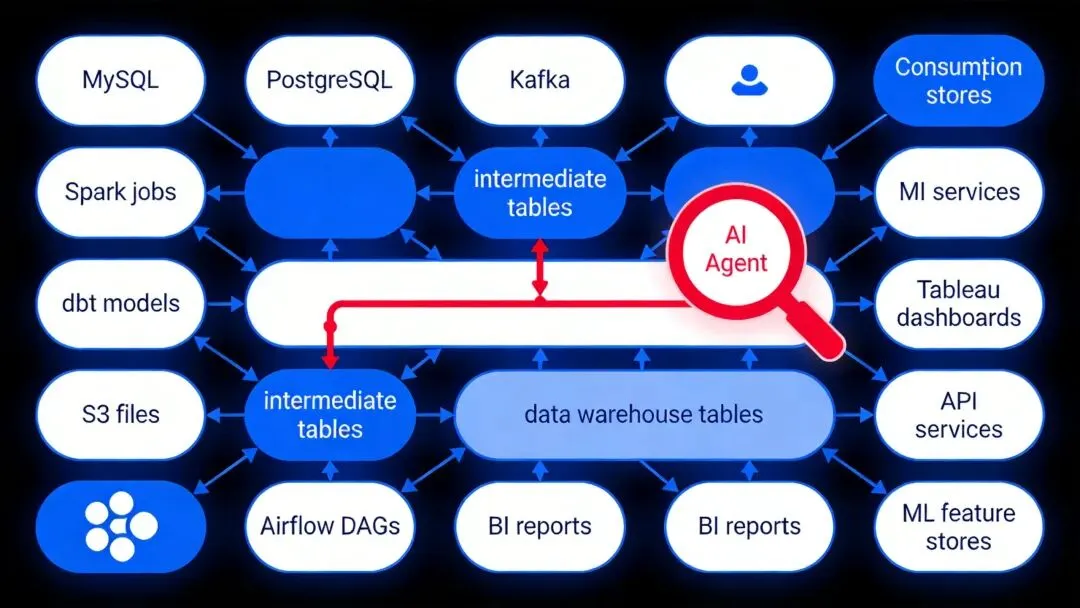
-
方式一:SQL解析
-
方式二:日志分析
-
方式三:大模型推理
-
影响分析 :当某张源表发生变更时,自动计算所有下游影响范围
-
根因定位 :当某张报表数据异常时,自动追溯上游可能的故障节点
-
合规审计 :自动生成数据的完整流转路径,满足监管审计要求
-
废弃评估 :识别长期无下游依赖的数据资产,为数据清理提供依据
05
-
建议一:先做好数据盘点在启动AI Agent之前,先花1-2周时间做一次全面的数据资产盘点。你至少需要知道:企业有多少数据源、多少张表、核心业务表有哪些、数据量级多大。这些信息是AI Agent配置的基础。 -
建议二:从单场景突破不要一上来就三个环节同时做。建议从”数据清洗”这个最通用、最刚需的场景切入,跑通之后再叠加标注和血缘能力。 -
建议三:保留人工审核环节AI Agent的自动化能力很强,但不要把它变成完全的黑箱。特别是在数据标注和质量规则确认等环节,保留人工审核机制,既能保证质量,又能帮助团队逐步建立对AI Agent的信任。 -
建议四:建立效果度量体系
06