 夜雨聆风
夜雨聆风





从文档块到知识网络:一次图谱增强 RAG 的工程探索
开篇摘要
做企业 RAG,最开始大家通常都很兴奋:文档传上去,向量库建起来,大模型一接,似乎就能问了。
但跑一段时间你会发现,一个很现实的问题冒出来了:
用户问的不是“哪段话提到了某个词”,而是“这些人、系统、流程、风险之间到底是什么关系”。
比如:
-
“这个客户涉及哪些项目风险?” -
“订单中心如果升级,会影响哪些下游系统?” -
“A 政策和 B 流程冲突的地方,出现在哪些文档里?”
这类问题只靠向量检索会有点吃力。向量检索像是在一堆资料里找“相似段落”,知识图谱则是在资料之间铺一张“关系地图”。
这篇文章就结合 SDH-RAG 项目里的图谱模块,聊聊:为什么企业 RAG 需要知识图谱、项目里现在怎么设计、后续怎么把它接进问答链路。
一、先把话说白:RAG 找内容,图谱找关系
传统 RAG 的工作方式,大概是这样:
-
用户提问。 -
系统把问题拿去检索。 -
找到几段相似文档。 -
把这些片段塞给大模型。 -
大模型组织语言回答。
这套流程处理“制度里有没有这句话”“接口字段怎么解释”“报销规则是什么”很舒服。
但企业知识里有很多问题,不是单点事实,而是关系链。
举个例子:
“华东二期项目最近有哪些延期风险,分别影响哪些客户交付?”
这个问题里至少有几类对象:
-
项目:华东二期 -
风险:延期、资源不足、接口联调失败 -
客户:某个交付对象 -
时间:最近、某个里程碑 -
责任人:项目经理、研发负责人、实施同学
如果只靠向量检索,系统可能召回几段“项目周报”“风险记录”“客户沟通纪要”。这些片段当然有用,但关系要靠模型临时拼。
而图谱的思路是:在入库或构建阶段,就先把这些对象和关系抽出来。

有了这张关系网,系统就不只是“找到了几段文字”,而是能沿着关系继续追:
华东二期 -> 关联风险 -> 影响系统 -> 关联客户 -> 来源文档
这就是知识图谱增强 RAG 的核心价值:让知识从“散落的片段”,变成“能顺着线索查下去的网络”。
二、SDH-RAG 里图谱模块长什么样?
项目里图谱相关代码主要集中在后端的 graph 包和 GraphBuildServiceImpl 里。
当前设计里,有四类核心节点:
-
DocumentNode:文档节点,记录标题、文件类型、分类、用户等信息。 -
EntityNode:实体节点,比如客户、系统、产品、流程、风险。 -
ConceptNode:概念节点,比如“权限控制”“召回策略”“审批流程”。 -
KeywordNode:关键词节点,用来承接高频词、关键术语、业务词。
构建过程可以理解成一条小流水线:
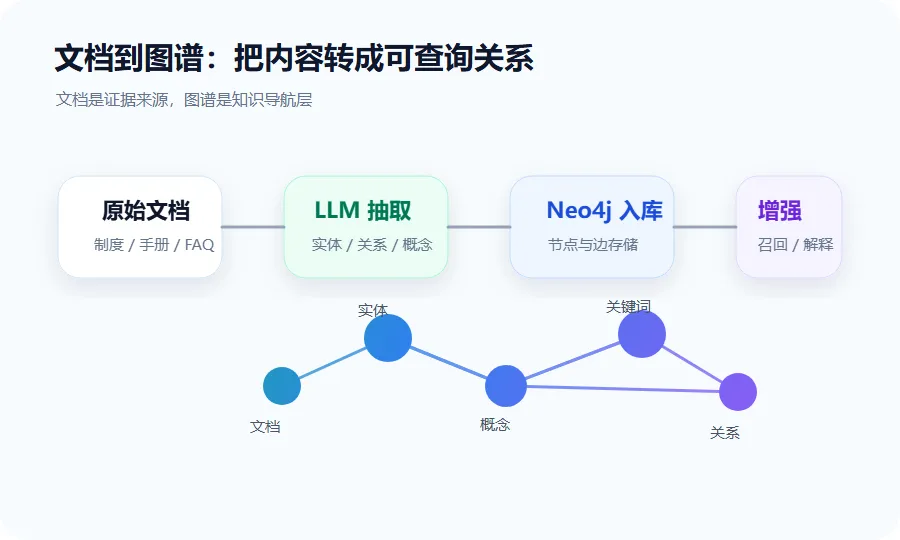
项目里的主流程摘出来,大概是这样:
public GraphBuildResponse buildFromDocument(Long documentId) {KnowledgeDocument document = knowledgeService.getDocumentById(documentId);if (document == null || document.getContent().isBlank()) {return GraphBuildResponse.fail(documentId, "文档为空或不存在"); } deleteByDocument(documentId);EntityExtractionResult result = entityExtractor.extract(document.getContent(), documentId);DocumentNode documentNode = createDocumentNode(document); Map<String, EntityNode> entityMap = createEntityNodes(result.getEntities(), documentId); Map<String, ConceptNode> conceptMap = createConceptNodes(result.getConcepts()); Map<String, KeywordNode> keywordMap = createKeywordNodes(result.getKeywords(), documentId); documentNode.setEntities(new HashSet<>(entityMap.values())); documentNode.setConcepts(new HashSet<>(conceptMap.values())); documentNode.setKeywords(new HashSet<>(keywordMap.values())); documentNodeRepository.save(documentNode); createEntityRelations(result.getRelations(), entityMap);return GraphBuildResponse.success(documentId, entityMap.size(), result.getRelations().size(), conceptMap.size(), keywordMap.size());}这段代码做的事情很朴素:
先拿文档,再抽实体,然后建节点、连关系,最后把结果写到 Neo4j。
朴素是好事。图谱系统最怕一开始就做得很玄,最后谁也说不清哪条边从哪来。企业项目里,第一版最好就是让它可理解、可排查、可重建。
三、实体抽取:别让模型自由发挥
图谱质量的上限,首先取决于抽取质量。
这里有个常见误区:把文档丢给模型,然后说一句“帮我抽取实体和关系”,就期待它吐出稳定、干净、能入库的数据。
结果往往是:
-
今天叫 SYSTEM,明天叫APP -
今天关系叫 DEPENDS_ON,明天叫依赖 -
有时返回 JSON,有时前面加一段解释 -
同一个实体一会儿全称,一会儿简称
这对图谱来说很要命。因为图谱不是聊天记录,它是要被查询的。
所以抽取 Prompt 不能太随意,至少要明确三件事:
-
允许哪些实体类型。 -
允许哪些关系类型。 -
必须返回什么 JSON 结构。
可以把抽取 Schema 设计成这样:
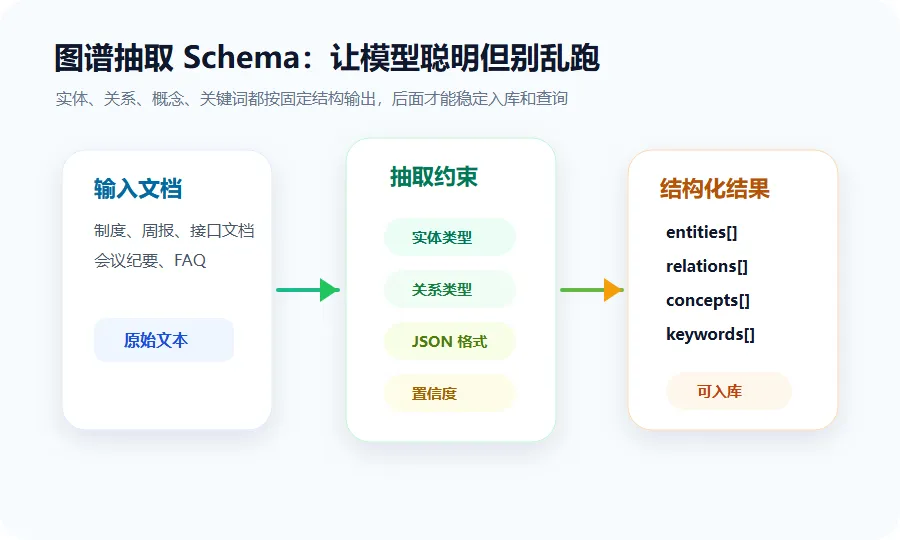
{"entities": [{"name": "订单中心","entityType": "SYSTEM","description": "负责订单创建、状态流转和履约协同","confidence": 0.92}],"relations": [{"sourceName": "订单中心","sourceType": "SYSTEM","targetName": "库存服务","targetType": "SYSTEM","relationType": "DEPENDS_ON","weight": 0.86}],"concepts": [{"name": "超时补偿","description": "请求失败或超时后的补偿处理机制","category": "稳定性"}],"keywords": [{"keyword": "订单超时","tfidf": 0.78}]}项目里 LLMEntityExtractor 已经预留了解析逻辑,会从模型输出里截取 JSON,再分别解析 entities、relations、concepts 和 keywords。
核心思路类似这样:
String jsonStr = response;int start = response.indexOf('{');int end = response.lastIndexOf('}');if (start >= 0 && end > start) { jsonStr = response.substring(start, end + 1);}JSONObject json = JSON.parseObject(jsonStr);JSONArray entitiesArray = json.getJSONArray("entities");JSONArray relationsArray = json.getJSONArray("relations");JSONArray conceptsArray = json.getJSONArray("concepts");JSONArray keywordsArray = json.getJSONArray("keywords");这一步看起来只是“解析 JSON”,但背后其实是图谱工程里很重要的一层防抖。
大模型可以聪明,但入库数据要规矩。聪明负责发现关系,规矩负责让系统长期可维护。
四、实体类型怎么定?先贴业务,别追求大而全
很多知识图谱教程里会从 PERSON、ORG、LOCATION 讲起。
这没错,但放到企业 RAG 里还不够。
企业内部更常见的是这些类型:
|
|
|
|
|---|---|---|
SYSTEM |
|
|
PRODUCT |
|
|
CUSTOMER |
|
|
PROCESS |
|
|
RISK |
|
|
POLICY |
|
|
API |
/api/chat/ask |
|
DATABASE |
|
|
关系类型也一样,先不要铺太满。
第一版可以从这几类开始:
-
RELATED_TO:泛关联,兜底用。 -
DEPENDS_ON:依赖关系,比如系统依赖服务。 -
AFFECTS:影响关系,比如流程变更影响系统。 -
BELONGS_TO:归属关系,比如接口属于模块。 -
MENTIONED_IN:来源关系,比如实体出现在某文档。 -
RESPONSIBLE_FOR:责任关系,比如人员负责风险。
这里的经验是:
类型少一点没关系,但一定要稳定。
稳定以后,查询、统计、可视化、权限控制才都能接上。
五、图谱怎么增强 RAG?三种方式最实用
图谱和 RAG 结合,不一定要一步到位做复杂推理。实际落地时,可以从三种方式开始。
1. 图谱辅助召回
用户问:
“订单中心超时问题怎么处理?”
系统先识别出 订单中心 是一个 SYSTEM 实体,再去图谱里找它的邻居:
-
关联故障文档 -
依赖服务 -
处理流程 -
历史风险 -
责任团队
然后把这些实体关联的文档作为候选范围,再和向量检索、关键词检索一起融合。
可以写成这样的查询思路:
MATCH (center {name: "订单中心"})-[r*1..2]-(neighbor)RETURN center, r, neighborLIMIT 50;如果接到 Java 服务里,就会更像这样:
public GraphDataResponse getNeighbors(Long nodeId) { Map<String, Object> result = graphRepository.findNeighbors(nodeId);return parseGraphResult(result);}这类能力的好处是:用户只说了一个实体,系统也能把它背后的上下游知识带出来。
2. 图谱解释来源
RAG 最容易被问的一句话是:
“你为什么引用这些资料?”
传统 RAG 通常只能说:“因为这些片段相似度高。”
但图谱可以给出更像人话的解释:
这段文档被引用,是因为它提到了“订单中心”;“订单中心”又依赖“库存服务”;而用户问题里问的是“超时处理”,该文档里记录了这两个系统之间的超时补偿流程。
这对企业内部问答很有价值。
因为很多时候,用户不是完全不信 AI,而是不知道 AI 的证据链从哪来。
3. 图谱支持复杂问题拆解
比如用户问:
“A 客户当前项目风险、责任人和处理进度分别是什么?”
这个问题可以拆成几步:
-
A 客户关联哪些项目? -
这些项目有哪些风险? -
风险分别由谁负责? -
最新进度出现在哪些记录里?
图谱天然适合这种路径查询。
先走图谱找路径,再用 RAG 找证据片段,最后让模型组织回答。这样比直接把问题扔给向量检索稳定得多。
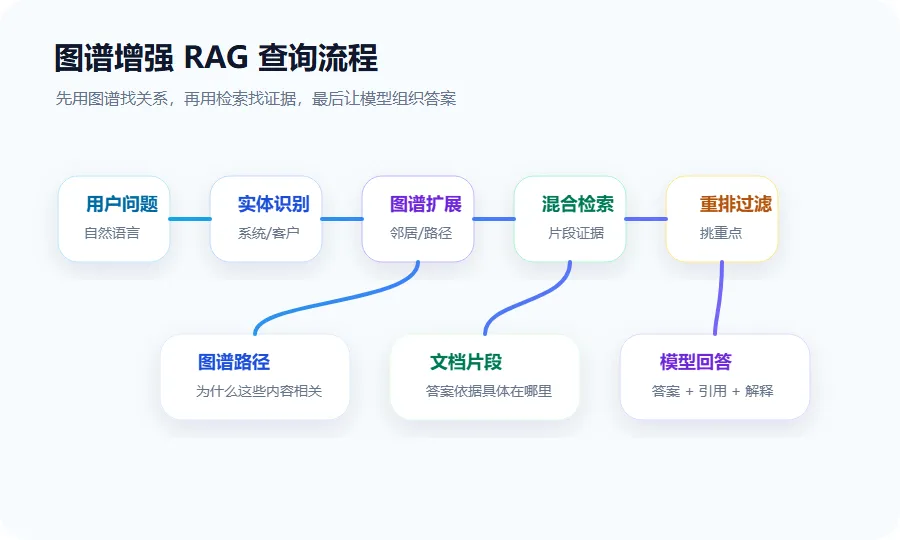
六、一个更完整的图谱增强查询流程
如果把它放进生产链路,我会建议这样设计:
-
用户输入问题。 -
识别问题中的实体、概念和意图。 -
如果识别到实体,就查询图谱邻居和路径。 -
根据图谱结果扩展关键词、候选文档和上下文线索。 -
执行向量检索、关键词检索和 Rerank。 -
把文档片段和图谱路径一起交给大模型。 -
回答时同时给出引用片段和关系解释。
Prompt 可以设计成这种结构:
你是企业知识库问答助手,请严格基于给定资料回答。用户问题:{question}图谱路径:1. 订单中心 --DEPENDS_ON--> 库存服务2. 订单中心 --MENTIONED_IN--> 《订单超时处理规范》3. 库存服务 --AFFECTS--> 履约状态同步检索片段:{retrieved_chunks}回答要求:1. 先给出直接答案。2. 再说明相关系统、流程、风险之间的关系。3. 最后列出引用来源。4. 如果资料不足,请明确说“不确定”。注意这里有一个小细节:图谱路径不要替代文档证据。
图谱告诉我们“为什么这些东西相关”,文档片段告诉我们“具体依据是什么”。两者合在一起,回答才既能讲清楚,又能站得住。
七、最容易踩的坑:图谱不是越大越好
知识图谱听起来很高级,但做坏也很容易。
常见问题有四个。
第一,实体没去重。
订单中心、订单服务、订单系统 可能说的是同一个东西。如果不做别名和标准化,图谱会被拆成好几个孤立节点。
第二,关系类型太自由。
今天抽出 影响,明天抽出 会影响,后天抽出 可能导致,看似丰富,实际查询时很难用。
第三,低置信度结果直接入库。
LLM 抽取一定会有不确定内容。低置信度实体和关系最好进入待审核池,而不是直接污染主图。
第四,只做展示,不接问答。
图谱页面很好看,但如果不能帮助召回、解释、追溯、运营,它就容易变成“看着很高级的装饰”。
可以给图谱加一条质量闭环:
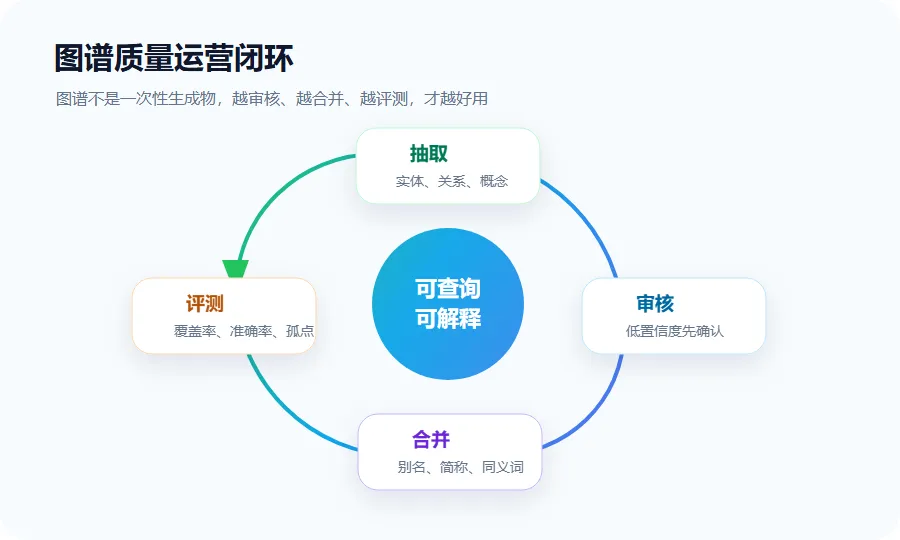
简单说就是:
抽取不是终点,审核、合并、评测、回流才是图谱真正变好用的过程。
八、后续怎么把 SDH-RAG 的图谱模块继续做深?
结合当前代码,我觉得可以按四步往前推进。
第一步:补齐抽取 Prompt 和 Schema
LLMEntityExtractor 里已经有解析框架,但抽取 Prompt 还需要正式补齐。
建议把实体类型、关系类型、JSON 格式、示例、置信度要求都写清楚。
第二步:增加实体标准化
可以先做一个简单版本:
private String normalizeEntityName(String name) {return name == null ? "" : name .trim() .replace("(", "(") .replace(")", ")") .toLowerCase();}再往后,可以加别名表、人工合并、同义词词典。
不要小看这一步。图谱碎不碎,很多时候就看实体合并做得怎么样。
第三步:把图谱接入检索链路
现在图谱构建和 RAG 检索还是相对独立的。后续可以在查询阶段增加一个图谱扩展器:
GraphContext graphContext = graphRetriever.expandByQuestion(question);List<Document> graphDocs = graphContext.getRelatedDocumentIds().stream() .flatMap(documentId -> searchByDocumentId(documentId).stream()) .toList();List<Document> merged = retrievalFusion.merge( vectorDocs, keywordDocs, graphDocs);不用一开始就做复杂推理。先把“图谱关联文档”作为第三路召回通道,价值就很明显。
第四步:让前端图谱页服务运营
前端已经有知识图谱页面,可以继续补:
-
实体详情:这个节点来自哪些文档。 -
关系路径:两个实体之间怎么连上。 -
热点实体:哪些系统、客户、风险最常出现。 -
孤立节点:哪些节点没有关系,可能抽取质量不高。 -
待审核关系:低置信度边进入人工确认。
做到这里,图谱就不只是技术能力,而是知识运营工具。
九、这件事真正的业务价值
图谱增强 RAG,听起来是技术升级,本质上解决的是企业知识里的一个老问题:
文档很多,但联系很少。
制度写在制度里,流程写在流程里,风险写在周报里,客户信息写在 CRM 里。单独看都有道理,合在一起就很难查。
图谱可以把这些散点连起来:
-
从一个客户,看到关联项目、风险和历史问题。 -
从一个系统,看到上下游依赖和故障影响面。 -
从一个流程,看到相关制度、角色和审批节点。 -
从一个答案,回溯到引用片段和关系路径。
这也是图谱和 RAG 最互补的地方:
RAG 擅长把证据讲清楚,图谱擅长把关系找出来。
一个负责“有据可查”,一个负责“有线可循”。
源码获取
这篇文章里提到的图谱构建、实体抽取、Neo4j 节点设计和 RAG 检索链路,都来自 SDH-RAG 项目的真实工程代码。
如果你也在做企业知识库、智能问答、RAG 平台,或者想看看“知识图谱 + RAG”在项目里到底怎么落地,可以继续关注这个系列。
点击关注,获取源码。
后面我会继续拆几块更实战的内容:
-
文档入库和切分策略怎么设计。 -
混合检索、Rerank、阈值过滤怎么调。 -
知识图谱如何接入问答链路。 -
前端知识图谱页面怎么做可视化和运营。 -
一个企业级 RAG 平台从 Demo 到生产,还需要补哪些工程能力。
如果你不想只停留在概念层,可以直接拿源码对着看,会比单纯读文章更有感觉。
结语
如果说向量库是企业知识的语义索引,那知识图谱就是企业知识的关系地图。
只有索引,系统能找到相似内容;有了地图,系统才能顺着对象、流程、系统、风险继续往下查。
企业 AI 问答要从“资料检索助手”走向“知识理解引擎”,图谱会是很关键的一步。
最后留一句适合收藏的话:
RAG 让知识能被问出来,知识图谱让知识能被连起来。
两者结合,企业知识才不只是躺在文档里,而是开始变成一张可以查询、可以解释、可以持续生长的网络。