把 OpenClaw 改造成会选模型的 Agent
把 OpenClaw 改造成会选模型的 Agent
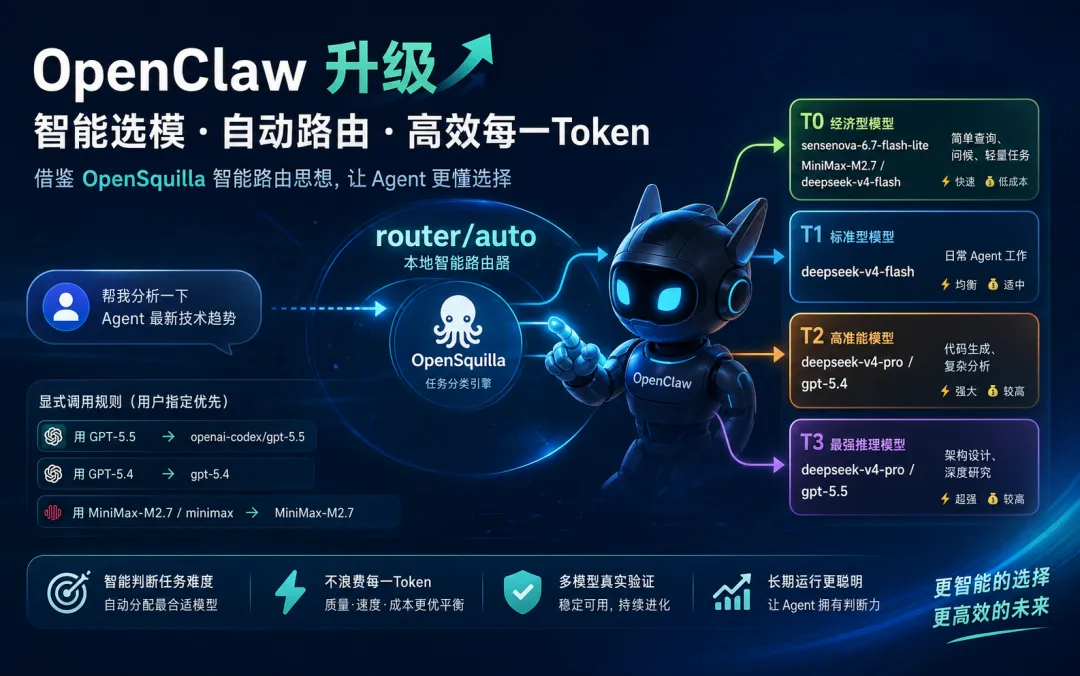
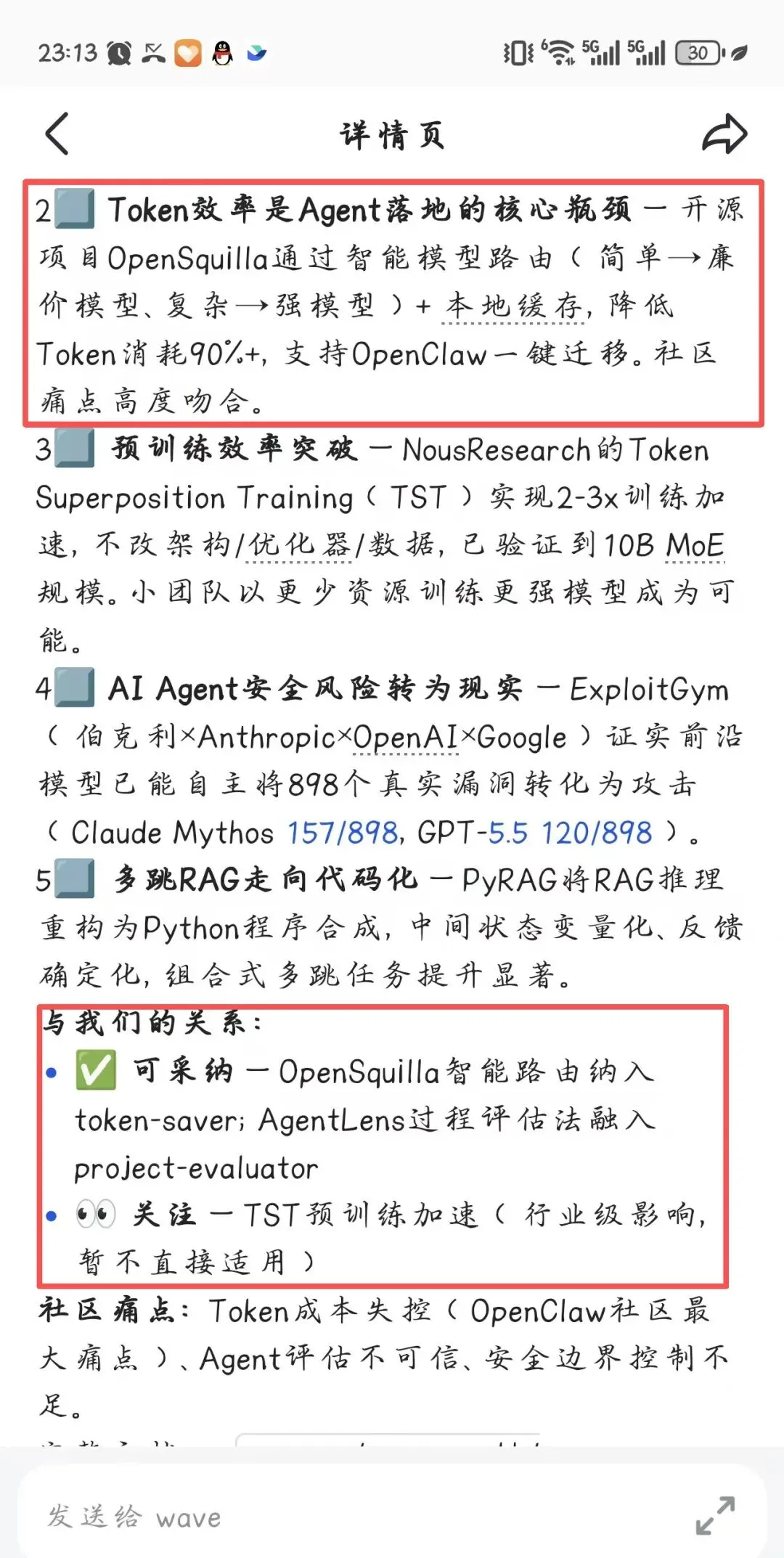
这次探索做的事很简单:让openclaw不再固定使用某一个模型,而是借鉴OpenSquilla 的智能路由思路,根据任务难度自动选择合适模型。简单问题交给便宜、快速的模型;复杂分析交给更强的模型;指定模型时则直接调用指定模型。意义也很直接:在不牺牲体验的前提下,减少浪费,让每一次 token 都花得更有判断。
事情的起点是我设置了一个定时任务,每天让wave去扫描agent相关资讯,每天列出15条最重要的内容,然后评估和我们当前系统的关系,有没有可以用的地方,目的是不断拓展它自己的能力,跟上最前沿的技术。它发现了叫OpenSquilla的开源项目,然后给出了评估:可以借鉴并完善openclaw的模型选择配置。于是,晚上回到家我就让它着手开始改造。
OpenSquilla 是一个面向 token 效率的开源 Agent Runtime,项目地址是 https://opensquilla.ai/,GitHub 仓库是https://github.com/opensquilla/opensquilla。它里面有一个关键思想:模型不应该靠人工拍脑袋选择,而应该由路由器判断任务复杂度。所谓路由器,可以理解成“模型调度员”。它先看用户输入,再判断这件事是简单查询、普通任务、复杂写作,还是深度推理,然后把任务分配给不同模型。
我们在 OpenClaw里做的是一次本地化改造:保留 OpenClaw原有的会话和网关能力,同时在中间加了一层 router-auto。用户仍然正常发消息,但请求会先进入本地路由器。路由器调用 OpenSquilla 的 SquillaRouter 分类能力,再结合我们写的规则和已知任务表,给任务分层。
|
Tier
|
典型模型
|
使用模型
|
适用场景
|
|
T0
|
经济型模型
|
|
简单查询、问候、
版本检查、
轻量任务
|
|
T1
|
标准型模型
|
|
日常 Agent 工作
|
|
T2
|
高性能模型
|
deepseek-v4-pro
|
代码生成、复杂分析
|
|
T3
|
最强推理模型
|
deepseek-v4-pro
|
架构设计、深度研究
|
另外还有显式调用规则:如果我输入“用 GPT-5.5”,就优先走openai-codex/gpt-5.5;输入“用 GPT-5.4”,就走 gpt-5.4;输入“用 MiniMax-M2.7”或“minimax”,就走 MiniMax-M2.7。这相当于给用户保留手动指定权。
真正麻烦的是MiniMax。它不是普通 OpenAI chat/completions 格式,而是 Anthropic Messages 兼容接口。早期我们把它交给 OpenClaw 网关转发,结果出现 500 和空响应。后来改成 proxy 直连 MiniMax Anthropic 接口,并把返回内容转换成 OpenAI 兼容格式,同时过滤掉 thinking 块,才让它稳定返回正文。
最后的结果是:router/auto已经在线,gpt-5.5、gpt-5.4、MiniMax-M2.7`都进入实际可调用池,并完成了真实请求验证。wave现在不只是“能调用多个模型”,而是开始具备“根据任务选择模型”的能力。这才是 Agent 系统进入长期运行后真正需要的能力:不是每次都用最贵的模型,也不是一味省钱,而是在质量、速度、成本之间自动做选择。
谢谢你看我的文章,如果觉得不错,随手点赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
 夜雨聆风
夜雨聆风