 夜雨聆风
夜雨聆风





Palantir官方文档—为什么需要 Ontology
在数字化浪潮席卷全球的今天,企业每天都在产生海量数据。然而,现实却是:数据越堆积越多,决策却越来越难。数据分散在数十甚至数百个异构系统中,各部门对同一业务概念的理解各不相同,AI 模型因缺乏业务上下文而频频“幻觉”。
Palantir 认为,要解这道题,不能靠堆叠更多的工具和报表,而要从根源上重构数据与业务之间的映射关系——这也正是 Ontology(本体) 诞生的初衷。
一、什么是 Ontology
1.1 术语溯源
“Ontology”一词源自哲学,意为对“存在”本身的研究与分析。在哲学中,Ontology 试图回答“世界上有什么”“它们如何关联”这些最根本的问题。Palantir 借鉴了这一思想,将企业视为一个独立的“存在领域”,将其中的业务实体、属性及其相互关系形式化为一个可计算、可推理的对象网络。
1.2 Palantir Ontology 的定义
在 Palantir 的语境下,Ontology是一个以决策为中心的模型(Decision-Centric Model) ——它不是为了描述数据本身而存在,而是为了描述企业中的决策而设计。它通过本体对象、属性、链接来统一描述业务实体及其关系,为整个系统提供标准化的“业务名词”和共同语言。例如,客户、飞机、订单等实体被赋予归属地、载重量、订单号等属性,并通过链接类型建立彼此之间的联系。
Ontology 集数据、逻辑、动作和安全于一体,构建出一个可扩展、动态、协同的基础设施,能够实时反映组织不断变化的条件和战略目标。
1.3 核心特征速览
|
|
|
|---|---|
| 决策中心 |
|
| 强语义 |
|
| 可行动化 |
|
| 动态演进 |
|
| 人机双用 |
|
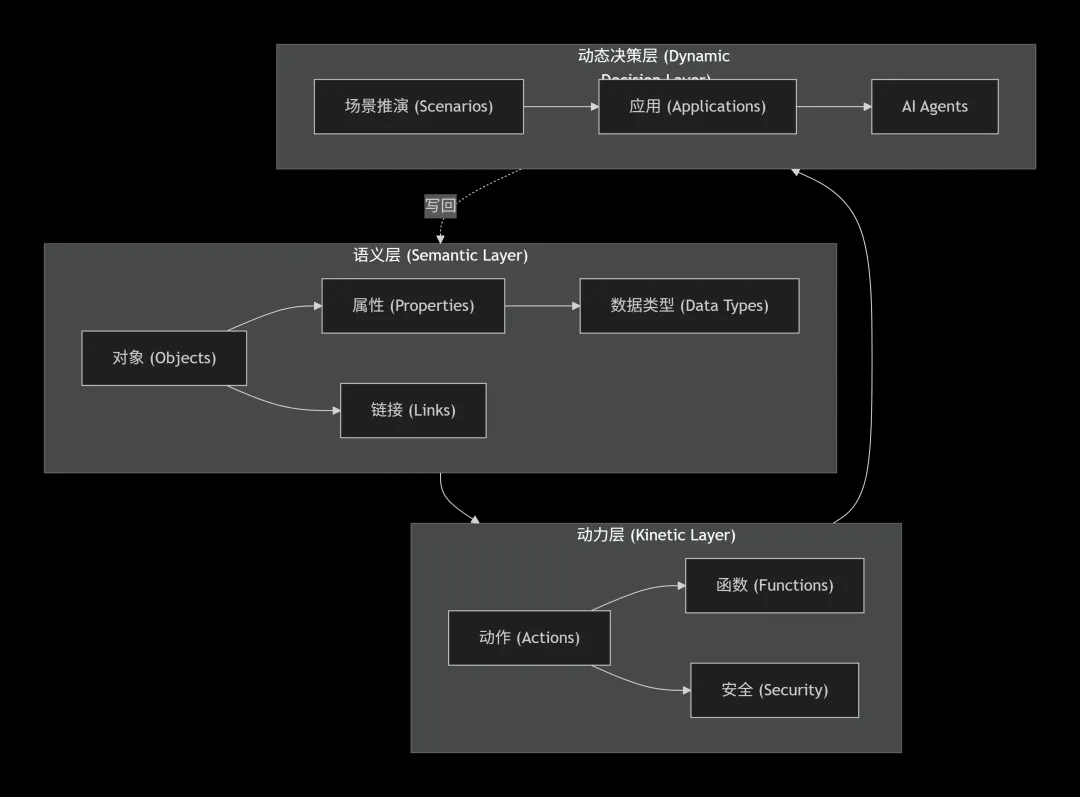
1.4 三层架构
在技术实现上,Palantir 通过三层架构将 Ontology 落地为可运行的业务系统:
二、Ontology 的四大核心支柱
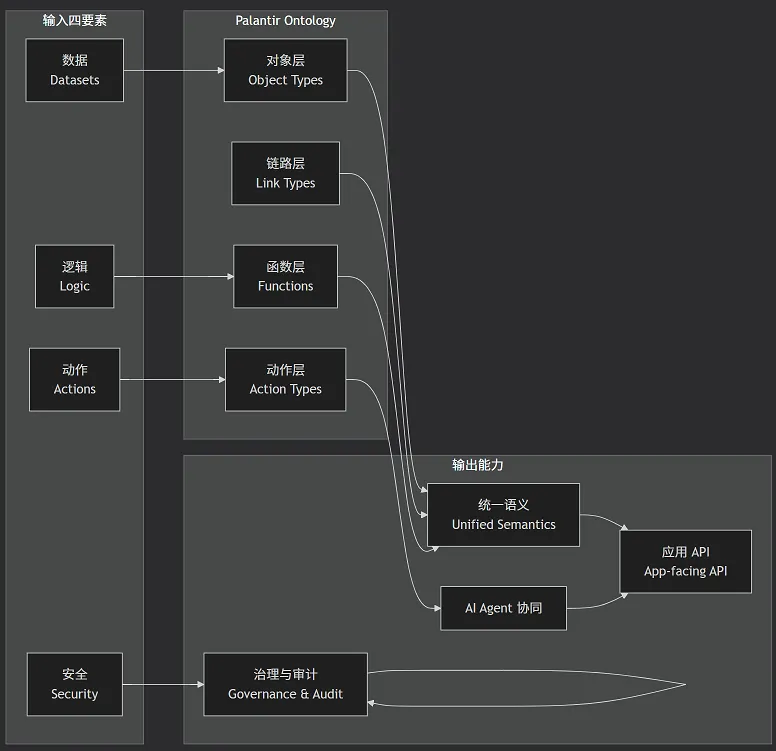
Palantir Ontology 将企业决策所需的四个核心要素——数据、逻辑、动作、安全——整合为一个统一模型。
2.1 数据:构建统一的业务实体视图
数据是 Ontology 的起点。企业中有海量的结构化数据(数据库表)、半结构化数据(日志、JSON)和非结构化数据(文档、图像),它们分散在数十个异构系统中,孤岛林立。Ontology 通过建立对象类型(Object Types)将这些杂乱无章的数据映射成一个统一的业务实体网络,使原本互不相通的“岛屿”被连接成一个可联结的整体。
2.2 逻辑:编织决策的规则网络
数据本身只是原材料,真正驱动决策的是背后的逻辑——计算、规则、流程和策略。Palantir 的 Ontology 允许将逻辑资产(Logic Assets)直接嵌入对象类型和链接类型中,并进行情境化关联。例如,你可以在 Ontology 中定义一个“高优先级客户”的逻辑规则,这个规则会自动作用于所有符合条件的客户对象,并在所有应用和代理中保持一致。
在 AIP(人工智能平台)中,AIP Logic 提供无代码环境,帮助用户轻松地将大语言模型与 Ontology 集成,让 LLM 能够基于可信的业务上下文进行推理,从根源上减少“幻觉”。
2.3 动作:注入“改变世界”的能力
如果说数据是 Ontology 的“骨架”,那么动作(Action)就是它的“肌肉”。传统的大数据平台通常是“只读”的——你只能查询和分析,无法改变什么。而 Palantir 的核心壁垒在于它是一个运营型平台(Operational Platform)。
Action Type 代表一组可以在 Ontology 中执行的变更和逻辑,它定义了用户可以一次性对对象、属性和链接执行的修改集合。更重要的是,这些动作可以写回到底层的事务性系统、边缘设备乃至定制化应用中,真正形成从数据到决策再到行动的业务闭环。
2.4 安全:全栈统管颗粒度权限
在强大的能力背后,安全是不可或缺的基石。Palantir 的 Ontology 体系构建了“经过实战检验的安全和审计系统”(Battle-tested security and audit systems),确保每一项活动——无论是人工操作还是机器行为——都可以被精确管理和审计,服务于客户最核心的任务。Ontology 可以基于对象(Object)、链路(Link)乃至动作(Action)设定细粒度的权限策略,并在数据、逻辑、动作和应用等全栈工件上落地动态化、体系化的变更与发布管理。
下图清晰地展现了 Ontology 如何通过“四合一”架构将分散的资源整合为统一的业务模型:
三、为什么要创建 Ontology:痛点与解决方案
要理解为什么需要 Ontology,首先要看清传统数据平台中普遍存在的问题。
3.1 传统模式的四大问题
|
|
|
|---|---|
| 语义不统一 |
cust_nm,业务人员无法直接理解 |
| 逻辑不一致 |
|
| 只读问题 |
|
| AI落地困难 |
|
3.2 Ontology 如何破局
|
|
|
|---|---|
|
|
|
| 逻辑不一致 |
|
|
|
|
|
|
|
3.3 Ontology 的传统知识图谱对比
为了更清晰地理解 Ontology 的独特定位,这里用表格对比其与传统知识图谱的区别:
|
|
|
|
|---|---|---|
| 核心目标 |
|
|
| 语义表达能力 |
|
极强
|
| 对外操作能力 |
|
读写兼备
|
| 是否能被 AI 理解 |
|
是
|
| 安全与治理 |
|
内置全生命周期
|
四、Ontology 的核心构建元素
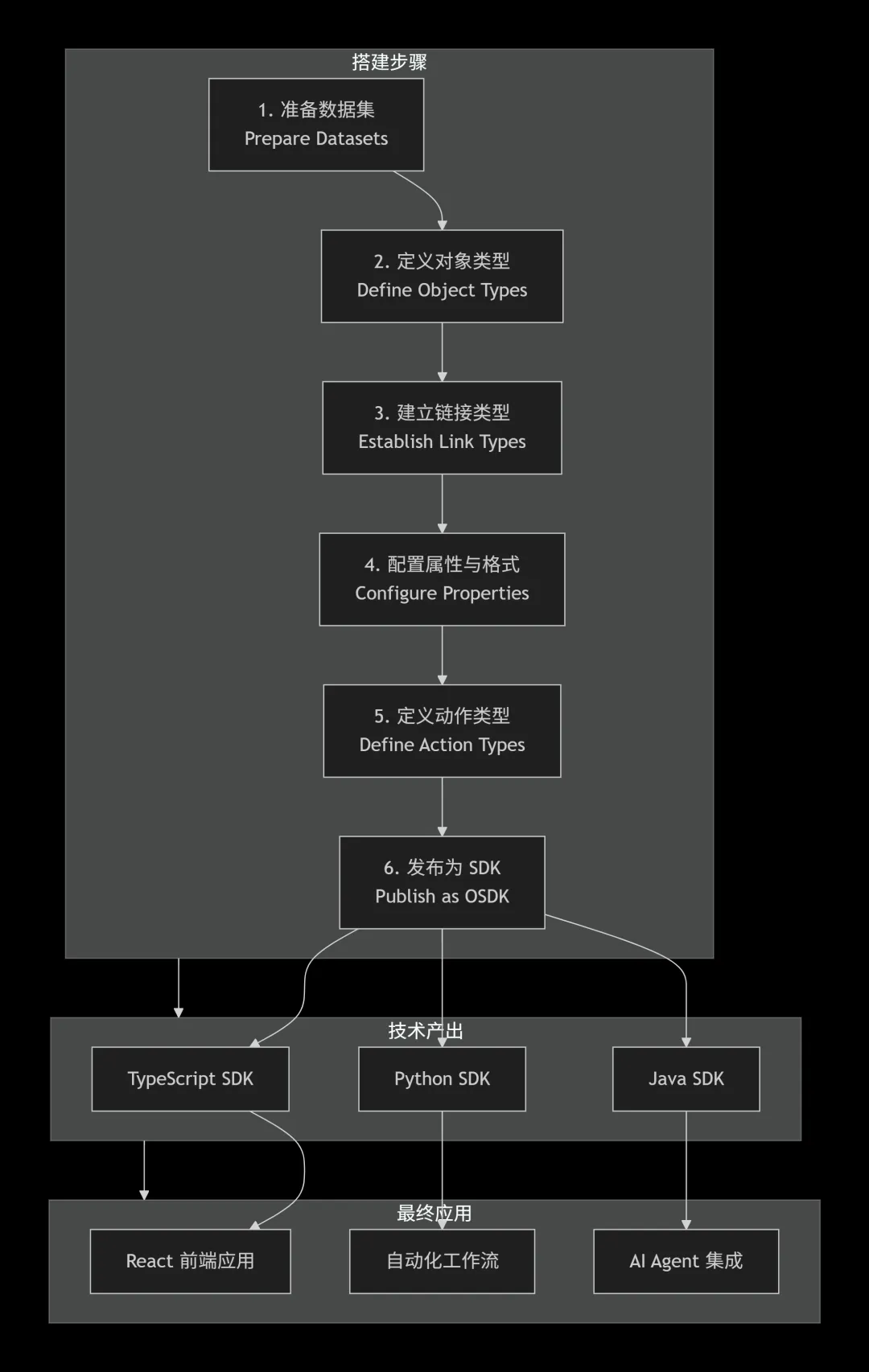
构建一个 Ontology 并非一蹴而就,而是通过 Palantir Foundry 平台,将一系列核心的建模元素有机组合而成。
4.1 四种核心构建元素
|
|
|
|
|---|---|---|
| Object Type(对象类型) |
|
|
| Link Type(链接类型) |
|
|
| Action Type(动作类型) |
|
|
| Function(函数) |
|
|
通过将现有数据源映射到 Ontology 中的 Objects、属性和链接,企业可以定义出完整的业务语义。
4.2 Ontology 搭建流程示意
以下是使用 Palantir Foundry 创建一个简单 Ontology 的典型流程:
五、Ontology 的业务价值
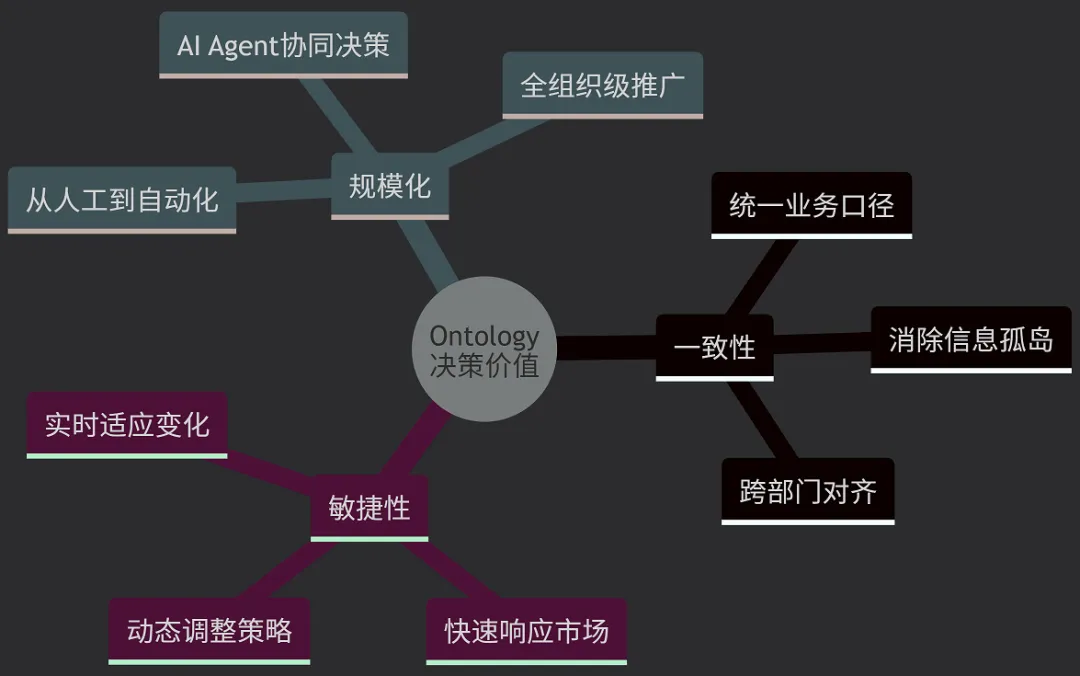
5.1 决策层面的价值
Ontology 的最终使命是支撑更好的决策。它让企业能够基于不断变化的内部和外部条件,做出尽可能好的、通常是实时的决策。具体体现在以下三个方面:
5.2 AI 层面的价值
在 AI 时代,Ontology 的价值愈发凸显。它让人和 AI 代理能够安全地推演各种“场景”(Scenarios),在统一的管控下自由尝试和决策,最终将可行性方案以安全、可控的方式写回真实的业务环境中。
通过 Ontology SDK,开发商可以生成与业务模型完全一致的 SDK(支持 Python、Java 和 TypeScript),直接在自己的开发环境中使用 Ontology 的力量。这就意味着,一个企业级的 AI 应用——从数据读取到逻辑推理,再到最终的行动执行——可以在 Ontology 的统一语义底座上快速搭建,而无需为每一个应用场景“从零建模”。
六、Ontology vs 知识图谱:澄清常见误解
很多人会将 Ontology 与知识图谱(Knowledge Graph)混为一谈。事实上,两者虽然都涉及“实体”和“关系”,但其设计哲学和应用范畴有着本质的区别。
6.1 核心区别对比
|
|
|
|
|---|---|---|
| 建模对象 |
|
|
| 核心组成 |
|
|
| 动态能力 |
|
活的
|
| 典型场景 |
|
|
Ontology 更类似于 Java 中的面向对象建模——你需要先定义清晰的类、接口、属性和方法,构建出一个严格的、可执行的结构框架,再去承载具体的业务数据。而知识图谱则更侧重于“从非结构化数据中抽取知识”,擅长发现隐性的关系网络。
6.2 可视化对比
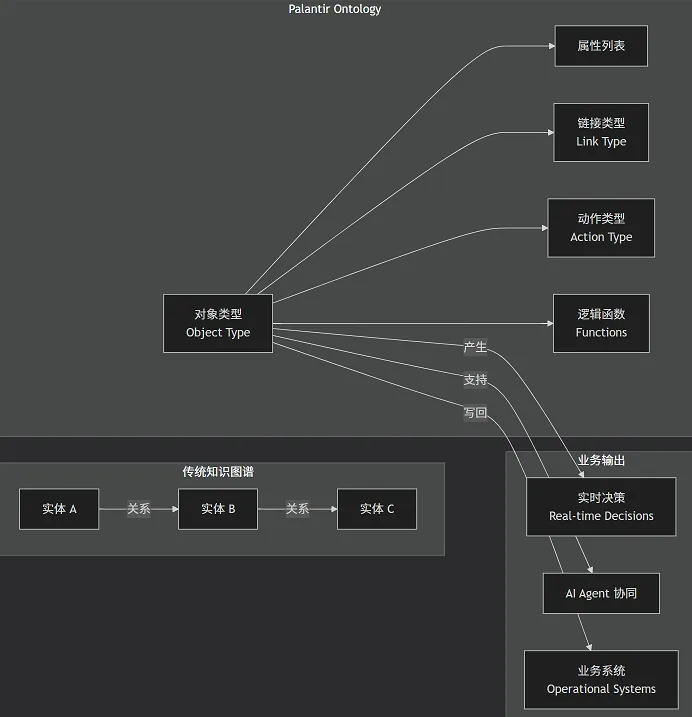
七、结语
创建 Ontology 的终极目的,并非仅仅为了管理数据。它要解决的是一个更根本的问题:如何让数字化系统真正理解企业的业务逻辑,并在此基础上,与人和 AI 一起做出实时、准确、可执行的决策,既如何让人与人、人与AI之间对齐语义。
对于一个现代企业而言,数据是“记录”,报表是“反映”,而 Ontology 则是“理解”与“行动”的交汇点。随着 Palantir AIP 的深化应用,Ontology 正在成为连接人类智慧与人工智能的“语义操作系统”。它让每一个人——无论是业务分析师、数据科学家、CTO、CEO还是AI Agent——都能用自己的语言相互无歧义的对话,从而让技术的进步真正转化为组织的竞争优势。
正如 Palantir 所定义的:“创建 Ontology,就是创建企业的数字孪生骨架。”有了这副骨架,一切数据、模型、逻辑和行动才能形成一个能动的躯体,企业才能真正从“数据驱动”走向“决策智能”。
Palantir Ontology的成功说明信息化建设要以整体论为主,还原论为辅,否则将会陷入迷途。
附:推荐资源
-
Palantir 官方文档:The Ontology System
-
Palantir 开发者社区:Ontology 专题讨论
-
Palantir 博客:Ontology 深度解析系列