 夜雨聆风
夜雨聆风





RAG系统痛点—“PDF解析”,这个今天已经帮你解决了!
你的RAG系统答不对题?问题可能是出在了第一步
做RAG的人,大概都会被同一件事折磨过——“PDF解析”。
你花了三天调试Prompt,又花两天换Embedding模型,检索召回率可就是上不去。最后一查,发现问题却根本不在模型那头。是喂进去的数据就是错的!
例如:一份双栏论文,解析出来左栏第一行接右栏第一行,两个毫不相关的句子被拼成了一段话。LLM拿着这坨东西去理解,能理解出个啥?
一张财报表格,解析完变成一堆散装文字,行列关系全没了。你问模型”Q3营收多少”,它只能瞎猜。
垃圾进,必然垃圾出。 这句话在RAG领域,杀伤力最大的环节不是生成而是解析。
1 被忽略的那一层
RAG的架构大家都清楚:文档解析 → 分块 → 向量化 → 检索 → 生成。
五个环节,行业讨论最多的是后面四个——什么分块策略、什么Embedding模型、什么Reranker、什么Prompt优化。唯独第一步,文档解析,被当成”理应如此”的基础设施。
但现实是,如果第一步就把文档结构搞丢了,后面做得再精致也是空中楼阁。
传统PDF解析工具的问题出在哪?
PDF这个格式,本质上是一套”打印指令”——它告诉渲染器在屏幕什么位置画什么字符,但它不存储任何语义结构。没有”段落”标签,没有”表格”标签,全靠坐标拼凑。
所以你用pypdf解析一份双栏论文,它会老老实实地从左到右逐行扫,把两栏内容搅成一锅粥。你用PyMuPDF提表格,它可能连表格边界都找不到。
过去两年,社区搞出了一批基于深度学习的方案——Unstructured、MinerU、Marker、Docling。效果确实好了不少,但新问题也来了:
要GPU。 Marker在H100上批处理也就25页/秒。没有GPU的团队直接出局。
要上云。 一些商业API按页收费,敏感文档传上去,合规部门第一个不答应。
不确定性。 模型推理有随机性,同一份PDF跑两次,结果可能不一样。在生产环境里,这是定时炸弹。

2 一个反常识的思路
OpenDataLoader PDF做了一件看起来”倒退”的事:不用深度学习模型做版面分析。
它走的是纯规则路线,核心是一套叫XY-Cut++的版面分割算法。说白了就是用坐标计算来判断哪些文字属于同一列、哪些构成表格、阅读顺序该怎么排。
听起来原始?但它解决了三个实打实的问题。
第一,快。 Apple M4笔记本上实测每页0.05秒,换算过来100+页/秒。Marker在H100上才25页/秒。一台普通笔记本吊打一张企业级显卡。
第二,确定性。 同一份PDF输入十次,十次输出一模一样。没有模型推理的随机性,测试和排查都有迹可循。
第三,零外传。 纯本地运行,不需要任何API调用。金融、医疗、法务场景,合规问题直接消失。
在200份真实文档的公开评测里,它的阅读顺序准确率达到0.91,综合评分在纯本地模式下排名前列。
而且它不是”要么快要么准”的二选一。对于复杂文档,它还提供了混合模式——用规则引擎打底,复杂表格和扫描件交给AI补刀。混合模式下综合准确率0.90,是目前开源方案里最高的。

3 RAG开发者真正需要什么
回到第一性原理想这个问题:做RAG的人,到底需要PDF解析器给出什么?
不是华丽的功能列表,是三样东西:
结构。 标题是标题,段落是段落,表格保持行列关系。分块的时候才能按语义边界切,而不是盲切500字。
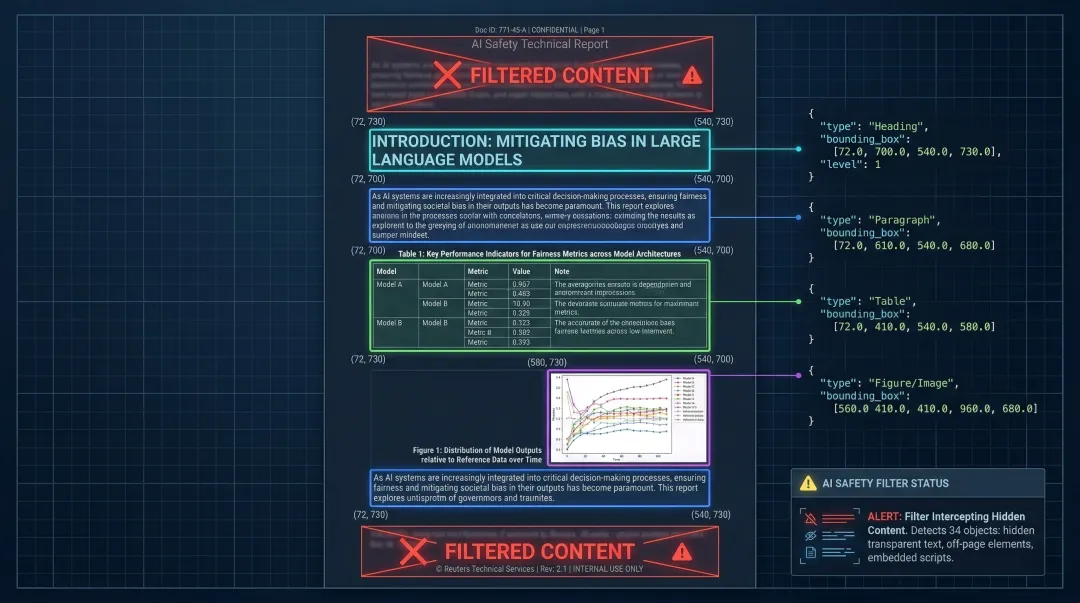
坐标。 每个元素的位置信息——左上角到右下角的精确坐标。有了这个,用户问”依据在哪”,你可以直接高亮原文的那一行那一段。这不是锦上添花,是产品体验的生死线。
干净。 页眉页脚、隐藏水印、透明文字,这些噪音不该出现在LLM的上下文窗口里。尤其是隐藏的Prompt注入攻击——有人会在PDF里埋不可见文字来劫持你的模型,这个威胁是真实存在的。
OpenDataLoader的JSON输出长这样:
{"type":"heading","page number":1,"bounding box":[72.0,700.0,540.0,730.0],"heading level":1,"content":"Introduction"}
每个元素都带语义类型、页码、精确坐标。拿到手直接喂LangChain的分块器,或者自己写按标题层级切分的逻辑,都行。
这才是为RAG而生的输出格式,不是把PDF转成一坨纯文本然后让你自己去猜哪里是标题哪里是表格。
4 三行代码跑起来
说了这么多,上手到底麻不麻烦?
pip install -U opendataloader-pdf
import opendataloader_pdfopendataloader_pdf.convert(input_path="document.pdf",output_dir="output/",format="markdown,json")
就这么多。Python、Node.js、Java、Docker四种方式随便选。
如果你的PDF有结构化标签(政府公文、法律文书越来越多带这个),加一行参数就能直接用原生语义结构:
opendataloader_pdf.convert(input_path="accessible.pdf",use_struct_tree=True)
LangChain用户更简单:
from langchain_opendataloader_pdf importOpenDataLoaderPDFLoaderloader =OpenDataLoaderPDFLoader(file_path=["report.pdf"],format="markdown")docs = loader.load()
无缝接入现有RAG管线,不需要推翻重来。
5 选对工具,少走弯路
最后放一张选型参考:
|
|
|
|
|---|---|---|
|
|
OpenDataLoader 本地模式 |
|
|
|
OpenDataLoader 混合模式 |
|
|
|
|
|
|
|
|
|
说到底,RAG系统的天花板不在模型有多聪明,而在喂给模型的数据有多干净。
大多数人优化RAG的方式是在后面四个环节里反复折腾,但真正的杠杆点,往往在最不起眼的第一步。
把PDF解析这一层做扎实了,后面的链路自然就顺了。不需要更贵的模型,不需要更复杂的策略,就是把数据搞对。
项目地址:https://github.com/opendataloader-project/opendataloader-pdf
MPL-2.0开源协议,放心用去吧。
全文完。