 夜雨聆风
夜雨聆风





我把 ClaudeCode 源码全部梳理了一遍,整理成了这篇文章.
大家好,我是 Sunday。
昨天 Claude Code 源码泄露的事大家应该都已经知道,源码公开十多个小时,已经有了 78k 的 star 和 77.1k 的 Fork,堪称历史上 star 增长最快的项目之一了
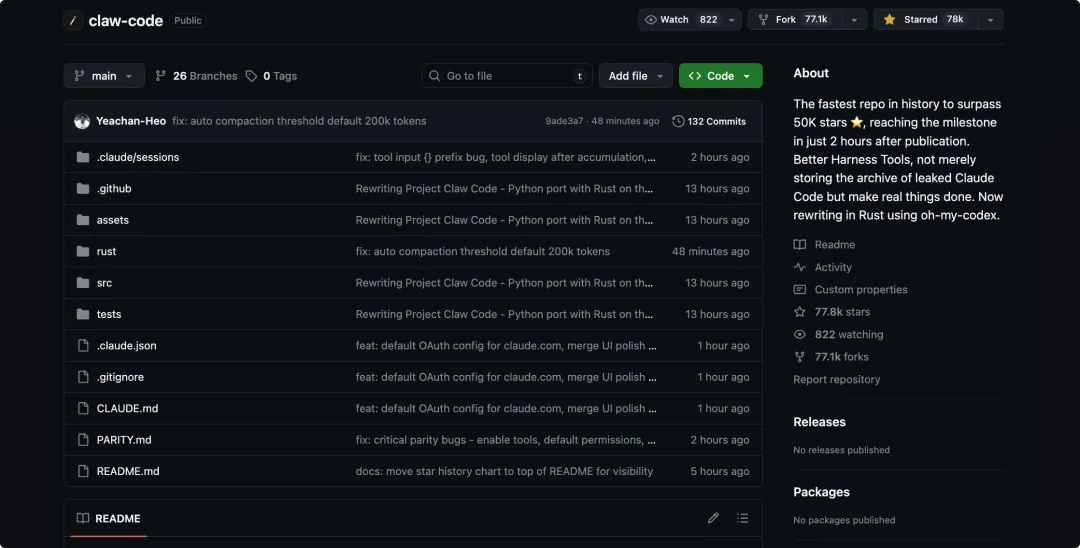
想要源码的同学,大家可以直接拿这个路径 https://github.com/instructkr/claw-code。不过先别着急,看完文章再走,今天这篇文章干货还挺多的!
PS:claw-code 昨天还叫 claude-code,之所以改名作者也在 README 中说明了原因
所以,这个仓库目前大家可以称他为 Rust 版移植仓库
我昨天花了好几个小时的时间,捋了一遍 Claude Code 的源码,包括:
-
Claude Code 真正复杂地方 -
扩展机制 -
上下文和记忆管理 -
几个隐藏功能
下面咱们就一个个来看
Claude Code 真正复杂地方
Anthropic 在官方文档里对 Claude Code 的描述是:
它不是一个单纯回答问题的工具,而是会围绕这一个特定的循环进行工作。这个循环包括:先收集上下文,再决定动作,再调用工具执行,再验证结果。
这个描述看起来普通,但它其实已经把 Claude Code 的核心说明白了:Claude Code 本质就是一个执行闭环逻辑的东西。
那么这次的代码暴露出来的目录其实也可以说明这一点:
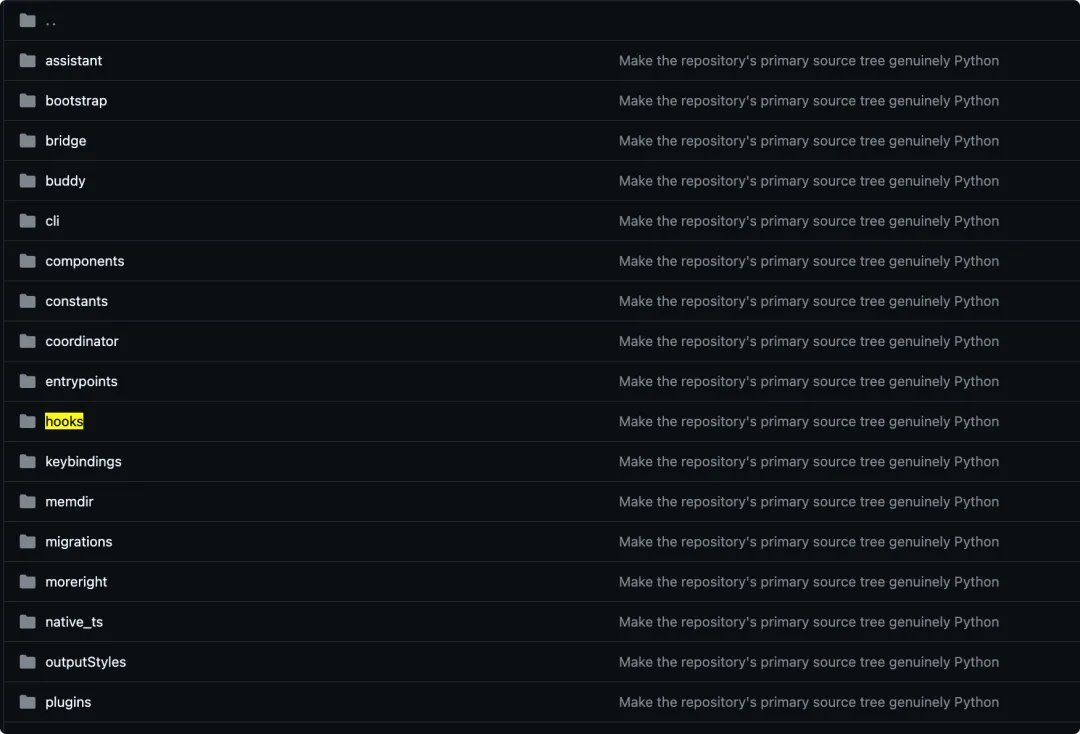
你会看到它不只是 cli、assistant、tools 这种基础目录,还出现了 hooks、skills、plugins,甚至还有 buddy(在这里可以理解为宠物伴侣。和最后的隐藏功能有关系)。
这说明它从一开始就不是“单轮对话 + 编辑文件”这么简单,而是在朝着一个长期运行、可扩展、可远程控制的 AI 工作台进行设计的。
更关键的是,Rust 版移植仓库里有一份很有价值的 PARITY.md

里面明确写了 TS 版缺失或尚未完全迁移的能力,包括插件体系、hooks 执行链、完整 CLI 命令面、skills registry、hook-aware orchestration、remote/structured transport,以及一大堆 service 层能力。

你会发现,Claude Code 真正复杂的地方,不在模型调用这里,而在多场景下的编排逻辑。
扩展机制
Claude Code 提供了四种扩展机制,分别是:skills、MCP、hooks、plugins。
这让我想起来前两天 训练营 同学去面试被问到的 mcp、skills、workflow 之间的区别,这个问题。
这些东西很多同学会搞混。
那么咱们就凑着这篇文章,把这几个概念讲一下。
首先,这四个公司本质上都是属于 Claude Code 的扩展方案,但是这四个扩展方案本质上是完全不同的一种设计机制
先说 skills
skills 本质上不是工具,而是 一套可复用的流程。
比如你想让 Claude Code 帮你做一次代码 Review。
如果没有 skills,它每次都得自己现场发挥:先看改了哪些文件,再找风险点,再总结问题,再给修改建议。
但有了 skills 之后,这套流程就可以被固化下来,变成一个“标准动作模板”。
所以 skills 更像是你沉淀出来的经验包、方法论、最佳实践。
再说 MCP
MCP 解决的是 Claude 到底怎么连到外面的世界。
比如 Claude Code 想查数据库、读 Notion、调 Figma、访问 GitHub、调用你公司的内部接口。这些东西不是它天生就会的,它得有一套统一协议,知道怎么去连接、怎么拿数据、怎么调用工具。
这个统一协议,就是 MCP。
所以你可以把它理解成:**MCP 负责对接各种能力**。
再说 hooks
hooks 这个就像很多同学都熟悉的生命周期钩子。
它解决的是:某个时机到了,要不要自动做点什么。
比如:
-
Claude 修改完文件后,自动跑一次 lint -
提交代码前,自动检查有没有危险命令 -
某个任务执行结束后,自动发通知 -
某个 Agent 启动后,自动初始化上下文
所以 hooks 的重点其实就是一个 生命周期回调钩子
最后是 plugins
plugins 表示插件,更直白的说就是 打包好的整套功能包。
你完全可以把一个插件理解成:
里面可能自带
skills,也可能接了MCP,也可能注册了hooks,最后统一装成一个可安装、可分发、可复用的扩展。
比如一个“代码审查插件”,里面可能会包含:
-
一套 review 的 skills -
一个接 GitHub 的 MCP -
几个任务完成后的 hooks
用户不需要自己一个个拼,直接装这个插件就能用。
所以,简单来说,这四个东西就是下面这样的:
-
skills:定义做事步骤 -
MCP:连接外部能力 -
hooks:决定什么时候自动触发 -
plugins:把前面这些东西打包起来
上下文和记忆管理
Claude Code 的记忆其实分成两部分:
-
一个是咱们自己写的 CLAUDE.md -
一个是 Claude 自己积累的 auto memory。
两者都会在会话开始时加载进上下文里。
大家可以重点看 auto memory(自动记忆),也可以理解成 Claude Code 会自己梳理长期记忆。
这个功能核心解决的是 claude code 使用的越来越到导致上下文混乱的问题
而从这次流出的代码来看,AutoDream(梦游模式) 很可能就是这套 auto memory 背后的一部分关键实现逻辑。
AutoDream 这套逻辑,从流出来的代码片段看,它做了几层判断逻辑,分别是:
-
距离上次使用至少过了多久 -
这期间累计了多少 session -
当前有没有别的使用场景在跑 -
当前是不是远程模式 -
当前是不是 KAIROS 模式(常驻主动助手模式)
说白了就是 claude code 他会通过上面的几层逻辑判断方案,来梳理 过去的所有上下文,把上下文进行 压缩、去重、纠错、更新索引
如果我们再往里看一层,你会发现 Claude Code 其实非常在意缓存命中率和上下文体积。
泄露代码里有个很典型的实现叫 microcompact。
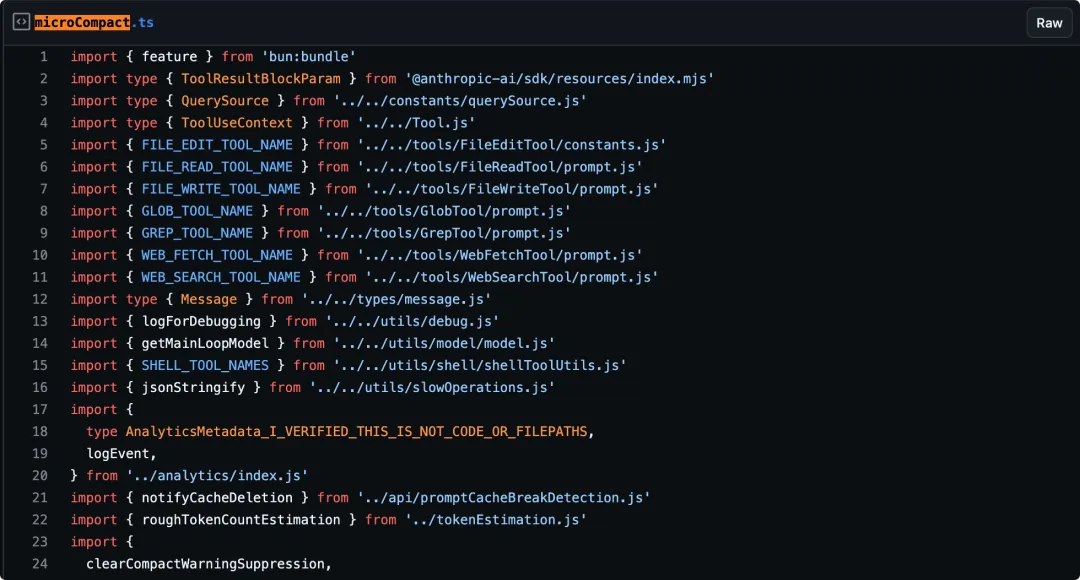
它的处理比较精细,大致逻辑是:
-
第一步:优先清理一部分旧的 tool results,目标主要包括 Read / Bash / Grep / Glob / WebSearch / WebFetch / Edit / Write 这些高频工具的输出。因为这些内容往往很长、很占 token,但对当前轮决策来说,很多时候又不是必须一直保留。 -
第二步:尽量通过 cache editing 的方式,定向移除旧 tool results。这样做的好处是:可以在缩小上下文体积的同时,尽量保住前缀缓存,不至于因为一次清理把前面的缓存命中率也一起打废。
简单来说就是 尽量可以在上下文长度、缓存复用、信息保留之间做平衡
几个隐藏功能
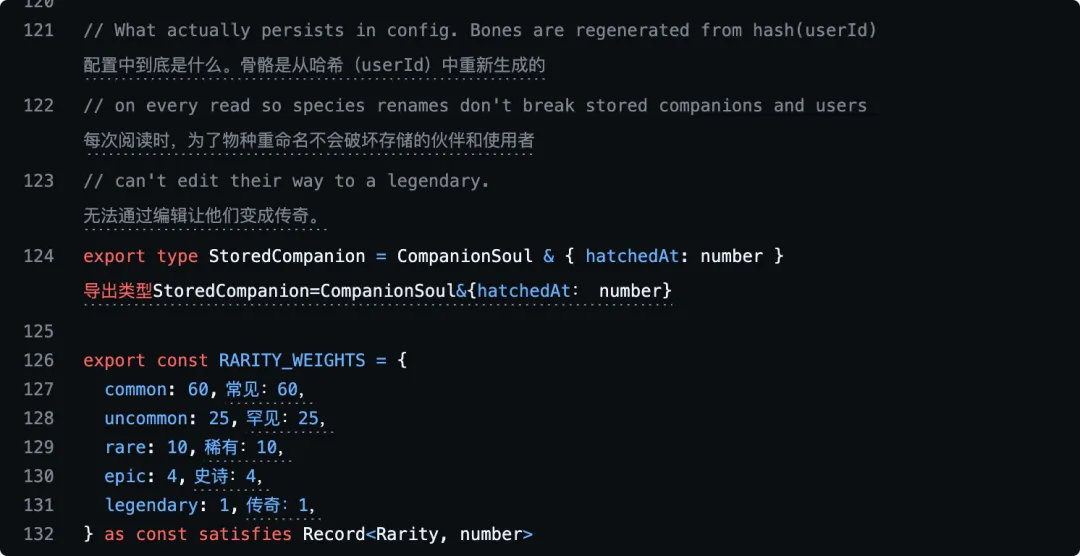
1:Buddy 宠物彩蛋
这个东西很多同学很有兴趣,他类似于一个 Claude code 的宠物。有一种认领了一个宝可梦的感觉。
从代码里明确能看到:
-
一共提供了 18 个宠物 -
稀有度权重是 60 / 25 / 10 / 4 / 1 -
获得闪光稀有卡的概率是 1% -
有 DEBUGGING(调试) / PATIENCE(耐心值) / CHAOS(混乱值) / WISDOM(智慧值) / SNARK(毒舌程度)五个属性 -
具体可以拿到什么宠物由 userId哈希生成,用户没法靠改本地配置伪造稀有度 -
真正持久化的是名字、性格、hatchedAt 这种信息
2:AutoDream 梦游
刚才已经说了,AutoDream 是实际存在的后台记忆。
核心目的就是尽量 可以在上下文长度、缓存复用、信息保留之间做平衡
3:KAIROS 主动模式
我比较谨慎一点说。
现在网上很多文章把 KAIROS 直接讲成“24 小时后台全自动 Agent”,这种表述我觉得说满了。
但至少从现有代码片段可以确定两件事:
第一,KAIROS 不是网友随便起的名字,因为运行时代码里直接有 getKairosActive() 这种状态判断; 第二,AutoDream 里还专门写了注释:KAIROS mode uses disk-skill dream,说明 KAIROS 和 dream/memory 这套逻辑是有明确耦合关系的,而且走的还不是同一条路径。
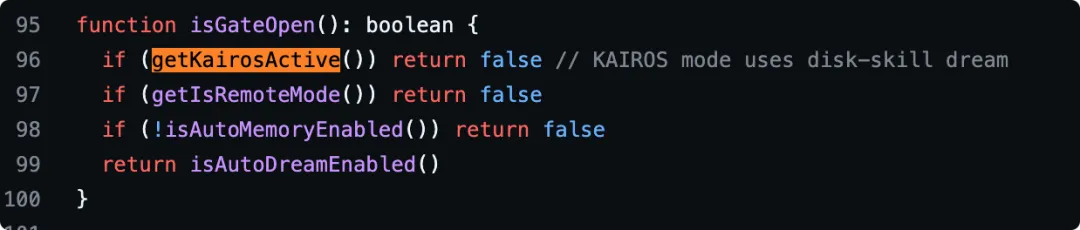
所以更稳妥的说法应该是:
KAIROS 至少已经是 Claude Code 代码体系里真实存在的一种模式概念,而且大概率和持续运行、跨会话状态、长期任务有关。
至于最终产品形态到底是不是大家想象中的“永远在线 Agent”,现在还不能下死结论。
总结
把这些全捋完之后,我最大的感受就一句话:Claude Code 的核心壁垒,不是模型,不是 Prompt,而是 把模型真正变成可用 Agent 的那一整套外壳和调度系统。。
模型层,大家早晚都会接近、工具层,社区也迟早会补齐。
但真正难的是下面这些:
-
怎么让一个 agent 长时间跑下来不乱 -
怎么让它在不同使用入口上共享一套能力 -
怎么把经验、能力、时机、分发拆干净 -
怎么控制权限,不让自动化失控 -
怎么维护内存,不让上下文越跑越脏 -
怎么把 token 成本压到可以商业化
而这些,恰恰就是这次源码最值得看的地方