 夜雨聆风
夜雨聆风





扒完 Claude Code 源码,我开源了个框架,24 小时 1500+ Star(2)

上一篇讲了营销。
这篇讲技术。
open-multi-agent 这个项目,技术方案不是我一拍脑袋定的。是跟 AI 反复掰扯,一个决策一个决策磨出来的。
这篇把 5 个核心决策摊开:为什么这么选、放弃了什么、哪些是 AI 帮我想通的。
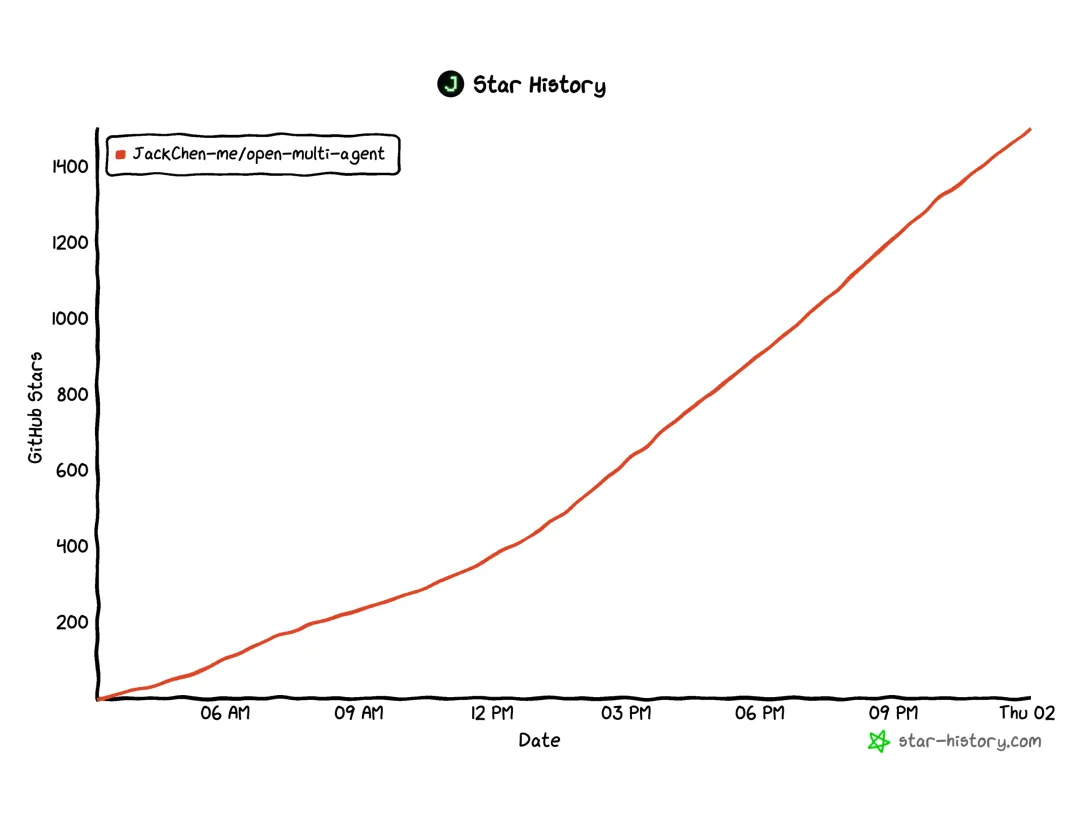
还是先贴项目截图和 Star 趋势图给大家~
先说问题
现在市面上大部分 Agent 框架,干的事其实很简单:
一个 Agent,一个循环。调 LLM → 调工具 → 再调 LLM → 完事。
但真实的复杂任务,一个人干不完。
你需要一个团队:
-
有人拆需求 -
有人写代码 -
有人做审查 -
他们之间得通信、得同步
于是就涉及五个问题:
-
任务怎么拆?拆完怎么排? -
Agent 之间怎么传话? -
怎么做到不绑死某个模型? -
并发怎么控? -
部署到云端,不能有额外开销
一个一个讲。
决策 1:任务 DAG + 拓扑排序
这是整个框架最核心的东西。
先看别人怎么做的:
- CrewAI
:默认串行,一个做完下一个。或者 Hierarchical 模式让 Manager 分配 - AutoGen
:Agent 互相聊,聊到收敛 - LangGraph
:手动画状态机,每个节点每条边都自己定义
三种方案,三个坑。
串行太慢。A 和 B 没有依赖关系,凭什么等 A 做完?
对话轮转不可控。Agent 聊着聊着跑偏了,你根本不知道要多少轮才收敛。
状态机太死。几十个节点几十条边,手动画出来,配置成本高得离谱。
我选的方案:任务 DAG(有向无环图)+ 拓扑排序。
你只需要说一句”B 依赖 A”。
剩下的,框架全自动:
-
Kahn’s algorithm 跑拓扑排序,算执行顺序 -
没有前置依赖的任务,立刻跑 -
能并行的, Promise.all()并行 -
一个任务做完,自动解锁下游 -
一个任务挂了,下游全标记失败。但无关任务不受影响
举个例子:
A: 设计数据模型B: 实现后端 API(依赖 A)C: 实现前端页面(依赖 A)D: 写测试(依赖 B)E: 代码审查(依赖 B 和 C)执行顺序自动算出来:A 先做 → B 和 C 并行 → D 等 B → E 等 B 和 C 都完成。
你不用画图。声明依赖就行。
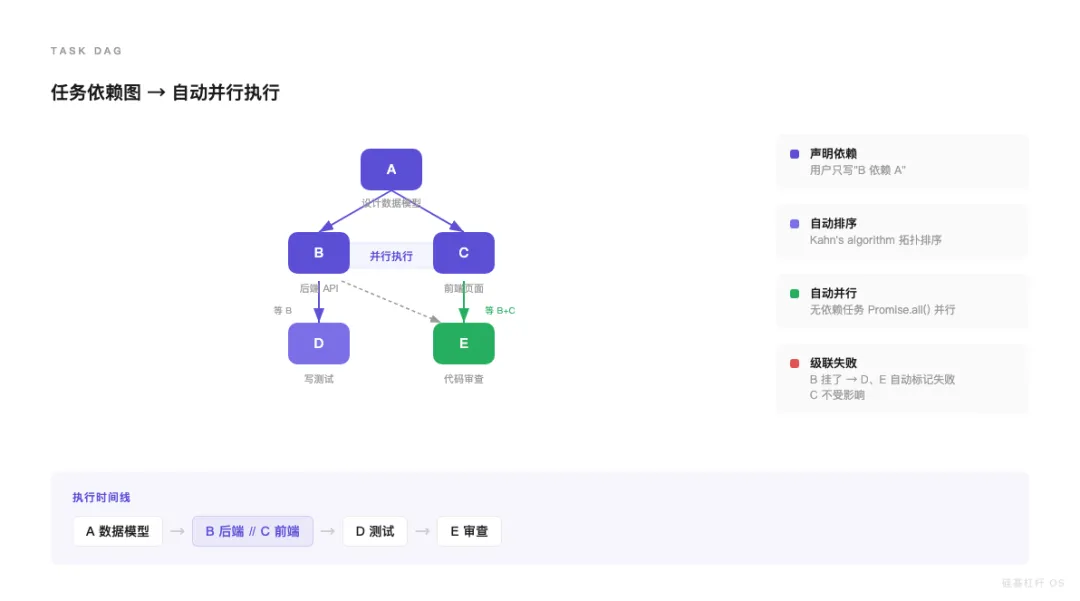
翻译成人话:在”自动化”和”可控性”之间,这个方案找到了甜点。 依赖声明是你写的(可控),但执行顺序和并行度全自动优化。
决策 2:in-process,不是子进程
这个决策是被一个具体问题逼出来的。
Claude Agent SDK 怎么做的?每调一次 Agent,spawn 一个 CLI 子进程。
桌面端跑跑没问题。
但如果你想在 AWS Lambda 里跑多个 Agent 协作?
子进程的启动开销、内存占用、进程数限制。
全是瓶颈。
我的方案:所有 Agent 跑在同一个 Node.js 事件循环里。
为什么能这么做?一个关键观察:
Agent 的主要等待时间在 LLM API 调用上。I/O 密集型,不是 CPU 密集型。Node.js 的异步 I/O 天然就是干这个的。
具体实现:
-
并发控制:Promise + Semaphore(信号量),不用 Worker Threads -
通信:内存里的 Map(MessageBus、SharedMemory),零序列化开销 -
部署:就一个 Node.js 进程。Serverless、Docker,没有额外复杂度
Semaphore 的实现特别轻。就是一个 Promise 计数器,控制同时跑的最大 Agent 数。一个 Agent 做完释放信号量,队列里的下一个自动拿到执行权。
“那 Worker Threads 呢?”
不需要。
瓶颈在网络 I/O,不是 CPU。上 Worker Threads 反而多了跨线程通信和数据序列化的活儿。多此一举。
决策 3:LLMAdapter 只有两个方法
框架不绑死任何模型供应商。核心就一个接口:
interface LLMAdapter { chat(messages, options): Promise<LLMResponse> stream(messages, options): AsyncIterable<StreamEvent>}就 chat() 和 stream()。
没了。
为什么够用?
因为不同 LLM 的 API 差异,说到底就两件事不一样:
- 消息格式
— Anthropic 用 content: ContentBlock[],OpenAI 用tool_calls数组 - 流式输出
— SSE 事件结构不同
其他所有东西——对话管理、工具执行、循环控制——全是通用的。适配器只做格式转换就行。
所以 AgentRunner(对话循环引擎)里面,没有一行跟具体 provider 相关的代码。它只调 adapter.chat(),拿标准化的 LLMResponse,提 ToolUseBlock,执行工具,喂回去。循环。
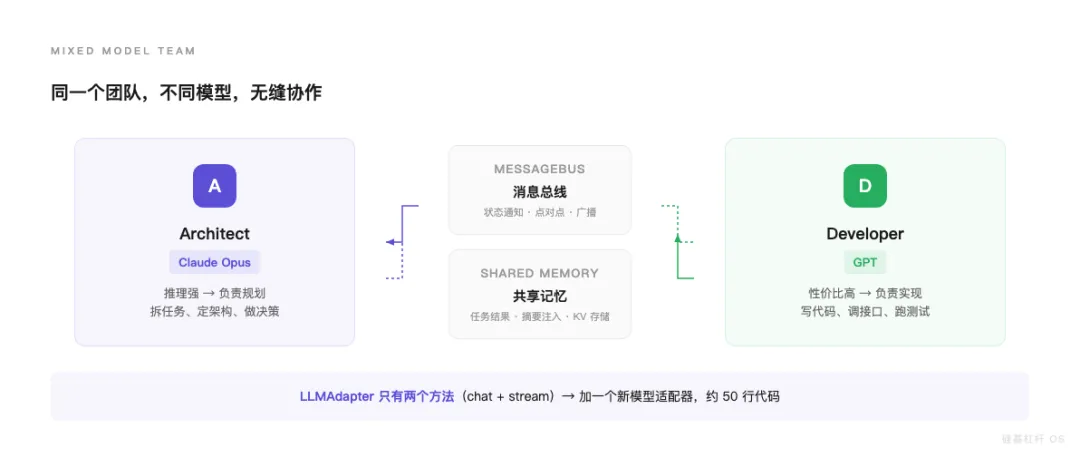
这带来一个很实用的好处:同一个团队里可以混用不同模型。
const architect = { name: 'architect', model: 'claude-opus-4-6', provider: 'anthropic' }const developer = { name: 'developer', model: 'gpt-5.4', provider: 'openai' }Architect 用 Claude Opus 做规划。Developer 用 GPT 写实现。共享 MessageBus 和 SharedMemory,无缝协作。
Reddit 上有人问过”跟 CrewAI 有啥区别?CrewAI 也能做模型无关”。
区别在接入成本。CrewAI 靠 LiteLLM 做适配,LiteLLM 本身是个重依赖。我这边就是两个方法的接口。社区要加 Ollama?大概 50 行代码的事。
决策 4:共享记忆,不是自由聊天
多个 Agent 之间怎么传信息?两条路。
路线 A:让 Agent 自由聊。 AutoGen 就这么干的。A 说一句,B 回一句,来回讨论到达成共识。
路线 B:结构化的共享状态。 做完任务,把结果写入共享内存。下一个 Agent 开始前,读内存了解前面的工作。

我选了 B。
原因很直接:自由聊天烧 token。
两个 Agent 来回 10 轮,轻松上万 token。而且过程不可控——你不知道它们会不会聊跑偏,也不知道要聊多少轮。
说实话,token 成本在生产环境里是个硬约束。不是贵不贵的问题,是可不可预测的问题。
共享内存干净很多。每个 Agent 只管自己的任务,做完往 SharedMemory 里写。下一个 Agent 启动时,prompt 里自动注入摘要:
## 团队共享记忆### architect- api-spec: REST API 设计文档已完成,包含 5 个端点...### developer- implementation: 代码已实现,通过基础测试...每个 Agent 都能看到队友的成果。但不用来回聊。
另外还有个 MessageBus 做即时通信,支持点对点和广播。但实际跑起来,MessageBus 主要就干一件事——通知”我做完了”。真正的信息传递靠 SharedMemory。
决策 5:让 AI 当项目经理
用户输入一句话:”创建一个 Todo 应用的 REST API”。
谁来拆?
我的方案:用一个临时的 Coordinator Agent 做拆解。 它接收目标 + 团队名单,输出 JSON 任务列表——title、description、assignee、dependsOn。
说白了,用 AI 做项目管理。
这有坑。LLM 可能拆得不好。
所以框架做了两个兜底:
-
Coordinator 的 JSON 解析失败?退化为每个 Agent 各分一个任务 -
不想用自动拆解? runTasks()手动定义任务图
说实话,实际跑下来比我预期的好。Claude 和 GPT 在”把大目标拆成小任务”这件事上做得挺靠谱。
想想也正常。这本质是个规划问题。LLM 擅长的事。
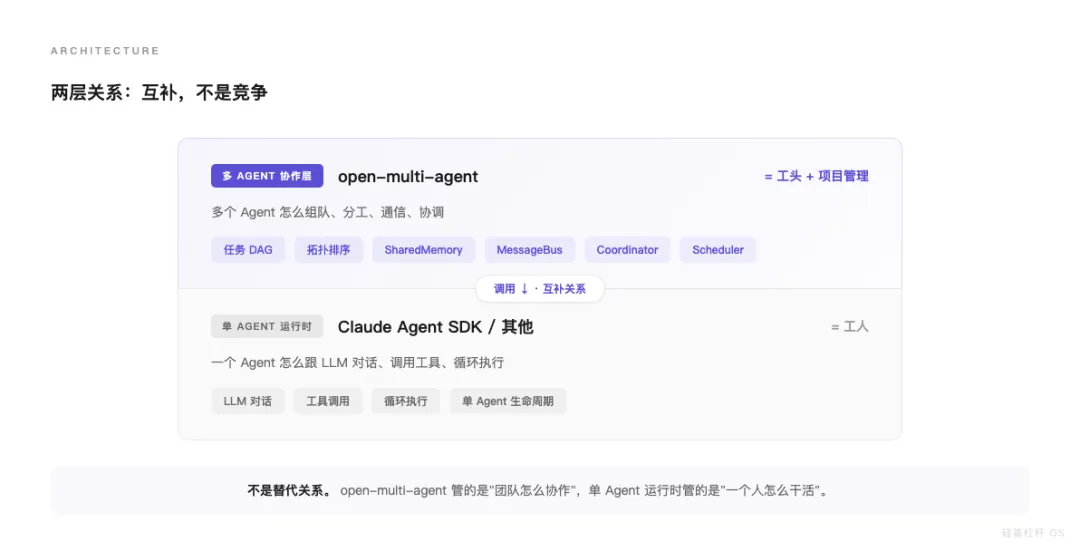
跟 Claude Agent SDK 到底什么关系
Reddit 上讨论最多的就是这个。技术层面说清楚。
它俩不在同一层。
Claude Agent SDK 是单 Agent 运行时——一个 Agent 怎么跟 LLM 对话、调工具、循环执行。
open-multi-agent 是多 Agent 协作层——多个 Agent 怎么组队、分工、通信、协调。
翻译成人话:Claude Agent SDK 是工人,open-multi-agent 是工头 + 项目管理系统。 互补关系,不是竞争。
我最初 README 里写了”Unlike Claude Agent SDK…”。
被 Reddit 精准打击了。
后来改掉了。教训是:为了营销效果做不准确的技术对比,一定会翻车。
TypeScript 生态的空白
做之前调研了一圈:
-
CrewAI — Python -
AutoGen — Python -
LangGraph — Python -
LlamaIndex Workflows — Python
TypeScript 呢?
几乎没有。
不是 TypeScript 不适合。恰恰相反。Node.js 的异步 I/O 天然适合 Agent 工作负载(I/O 密集型)。而且大量 AI 应用的后端就跑在 Node.js 上。
空白的原因更可能是:AI 框架的开发者社区以 Python 为主。TS 开发者还没大规模进这个领域。
这也是项目能在 24 小时内拿 1500+ star 的原因之一。
需求是真实存在的。
Reddit 上有人说”终于有一个 TypeScript 的了”。
这句话比任何技术夸奖都更说明问题。
AI 辅助开发:几个真实体感
8000 行 TypeScript。全程 AI 辅助。说几个具体的。
AI 擅长的:
-
架构讨论。我说”想做一个多 Agent 框架”,AI 帮我理出 Orchestrator → Team → Agent → AgentRunner 的层级 -
算法实现。Kahn’s algorithm、Semaphore 的 Promise 实现,写得又快又对 -
适配层代码。Anthropic 和 OpenAI 的 API 格式转换,AI 对这些 API 门儿清
AI 不擅长的:
-
取舍判断。”要不要上 Worker Threads”,AI 会列所有利弊。但拍板得你自己来 -
事实核查。npm 包名是不是被占了、API 是不是真按文档说的那样——AI 不会主动验证 -
长期规划。”这个项目值不值得长期做””该做产品还是冲 star”——AI 能分析,不能替你决定
然后我踩了一个印象深刻的坑。
AI 帮我写 README,直接用了 npm install open-multi-agent。
没验证包名是否可用。
我当时有过一闪念——”这里可能有问题”。
但没停下来查。
结果这个包名被别人占了。导致 2100 次错误安装。
AI 生成的东西看起来很自信。但它不会告诉你”我没验证过”。那个一闪而过的直觉,才是你该听的。
代码地图
给想翻源码的人一个索引:
src/├── orchestrator/ # 顶层编排│ ├── orchestrator.ts # 接收目标、拆任务、协调执行│ └── scheduler.ts # 四种调度策略├── agent/ # Agent 引擎│ ├── agent.ts # Agent 定义 + 生命周期│ ├── runner.ts # 对话循环:LLM → 工具 → LLM│ └── pool.ts # Agent 池 + Semaphore├── task/ # 任务系统│ ├── task.ts # 任务定义 + 拓扑排序│ └── queue.ts # 队列 + 依赖解析 + 级联失败├── team/ # 团队│ ├── team.ts # 团队管理│ └── messaging.ts # MessageBus├── memory/ # 共享记忆│ ├── shared.ts # SharedMemory + 摘要生成│ └── store.ts # KV 存储├── llm/ # 模型适配│ ├── adapter.ts # 工厂函数│ ├── anthropic.ts # Claude 适配器│ └── openai.ts # GPT 适配器├── tool/ # 工具系统│ ├── framework.ts # defineTool() + Zod schema│ ├── executor.ts # 执行器│ └── built-in/ # 5 个内置工具└── utils/ └── semaphore.ts # Promise 信号量约 7000 行,25 个文件。想看什么,进对应目录就行。
最后问一句:
你现在用 AI 写代码,架构这一步是完全交给 AI 拍板,还是自己判断?
我的经验是——AI 是很好的讨论搭子。但架构决策这种事,一定是人拍板。
GitHub: https://github.com/JackChen-me/open-multi-agent
npm:npm install @jackchen_me/open-multi-agent
MIT 协议,欢迎 PR。 特别是本地模型的 LLMAdapter(Ollama、llama.cpp),接口就两个方法,实现成本极低。