 夜雨聆风
夜雨聆风





别人翻三天文档,我半小时出两万字研究报告,靠的是这个 Skill
最近热度超过龙虾、在 GitHub 上爆火的 Hermes Agent,你们研究了吗?GitHub 狂揽 66k Stars,OpenRouter token 消耗日榜冲到第二,仅次于龙虾本虾 OpenClaw。
全球「编程应用」榜直接登顶,「生产力榜」第二。

YC CEO Garry Tan 亲自试完说「彻底回不去了」。
Nous Research 甚至专门发了一条中文推宣布原生接入微信。一家硅谷实验室,用中文跟中国用户互动,你说离不离谱。
一时间,很多人直接弃掉了 OpenClaw,纷纷转战 Hermes。第一次注意到它的时候,点进去看了一眼 README,写着「The Only Agent with a Built-in Learning Loop」,大概意思是这个 Agent 能自我进化,越用越聪明。
听着挺唬人的。
但说实话,我完全搞不清楚它到底是什么来头。Nous Research 是谁?它跟 LangChain、AutoGPT 那堆框架是什么关系?为什么突然就火了?那个「学习闭环」到底是真的还是营销话术?3.99 美元就能用上,门槛低到离谱,但它凭什么能撼动 OpenClaw?
这种感觉你们应该很熟悉。
一个东西一夜爆火,所有人都在聊,但你既不想当那个跟风喊牛逼的人,也不想当那个啥都不知道的人。
你想搞懂它,但你没有三天时间去翻完它所有的 GitHub commit、HuggingFace 模型页面、arXiv 论文和 Reddit 讨论帖。
这种焦虑感,我觉得是这个时代最普遍的情绪之一了。
每天打开手机,又有新框架了,又有新模型了,又有谁融了几个亿了。你刚搞明白 MCP 是什么,Harness 又来了;你刚搞明白 Harness,Hermes Agent 又火了。昨天还是 OpenClaw 一家独大,今天 Hermes 就冲上全球第一。YC CEO 都在推特上喊「回不去了」,你的时间线被各种「Hermes 太牛了」刷屏,Issues 都堆到 2.3k 了。信息像洪水一样朝你涌过来,AI 让你获取信息的成本趋近于零,但问题是,你获取的信息越多,你反而越焦虑。
因为你不知道哪些是重要的,哪些是噪声。
你不知道该从什么角度去看一个新东西。
你不知道怎么把散落的信息组织成一个有意义的判断。
这些东西,AI 帮不了你。或者说,AI 只能在你给出方向之后帮你执行,但方向本身得你自己定。
我之前也一直被这个问题困扰。直到我给自己搞了一个提问框架。
后来我把它做成了一个 Skill,装在 Claude Code 里面,每次遇到一个陌生的东西,跟它说一句「帮我研究一下 xxx」,半小时就能出一份带图表的深度研究报告。
就比如这次的 Hermes Agent。
我就跟 Claude Code 说了一句,帮我研究一下 Hermes Agent,顺便对比一下 OpenClaw。
然后它就开始跑了。
先是三个子 Agent 同时出去搜集信息,一个负责挖 NousResearch 的历史和 Hermes 模型系列的发展脉络,一个负责搜集 OpenClaw 和 LangChain、CrewAI 那堆竞品的数据,一个负责深扒 GitHub 仓库的技术架构和社区讨论。
大概半小时左右,一份两万字的研究报告就出来了,还附带 7 张图表。

我当时看完第一个反应是,卧槽,原来 Hermes Agent 的来头这么深。
它不是凭空冒出来的。Nous Research 这个组织从 2023 年就开始做开源模型微调了,一个叫 Teknium 的人用 GPT-4 合成了 30 万条训练数据,搞出了第一个 Hermes 模型。然后一路迭代,Hermes 2、Hermes 2 Pro、Hermes 3,每一代都在往「Agent」方向加码。
特别是 2024 年 3 月的 Hermes 2 Pro,第一次在模型层面做了原生的 Function Calling,准确率 91%。这一步现在回头看,是整个故事的转折点,它让 NousResearch 从「微调模型的人」变成了「定义 Agent 能力标准的人」。
然后 2025 年 7 月 22 日,Teknium 提交了 Hermes Agent 仓库的第一个 commit, commit message 还拼错了,写的是「initital commit」。
你看,这不是一个精心策划的企业级 launch,就是一个人某天下午决定开干了。
但到了 2026 年 3 月,事情开始变得疯狂。22 天,6 个大版本。v0.8.0 一个版本就合并了 209 个 PR。Stars 从几千飙到七万多。
研究报告里有一张时间线图,把这整个过程画的特别清楚,从 2023 年的模型积累期,到 2024 年的 Agent 能力萌芽,再到 2026 年的框架爆发期,三个阶段,一目了然。

我觉得最有意思的发现是,报告挖出来 Hermes Agent 其实是 OpenClaw 的继任者。
OpenClaw,356k Stars,AI Agent 领域最大的开源项目之一。Hermes Agent 直接提供了一个 hermes claw migrate 命令,可以从 OpenClaw 迁移全部资产。这说明两个项目之间有直接的继承关系。
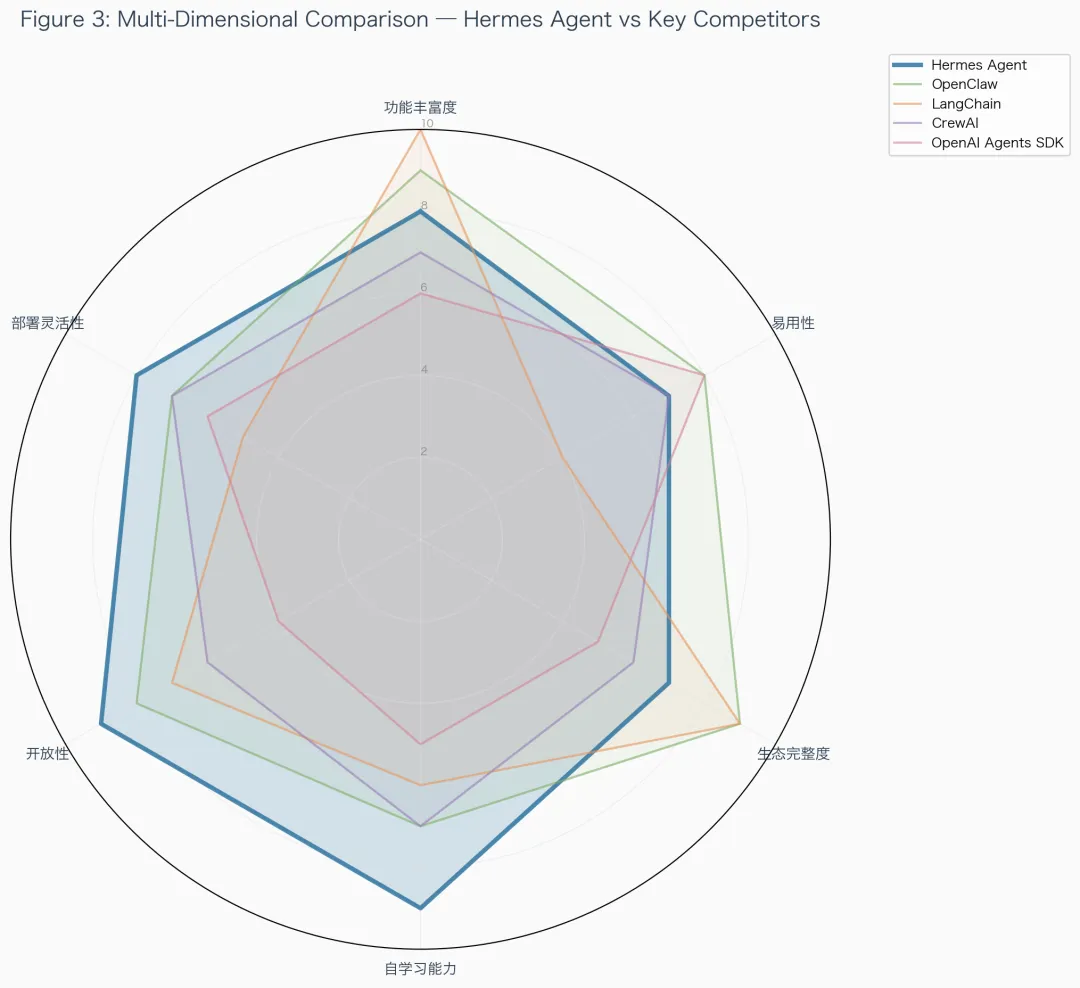
但 Hermes Agent 做了几个关键改变,语言从 TypeScript 切换到 Python,加入了自学习循环,深度集成了 NousResearch 自己的模型生态。研究报告里有一张 Hermes Agent 和 OpenClaw 的八维雷达对比图,一眼就能看出两者的差异化方向。
这些东西,你靠刷十篇公众号文章是拼不出来的。
但一个好的研究框架 + AI 的执行力,半小时就搞定了。
好,说到这个框架本身。
我管它叫横纵分析法,其实特别简单,就两条轴。
第一条轴,纵向。沿着时间线,把一个东西从诞生到现在的完整故事给还原出来。它怎么来的?谁做的?中间经历了什么?为什么在某个节点突然爆发了?你把这条线理清楚,你就理解了一个东西的因果和脉络。
这是深度。
第二条轴,横向。在当下这个时间点,把它跟同赛道的其他东西放在一起比。它跟竞品有什么不同?用户为什么选它不选别的?它在整个赛道里是什么位置?你把这个切面看清楚,你就理解了一个东西的位置和差异。
这是广度。
很多人研究一个东西,要么只看历史,要么只看对比。只看历史,你知道它怎么来的,但不知道它在市场上处于什么位置。只看对比,你知道它跟别人有什么不同,但不知道这些不同是怎么形成的。深度没有广度来锚定,容易钻牛角尖,广度没有深度来支撑,容易浮于表面。
横纵分析法就是让你同时拥有深度和广度,建立一个立体的认知框架。
然后最关键的一步,是把两条轴交叉起来看。
纵向告诉你它是怎么走到今天的,横向告诉你它今天站在哪。两条轴一交叉,你就能看到一些单独看任何一条轴都看不到的东西。
比如 Hermes Agent 今天的「自学习循环」这个核心优势,其实可以追溯到 2023 年 Teknium 做合成数据策划的能力积累,到 2024 年 Function Calling 标准化,再到 2025 年 Skill 系统的设计。这条因果链,你只看横向对比看不到,只看历史也看不到,两条轴交叉了才能拼出来。
再比如 Hermes Agent 今天缺少原生客户端这个短板,根源在于它从 TypeScript 切换到 Python 的那个决策,OpenClaw 的 macOS/iOS/Android 客户端没法直接继承过来。这是一个「当初合理的选择变成了今天的包袱」的典型案例。
纵向追时间深度,横向追同期广度,最后交汇出判断。
就这么简单。
这个方法的学术根源其实蛮有意思的。语言学里索绪尔提出过「历时分析」和「共时分析」的概念,社会科学里有「纵向研究」和「横截面研究」的范式,商学院里有竞争战略分析的各种框架。我只是把这些东西揉到一起,做成了一个 AI 能跑的通用研究 Skill。
具体怎么用呢。
如果你用 Claude Code、Codex、Gemini CLI 这类 Agent 工具,你可以直接装这个 Skill。装上之后,你跟 Agent 说「帮我研究一下 xxx」,它就会按照横纵分析法的框架去跑。
它会自动联网搜索信息,会调用 arxiv API 去查相关论文,会并行派出多个子 Agent 分头搜集纵向和横向的数据,最后还会自动生成图表,时间线图、竞争格局气泡图、多维雷达对比图、架构图、生态图,全都有。
出来的报告一般在一到两万字,读起来不像那种干巴巴的咨询报告,更像一篇有节奏感的深度长文。这个是我花了不少时间调的,因为一份你读不下去的研究报告,写得再全面也没用。
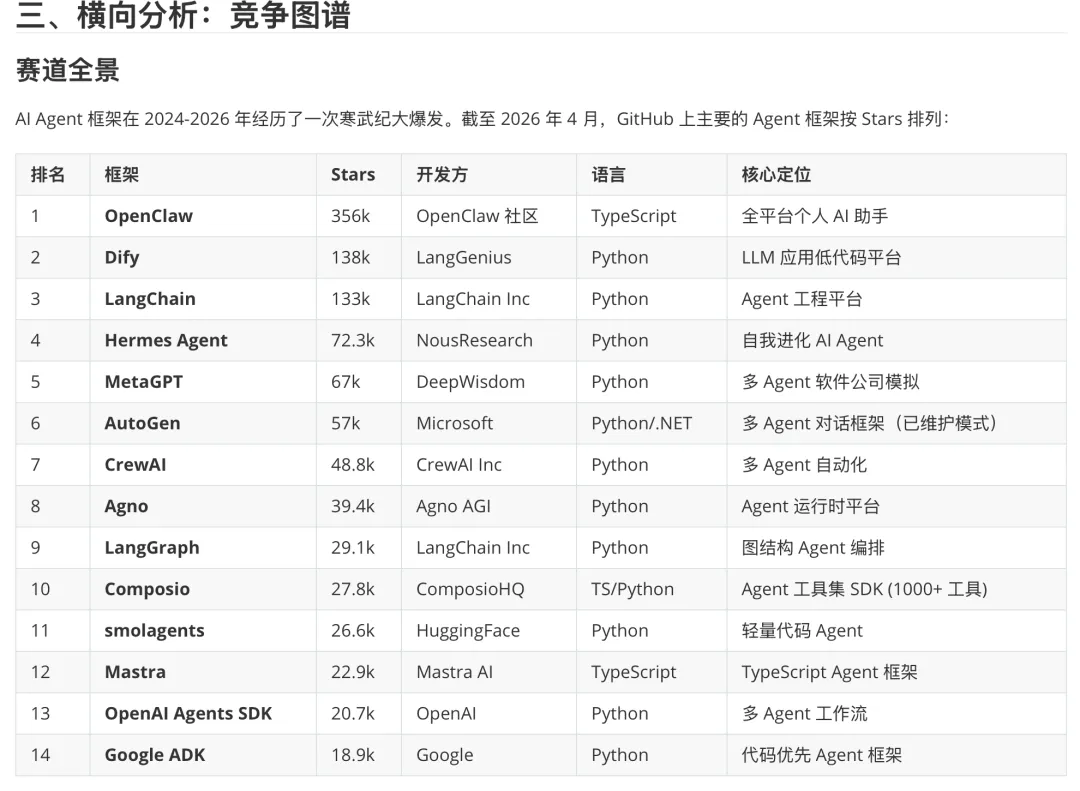
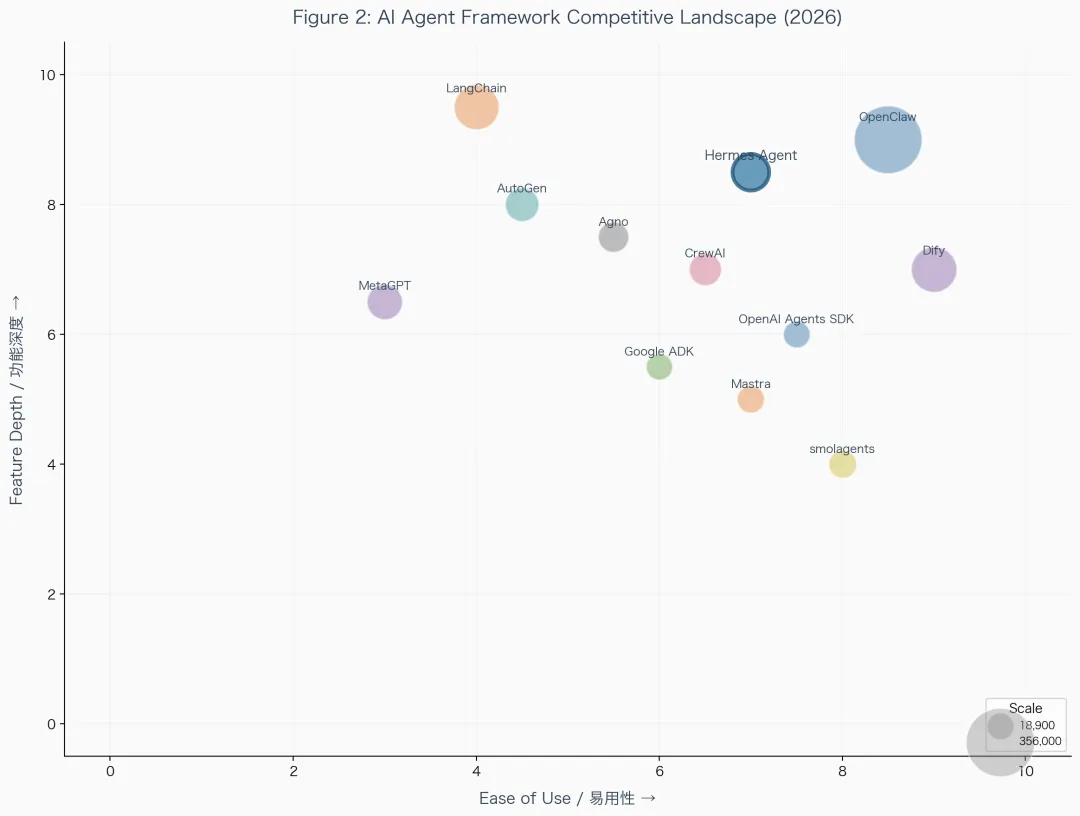
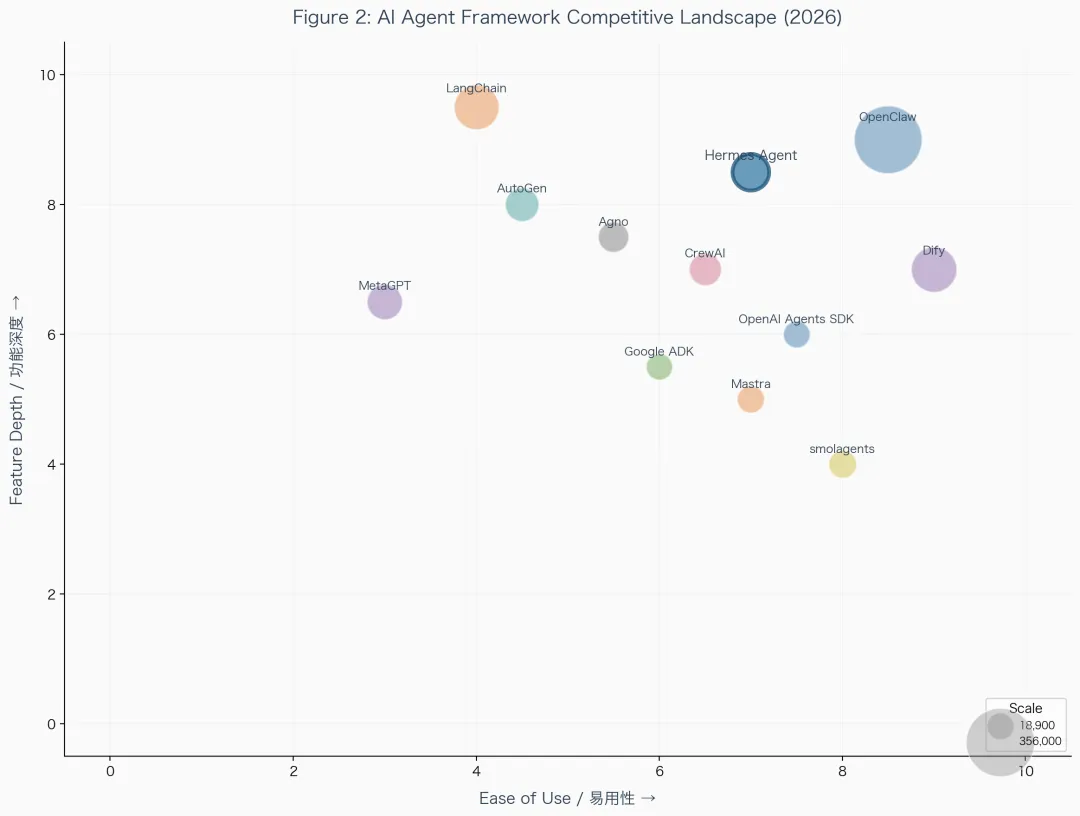
我拿 Hermes Agent 这次研究举个例子,报告里的竞品对比部分,不只是罗列功能差异,而是把 14 个主要框架画成了一张气泡图,X 轴是易用性,Y 轴是功能深度,气泡大小是 GitHub Stars。一眼就能看出整个赛道的格局。
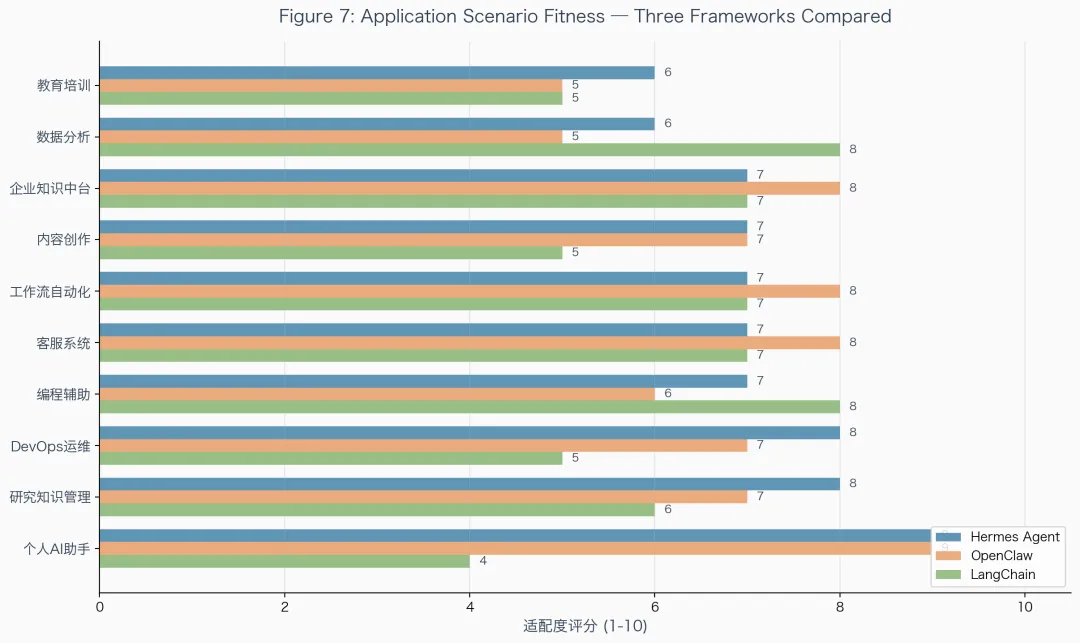
还有一张应用场景适配度的图,对比了 Hermes Agent、OpenClaw 和 LangChain 在 10 个场景下的评分,从个人 AI 助手到 DevOps 运维到教育培训,特别直观。
当然,我得坦诚说一下这个方法的局限。
它不是万能的。
它能帮你在很短的时间内建立一个相当完整的认知框架,但它替代不了真正深入的、亲自下场的研究。AI 搜集到的信息虽然现在幻觉已经很低了,但还是可能出现不准确的地方。
所以你不能拿到报告就直接当结论用,它更像是一个起点,帮你快速建立地图,然后你再根据这个地图去做更深入的探索。
我自己的做法是,拿到报告之后先快速通读一遍建立框架,然后针对我觉得有疑问或者特别感兴趣的点,再去深挖。横纵分析法生成的报告 + 自己手动深挖,这个组合拳的效率,比从零开始高了一个数量级。
另外一个很现实的问题是,Skill 版本需要你有 Claude Code 或者类似的 Agent 环境,如果你平时不用这些,也可以直接拿横纵分析法的 Prompt 版本,扔给 ChatGPT 的 Deep Research、Claude 的深度研究、豆包的专家模式,效果也不错,只是没有图表和自动联网搜索那么强。
回到开头那个场景。
几天前我在 GitHub Trending 上看到 Hermes Agent 的时候,脑子里只有一个模糊的问号。半小时之后,我手里有了一份两万字的研究报告,7 张图表,从 2023 年 Teknium 上传第一个 13B 模型到 2026 年 22 天迭代 6 个大版本的完整故事,从 OpenClaw 到 Hermes Agent 的继承关系,从 LangChain 到 smolagents 的 14 个竞品定位图。还有三个未来剧本的推演。
那个从「这啥」到「原来是这样」的过程,说真的,太爽了。
我有时候觉得,这个时代做研究,真正稀缺的不再是信息,而是你对这个世界有多好奇。
信息已经像洪水了。AI 让搜集信息的成本趋近于零。但你要问什么问题、从什么角度去看、怎么把散落的碎片拼成一幅有意义的图,这些事情,得你自己来。
横纵分析法就是我给自己定的一个提问框架。每次面对一个陌生的东西,我不需要临时想该从哪几个角度去了解它,这个框架已经帮我想好了。
它让我不用再像几年前一样花三天时间搜集信息。现在半小时框架就搭起来了,剩下的时间可以花在真正有意思的地方,就是看着这些信息慢慢拼成一幅完整的图,然后突然「啊,原来是这样」的那个瞬间。
那个瞬间,真的很过瘾。
说实话我也不确定这个 Skill 适合每个人。但如果你也是那种脑子里经常冒出一堆问题、又嫌搜集信息太慢的人,可以试试。
古希腊人说,哲学始于惊奇。
研究也是。始于你对一个东西真的好奇。方法和工具都是后面的事,好奇心在前面。
没有好奇心,有再好的框架也是摆设。
有了好奇心,哪怕方法笨一点,你也总会找到答案的。
只不过现在,找答案这件事,确实比以前快多了。
快到你可以对更多的事情。
保持好奇。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧。
谢谢你看我的文章,我们,下次再见。