 夜雨聆风
夜雨聆风





一个能精准纠错的AI,为何造不出纠错工具?
最近对文章校对失去耐心了。像昨天那篇文章,1000 多字。我足足看了 5 遍,结果用电脑里的 WPS 检测了一下,竟然还有错别字。
我不想开电脑。
我也不愿意让豆包帮我检查,TA废话太多,而且还喜欢改文章,你给TA看过的文章,不知道多了文还是少了字。
要不,用灵光做个小应用,自动帮我检查错别字和敏感词,自动纠错,岂不美哉?
说干就干。
打开灵光,在对话框中输入:帮我开发个文本检测工具,检测文章中的错别字和敏感词,错别字用红色标注,敏感词用黄色标注。
大概30秒,应用就生成了,挺像模像样的。

一测,不是十分精确,但也能发现文章的错别字,可惜把错别字挪到别的地方去了。
错了 3 次,每次错别字放的地方都不一样。这发挥,真是随心所欲啊。
我想这功能可能太复杂了。敏感词和错别字一起会互相干扰,我命令灵光:把敏感词去掉。
敏感词去掉了,结果也没有好转。小应用好像把错别字当成了一个“字块”,这个字块搬到哪里,可能TA也不知道。
我换了个思路,让TA别在文中标注了,在文章的底下列出来,再提出修改建议。结果还是差得太远。
反复折腾了十来次,我发现,不管怎么发号施令,灵光都达不到我的要求。
是TA的能力有限,达不到这要求吗?
我把文章直接抛给灵光,让TA帮我检测错别字。TA检测得又快又精准,一点废话都没有,说明大模型的能力是足够的。
到底问题在哪呢?
我反复摸索了许久,三次重起炉灶,最后,不得不放弃了。
毕竟,及时止损也是人生大智慧,对吧?
但我百思不得其解,虚心向灵光请教:作为大模型的你明明做得那么好,为什么开发出来的小程序就不行呢?
灵光回答我:大模型直接检测时,能完整理解上下文语义;但生成小程序时,它只能输出代码,真正的检测逻辑要由小程序自己去执行——而小程序没有大模型的理解能力。

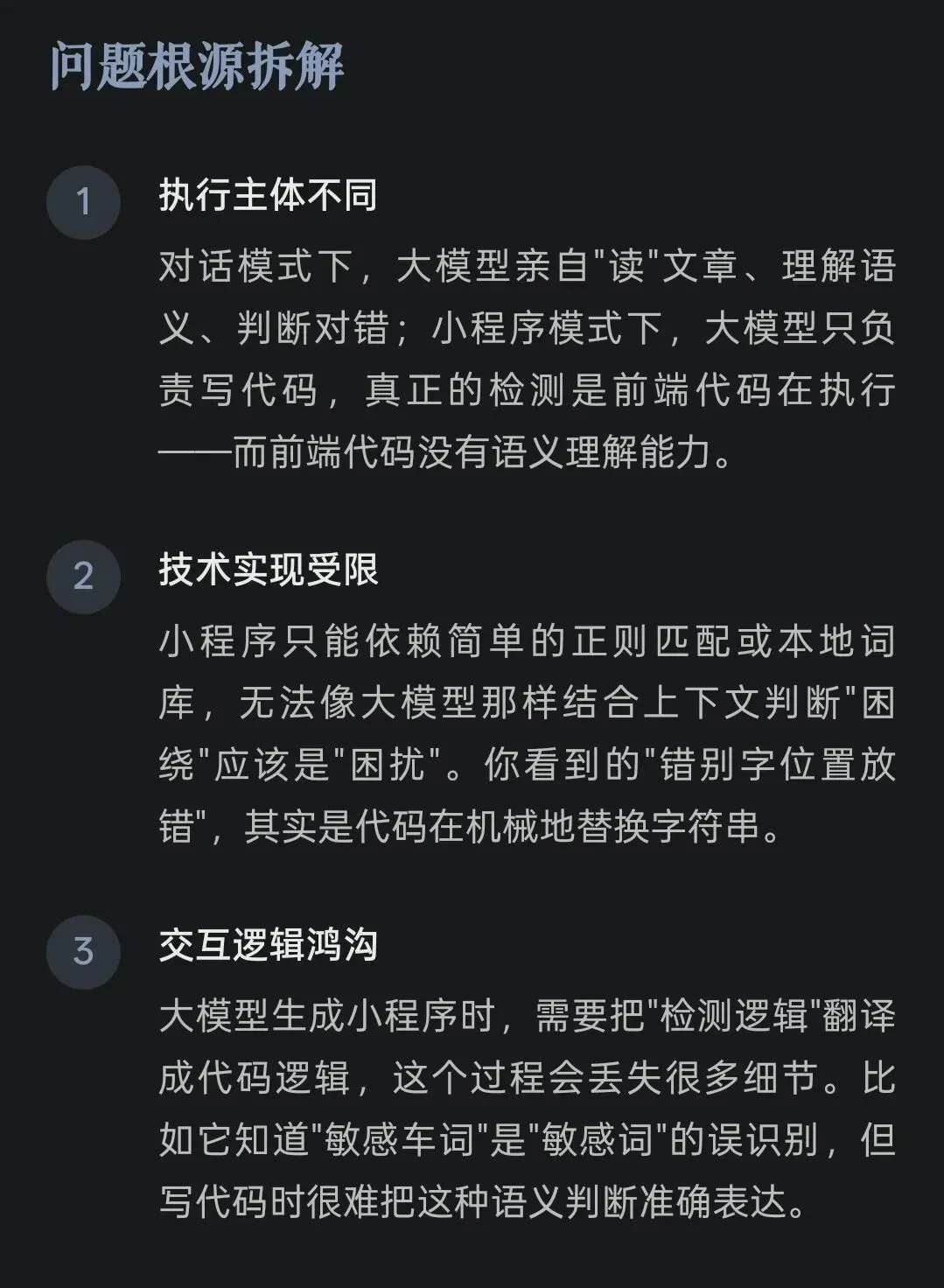
原来,问题在这里。
大模型是大脑,小程序是手脚。不需要调用大模型的时候,用小程序这个手脚就能跑,比如:口算、背单词游戏等。但涉及到生成图片、检查文章这种需要大模型支持的功能,用小程序的效果就差强人意了。
我捣鼓了一天,文本校对小应用开发还是失败了。但在开发过程中的思考和探索,也是值得记录和分享的。
最后,用灵光模式总结——
当你发现怎么也跑不通的时候,
换个思路;
换思路还不行,就换种做法;
换做法还不行,
放弃就是最好的前进。