 夜雨聆风
夜雨聆风





金融风控中的AI调度:低延迟决策引擎的资源分配策略
——实时反欺诈场景下的GPU调度突围之路
一、引言:毫秒之差,百万之失
在金融风控领域,每一笔交易背后都在进行一场无声的赛跑。欺诈检测模型必须在一笔交易完成之前给出判断结果,用户几乎没有耐心等待超过100毫秒。
这不是危言耸听。某支付处理商每天处理数上千万笔交易,峰值要求每秒钟处理1000笔交易,且每笔交易延迟必须低于20毫秒——一旦超时,风控系统直接降级甚至跳过检测,欺诈交易将漏过闸门。
面对这样严苛的SLA,传统GPU调度方式彻底失效。K8s调度器按整卡分配资源,一个推理Pod独占整张A100,哪怕只用20%算力和30%显存,其余80%的算力也在空转等待,与此同时,一波又一波的交易请求却在排队——当欺诈检测系统因资源争用而延迟超过100毫秒时,交易可以直接通过。
二、算力困局:GPU资源“整卡批发”如何拖垮风控响应
2.1 核心矛盾:毫秒级延迟 Vs 整卡分配
欺诈检测推理有两个核心特征——低延迟、高并发。一家中型银行的线上反欺诈系统,峰值QPS可达5万-10万,这意味着每秒钟有上万笔交易在等待AI判断。
然而,传统K8s调度器始终按整卡分配GPU资源。一个推理服务请求1张A100,调度器就给1张,即便该服务的GPU利用率仅在20%-30%之间波动。银行风控集群中大量这类服务同时运行,部分卡被“假负载”长期占用(利用率持续低于15%),其他新上线的风控模型却因无卡可用而陷入Pending。
有一个场景最能说明问题:银行在周末对历史交易数据进行离线欺诈分析时,GPU利用率迅速攀升;但周一早高峰开启实时反欺诈服务时,推理Pod却因为离线任务占满卡而无法调度,结果线上交易排队超过100ms,SLA直接击穿。
2.2 三大失控表现:从利用率账单到排队洪峰
2.2.1 波峰时段任务卡死,高优服务反复Pending
该行曾追踪一周数据:工作日10:00-12:00交易高峰期,某些紧急上线的风控模型推理服务的平均Pending时长达5-10分钟——这在新欺诈模式爆发的时段显得极为致命。
2.2.2 波谷时段算力沉睡,利用率账单照付
深夜交易量大幅下降,GPU集群整体利用率不足20%,显存空置却依然支付巨额的硬件和电力成本。
2.2.3 缺乏分层机制,冷门模型与高频服务“同卡竞争”
有时低频使用的辅助模型与核心欺诈检测模型共享同一GPU,导致核心模型推理延迟出现不可控的抖动。
这些现象的核心,是目前GPU资源在延迟敏感场景下“分配粒度不足”——我们需要将整卡批发模式,转变为“根据延迟需求、并发量和优先级”动态切分的精细化调度体系。
三、三步破局:从“卡级锁定”到“毫秒级按需取餐”
3.1 第一步:GPU共享调度——打破整卡锁定
实现GPU动态切分有两种主流路径:
-
硬件级虚拟化(MIG):适用于A100/H100,将单卡物理切分为2-7个独立实例。欺诈检测这类对延迟要求极高、对显存隔离诉求强烈的场景尤为适用。 -
软件级共享(cGPU / FractionalGPU):基于内核驱动层的虚拟化,按5%为最小单位切分算力,支持高优任务抢占。阿里云cGPU可在内核驱动层将GPU资源虚拟化为vGPU,实现MB级显存隔离和算力按需分配。多租户场景、需要灵活调整资源边界的金融机构更推荐此路径。
此外,动态批处理(Dynamic Batching) 也是提升吞吐的关键优化:系统根据到达请求的间隔自动合并小批次,一次性送入GPU执行推理。实测表明,集成动态批处理后的GPU利用率可从不足30%提升至50%以上。
3.2 第二步:分层调度——在IM里用自然语言定义策略
利用运维智能体通过自然语言交互让调度策略“可描述、可沟通、可执行”:
👤 “@智能体 创建调度策略:p0级的信用卡实时欺诈检测服务最低保障50%算力冗余,允许抢占离线训练任务。”“@智能体 列出过去30分钟内延迟超过100ms的推理Pod,按P99延迟降序输出。”“@智能体 把周末离线欺诈分析任务优先级降至最低,周一早上8点自动恢复。”
智能体将这些指令解析为K8s调度规则,联动底层调度器实现自动化资源调剂。
金融风控低延迟推理GPU共享调度架构图
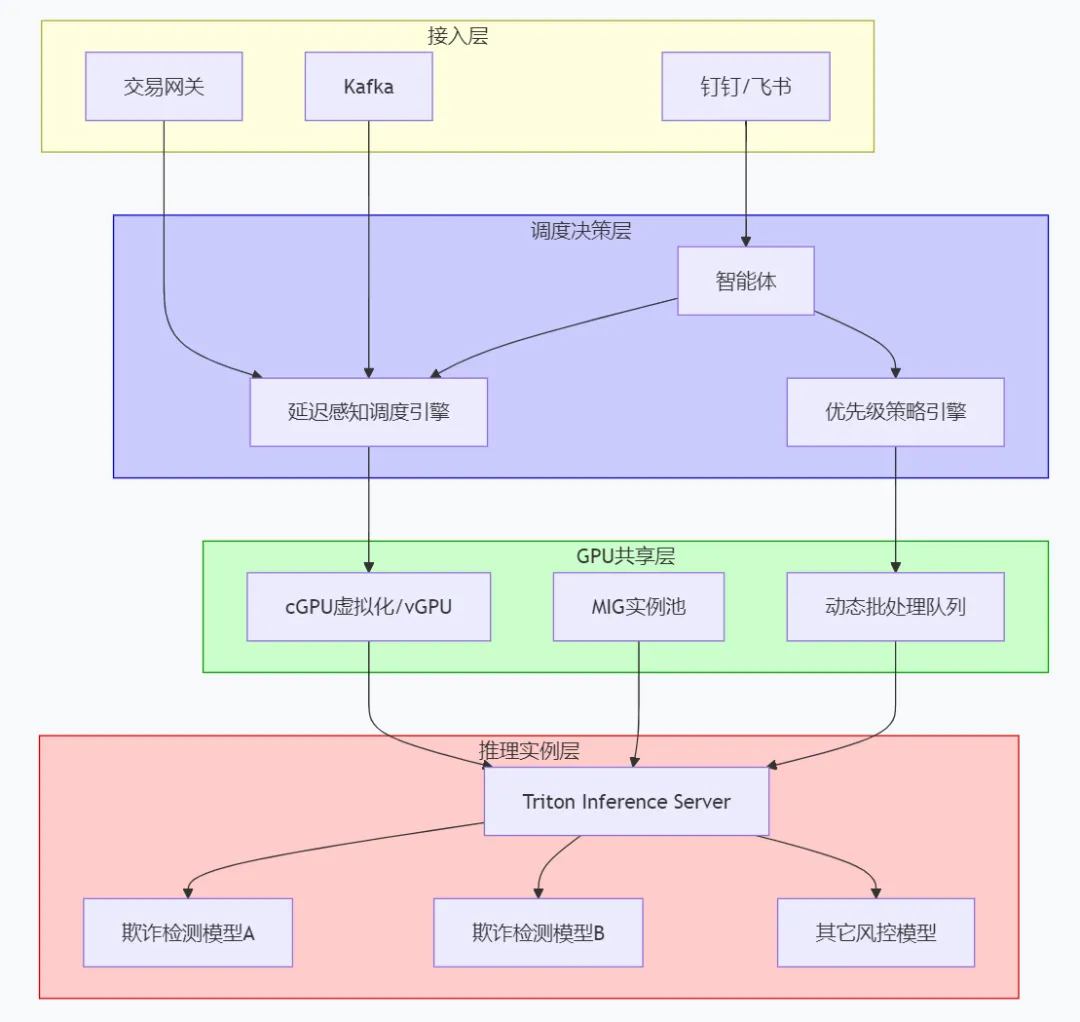
3.3 第三步:分级策略与弹性伸缩——让“好钢用在刀刃上”
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.4 推理运行时优化——每一毫秒都必须精打细算
在100ms的硬约束下,模型推理的每个环节都要精打细算。NVIDIA Triton Inference Server是当前金融风控领域的主流部署方案,NVIDIA官方AI蓝图已基于Dynamo‑Triton构建欺诈检测参考架构,输出欺诈分数及Shapley值实现可解释性。
NVIDIA工具链与典型优化效果:
-
TensorRT:将欺诈检测模型FP32精度转换为FP16/INT8,在A100上推理延迟可降低40%-60%; -
TensorRT-LLM:为LLM场景优化的推理加速框架,将注意力计算延迟从8.2ms降至3.7ms; -
Triton Model Analyzer:自动确定最优batch_size与并发数; -
模型预加载(Model Caching):无需等待模型从磁盘加载,KServe与Triton均支持将高频模型预热到GPU内存中。
金融风控低延迟推理SLA保障流程图

四、实战案例:顶级支付处理商的低延迟欺诈检测突围
4.1 场景回顾
一家全球顶级支付处理商,每天处理数十亿笔交易,系统压力巨大:
-
高并发要求:峰值需处理65000笔/秒交易; -
延迟红线:单笔推理延迟必须低于2ms; -
模型迭代慢:训练周期长,新型欺诈模式应对滞后; -
存储成本失控:每张卡的交易历史预计算状态存储成本急剧膨胀。
4.2 破局之策:全栈优化组合出击
-
推理栈优化:从GPU推理全面转向CPU优化推理栈,维持低于1ms延迟同时消除GPU碎片化争用; -
训练效率突破:引入Packing技术(将可变长度序列打包成紧凑批次统一处理),单批次Token数提升80%(训练吞吐量提升1.8倍),消除因GRU填充浪费的80%计算量; -
状态表示精简:设计紧凑的每用户状态表示,磁盘占用与用户规模解耦,避免存储成本失控; -
私有化合规部署:全量部署于本地基础设施,满足严苛的安全合规要求。
4.3 量化成果
-
全年检测欺诈损失增加约2.3亿美元,欺诈捕获率大幅提升; -
单笔交易推理延迟仅为原系统的不到一半; -
CPU优化推理栈在65000笔/秒压力下稳定运行,彻底告别GPU争用导致的SLA击穿隐患。
此次案例表明:金融风控系统的GPU调度,绝非“堆卡”就能解决,需要将资源切分、优先级动态调优、推理引擎深度优化、存储成本治理等一系列技术组合在一起,才能在极端压力下守住每一毫秒的承诺。
五、总结:从“算力洼地”到“产粮高地”
金融风控特别是反欺诈推理场景,对延迟的要求已经到了“不可妥协”的极点。GPU调度已不能停留在整卡锁定的“批发模式”,必须转向支持分层优先级、毫秒级弹性伸缩和引擎级深度优化的新范式。
本文覆盖的核心技术组合包括:NVIDIA Triton推理服务器(生产级可扩展部署)、阿里云cGPU共享技术(内核级GPU虚拟化,MB级切分)、TensorRT推理优化、KServe自动扩缩容,以及智能体的自然语言调度策略定义。
对于正被“高购低用”算力困局和SLA击穿风险困扰的团队,建议从一个小型实时推理集群开始试点:先评估当前GPU利用率和P99延迟基线,引入GPU共享调度技术(MIG或cGPU),为不同任务定义优先级和资源保障策略,再结合Triton动态批处理和KServe自动扩缩容,最后通过运维智能体实现策略的“对话式定义”与自动闭环。算力治理从来不是一锤子买卖,而是为每一毫秒、每一笔交易构建的系统性竞争力。
欢迎加w一起交流:19067272547