 夜雨聆风
夜雨聆风





两套 AI 机器:美国把智能租给世界,中国把智能铺进产业
两套 AI 机器:美国把智能租给世界,中国把智能铺进产业
斯坦福 HAI 的 2026 AI Index 里有两个数字放在一起,会让人很不舒服:2025 年,美国私人 AI 投资是 2858.8 亿美元,中国是 124.1 亿美元;同一份报告又说,截至 2026 年 3 月,中美顶级模型性能差距只剩 2.7%。
23 倍的钱,换来不到 3 个百分点的领先。
这个比例太刺眼,它不是“谁赢谁输”的新闻判断,更像一张底片,把中美两国正在建造的两套 AI 机器显影出来。
美国建造的是一套云端机器。它由 GPU、云厂商、基础模型、API、企业软件、风投和美元资本市场组成。它的商业动作很清楚:把智能打包成服务,按 token、席位、算力小时和企业合约租给全世界。
中国建造的是一套产业机器。它由开源模型、制造业场景、政府牵引、平台公司、工业数据、机器人、终端和本土芯片替代组成。它的动作也很清楚:把智能铺进工厂、汽车、政务、教育、医疗、物流和消费电子,让模型在密集场景里快速折旧、快速迭代。

▲ 中美 AI 两套系统的关键差异:美国更强在算力、资本和全球软件入口,中国更强在场景密度、产业反馈和低价开源。
先给出判断:
美国仍然拥有 AI 的上游定价权,但中国正在用低成本开源和场景密度,持续压低这种定价权的有效半径。
如果只看今天,美国强得离谱。它有最多的钱、最强的模型、最多的数据中心、最深的软件生态和最强的芯片设计公司。可如果把时间拉长到 2030 年,AI 竞争不再只奖励“谁先训练出最强模型”。它会奖励谁能把模型能力转成组织流程、产业反馈、电力系统、标准体系和日常工作流里的复利。
2026 年之后,中美 AI 竞争开始按这套新逻辑运转。
一、美国的机器:把智能做成可租赁的基础设施
美国 AI 的优势并不神秘。它像一台层层叠起来的机器。
最底层是芯片和数据中心。斯坦福 AI Index 统计,美国拥有 5427 个数据中心,数量超过任何其他国家十倍以上;全球 AI 算力容量自 2022 年以来以每年 3.3 倍的速度增长,达到 1710 万个 H100 等效单位。Nvidia 在 2026 财年第四季度的数据中心收入达到 623 亿美元,这个数字已经不像一家传统芯片公司的季度业务,更像整个 AI 时代的电表。
再往上是云。AWS、Azure、Google Cloud、Oracle、CoreWeave、xAI、OpenAI、Anthropic 的数据中心合同把模型训练变成一种金融工程:谁能更早锁定 GPU、HBM、电力、机房和网络,谁就能更早把下一代模型推到市场上。
再往上是模型。OpenAI 在 2026 年 4 月发布 GPT-5.5,Anthropic 发布 Claude Opus 4.7,Google 把 Gemini 3.1 Pro 接入 Deep Research Max,Meta 推出 Muse Spark。这些发布的共同点已经不再是“聊天更聪明”。它们都在争同一个位置:让模型从问答工具变成能操作电脑、调用工具、阅读文件、写代码、做研究、跑流程的工作代理。
斯坦福报告的技术性能章节也能看出这个方向。SWE-bench Verified 的顶级成绩一年内从大约 60% 升到接近满分;OSWorld 这类测试电脑操作能力的 benchmark,AI agent 准确率从大约 12% 升到 66.3%,距离人类表现只差 6 个百分点左右。模型能力的主战场已经从“回答得像不像人”,移到“能不能接活”。
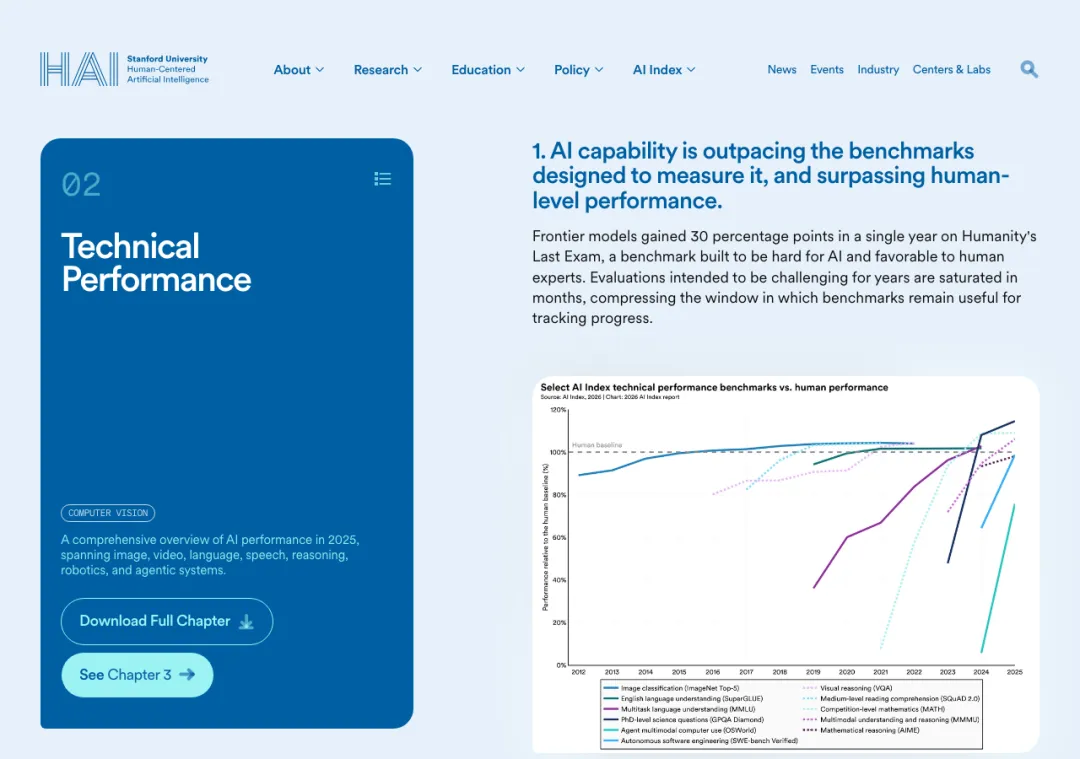
▲ 斯坦福 AI Index 2026 的技术性能章节:前沿模型正在迅速吃掉旧 benchmark,软件工程、电脑操作、长链路任务变成新的主战场。
美国的领先,不能归功于 OpenAI 或 Anthropic 两家公司。它来自一整套把 AI 变成商品的制度。
开发者今天可以打开 Codex、Claude Code、Cursor、Devin、Replit、Windsurf,把一个工程任务拆给模型。企业可以把模型接进客服、财务、法务、销售、数据分析、文档系统。政府可以把模型纳入采购清单,给它写安全条款、供应商要求和合规框架。资本市场会把这些动作折现成市值,再把市值变成下一轮融资和算力采购。
美国的 AI 机器因此形成了一个很强的飞轮:
钱买算力,算力训练模型,模型进入软件,软件提高收入,收入和预期再去买更多算力。
白宫 2025 年 7 月发布的 America’s AI Action Plan 也沿着这条线走。它把政策分成三根柱子:加速创新、建设 AI 基础设施、国际外交与安全。白宫自己说,这份计划列出 90 多项联邦行动;其中一个重点是向盟友输出“全栈 AI 包”,包括硬件、模型、软件、应用和标准。

▲ 白宫 AI Action Plan 的关键段落:美国已经把 AI 写成“全栈出口包”,模型、云、芯片和标准被放在同一张政策表里。
普通科技产业政策解释不了它。它更接近一次“云端帝国”的搭建。
过去,美国把操作系统租给世界,后来把搜索、社交、移动 App、云服务租给世界。现在,它试图把智能本身租给世界。谁使用美国模型、美国云、美国芯片、美国开发工具,谁就把一部分组织流程交给美国技术栈托管。
所以美国政策语言里会反复出现“dominance”“gold standard”“full-stack export”。这些词不只是宣传口号。它们说的是同一件事:AI 时代的标准权不在论文里,也不只在模型榜单里,它在企业每天调用的 API、政府采购清单、开发者工具链和数据中心供电合同里。
美国的微观优势也来自这里。
一个旧金山创业公司的工程师,可以在一天内用 Cursor 或 Codex 改完十几个文件、让 Claude 做代码审查、让 GPT-5.5 跑市场研究、让 Gemini Deep Research 生成行业资料。一个华尔街分析师可以让模型读几百页 K-1 表格和财务报告。一个药企团队可以把模型接入内部实验数据,做候选分子筛选和统计分析。
这些场景看起来分散,其实都在喂同一台机器。每一次企业工作流被模型接管一点点,美国 AI 栈就多拿到一份真实反馈:哪里会报错,哪里需要工具,哪里能省钱,哪里能被法务接受。
这份反馈,比 benchmark 更值钱。
二、中国的机器:把智能铺进密集场景
如果按私人投资、数据中心、前沿闭源模型、云收入来比较,中国明显落后。
但中国的 AI 机器用的是另一套指标。
斯坦福 AI Index 里还有另一组数字:中国在 AI 论文数量、引用、专利授权、工业机器人安装量上领先;美国在高影响力专利和 notable model 数量上领先。2025 年,美国生产 59 个 notable models,中国是 35 个。差距还在,但它和 2020 年前后那种“美国做前沿,中国做应用”的距离已经不同。
DeepSeek-R1 在 2025 年初短暂匹配美国顶级模型,是一个转折点。它给中国 AI 产业提供了一种新的叙事:在芯片受限、资本不如美国、训练成本被质疑的情况下,中国公司仍然可能靠工程效率、蒸馏、MoE、强化学习、开源社区和低价 API 逼近前沿。
到了 2026 年 4 月,DeepSeek V4 继续把这个方向往前推。Hugging Face 的介绍里写得很直接:V4-Pro 是 1.6T 总参数、49B 激活参数,V4-Flash 是 284B 总参数、13B 激活参数,两者都有 100 万 token 上下文窗口。AP 的报道还提到,DeepSeek V4 得到华为 Ascend 芯片和相关技术的兼容支持,这让它在叙事上从“更便宜的模型”,转向“中国本土算力生态也能跑前沿模型”。
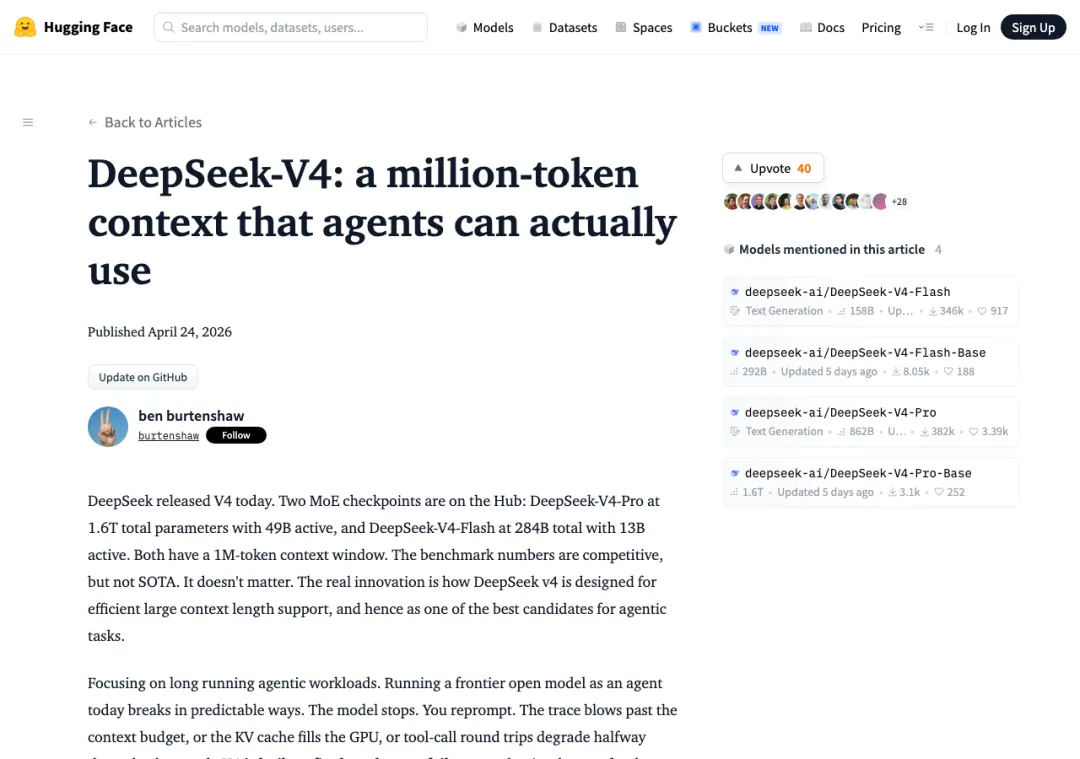
▲ DeepSeek V4 在 Hugging Face 上的介绍页:100 万 token 上下文和 agent 任务优化,是中国开源模型继续逼近前沿的最新信号。
中国这套机器最锋利的地方,不在单个模型发布。它在“场景密度”。
2025 年 8 月,国务院发布《关于深入实施“人工智能+”行动的意见》。文件把 AI 应用推进到六类领域:科技、产业、消费、民生、治理和全球合作。到 2027 年,新一代智能终端和智能体渗透率要超过 70%;到 2030 年,要超过 90%。
2026 年 1 月,工信部等八部门又提出 AI 与制造业深度融合的行动计划:到 2027 年,3 到 5 个通用大模型要在制造业深度应用,形成覆盖重点行业的专用模型,建设 100 个高质量工业数据集,推广 500 个典型应用场景。

▲ CSET 对国务院“人工智能+”行动意见的翻译页。中国政策的关键词,正在从单点前沿转向跨行业渗透、终端和智能体普及。
这些数字很行政化,读起来不像硅谷发布会。但它们说出了中国 AI 机器的底层逻辑。
中国要把 AI 放进已经存在的产业毛细血管里。
中国有全球最完整的制造业门类,有巨量电商、物流、短视频、支付、网约车、自动驾驶、政务和工业互联网场景。它从来不缺需求,麻烦在需求太碎、数据太脏、流程太老、行业 Know-how 太分散。大模型如果只会聊天,在这些场景里价值有限;大模型如果能看图、读表、写代码、接 MES、接 ERP、接机器人控制系统,价值会突然变得具体。
在美国,一个 AI agent 首先像办公室里的白领外包。它写代码、做 research、整理文档、分析合同。
在中国,一个 AI agent 更可能先像车间里的调度员、质检员、客服主管、投放运营、政务窗口助理、直播脚本生成器、自动驾驶车队的后台分析员。
这两种微观位置,会反过来塑造两国模型的性格。
美国模型会更擅长长链路知识工作、企业软件、科学研究、代码库操作。中国模型会更在意推理成本、中文场景、多模态输入、端侧部署、行业低价交付和硬件适配。美国模型被高价值白领流程训练,中国模型被高频低毛利流程打磨。
前者贵,但能卖高价。后者便宜,但迭代快。
这也是中国最强的反击方式。它不一定在每一代模型上超过美国,但它会把模型能力变成价格压力。只要一个中国开源模型能在 80% 的企业任务上达到足够好,美国闭源模型的高价空间就会被压缩一次。
三、芯片战没有结束,它改变了中国的创新姿势
中美 AI 竞争里,芯片是最容易被写成单线故事的部分:美国限制先进芯片出口,中国缺 GPU,所以中国会被卡住。
这个判断成立一半。
训练前沿模型确实需要最先进的 GPU、HBM、先进封装、低延迟网络和稳定供电。美国手里有 Nvidia、AMD、Broadcom、Marvell,有云厂商和数据中心建设能力;先进芯片的关键制造环节又高度依赖台积电。斯坦福 AI Index 直接点出:几乎所有领先 AI 芯片都由台积电制造,全球 AI 硬件供应链因此依赖台湾的一家晶圆代工厂。
美国的上游杠杆就在这里。
但另一半没有那么简单。出口管制不像一堵墙,更像一套会改变水流方向的闸门。
2022 年 10 月之后,美国对中国先进计算芯片和半导体制造设备持续加码。2025 年,美国曾推进 AI Diffusion Rule,又在当年 5 月启动撤销。2026 年 1 月,美国商务部 BIS 调整了对中国和澳门出口部分先进计算芯片的审核政策:Nvidia H200、AMD MI325X 及同等或更低性能芯片,可以在满足条件后从“推定拒绝”变成逐案审查。
条件并不松。联邦公报写得很细:TPP 要低于 21000,总 DRAM 带宽低于 6500 GB/s;出口商要证明美国供应不受影响,不能转移本应用于美国客户的先进制程产能;对中国和澳门的总发货量不能超过同一产品面向美国最终用户发货量的 50%;每批货还要经过美国境内合格第三方测试实验室验证。
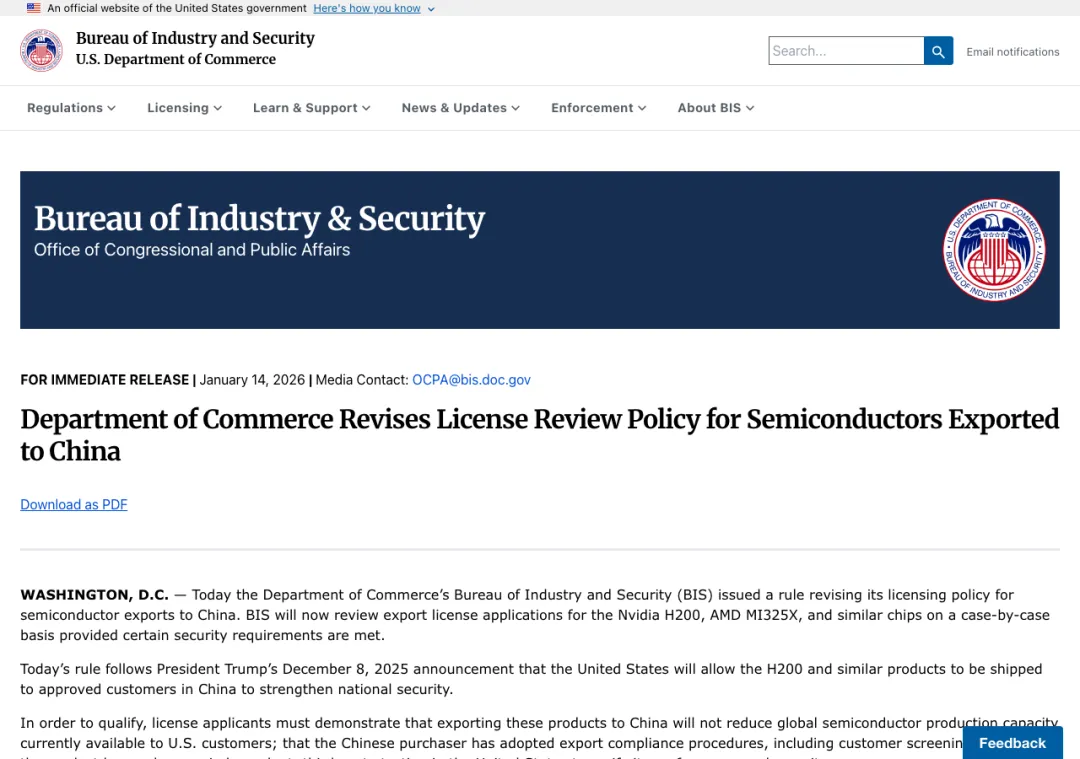
▲ BIS 2026 年 1 月对部分 AI 芯片出口中国的许可审查政策。美国没有完全关闭闸门,但把闸门改成可计算、可审查、可撤销的控制系统。
这套规则背后的意图很清楚:美国既不想让中国拿到最先进算力,又不想把中国市场完全推给华为、寒武纪、沐曦、壁仞和其他国产生态。Nvidia 的商业利益、美国国家安全部门的限制冲动、中国本土替代的政策压力,三者挤在同一个阀门上。
结果很吊诡。
美国越限制,中国越有动力把模型训练和推理转向国产硬件兼容、低显存优化、MoE 稀疏架构、长上下文缓存压缩、低成本推理和开源生态。
DeepSeek V4 对 Huawei Ascend 的支持,象征意义就在这里。它未必说明中国芯片已经追平 Nvidia。它说明中国模型公司开始认真适配一个没有 CUDA 绝对统治权的世界。
这会带来一条分叉路。
美国路线会继续追求最大模型、最强集群、最高性能、最成熟云服务。中国路线会被迫在有限算力里榨效率:更低激活参数、更便宜推理、更强蒸馏、更好的国产硬件适配、更密集的行业落地。
短期看,这是劣势。长期看,它可能形成另一种工程文化。
历史上,技术封锁经常会制造两种结果。它会拖慢被封锁者,也会迫使被封锁者绕开原本的路径。苏联航天、美国冷战时期的半导体军工体系、日本 1980 年代的半导体设备链、中国 2019 年后的手机和芯片替代,都有类似影子。封锁从来不像按钮,它更像压力容器。容器里有没有足够市场、人才和组织能力,决定压力最后是爆炸、泄漏,还是变成新的工艺。
中国 AI 的变量就在这里。
如果国产算力生态无法稳定支持大规模训练和推理,中国模型会长期卡在“够用但不领先”的位置。如果国产硬件、编译器、推理框架、模型架构和行业场景形成正循环,中国会把美国的算力优势折成成本优势和部署速度优势。
这还没有答案。
但 2026 年已经能看出一个趋势:芯片战没有把中国 AI 压回论文时代,它把中国 AI 推向了“效率优先”和“国产栈适配”。
四、模型榜单正在失去解释力
很多人还在用“谁的模型更强”理解中美 AI 竞争。这个问题当然重要,但它的解释力正在下降。
斯坦福 AI Index 说,2026 年 3 月,Arena Elo 排名里,Anthropic 1503、xAI 1495、Google 1494、OpenAI 1481、Alibaba 1449、DeepSeek 1424。前四家美国公司挤在 25 个 Elo 点以内,中国头部模型已经站在同一个高段位区间的下沿。
这并不说明中国已经追平美国所有能力。闭源模型在最难任务、长链路 agent、安全控制、企业级可靠性上仍然占优。OpenAI、Anthropic、Google 的工程体系和产品化能力很难被单个开源模型复制。
模型性能越接近,价格、可部署性、工具生态、数据合规和行业适配就越重要。
对一个银行、医院、工厂、跨境电商团队来说,最强模型未必总是最好的模型。它们关心的问题更具体:
这套模型能不能本地部署?中文合同能不能看懂?一百万次调用多少钱?能不能接内部数据库?出了错谁负责?能不能通过审计?它会不会把数据送到境外?它能不能在国产 GPU 上跑?
这些问题把 AI 竞争从榜单拉回地面。
美国在地面上的优势是企业软件和全球客户。Salesforce、Microsoft 365、Google Workspace、ServiceNow、Adobe、Databricks、Snowflake、Palantir、GitHub,这些系统本来就在企业流程里。美国模型只要接进这些系统,就能吃到大量高价值工作流。
中国在地面上的优势是产业链和应用场景。新能源汽车、光伏、锂电、跨境电商、短视频、本地生活、快递网络、工业园区、智慧城市、政务服务,这些场景并非每一个都高利润,但它们密度高、反馈快、改造空间大。
中美 AI 的下一轮差异,可能不会体现在“谁的模型 IQ 高 5 分”。它会体现在两个更难看的指标上:
一个指标叫毛利率。美国能不能继续维持高价闭源模型和云服务的利润?
另一个指标叫渗透率。中国能不能把足够便宜的 AI 铺到足够多的产业流程里?
美国怕中国的低价,中国怕美国的上游锁定。
这两个恐惧都是真的。
五、两个社会的微观分叉
宏观叙事很容易写得太大。变化会先发生在具体岗位里。
美国的 AI 会优先改造白领工作。软件工程师、律师、咨询顾问、金融分析师、科研助理、市场运营、客服主管、产品经理,会最先和 AI agent 形成新的分工。斯坦福报告提到,组织 AI 采用率在 2025 年继续上升,受访组织中达到 88%;生成式 AI 三年内达到 53% 采用率,速度快过个人电脑和互联网。
但美国也有一个反常识数字:尽管美国在投资和模型发展上领先,它在生成式 AI 采用率上只排第 24 位,为 28.3%。这说明美国的优势更多在供给侧:模型、云、资本、工具、平台。需求侧的全民采用并没有自动同步。
这背后有制度原因。美国企业流程复杂,合规成本高,工会、诉讼、隐私、版权、州法差异都会拖慢部署。美国可以最快发明一个 AI 工具,也可能最慢把它安全地塞进每个行业。
中国的问题反过来。中国可以通过政策、平台和场景把 AI 推得很快,但它要面对另外几类代价:数据质量参差不齐,行业数字化基础不均衡,地方项目容易变成指标工程,内容和安全监管会影响模型开放度,芯片限制会提高高端训练成本,激烈价格战会压缩模型公司的商业耐心。
如果把微观画面拍出来,美国像一个工程师同时管理 5 个 agent:一个改代码,一个查资料,一个写测试,一个修文档,一个做 PR 说明。他的产出提高了,但他也开始从“亲手写代码的人”变成“管理模型劳动的人”。
中国像一个工厂主管把质检、排产、客服、库存预测和设备维护接入模型。单个环节提升不一定惊人,但一条产线、一座园区、一个产业带被连起来以后,AI 会变成生产系统里的新润滑剂。
这两种变化都会带来不平等。
美国的不平等会集中在“谁能管理 agent”。高级工程师、资深律师、懂业务的数据分析师会得到杠杆,初级岗位会被压缩。斯坦福报告里提到,AI 对结构化、可度量工作的生产率提升最大,客服 14% 到 15%,软件开发 26%,市场输出 50%。这类数字听起来温和,但它们进入预算表后,会变成招聘减少、岗位合并和晋升路径变窄。
中国的不平等会集中在“谁有场景和数据”。有工业数据、有供应链、有终端入口、有政务合作、有车队、有医院、有学校的组织会吸收 AI 红利。没有数据、没有数字化基础、没有场景入口的中小企业,会继续在低毛利里挣扎。
AI 不会平均地改变社会。它会先放大已有结构。
美国放大资本、云和专业服务优势。中国放大制造、平台和行政动员优势。
这也是为什么“中美谁领先”这个问题越来越粗糙。两国领先的地方不同,失速的地方也不同。
六、历史给出的纵深:美国继承了冷战机器,中国继承了互联网+机器
AI 的历史早于 ChatGPT。
美国今天的优势,至少可以追到二战后的军工—大学—企业研究体系。DARPA、贝尔实验室、斯坦福、MIT、硅谷、风险投资、半导体、互联网、云计算,构成了一条很长的制度链。2012 年 AlexNet 赢下 ImageNet,只是深度学习重新点燃的时刻;背后更重要的是美国已经有 Nvidia、云计算、开源社区、顶尖高校和全球人才吸引力。
中国的 AI 路径也早于 DeepSeek。2015 年“互联网+”给中国积累了移动支付、电商、物流、短视频、本地生活和工业互联网场景。2017 年《新一代人工智能发展规划》把 AI 写入国家目标。2022 年以后,美国芯片出口管制又把“自立”从口号推成硬约束。
到 2025 年 DeepSeek-R1 出现,中国 AI 产业第一次在全球舆论里拿到一个可传播的反例:便宜、开源、接近前沿。这个反例改变了许多人的心理模型。它告诉市场,前沿能力不一定永远绑定美国高价闭源 API;它也告诉美国政策圈,中国公司可能在限制中找到绕路能力。
2026 年的中美 AI 竞争,就是这两条历史线在同一个时间点相撞。
美国继承了冷战以来最强的科研、资本和技术商业化机器。中国继承了互联网十年堆出来的场景、供应链和行政动员机器。
前者擅长创造上游范式。后者擅长把技术压进规模化应用。
这两种能力在上一轮互联网时代已经交过手。美国创造了操作系统、芯片架构、云计算和移动生态的核心标准;中国创造了移动支付、外卖、短视频、电商和超级 App 的高密度应用。AI 时代的差别在于,模型本身既是上游技术,又会下沉成每个行业的生产要素。
所以这一次,两边都不可能只守自己的传统优势。
美国必须学会把模型落地到能源、制造、政府和实体产业,否则算力支出会变成资本市场越来越难讲的故事。中国必须补上芯片、基础软件、原创科学和全球标准,否则场景优势会被上游许可证和硬件瓶颈反复定价。
谁都没有舒服位置。
七、未来三种远景
到 2026 年 5 月,我更愿意把后面的路拆成三种可能。
第一条路,美国继续保持“云端智能帝国”。OpenAI、Anthropic、Google、Meta、xAI 和云厂商继续领先最强模型。Nvidia、AMD、Broadcom、TSMC 和先进封装体系继续支撑算力扩张。美国通过 AI Action Plan 和全栈出口包,把美国模型、美国云、美国芯片和美国标准卖给盟友与全球企业。
中国仍然能做便宜模型和本土应用,但在最高端训练、科学发现、军用 AI、全球企业软件和标准制定上被美国压住。中国模型成为强大的区域性和开源替代品,却很难成为全球默认层。
第二条路,中国用低价开源和产业场景定义另一个 AI 世界。DeepSeek、Qwen、Kimi、智谱、MiniMax、字节、腾讯、百度、华为云等形成一套足够好、足够便宜、足够可部署的模型生态。国产芯片不必完全追平 Nvidia,只要在推理、行业模型、端侧和机器人场景里足够稳定,就能撑起大量应用。
中国企业把 AI 接进制造、汽车、硬件、消费电子、跨境电商和“一带一路”市场。发展中国家不一定买得起美国高价闭源模型,也未必愿意把数据放进美国云。中国开源模型和本土硬件方案会成为它们的低成本选择。
第三条路,也是我更倾向的一条:世界被切成多层。
最前沿、最高风险、最高资本密度的模型训练,仍然集中在美国及其盟友技术栈里。大规模产业应用、低价推理、开源改造和端侧部署,会出现一个中国强势参与的平行层。中间还有一层混合地带:跨国企业同时用美国闭源模型、中国开源模型、本地私有模型和行业小模型。
AI 不会形成一个统一世界。它更可能像电力、互联网、金融清算和半导体一样,出现多套互相连接又互相防备的基础设施。
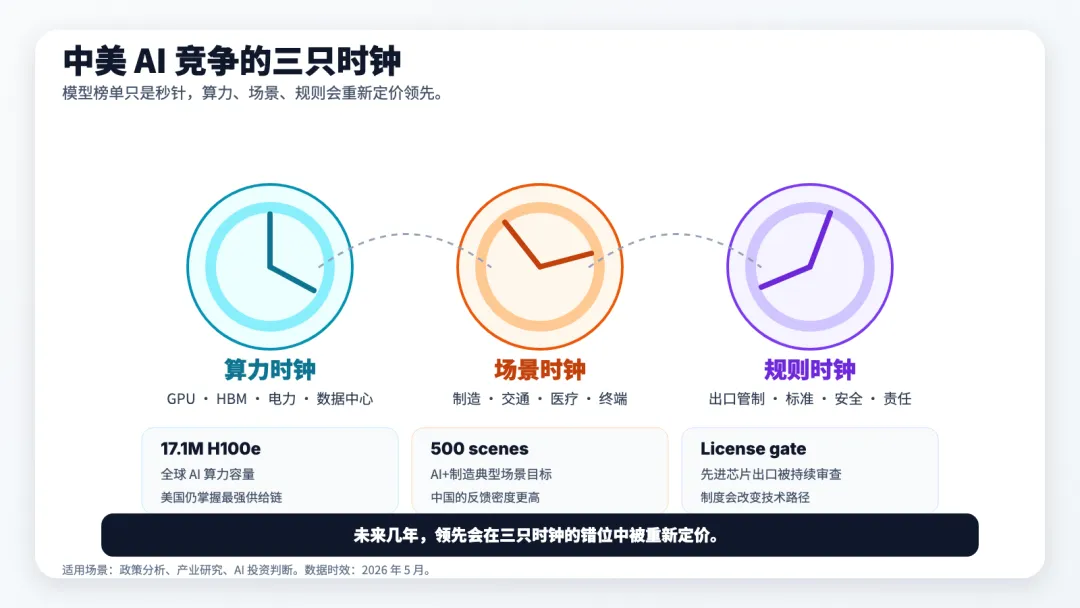
▲ 未来竞争会被三只时钟共同决定:算力、场景、规则。模型榜单只是秒针,基础设施和落地速度会重新定价领先。
在这个多层世界里,模型榜单会退到后面,三个问题会浮到前面。
第一,算力由谁支付。模型越强,越像一座吞电的城市。电力、土地、冷却、水、HBM、先进封装,会持续把 AI 从软件产业拖回物理世界。
第二,模型在哪里落地。一个模型如果只活在发布会和 benchmark 里,它的能力会很快被下一个模型覆盖。一个模型如果进入代码库、工厂、车队、医院、合同系统和政务流程,它会积累别人拿不到的反馈。
第三,反馈数据归谁所有。AI 时代最贵的东西,可能会从训练语料转向另一类燃料:模型在真实任务中犯错、修正、重试、被人类接管、最后成功的全过程记录。谁拥有这些轨迹,谁就拥有下一代模型最难买到的燃料。
这三个问题,比“中美谁领先”更耐用。
尾声:领先会被重新定价
2026 年的 AI 竞争有一个残酷之处:领先不再是一个静态位置。
美国今天确实领先。它的模型、资本、云、芯片和全球软件生态,仍然是世界上最强的一套组合。任何轻率宣布“中国已经超过美国”的说法,都经不起数据。
但美国领先的价格正在变高。算力越来越贵,数据中心越来越难建,能源越来越紧,监管越来越碎,模型能力越强越需要安全闸门。领先不再只是训练一个更大模型,还要维持一整套高压基础设施。
中国今天确实受限。芯片、基础软件、原创科学、全球企业市场和高端人才流动,都有明显短板。任何轻率宣布“开源低价会自动赢”的说法,也经不起现实。
但中国受限的方式正在塑造它的 AI 路径。低成本、开源、国产硬件适配、产业场景和政府牵引,会把中国 AI 推向另一种竞争力。它未必总是优雅,未必总是前沿,却很难被忽视。
中美两国正在建造的,远远超过两家公司,也远远超过两组模型。
它们在建造两套把智能接入社会的机器。
美国的机器把智能变成云端租赁品。中国的机器把智能变成产业渗透剂。
未来几年,最值得看的不再是哪一边喊得更响,焦点会落到哪一台机器先在自己的短板上卡住。
如果美国的算力支出无法持续兑现收入,它的领先会被资本市场重新定价。
如果中国的国产算力和产业数据无法形成闭环,它的追赶会被工程现实重新定价。
AI 竞争最后可能不会有一个简单的冠军。
它会留下一个更冷的世界:每个国家、每家公司、每个人,都要选择自己接入哪一套智能基础设施,并承担那套机器背后的价格、规则和风险。
资料来源与时效
数据时效:2026 年 5 月。强时效数据以来源发布时间为准。
-
Stanford HAI, The 2026 AI Index Report -
Stanford HAI, 2026 AI Index — Economy -
Stanford HAI, 2026 AI Index — Research and Development -
Stanford HAI, 2026 AI Index — Technical Performance -
The White House, America’s AI Action Plan -
The White House, Promoting The Export of the American AI Technology Stack -
U.S. Bureau of Industry and Security, Semiconductor Export License Review Policy to China -
Federal Register, Revision to License Review Policy for Advanced Computing Commodities -
State Council / CSET translation, Opinions on Deepening the Implementation of the “Artificial Intelligence+” Initiative -
State Council English site, China issues guideline to accelerate “AI Plus” integration -
State Council English site, China aims for secure, reliable supply of AI core tech by 2027 -
Hugging Face, DeepSeek-V4: a million-token context that agents can actually use -
AP News, China’s DeepSeek rolls out a long-anticipated update of its AI model -
OpenAI, Introducing GPT-5.5 -
Anthropic, Introducing Claude Opus 4.7 -
Google, Introducing Deep Research and Deep Research Max -
NVIDIA Investor Relations, FY2026 Q4 Financial Results