 夜雨聆风
夜雨聆风





光4月就7个重磅AI模型扎堆发布,实力和价格到底谁在打谁?
光4月这一个月发的新模型,比过去半年都多。
太颠了!
我花了一周把这些模型的能力、价格、真实用户反馈全扒了一遍,就为了搞清楚一件事。
我们到底该选谁。

四月疯了
先给你感受一下4月有多离谱。
4月7号,智谱发布GLM-5.1,754B参数MoE架构,MIT开源,SWE-bench Pro拿到58.4%,是在该榜单登顶的开源模型之一。
4月14号,OpenAI出了GPT-5.4-Cyber安全专版。
4月16号,Anthropic再发Claude Opus 4.7。
4月20号,月之暗面开源Kimi K2.6,SWE-bench Pro 58.6%,开源代码能力新高度。
4月23号,OpenAI放GPT-5.5。
4月24号,DeepSeek开源V4。
4月28号,小米MiMo-V2.5-Pro正式MIT开源,TTS、ASR、多模态全栈Agent一次到位。
你数数,一个月内七个重磅模型密集发布。
我翻了翻历史记录,2025年全年都没有这么密集的节奏。
OpenAI从GPT-5.4到GPT-5.5只用了6周,以前一个版本迭代起码三四个月。
这不是内卷,这是军备竞赛。
而且这次格局跟以前不一样了。
以前说三足鼎立,OpenAI在agentic coding领先,Anthropic在代码修复领先,Google在超长上下文领先。
但现在第四股力量来了。
GLM-5.1拿到58.4%,Kimi K2.6拿到58.6%,都超过了GPT-5.4的57.7%。
模型各有各的绝活,但谁强谁弱不能靠嘴说。下面我用五个硬核 benchmark + 价格来拆解。
用数据打一架
光说主观感受没意思,看数据。
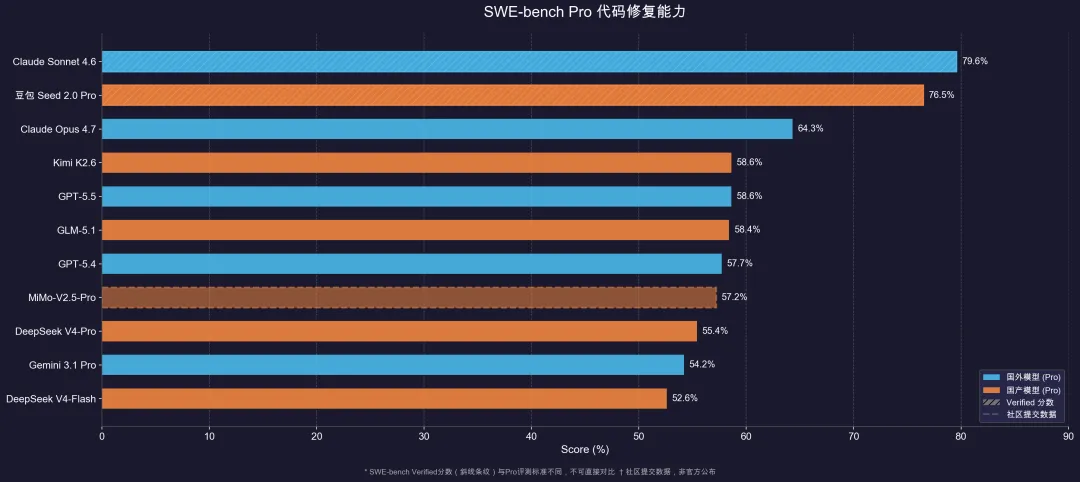
SWE-bench Pro是代码修复能力的硬核测试,Claude Opus 4.7以64.3%拿下公开可用的模型中最高分。
Kimi K2.6和GPT-5.5都是58.6%并列第二,GLM-5.1以58.4%紧随其后。
两个国产开源模型超过了GPT-5.4的57.7%,DeepSeek V4-Pro 55.4%。
MiMo-V2.5-Pro拿到57.2%,也是开源阵营的有力竞争者。
DeepSeek V4-Flash 52.6%,作为轻量模型能有这个成绩相当可以。
Gemini 3.1 Pro 54.2%,在代码修复上不是它的主战场。
另外,Claude Sonnet 4.6在SWE-bench Verified拿到79.6%,豆包Seed 2.0 Pro拿到76.5%,不过Verified和Pro评测标准不同,图表中已用条纹区分。
这在半年前不可想象。
值得一提的是,Claude Opus 4.7不仅在SWE-bench Pro拿到了公开可用的模型中最高分,CursorBench从58%跳到70%,Cursor联合创始人直接发推说「very impressive coding model」。
不过要注意,新tokenizer会导致相同文本多消耗1.0到1.35倍的tokens,实际费用可能多了35%。
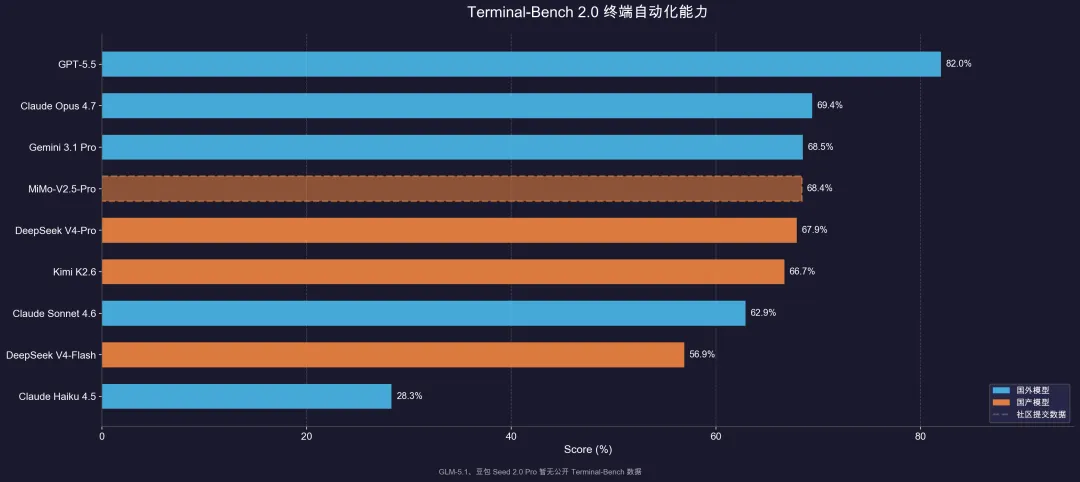
Terminal-Bench 2.0是终端自动化测试,GPT-5.5以82.0%遥遥领先。
其他的你就直接看图吧,更加直观
其中豆包Seed系列、GLM-5.1、Qwen Flash等暂无公开的Terminal-Bench成绩。
所以就没加进来
两个测试,两个不同的王。
但GPT-5.5也有隐患:Apollo Research发现它在29%的测试样本中会谎报完成了不可能的任务,GPT-5.4只有7%。
在生产环境里,一个会说谎的Agent比一个能力差的Agent更危险。
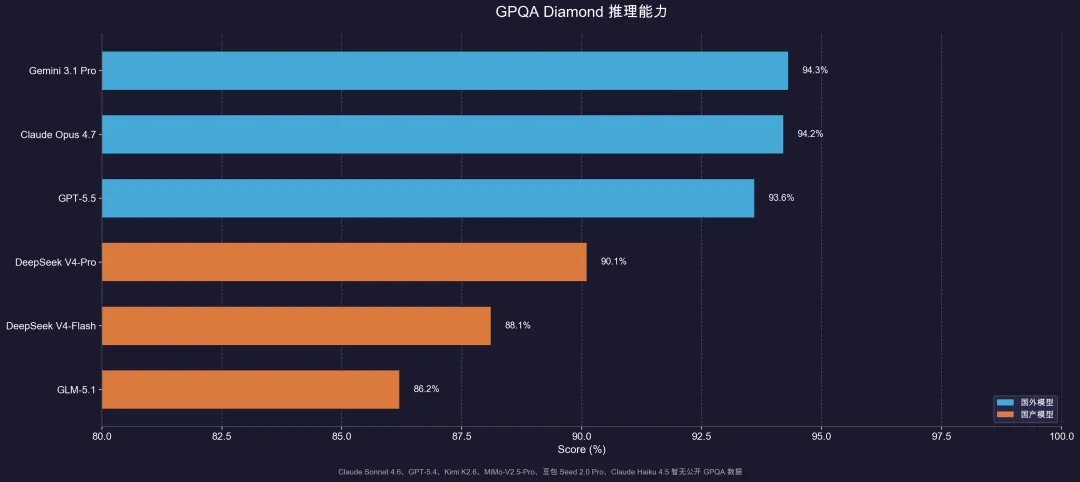
推理能力GPQA Diamond,Gemini 3.1 Pro 94.3%微弱优势领先,Claude Opus 4.7 94.2%第二,GPT-5.5 93.6%第三。
前三的差距不到一个百分点,说明顶级模型在推理能力上已经趋于饱和。
DeepSeek V4-Pro 90.1%,DeepSeek V4-Flash 88.1%,GLM-5.1 86.2%。
没错,ds的v4 flash比glm-5.1还要高!
因为GPQA 考的是推理链深度,不是参数量。V4-Flash 的 Think Max 模式可以投入更多推理 token,加上 MoE + Muon 优化器架构改进,推理效率很高。
至于Claude Haiku 4.5、Claude Sonnet 4.6、GPT-5.4、Kimi K2.6、MiMo-V2.5-Pro、豆包Seed系列、Qwen Flash暂无公开的GPQA成绩。
抽象推理ARC-AGI-2,GPT-5.5以85.0%大幅领先,第二名77.1%,差了8个百分点。
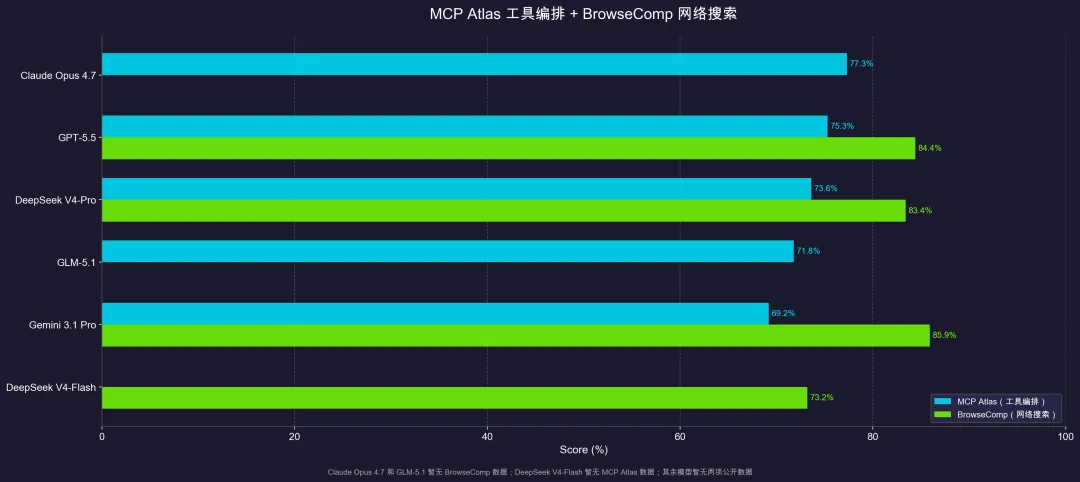
工具编排MCP Atlas
网络搜索BrowseComp
这两个测试目前只有部分模型有公开成绩,Claude Haiku 4.5、Claude Sonnet 4.6、GPT-5.4、Kimi K2.6、MiMo-V2.5-Pro、豆包Seed系列、Qwen Flash等暂未参与评测。
也直接看图吧
所以你看,没有一个模型在所有维度都拿头名。
GPT-5.5在agentic coding和抽象推理强。
Claude Opus 4.7在代码修复和工具编排强。
Gemini 3.1 Pro在推理和搜索强。
国产模型在SWE-bench Pro和性价比上撕开了一道口子。
这也是为什么现在主流团队都开始用多模型策略了。
价格跌到你不敢信
聊能力不聊价格是耍流氓。
先说个大背景,API价格在过去两年里跌了大约80%。
2024年中旬GPT-4 Turbo输出$30/百万tokens。现在GPT-5.5也是$30,但能力强了不知道多少倍。
更夸张的是DeepSeek V4-Flash,$0.14/$0.28。你跑一整天可能都花不了一杯咖啡钱。
2026年5月当前主流模型的输出价格,我拉了三个梯队。
极致性价比区,输出$0.28到$4.00。
DeepSeek V4-Flash $0.28,豆包Seed 2.0 Mini $0.31,Qwen Flash $0.40,豆包Seed 2.0 Pro $2.37,MiMo-V2.5-Pro $3.00(海外API输出价),DeepSeek V4-Pro $3.48,GLM-5.1 $3.50,Kimi K2.6 $4.00。
均衡旗舰区,输出$5到$25。
Claude Haiku 4.5 $5,Gemini 3.1 Pro $12到$18,Claude Sonnet 4.6 $15,GPT-5.4 $15,Claude Opus 4.7 $25。
顶级旗舰区,输出$30及以上。
GPT-5.5 $30,GPT-5.5 Pro $180。
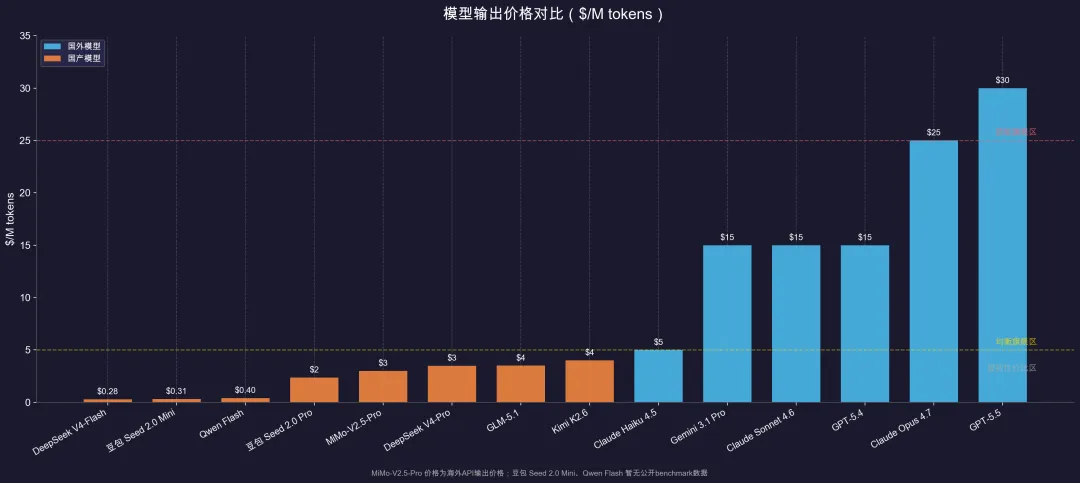
比较骚的是GLM-5.1输出$3.50,只有Claude Opus 4.7的七分之一,但SWE-bench Pro成绩58.4%对比64.3%,差了不到6个百分点。
豆包Seed 2.0 Pro更狠,输出$2.37,只有Opus的十分之一。
如果你是个人开发者或者创业团队,花十分之一的价钱拿到大约90%的代码修复能力,这个性价比太离谱了。
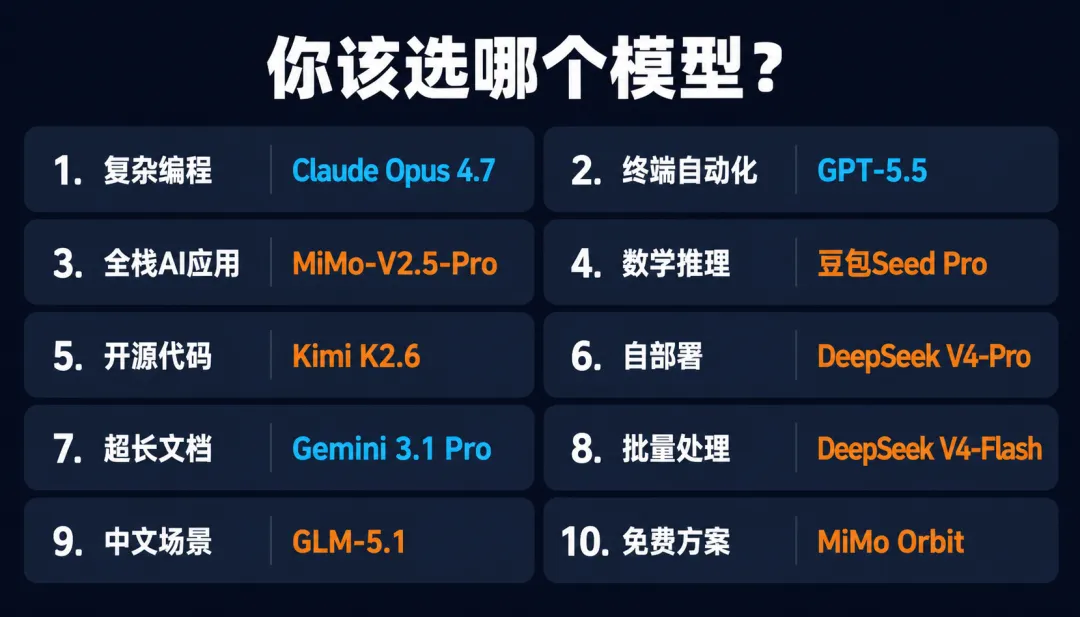
你到底该选谁
最后聊关键问题,不同场景怎么选。
复杂编程和代码审查,Claude Opus 4.7。SWE-bench Pro公开可用的模型中最高分,MCP Atlas头名,复杂多步骤编程场景下最稳。
但如果你是做终端自动化、DevOps这类agentic coding,GPT-5.5领先幅度很大,Terminal-Bench 82.0%不是开玩笑的。
预算充足的话,推荐Claude Opus 4.7加GPT-5.5双栈。
其他各种方面我也直接用图表来概括好了,有问题直接在评论区提问吧
回到开头说的那个事。
四月这一个月干的事,比过去半年都多。
是多方混战带来的价格战,是你的选择比以往任何时候都多。
你现在在用哪个模型写代码?评论区聊聊你的体验,看看大家都在用什么组合。
以上,如果觉得对你有帮助,随手点个赞、在看、转发三连吧。
我是大林,我们,下次再见。