 夜雨聆风
夜雨聆风





LUMS提出AI无悔学习框架:LLM引导智能聚类实现最优资产配置
关注「AI大模型时代资产增值与市场前瞻」
核心发现:该框架将大语言模型与在线学习理论结合,通过CNN恐惧与贪婪指数过滤和LLM驱动的行业对冲机制,构建低频季度再平衡策略,在51个行业ETF组成的投资宇宙中实现显著的风险调整后收益优势,最大回撤仅为16%远低于SPY的34%。
Regret-Driven Portfolios: LLM-Guided Smart Clustering for Optimal Allocation
Muhammad Aarash, Hassan Jaleel | Lahore University of Management Sciences
arXiv: 2601.17021
为什么传统投资组合难以超越被动指数基金?
在过去十年中,仅有约6.6%的对冲基金在名义收益率上超越了标准普尔500指数,这一数据深刻揭示了主动投资策略面临的巨大挑战。沃伦·巴菲特在2007年发起的著名赌注最终以指数基金85.4%总收益对对冲基金22%收益的压倒性优势获胜,迫使投资界重新审视主动选股策略的有效性。然而名义收益率仅是投资表现的一个维度,机构和个人投资者更关注风险调整后的收益表现,尤其是在养老金和退休基金等需要严格下行保护的场景中。如何在不承担过度风险或频繁交易的前提下实现优越收益,成为量化金融领域的核心难题。传统均值方差框架虽然提供了理论基础,但在适应市场动态变化方面存在根本性局限。更为关键的是,在全球低利率环境和地缘政治不确定性加剧的背景下,传统的资产配置模式面临着前所未有的挑战。投资者需要在收益率压缩的环境中寻找超额回报来源,同时还必须应对日益频繁的市场冲击和政策不确定性。
传统投资组合优化的理论基础可追溯至Markowitz均值-方差框架,后续发展出均值绝对偏差、条件风险价值等替代性风险度量以及稳健优化方法。然而这些静态方法本质上无法根据数据流动态调整策略,在线投资组合优化框架特别是无悔算法通过渐近匹配最优恒定再平衡组合来克服这一局限。深度学习和强化学习方法虽然灵活但常缺乏可解释性且易过拟合,行为金融学揭示的遗憾厌恶和长赌偏好等偏见进一步驱动了对内建风险控制策略的需求。近年来大语言模型的突破使得从文本中提取高层次情绪信号成为可能,但大多数应用仍以启发式方式与优化引擎松散耦合。
在线投资组合优化框架中,Universal Portfolio和Hedge算法已证明渐近匹配最优恒定再平衡组合的可能性。然而大多数现有方法仅关注累积收益率而非夏普比率或卡尔玛比率等风险调整指标,这对于风险敏感型投资者而言是重大缺陷。本文方法在此文献基础上,通过在无悔学习框架内显式优化风险感知目标(如夏普比率和卡尔玛比率),将自适应性与稳健性相结合,同时融合行为金融信号以构建一种既有理论保障又有实际可操作性的资产管理框架,为低频资产管理开辟了新路径。具体而言,无悔学习算法能够在不依赖精确市场预测的前提下实现近似最优配置,这一特性对于实际投资管理具有重要意义——在市场预测本质上不可靠的认知前提下,无悔学习提供了一种更为务实和鲁棒的投资决策范式。
LLM如何指导投资组合的无悔学习策略?
本文提出的LLM引导无悔投资组合配置框架将投资组合构建建模为序贯决策问题,采用无悔在线学习原则来自适应平衡收益与风险。该策略学习最小化相对于事后最优静态投资组合的遗憾,确保策略表现逐渐逼近最优基准。搜索空间被约束为围绕多元化基准的增量调整,既保留广泛配置可能性又限制极端偏移。整个框架包含四个核心组件:数据准备模块负责处理缺失数据和退市资产、情感过滤模块利用CNN恐惧与贪婪指数作为二元门控决定是否再平衡或全部清仓、LLM模块解读情绪趋势提出板块级对冲建议、遗憾引导配置模块执行受FTL启发的再平衡。
在博弈论框架中,投资组合优化被建模为单智能体博弈,智能体在每个时间步选择n维资产配置向量,每个权重满足非负性和归一化约束。遗憾引导学习目标确保智能体累积表现接近事后最优固定决策。候选行动集通过结构化扰动方法生成:以现有配置为基线,在预定义区间内修改单一资产配置权重同时调整其余权重保持可行性。这种方法在有效配置单纯形内进行高效搜索并确保预算和配置约束的满足。关键设计参数包括最小和最大配置限制用以强制多元化、回望窗口k用于评估候选配置的历史表现以及再平衡频率。
在LLM集成方面,框架利用动态聚类和伪对冲两种机制。动态聚类利用12个月恐惧与贪婪时间序列数据向LLM提问推荐最有前景的三个行业板块,每次提示重复五次取最频繁推荐的板块以缓解输出方差。伪对冲在动态聚类后执行,LLM被提示为每个选定板块建议互补性对冲板块,研究避免了股票级别对冲以防止LLM对高频提及股票的偏见。恐惧与贪婪指数过滤包含上界、下界和差值有界三种机制,限制再平衡仅发生在情绪可接受的市场体制中,若当日无过滤条件满足则投资组合可选择全部转为现金以限制风险敞口。
从实现细节来看,指数加权机制决定了资产收益在回望窗口内的聚合方式——启用时近期日收益获得更高权重以更好反映最近市场趋势,禁用时则在窗口内均匀加权。百分位过滤通过排除极端表现者来平滑收益——资产按历史表现排名,仅保留可配置百分位范围内的资产。该框架的自定义回测框架在每个再平衡日期模拟投资组合清算和重新配置,跟踪每日投资组合价值直到下一个再平衡日期,并采用灵活的费用模型支持按份额和百分比交易成本,在每个再平衡日扣除费用以模拟真实交易条件。
从历史演进的视角来看,投资组合管理经历了从基本面分析到量化投资再到AI驱动决策的根本性变革。早期的量化方法主要依赖于统计套利和因子模型,虽然在特定市场条件下表现出色,但在市场结构发生根本性变化时往往失效。随着大数据技术和人工智能的迅猛发展,投资管理行业正面临一场深刻的范式转变——如何将海量非结构化信息转化为可执行的投资信号,如何在复杂的市场环境中实现自适应的动态配置,以及如何在追求收益的同时有效控制尾部风险。这些问题的回答需要跨学科的方法论创新,将计算机科学中的最新进展与金融工程的核心理论相融合。本文的研究正是在这一交叉领域做出了重要贡献。
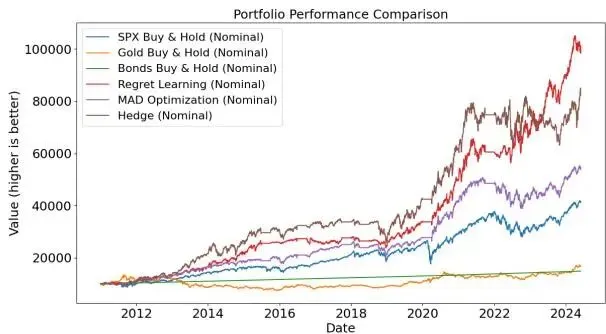
▲ 图1:无悔学习策略在行业ETF资产宇宙中显著超越买入持有基准
实验资产宇宙如何构建?
研究构建了两个不同复杂度的资产宇宙来评估方法的泛化性。第一个COCKROACH宇宙由现金、黄金、10年期美国国债和SPY ETF四种资产组成,回测期间为2000年1月至2024年5月,涵盖多个经济周期。第二个行业ETF宇宙包含代表20个经济板块的51个ETF辅以现金、黄金、10年期债券和SPY,回测期间为2011年1月至2024年5月。数据预处理流程严格处理了非统一上市持续时间的问题,包括移除通用非交易日、标记资产进入和退出日期、前向填充间歇性缺失值,退市资产被清仓并列入黑名单。
评估体系采用六项核心指标:年化收益率衡量平均年度收益、波动率指示总风险、夏普比率衡量单位波动率风险调整收益、索提诺比率衡量单位下行波动率风险调整收益、最大回撤捕捉最大峰谷跌幅、卡尔玛比率为年化收益除以最大回撤。基准比较对象包括SPY买入持有、10年期国债买入持有和黄金买入持有策略,以及在线均值绝对偏差方法和Hedge乘法权重算法。这些指标共同提供了全面的风险收益评估维度。
网格搜索实验系统性地探索了多种参数组合对策略表现的影响。搜索维度包括优化目标选择(收益率、夏普比率、卡尔玛比率、索提诺比率)、再平衡频率(季度和年度)、板块聚类方式(全部板块或LLM动态聚类)、恐惧与贪婪阈值设定、回望窗口长度以及是否启用LLM对冲机制。每种配置的表现均通过上述六项指标进行综合评估,结果汇总在详细的性能对比表中。这种系统性实验设计确保了研究结论的全面性和可靠性。
策略表现的关键影响因素是什么?
实验发现再平衡频率是最关键的因素之一:所有超越SPY的配置中71%采用季度再平衡,表明中期市场趋势以数月为周期持续。季度再平衡在响应市场变化和避免过度交易之间达成理想平衡。在优化目标方面,约50%的跑赢SPY配置以纯收益为目标,但最高质量绩效来自夏普或卡尔玛比率优化。不使用百分位过滤通常获得更高夏普比率,表明更广泛的资产宇宙提供了更大的再平衡灵活性和多元化机会。
在LLM增强实验中,动态板块选择未能超越完整资产宇宙——累积收益和夏普比率分别平均低34%和37%。然而LLM对冲机制带来显著改善:结合动态聚类时夏普比率平均提高31%,季度再平衡下甚至达63%。这表明LLM虽在高收益板块识别上有限,但能有效定位互补性对冲板块增强稳健性。回望窗口长度也至关重要——启用动态聚类时120天窗口比10天窗口夏普比率高17%。
恐惧与贪婪指数的应用提供了额外风险控制维度。5天内20个点绝对变化的阈值在过滤短期噪声和保留适时调整间达到最佳平衡。绝对水平约束方面,阻止指数低于10或超过90时的交易能最优平衡市场参与与回撤保护,更严格约束则因错过高动量机会而降低收益。这些发现表明适度暴露于极端情绪体制在配合有效风险管理时可以是有利的。
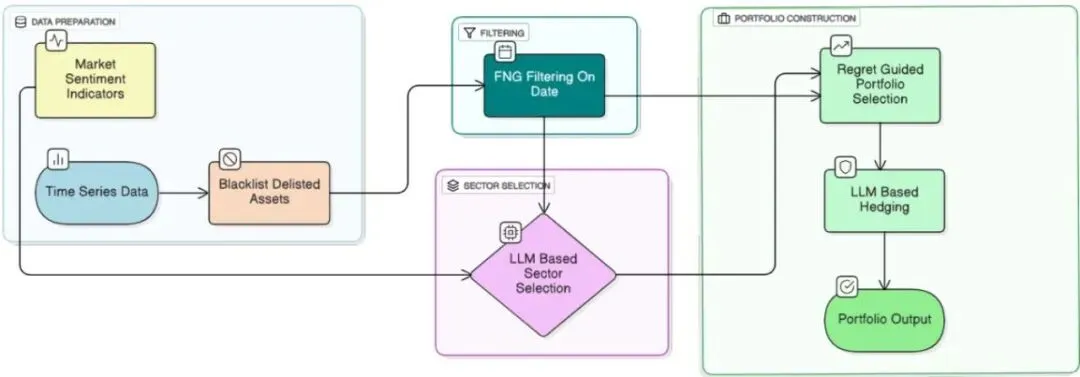
▲ 图2:框架四大模块:数据准备、情感门控、LLM对冲与遗憾驱动配置
COCKROACH宇宙中表现如何?
在仅由四种资产组成的COCKROACH宇宙中,NRL策略总收益略超SPY和黄金且增长轨迹更平稳。这证明模型充分利用了SPY内含的广泛多元化优势——SPY本质上包含具有坚实基本面的强势企业篮子,结合黄金等非相关资产即可以显著更低波动率交付类似股票的收益。该策略在此极简配置中的稳健性验证了无悔学习框架在基础层面的有效性。从风险管理角度来看,策略在2020年新冠疫情引发的市场崩盘和2022年通胀冲击导致的持续下跌中均表现出较强的防御能力,证明了其在极端市场条件下的适应性。
波动率和回撤统计进一步证实了策略的风险控制能力。NRL策略不仅获得了优越的收益表现,其波动率略低于基准且最大回撤显著更小。这种在仅四种资产极简配置中的稳健风险控制为更复杂资产宇宙的应用奠定了基础,对需要简单但有效资产配置策略的养老金和退休基金等机构投资者具有重要实践指导意义。
从方法论视角分析,COCKROACH宇宙的测试结果特别有价值因为它证明NRL框架的核心优势不在于资产数量多寡而在于自适应配置机制的有效性。即使资产选择极为有限,框架仍能通过动态调整配置权重捕捉市场趋势并控制下行风险。这一发现也表明该方法可以推广到其他资产有限但需要动态管理的投资场景中去。
进一步的分析表明,在COCKROACH宇宙中NRL策略的成功主要归因于其对市场体制转换的敏感识别和及时响应。当市场进入高波动率状态时,策略能够迅速将权重转移到黄金和国债等避险资产,有效避免了股票市场的大幅回撤。而当市场恢复正常时,策略又能适时增加风险资产的配置以捕获上行收益。这种动态的资产配置能力是传统静态策略所不具备的,也是无悔学习框架相比于简单再平衡规则的核心优势所在。
行业ETF宇宙有何突破?
在更广泛的行业ETF宇宙中NRL策略显著超越SPY基准:累积收益+68.6%、夏普比率+119%、卡尔玛比率+262%。最大回撤仅约16%远低于SPY的34%,突显了NRL在缓解下行风险同时捕获上行收益的能力。最优配置(卡尔玛目标、季度再平衡、全板块、10-90恐惧贪婪阈值)实现了18.91%年化收益率、1.03夏普比率和0.16最大回撤。
与其他方法的对比中NRL也表现优异:在线MAD获得13.56%收益率和0.74夏普比率,Hedge算法虽达17.09%收益但波动率和回撤均高于NRL最优配置。SPY基准仅11.21%年化收益和0.47夏普比率。黄金表现更弱仅3.91%收益和0.06夏普比率。这些比较充分验证了无悔学习原则与LLM情绪信号结合在中低频资产管理中的实际经济价值。
值得注意的是LLM对冲在行业ETF宇宙中的增益尤为明显。当结合动态聚类和季度再平衡时,LLM对冲配置的夏普比率相对非对冲配置提高了63%。这说明在更广泛的资产宇宙中LLM识别互补性板块的能力得到了更充分的发挥。该结果为构建基于AI的低频资产管理系统提供了重要的实证支持。从实践角度看,这种结合策略特别适合管理规模较大、换手率要求较低的机构投资组合,如养老金基金和大学捐赠基金,因为它能够在有限的交易频率内实现显著的风险调整后超额收益。
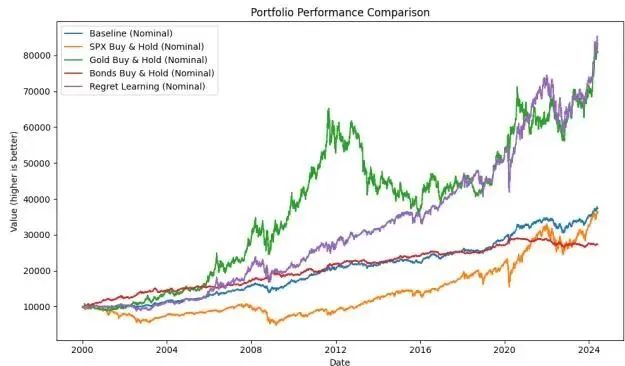
▲ 图3:COCKROACH资产宇宙中策略的稳健表现
研究存在哪些局限?
主要局限在于优化目标与实际表现之间的不确定关系——优化卡尔玛比率的配置经常产生最高收益,这在直觉上矛盾因为卡尔玛强调回撤缓解而非绝对表现,为终端用户引入了不确定性。另一约束是对固定频率再平衡的依赖,在剧烈波动或结构性转变期间可能不理想。未来可探索事件驱动再平衡机制以提高对不利条件的响应能力。
LLM角色被有意限制在对冲功能上。虽然LLM在识别风险对冲敞口方面展现实用性,其在更精细资产级别决策方面的潜力未充分开发。鉴于低频再平衡约束LLM微观级别应用测试有限。未来可探索实时新闻情绪解读以动态调整板块权重或根据展开事件调整配置等更精细用途。此外框架对LLM输出的依赖也引入了模型选择和提示工程方面的额外不确定性。
从数据和方法论角度看,该研究仅在美国市场的ETF资产上进行了验证,其在其他市场(如新兴市场或亚洲市场)和其他资产类别(如个股或另类资产)上的适用性有待进一步检验。此外无悔学习算法的理论保证基于特定的数学假设,在实际市场中这些假设可能无法完全满足。未来研究需要在更广泛的市场环境中验证框架的稳健性和可迁移性。
该研究对量化投资有何启示?
本文引入了无悔学习与LLM智能聚类对冲相结合的新型投资组合优化策略,实证表明该集成框架在各种市场条件和资产宇宙中显著优于买入持有基准。核心创新在于将在线学习自适应性与LLM语义理解能力融合,构建了既有理论保障又有实际可操作性的资产管理框架。对机构投资者而言季度再平衡的有效性表明中低频策略在实际操作中具有显著优势。
从技术发展前景看,框架展示了传统量化方法与新兴AI技术结合的可行路径。随着LLM能力提升和金融数据日益丰富,这类混合方法有望在ESG投资、另类资产配置和跨市场策略等更广泛场景中发挥作用。特别是LLM辅助的投资组合构建在整合非结构化信息和生成互补性投资建议方面展现了巨大潜力,可能为投资管理行业带来变革性影响。
综合而言该研究的最大贡献在于证明了将经典金融理论(无悔学习、投资组合优化)与前沿AI技术(大语言模型、情绪分析)结合的可行性和经济价值。无悔更新与轻量级情绪条件化相结合能够产生持续超越标准基准的投资组合,这为将在线学习与行为信号集成到实际低频资产管理中开辟了新途径。未来的研究方向包括事件驱动再平衡、更精细的LLM应用以及跨市场验证等。
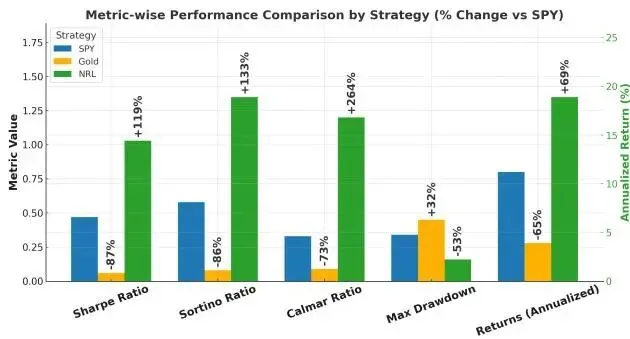
▲ 图4:NRL多指标综合表现对比SPY基准
论文信息
arXiv: https://arxiv.org/abs/2601.17021
参考文献:Muhammad Aarash, Hassan Jaleel. Regret-Driven Portfolios: LLM-Guided Smart Clustering for Optimal Allocation. arXiv:2601.17021.