 夜雨聆风
夜雨聆风





深入剖析Gemma 4 MoE架构源码

0 前言
近几年,MoE架构的模型几乎都被贴上了”又快又便宜”的标签。MoE 全称是 Mixture of Experts,即混合专家。它的目标很明确,稠密 Transformer 里每生成一个 token,模型都要让所有参数全部跑一遍,就本地推理而言,这件事在 70B 这一档上算力负载已经非常严重,而几百 B 的尺度更是痴人说梦。但你要是真的去看一个 token 的推理过程,又会发现这些参数里大部分压根没派上用场,比如生成”今天天气”这种日常表达时,模型其实只用到了”通用语言”那一小块能力,像代码、数学、形式逻辑等参数完全是闲置的。MoE 的思路就是把 FFN 切成一组组小的”专家”,前面挂一个轻量的”路由器”,让它根据当前 token 决定只激活其中几个。这样一来,模型的总参数量没缩水,但每次前向真正动用的参数(算力)只是其中很小一部分。把”知识容量”和”算力成本”这两件事第一次解耦开来,这是 MoE 真正牛x的地方。
Gemma 4 26B-A4B 这个模型,总参是 25.2B,激活参数 3.8B,每层 128 个路由专家推理/训练时只挑 8 个组队,再外加一条永久激活的 dense MLP,每生成一个 token 实际只动用 4B 的算力。换句话说,它把 MoE 这套”容量与算力解耦”的思路推到了一个相当极致的状态。本文的目的,就是深入剖析 26B-A4B 中关于MoE的实现原理。
在此大家需要注意,Gemma 4 的 PyTorch 源码,官方并没有放出来。Google DeepMind 在 `google-deepmind/gemma` 这个仓库里公开了 JAX 实现,但那一份绑死在 TPU 训练栈上;他们另一个 `google/gemma_pytorch` 仓库到现在只支持到 Gemma 3,里面的 `Architecture` 枚举根本没给 Gemma 4 留位置;技术报告也写着 “Coming soon”,至今没发。PyTorch 这边想跑 Gemma 4,就得有人照着 JAX 实现、模型卡、加上 safetensors 权重的命名约定,把整套前向传播在 PyTorch 里重写一遍。这件事是 vLLM 团队联合 HuggingFace 团队做的,`vllm/model_executor/models/gemma4.py` 这份 1718 行的源码,文件头版权写的就是这两家,整份代码用的全是 vLLM 自家的 `FusedMoE`、`GateLinear`、`RMSNorm`,加上 TP / EP 切分接口和一个专门为 router 写的 Triton kernel,是一份和 Gemma 4 权重严格对齐的 PyTorch 重实现。
1 MoE 在 DecoderLayer 里的位置
读 MoE 源码最容易踩的第一个坑,是带着”MoE 就是把 FFN 替换成一组专家”这个先入为主的印象进去。Mixtral 是这么做的,它把每一层 Transformer 里的 FFN 整个换成 8 个专家加一个 router,FFN 这条路径就此消失。但 Gemma 4 不是这样。在 Gemma 4 的每一个 MoE 层里,dense MLP 没有被替换,它仍然完完整整地保留着,而 MoE 是被并联到 dense MLP 上的另一条支路。这件事在 model card 里被一句话带过,”Expert Count: 8 active / 128 total and 1 shared”,那个 “1 shared” 看上去像是个微不足道的注脚,但落到代码里就是一整条与 128 个路由专家平起平坐的、宽度为 `intermediate_size` 的全宽 MLP。
在源码 `vllm/model_executor/models/gemma4.py`中的类`Gemma4DecoderLayer` ,先看它的 `__init__`函数。这一段代码塞了相当多东西,但只看 MoE 相关的部分,骨架其实非常清晰:每一层都会无条件地构造一个 `self.mlp = Gemma4MLP(…)`,然后再根据配置开关 `enable_moe_block` 决定要不要额外构造一个 `self.router = Gemma4Router(…)` 和 `self.moe = Gemma4MoE(…)`。换句话说,dense MLP 是这一层的”必选项”,MoE 是”可选项”,开了就并联上去,不开就退化成普通的 dense Transformer 块。Gemma 4 家族里的 26B A4B 是全 30 层 MoE 都开启的版本,而 E2B/E4B/31B Dense 那几个稠密变体则全程关着这个开关,整份代码因此可以同时承载稠密与 MoE 两套架构,而不需要分两个文件。
`__init__` 真正容易让人头皮发麻的,是它一口气声明了七个独立的 RMSNorm。这七个 norm 各司其职,`input_layernorm` 在 attention 入口,`post_attention_layernorm` 在 attention 出口,`pre_feedforward_layernorm` 是 MLP 自己的入口 norm,`post_feedforward_layernorm` 是整个 MLP+MoE 合流之后的出口 norm;而一旦开启了 MoE,又会额外多出三个,`pre_feedforward_layernorm_2` 给 MoE 当独立入口 norm,`post_feedforward_layernorm_1` 是 MLP 输出的 post-norm,`post_feedforward_layernorm_2` 是 MoE 输出的 post-norm。无论是听起来还是看起来都非常的罗里吧嗦,但这些 norm 的命名规律其实很守纪律,后缀 `_1` 全部跟 MLP 走,后缀 `_2` 全部跟 MoE 走,没带后缀的是这一层”主干上”的 norm。看到这里各位读者大概就能猜到,MLP 和 MoE 不是简单的”输出相加”,而是两条独立装修的支路,各自带着自己的进/出 norm。这正是 Gemma 系列从 Gemma 2 开始一直坚持的 sandwich-norm 风格,每个子模块的输入和输出都各自归一化一次,而不是只在入口归一化的 pre-norm 写法。
讲清楚了 `__init__` 之后,再看 `forward` 就会顺得多。把和 PLE(Per-Layer Embedding)、layer_scalar 这些只在小模型里用到的旁支去掉,纯 MoE 路径的 forward 大致是这样的,如下所示:
residual = hidden_stateshidden_states = self.input_layernorm(residual)hidden_states = self.self_attn(positions, hidden_states, kwargs)hidden_states = self.post_attention_layernorm(hidden_states)hidden_states = hidden_states + residualresidual = hidden_states # ← 这是关键的"分叉点"# MLP runs unconditionally (same inputs for MoE and non-MoE)hidden_states = self.pre_feedforward_layernorm(hidden_states)hidden_states = self.mlp(hidden_states)if self.enable_moe_block:hidden_states_1 = self.post_feedforward_layernorm_1(hidden_states)# Router and MoE experts see the residual (pre-MLP state)router_logits = self.router(residual)hidden_states_2 = self.pre_feedforward_layernorm_2(residual)hidden_states_2 = self.moe(hidden_states_2, router_logits)hidden_states_2 = self.post_feedforward_layernorm_2(hidden_states_2)hidden_states = hidden_states_1 + hidden_states_2hidden_states = self.post_feedforward_layernorm(hidden_states)hidden_states = hidden_states + residual
如图1所示,这段 forward 里,有两件事必须挑出来单说。
第一件事,MLP 和 MoE 的输入是同一个张量,但各自先过一道独立的 norm 才进入计算。注释行 `MLP runs unconditionally (same inputs for MoE and non-MoE)` 已经把这件事点出来了,无论本层是否启用 MoE,`self.mlp` 都会在 `pre_feedforward_layernorm` 之后被无条件调用一次。一旦本层启用了 MoE,刚刚那个变量 `residual`(也就是 attention 残差合流之后的状态)会被原封不动地复用为 MoE 路径的输入;接下来这条 MoE 路径再走自己专属的 `pre_feedforward_layernorm_2`,再喂进 `self.moe`。所以 MLP 看到的实际上是 `pre_feedforward_layernorm(residual)`,MoE 专家看到的是 `pre_feedforward_layernorm_2(residual)`,两条支路的”原始材料”相同,但各自先被自己的归一化器调过味,才进入后面的 FFN/专家组。两条支路出来之后再分别过 `post_feedforward_layernorm_1` / `post_feedforward_layernorm_2`,最后做的事情是 `hidden_states_1 + hidden_states_2`,直接相加,没有任何加权系数,没有可学的混合比,也没有 sigmoid gate。这一点和 Mixtral 那种”router 决定一切”的写法形成鲜明对比,在 Gemma 4 里,dense MLP 的贡献是”无条件入账”的,router 只决定 MoE 这一边怎么挑专家,对 MLP 这条路完全没有发言权。
第二件事,router 看到的输入和 MoE 专家看到的输入并不是同一个张量。代码里那行 `router_logits = self.router(residual)` 喂进去的 `residual` 是没有经过任何 pre-FF norm 的原始残差;而紧跟着的 `hidden_states_2 = self.pre_feedforward_layernorm_2(residual)` 才把同一个 `residual` 归一化之后送进专家。换句话说,router 的输入和专家的输入差了一道 `pre_feedforward_layernorm_2`。这个差异第一眼看上去像是疏漏,其实是有意为之,后面第 3 小节会讲到,Gemma 4 的 router 自带一套相当克制的输入预处理流水线(无 gamma 的 RMSNorm + root-size 缩放 + 逐维度可学 scale),它对输入的归一化已经在 `Gemma4Router` 内部完成,没有必要再让外面的 `pre_feedforward_layernorm_2` 提前介入。两个 norm 的边界在这里被划得很干净:外部的 `pre_feedforward_layernorm_2` 服务于专家,内部的 router 自带 norm 服务于路由判断,互不干扰。
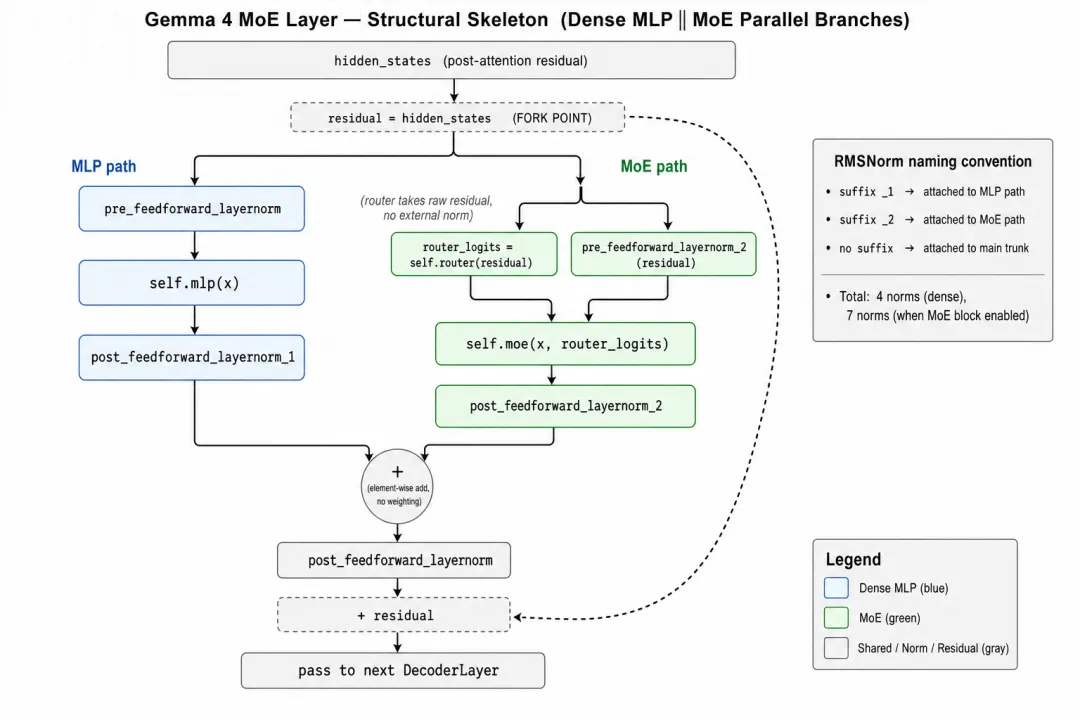
到这里,DecoderLayer 这一层的”骨架”就拼完了,dense MLP 与 MoE 共享同一个 attention 残差作为分叉点,再各自走一条带独立 norm 的小路,最后无加权地汇合,过一道 `post_feedforward_layernorm` 写回主干残差。MLP 这条路的内部细节(GeGLU 还是 SwiGLU、激活函数到底是哪种 GELU)会留到第 6 小节和 MoE 专家放在一起讲;MoE 这条路里 router 的输入预处理三件套和路由数学,是接下来第 3、4 小节的主题;而 `Gemma4MoE` 模块内部 dispatch / expert / combine 的张量流,会在第 7 小节用一组具体的 shape 跑一遍。这些细节会被一一拆开。
2 Gemma4TextConfig-MoE 相关字段
讲完 DecoderLayer 的骨架,下一件事是把每一个尺寸落到具体的数字上。这一步其实很简单,所有数字都摆在 `google/gemma-4-26B-A4B` 仓库的 `config.json` 里。
先做一个名字上的澄清。HuggingFace transformers 里负责描述 Gemma 4 的配置类不叫 `Gemma4MoEConfig`,而是叫 `Gemma4TextConfig`,它是一个统一的文本主干配置类,里面用一个bool开关 `enable_moe_block` 来决定本份配置走稠密路线还是 MoE 路线。Gemma 4 家族里的 26B A4B 配置 `enable_moe_block: true`,于是就有了我们要分析的 128 路由专家结构;而 31B Dense / E2B / E4B 那几个稠密变体里 `enable_moe_block: false`,整个文本主干就退化成普通的稠密 Transformer。这意味着 vLLM 的 `gemma4.py` 里那段 `if self.enable_moe_block:` 的分支判断(544-758 行的 `Gemma4DecoderLayer`),不是在描述某种”运行时切换”,而是在响应配置文件里这一个字段,配置怎么写,模型就怎么搭。
把 26B A4B 的 `config.json` 里和 MoE 直接相关的几个字段拎出来,如下所示:
`hidden_size`:取值 2816,主干维度,所有 token 都活在这个空间里`intermediate_size`:取值 2112,dense MLP(self.mlp)的中间层宽度`moe_intermediate_size`:取值 704,单个路由专家的中间层宽度`num_experts`:取值 128,路由专家总数`top_k_experts`:取值 8,每个 token 激活几个路由专家`num_hidden_layers`:取值 30,主干层数(每层都是 MoE)`enable_moe_block`:取值 true,MoE 总开关`hidden_activation`:取值 `"gelu_pytorch_tanh"`,dense MLP 的激活函数
光看数字密度不大,但有三件事需要单独讲一下,它们都不是那么直观。
第一件,`intermediate_size` 居然比 `hidden_size` 还小。这是整组字段里最反直觉的一项。在 LLaMA、Mistral、Qwen 这些主流稠密模型里,FFN 的中间层通常是 `hidden_size` 的 3 到 4 倍,一个 8K 隐层的稠密模型,FFN 中间层往往落在 24K~32K 这个区间。但 Gemma 4 26B A4B 的 dense MLP 里,`intermediate_size = 2112`,而 `hidden_size = 2816`,比例只有 0.75,第一次看到几乎会怀疑是不是写错了。但这件事其实是有道理的,在 26B A4B 这个 MoE 架构里,每一层真正的”FFN 容量”是由 dense MLP 加上 8 个路由专家一起承担的,dense MLP 不需要独自背完整的 FFN 任务,它只承担那部分”所有 token 都需要”的通用计算,剩下的专精化能力交给 128 选 8 的路由专家组。这条 dense MLP 之所以小到 0.75 倍,正是因为它已经不是”唯一的 FFN”,而是”无条件激活的那一份基底”。
第二件,三个宽度(hidden / intermediate / moe_intermediate)之间的比例关系。把数字摆开来看,`hidden_size : intermediate_size : moe_intermediate_size = 2816 : 2112 : 704 = 4 : 3 : 1`。这个 4:3:1 的关系不是巧合,它体现了 Gemma 4 的容量分配策略,dense MLP 的中间层是路由专家中间层的 3 倍,所以一条 dense MLP 路径在参数量上其实就相当于 3 个路由专家。粗略地算一下账:GeGLU 这种 gated FFN 每层有三个权重矩阵(`gate_proj` / `up_proj` / `down_proj`),所以每层 dense MLP 的参数量大约是 `3 × hidden_size × intermediate_size = 3 × 2816 × 2112 ≈ 17.8M`,而单个路由专家大约是 `3 × 2816 × 704 ≈ 5.95M`,128 个就是 ≈ 761M。也就是说每一层里,128 个路由专家加起来的参数量大约是 dense MLP 的 43 倍,而每次推理实际只激活 8 个专家加一个 dense MLP,被激活的参数量比例约为 `(8 × 5.95M + 17.8M) / (128 × 5.95M + 17.8M) ≈ 8.4%`。Model Card 里”3.8B 激活 / 25.2B 总参”这两个数字背后真正的算术,其实就是这套比例在 30 层上叠加再加上 attention、embedding、router 等部件之后的结果。
第三件,`top_k_experts` 这个字段名。绝大多数 MoE 实现里这个字段叫 `num_experts_per_tok`(HF Mixtral)或 `moe_topk`(DeepSeek),Gemma 4 的命名是 `top_k_experts`,这是一个细枝末节的差别,但如果照着别的模型的字段名去读 vLLM 源码,会找不到对应的入口。vLLM 的 `Gemma4MoE`(306 行起)在初始化时直接通过 `config.top_k_experts` 把这个值取出来,再传给 `FusedMoE` 的 `top_k` 参数。
最后顺带说一句和 attention 相关的字段,虽然不是本文重点,但读源码时绕不开,`config.json` 里那个 `layer_types` 数组直接列出了 30 层里每一层是 `sliding_attention` 还是 `full_attention`,具体模式是”5 个 sliding + 1 个 full”循环 5 次,最后一层(第 29 层)落在 `full_attention` 上,对齐了 model card 里 “ensuring the final layer is always global” 的承诺。这个数组只影响 attention 这一路的实现,MoE 的 router 和专家组对每一层都是同构的,不会因为 sliding/full 的切换而改变结构。换句话说,本文后面所有讨论 router、per-expert scale、FusedMoE 的小节,都可以默认面对的是 30 层完全相同的 MoE 结构,不需要再额外区分层类型。
到这里 `Gemma4TextConfig` 里和 MoE 相关的字段就都讲完了。需要特别强调的一点是,`config.json` 里找不到任何 router 超参,softmax-all 的路由公式、per-expert scale 向量的初始化、router 内部那套 RMSNorm-without-gamma 的预处理三件套,都不是配置项,而是硬编码在 vLLM 源码里的。这意味着如果有谁想 fork Gemma 4 改个路由策略,光改 `config.json` 是没用的,必须直接动 `Gemma4Router` 那个类。这也正好引出下一小节的主题,第 3 小节会回到源码里 256 行的 `Gemma4Router`,把那套预处理三件套与 fp32 投影逐行拆开。
3 Gemma4Router-MoE 的入口
第 1 小节里那张并行残差图最右边那条 MoE 支路,第一步就是 `router_logits = self.router(residual)`。这一步的输入是一个 `[T, hidden_size]` 的张量,输出是 `[T, num_experts]` 的 router logits,表面上看,这就是一次 `Linear(hidden_size, 128)` 投影,没什么可讲的。但如果你真的去打开 `Gemma4Router` 这个类,会看到它绕了一大圈才完成这次投影,先过一道无 gamma 的 RMSNorm,再乘一个常数缩放因子 `root_size`,再乘一个逐维度可学的 scale 向量,最后才用一个特殊的 `GateLinear` 投影到专家空间,而且这个 `GateLinear` 还会把输出强制提升到 fp32。
这一切都是有意义的。MoE 训练里最常见的失败模式,是 router 在训练初期被某些极端 token 的隐状态带偏,一旦 router logits 数值失稳,专家分工就会塌缩到少数几个”幸运儿”上,剩下大量专家彻底成为死参数。Gemma 4 这套 router 预处理的整个目标,就是让 router 看到的输入分布与 token 无关、与训练阶段无关、与维度数无关,把所有能交给可学层之前的不确定性都先消灭掉。
整个 `Gemma4Router` 加起来不到 50 行,`forward` 更是只有 5 行:
def forward(self, x: torch.Tensor) -> torch.Tensor:"""Returns raw router logits [T, E]."""x = self.norm(x) # 1. RMSNorm (no gamma)x = x * self.root_size.to(x.dtype) # 2. × hidden_size^(-0.5)x = x * self.scale.to(x.dtype) # 3. × per-dim learned scalerouter_logits, _ = self.proj(x) # 4. GateLinear → fp32return router_logits
这 4 步对应了 4 个在 `__init__` 里声明的部件,把它们逐个拆开,会发现每一个的设计动机都不一样。
第一步:`self.norm = RMSNorm(hidden_size, eps=rms_norm_eps, has_weight=False)`。这是一个标准的 RMSNorm,但带着一个非常关键的参数 `has_weight=False`。普通 RMSNorm 的公式是 `y = (x / RMS(x)) * gamma`,那个 `gamma` 是一个长度为 `hidden_size` 的可学参数,作用是让模型自己决定每个维度归一化后要乘多大;去掉 `gamma` 之后,公式就退化成 `y = x / RMS(x)`,只剩纯粹的归一化。这一步做的事情很纯粹,把每个 token 的隐状态向量都拉到 RMS 等于 1 的”单位球面”上。不论一个 token 进来时它的隐状态范数是 0.1 还是 100,归一化之后送给 router 的都是范数为 `sqrt(hidden_size)` 的向量。换句话说,这一步消掉了 token-to-token 的范数差异。为什么不让 RMSNorm 自带一个可学 gamma?因为 router 后面紧接着还会乘一个 `self.scale`,那才是 router 真正”学习如何调整每个维度权重”的地方。如果 RMSNorm 这里也带 gamma,就会出现两个可学缩放向量串联,参数冗余、梯度路径混乱、训练不稳定。Gemma 4 把 norm 和 scale 的职责分得很干净,norm 只做归一化,scale 只做学习。
第二步:`x = x * self.root_size.to(x.dtype)`,其中 `root_size = torch.tensor(hidden_size**-0.5)` 是一个 `register_buffer` 注册的常量(注意是 buffer 不是 Parameter,它不参与梯度更新,只是个静态系数)。这个 `1/sqrt(hidden_size)` 看起来像是凭空冒出来的因子,但它的作用是消掉维度本身对数值范围的影响。RMSNorm 之后的向量范数是 `sqrt(hidden_size)`,也就是说,向量长度会随着隐层维度的增大而自然变大。如果你想把同一份 router 代码用在 `hidden_size=2048` 和 `hidden_size=8192` 两个不同尺寸的模型上,norm 之后的输入数值范围会差出 2 倍,紧接着的可学 scale 和 proj 在两个尺度下需要学出完全不同的初始化和量级。乘上 `1/sqrt(hidden_size)` 之后,向量范数被压回 1,router 输入的数值规模就和模型尺寸完全解耦了。这件事在 Gemma 4 这种”同一份代码同时承载 E2B / E4B / 26B A4B / 31B 多个尺寸”的家族里特别有价值,所有变体的 router 都共享同一套数值假设。
第三步:`x = x * self.scale.to(x.dtype)`,其中 `self.scale = nn.Parameter(torch.ones(hidden_size))`。这是这套预处理里唯一可学的部分,初始值全部为 1,意味着训练刚开始时这一步什么也不做。它的作用是让模型自己决定”用 hidden state 的哪些维度来做路由判断”,某些维度可能对路由几乎没用(学出 scale ≈ 0),某些维度可能极其关键(学出 scale ≈ 几)。这一步把”哪些维度应该被 router 看见”这个判断从硬编码升级为可学,但又约束在乘法这一种最简单的运算上,参数量只有 `hidden_size`(在 26B A4B 里就是 2816 个浮点数),对总参的贡献几乎可以忽略。这种”用最小代价让 router 拿到自由度”的设计,是 Gemma 4 整个 MoE 设计里反复出现的克制风格。
第四步:`self.proj = GateLinear(hidden_size, num_experts, bias=False, out_dtype=torch.float32)`。这一行是整个 router 里最不像普通 PyTorch 写法的地方。它没有用 `nn.Linear`,也没有用 vLLM 自己最常用的 `ColumnParallelLinear` 或 `RowParallelLinear`,而是用了一个专门的 `GateLinear`,并且显式指定 `out_dtype=torch.float32`。源码的注释把动机写得很直白:”GateLinear supports bf16 W/A → fp32 output, which is important because the topk kernel often needs fp32 for stable routing.” 翻成大白话就是,权重和激活值都是 bf16(因为 26B A4B 整个模型都是 bf16),但这次投影出来的 logits 要立刻提升到 fp32,因为紧接着的 top-k 选取对数值精度极其敏感。bf16 的 7 位有效位完全不足以稳定地比较 128 个非常接近的浮点数,可能两个真实差距很小的 logits 在 bf16 下被四舍五入成同一个值,导致每次前向传播的 top-k 结果都在抖动。`GateLinear` 解决的就是这个”局部精度提升”的问题:让大头计算(matmul)保持在 bf16 提速,但关键的输出立即提升到 fp32 保精度。
`GateLinear` 还有一个不在源码这一行、但在 vLLM 的 FusedMoE 通用约定里写明的特点,它是 TP-replicated 的。也就是说,无论 tensor parallelism 切多少卡,router 投影这一步都会在每张 GPU 上完整跑一遍,每张卡得到的 router logits 完全一致。源码注释 “Project to expert logits; replicated across TP for consistent routing” 直接说了这件事。这个设计是必然的,路由决策必须在所有 rank 上一致,否则不同 GPU 上为同一个 token 选出的 top-8 专家可能不一样,整个 dispatch 阶段就会乱套。
把这四步串起来再回头看一眼 forward,整个 router 的本质其实是这样一个流程:
[T, hidden_size]│▼ RMSNorm(no gamma):消除 token 范数差异[T, hidden_size],每个向量范数 = sqrt(hidden_size)│▼ × 1/sqrt(hidden_size):消除维度数差异[T, hidden_size],每个向量范数 ≈ 1│▼ × per-dim learned scale:让模型决定哪些维度重要[T, hidden_size],仍然 bf16│▼ GateLinear(bf16 → fp32):投影到专家空间,提升精度[T, num_experts=128],fp32
讲完这套 forward,回头补一个第 1 小节留下的小细节就顺理成章了。第 1 小节末尾我们注意到一件事,DecoderLayer 里 router 看到的是没有过 `pre_feedforward_layernorm_2` 的 raw residual,而专家看到的是 norm 之后的版本。现在原因清楚了,`pre_feedforward_layernorm_2` 是一个有 gamma 的 RMSNorm,它的 gamma 是为专家这条路径专门学出来的;而 router 已经在自己内部带了一道无 gamma 的 RMSNorm 加一套独立的 root_size 和 scale,它对输入的归一化诉求和专家不一样,没有必要也不应该共用一道外部 norm。两条路径在 norm 这件事上是各管各的,互不串扰,这种边界划分在工程上极其重要,任何一边的 norm 出问题都不会污染到另一边。
到这里 router 的预处理就讲完了。它的产出是一份 `[T, 128]` 的 fp32 router logits,但仅仅是 logits,还远不是最终用来 dispatch 的权重。从 logits 到 dispatch decision 之间,还要经过 Gemma 4 那套相当独特的”softmax-全集 → top-k → renormalize”路由公式,再叠加一个可学的 per-expert scale 折叠。这两件事是接下来第 4 小节和第 5 小节的主题。
4 路由数学
第 3 小节里 router 走完那 4 步预处理 + 投影之后,输出是一份 `[T, 128]` 的 fp32 router logits。但 logits 只是一份”打分表”,它告诉你每个 token 对 128 个专家分别有多偏好,但还不是真正的 dispatch decision。要把 logits 变成”哪些 token 该去哪些专家、以多大权重去”,还需要走完 MoE 模型里最具个性的那一段计算:路由公式。
不同 MoE 模型在这一段的写法分歧极大,是先 softmax 再 topk,还是先 topk 再 softmax;最后是否做重归一化让 K 个权重和等于 1;是用 softmax 还是用 sigmoid,这些都是被反复尝试过的变体。每种写法都会让 router weights 有不同的数值范围、不同的归一化性质、不同的梯度行为。Gemma 4 选的是其中相对完整的一种,先在全部 128 个 logits 上做 softmax,再用 top-k 的 indicator mask 把未中选专家的概率清零,再对剩下 K 个权重做一次重归一化。这套流程在 vLLM 源码里有两份完全等价的实现,CUDA/XPU 平台跑 Triton kernel(92-179 行),其他平台 fallback 到 PyTorch reference(182-202 行)。Triton 那份做了大量位运算优化,读起来很硬核;要看清楚数学,PyTorch 那份才是源码本身的”自我注解”,下面这段就是它的全部 15 行:
def gemma4_routing_function_torch(gating_output, topk, per_expert_scale):_, topk_ids = torch.topk(gating_output, k=topk, dim=-1) # 1router_probabilities = torch.nn.functional.softmax(gating_output, dim=-1 # 2)indicator = torch.nn.functional.one_hot(topk_ids, num_classes=gating_output.size(-1) # 3).sum(dim=-2)gate_weights = indicator * router_probabilities # 4renorm_factor = torch.sum(gate_weights, dim=-1, keepdim=True) # 5renorm_factor = torch.where(renorm_factor > 0.0, renorm_factor, 1.0)dispatch_weights = gate_weights / renorm_factor # 6topk_weights = dispatch_weights.gather(1, topk_ids) # 7expert_scales = per_expert_scale[topk_ids].to(topk_weights.dtype) # 8topk_weights = topk_weights * expert_scales # 9return topk_weights.to(torch.float32), topk_ids.to(torch.int32)
每一行都不复杂,但合起来塑造了 Gemma 4 路由的整套数值性质。下面把它拆成五个步骤逐一进行讲解。
第一步:在全集上选 top-k(第 1 行)。 `torch.topk(gating_output, k=8, dim=-1)` 直接在 128 维 logits 上选出值最大的 8 个,返回它们的索引 `topk_ids: [T, 8]`。注意这一步只用到 logits 本身,没碰 softmax,选 top-k 这件事是在原始 logits 上做的,不是在 softmax 概率上做的(虽然数学上完全等价,因为 softmax 是单调函数)。
第二步:在 ALL 128 个 logits 上做 softmax(第 2 行)。这是 Gemma 4 路由公式里最具辨识度的一步。`router_probabilities = softmax(gating_output, dim=-1)` 把 128 个 logits 转成一份和为 1 的概率分布。这里的关键词是 ALL,softmax 的 scope 是全部 128 个专家,而不是只在选中的 8 个上。这意味着每一个未中选专家的 logits 也参与了归一化分母 `Σ exp(z_j)` 的计算,从而影响最终落到中选专家身上的概率值。后面会看到这件事并不会让未中选专家拿到梯度,但它确实让 top-k 的概率值取决于全集的 logits 分布。
第三步:用 top-k 的索引构造 one-hot indicator(第 3 行)。`one_hot(topk_ids, num_classes=128)` 会把 `[T, 8]` 的索引展开成 `[T, 8, 128]` 的 one-hot 张量,每个 token 在 8 个槽位上各有一个长度 128 的 one-hot。再 `.sum(dim=-2)` 把 8 个 one-hot 沿专家维度累加,得到 `indicator: [T, 128]`,每一行里被选中的 8 个位置是 1,其余 120 个位置是 0。这一步的本质是把”哪些专家被选中”这件事,从一个索引集合翻译成一个0/1 mask,方便接下来做逐元素相乘。
第四步:indicator 与全集概率相乘(第 4 行)。`gate_weights = indicator * router_probabilities`,每一行里被选中的 8 个位置保留它们在 softmax 后的概率值,未中选的 120 个位置统统乘 0 清零。这就是 “softmax-all + indicator mask” 这种写法的核心动作,先在全集上算概率,再硬性 mask 掉非 top-k。
第五步:重归一化(第 5、6 行)。`renorm_factor = Σ gate_weights`,`dispatch_weights = gate_weights / renorm_factor`,把剩下那 8 个 mask 之后的概率值再除以它们的和,让最终中选 8 个权重的总和精确等于 1。注意第 5 行紧跟着的 `torch.where(renorm_factor > 0.0, renorm_factor, 1.0)` 是一个数值安全垫,理论上 8 个 softmax 概率之和不可能等于 0,但浮点下偶尔会有极端情况,万一为 0 就用 1 替代,避免除零产生 `nan` 污染整张图。剩下的第 7 行 `gather` 只是把 `[T, 128]` 的稀疏权重压缩回 `[T, 8]` 的稠密形式,方便后面 dispatch 用。
到这里为止,一个最自然的疑问是,先在全集上 softmax 再 mask 再重归一化,绕这么大一圈,到底和”直接对 top-k 的 logits 做一次 softmax”有什么区别?答案是,前向输出严格相等。这件事可以用一组具体数字验证。假设有 4 个专家、Top-2,原始 logits 是 `[1, 2, 3, 4]`:
走 Gemma 4 这条路,先 softmax 全集 → `p = [0.0321, 0.0871, 0.2369, 0.6439]`;top-2 是索引 `[3, 2]`;mask 清零 → `[0, 0, 0.2369, 0.6439]`;重归一化 → 除以 `0.6439 + 0.2369 = 0.8808`,得 `[0, 0, 0.269, 0.731]`。
走”先 topk 再 softmax”这条路,先取 top-2 logits = `[4, 3]`;直接 softmax → `[exp(4)/(exp(4)+exp(3)), exp(3)/(exp(4)+exp(3))] = [0.731, 0.269]`。
两组中选权重完全一致。这并不是巧合,把分式写出来就能看到,Gemma 4 那条路里,被选中专家 i 的最终权重是 `exp(z_i) / Σ_j exp(z_j) ÷ Σ_{k∈S} exp(z_k) / Σ_j exp(z_j) = exp(z_i) / Σ_{k∈S} exp(z_k)`,全集归一化常数 `Σ_j exp(z_j)` 在分子分母上被完全约掉,得到的就是”先 topk 再 softmax”那条路的同一个表达式。
那 vLLM 既然两种写法等价,为什么不直接调 FusedMoE 内置的 `fused_topk`,而非要自己写一份?源码 `Gemma4MoE` 类(331-333 行)的注释把动机写得很直白:
Gemma4 routing: softmax over ALL experts → top-k → renormalize.FusedMoE's built-in fused_topk scopes softmax differently, soa custom routing function is needed for numerical correctness.
也就是说,vLLM 内置的 `fused_topk` 走的并不是上面验算过的”topk-then-softmax”那条等价路径,而是第三种 softmax scope(具体哪种就需要去翻 FusedMoE 源码了,本文不展开),只要它和 Gemma 4 训练时用的”softmax-all + mask + renorm” 在数值上不一致,HF checkpoint 里训练好的 router 投影权重就会和 vLLM 推理时的路由分布对不齐,整套模型的输出质量就会出现肉眼可见的下降。所以 vLLM 这份 custom routing 不是为了性能,而是为了与 HF checkpoint 的训练语义在数值上严格对齐,这是 vLLM 几乎所有自定义 op 的共同动机。
第二个值得专门破除的误解是,很多人看到 “softmax over ALL experts” 这种写法,会下意识觉得既然全部专家都参与了 softmax,那未中选的专家是不是也能从归一化分母里拿到一点点梯度,从而获得训练?答案是不能。在第 4 步 `indicator * router_probabilities` 这一行,未中选的 120 个专家的概率被硬性乘以 0;后续重归一化、gather、与专家输出相乘的链路里,它们的贡献始终是 0。求导时 0 乘以任何东西的导数还是 0,所以未中选专家的 logits 关于 loss 的偏导数精确为 0,它们既不会被强化也不会被抑制。”softmax-all” 这个写法的唯一实际效果,是让中选专家的 logits 梯度计算路径里多了一个”全集归一化常数 `Z = Σ_j exp(z_j)`“作为分母,这个分母把所有专家的 logits 间接耦合在一起,但没有给未中选专家开任何反向梯度通道。专家分工的真正培育,依靠的不是这一步,而是后面第 5 小节要讲的 per-expert scale 这种显式机制。
最后再回到这 15 行 reference 实现的最后两行,第 8、9 行就是把第 5 小节要详细讲的 per-expert scale 折叠进 `topk_weights`。这里只点一下机制的位置:`per_expert_scale[topk_ids]` 用 top-k 索引出 `[T, 8]` 的 scale 值,再逐元素乘到刚算好的 `topk_weights` 上。换句话说,这个可学的”专家音量旋钮”并不是乘到专家的输出端,而是直接加进了 dispatch 权重里。为什么要这么折叠、它在数学上和”乘到专家输出端”是不是等价、对 FusedMoE 的 fused kernel 又意味着什么,这些细节是下一小节的主题。
到这里,整套路由数学就讲完了。这一小节用 15 行 PyTorch 代码描述的事情,在 26B A4B 的实际部署里其实是由那个 Triton kernel `_gemma4_routing_kernel`(92-154 行)来执行的,它做了相当多的位运算优化(把 fp32 logits bit-cast 成 int32 来用 `tl.sort` 做 vectorized topk、用 `exp2` 替代 `exp` 节省指令周期、用 masked store 替代循环),但前向数学和上面 reference 实现完全等价,区别只在于浮点累加顺序导致的 ULP 级误差,对模型行为没有影响。本小节不展开 kernel 细节,MoE 数学本身才是重点,性能优化是另一个层次的话题。
走完 router 预处理(第 3 小节)和路由数学之后,每个 token 已经有了一份明确的 `topk_ids: [T, 8]` 和 `topk_weights: [T, 8]`,前者告诉它”该去哪 8 个专家”,后者告诉它”以什么权重和这些专家的输出做加权聚合”。这两份张量就是下一阶段 dispatch / expert FFN / combine 的全部输入。第 5 小节会专门讲 `topk_weights` 里那个被折叠进去的 per-expert scale,第 6 小节讲 expert FFN 本身的结构,第 7 小节再用一组完整的 shape 把整条 MoE 张量流跑一遍。
5 Per-expert scale:可学习的”音量旋钮”
第 4 小节末尾留了一句话没展开,routing function 的最后两行把一个叫 `per_expert_scale` 的东西乘进了 `topk_weights`,但当时没说它是什么、为什么要这么乘。这一小节就专门讲它。这个机制在 Gemma 4 的 MoE 设计里很容易被忽略,因为它的源码痕迹真的很轻,总共就一行声明、两次乘法。但越是这种”看着不起眼”的东西,越值得单独拎出来讲一讲,因为它是 Gemma 4 防止专家塌缩的几道保险里做得最巧的一道。
先看它的声明。`Gemma4MoE.__init__` 第 329 行就一行,如下所示:
self.per_expert_scale = nn.Parameter(torch.ones(config.num_experts))读懂这一行需要把每个细节都拆开。第一,它是一个 `nn.Parameter`,意味着它会被 PyTorch 收进 `model.parameters()`,跟着模型一起训练,不是一个固定常量。第二,shape 是 `[num_experts]`,在 26B A4B 里就是 `[128]`,每个路由专家对应一个标量,共 128 个浮点数,参数量小到几乎可以忽略。第三,初始值是 `torch.ones(…)`,全部为 1,这是一个非常有设计感的中性初始化,训练刚开始时这一步什么也不做,乘 1 等于没乘;但训练一旦推进,这 128 个数就会各自漂移到模型认为合适的值上。第四,它住在 `Gemma4MoE` 这个类里,不在 `Gemma4Router` 里,这件事后面还会再展开讲。
它是怎么被用的,第 4 小节已经看到了,再贴一次 reference 实现的最后两行,如下所示:
expert_scales = per_expert_scale[topk_ids].to(topk_weights.dtype) # [T, K]topk_weights = topk_weights * expert_scales
`per_expert_scale[topk_ids]` 这一句是把那个 `[128]` 的可学向量按 `[T, 8]` 的 top-k 索引”摊开”成 `[T, 8]`——每个 token 在自己被选中的 8 个专家位置上各拿到一个对应的 scale 值。然后这 `[T, 8]` 的 scale 直接乘到刚算好的 `topk_weights` 上。这一步的几何意义非常清晰,这个可学参数没有以任何方式触碰专家的输出,它从头到尾只在 routing weights 这条路径上活动。
大家思考下,把 scale 折叠进 routing weights 和把 scale 乘到 expert 输出端,这两种写法的差别到底在哪?
数学上完全没差。设某个 token 选中了第 e 个专家,专家的输出是 `y_e`,routing weight 是 `w_e`,per-expert scale 是 `s_e`。最终对这个 token 的贡献无论怎么写都是 `(w_e × s_e) × y_e = w_e × (s_e × y_e)`,乘法的结合律保证两种写法的浮点结果在数值精度内都是一样的。但工程上的差别就大了,FusedMoE 这种把 dispatch / GEMM / combine 三步融成一个 kernel 的设计,它的接口签名本来就长成 `fused_moe(x, w1, w2, topk_weights, topk_ids)` 的样子,`topk_weights` 是它原生支持的输入。如果 scale 提前折进了 `topk_weights`,整条 FusedMoE 路径不需要改任何代码就能算出正确结果;但如果 scale 走”乘到 expert 输出端”那条路,就得在 FusedMoE 的 GEMM 之后插一次 elementwise multiply,要么破坏 kernel 的 fusion 边界(多出一次显存往返),要么就得为 Gemma 4 专门 fork 一个变体 kernel,前者损失性能,后者放大维护成本。源码 `Gemma4MoE` 第 327-328 行那行注释把这个动机写得非常清楚,如下所示:
# Per-expert output scale folded into routing weights so that# FusedMoE's fused kernel computes: Σ_e (expert_e * w_e * scale_e)
类的 docstring 里也补了一句更直接的话,`per_expert_scale is folded into routing weights for mathematical correctness with FusedMoE’s fused kernel`。意思是,不折叠就用不上 FusedMoE 现成的 fused kernel。这是一个典型的”为了对接现成工具而做的形式调整”,数学上不变,物理上让代码刚好能复用最快的那条路径。
这里还有一个相当有趣的”概念归属”差异,藏在 vLLM 的权重加载逻辑里。HF 那边发布的 checkpoint 里,per-expert scale 这个权重的命名带着 `.router.per_expert_scale` 这个后缀,HF 把它放在了 router 这个模块下;但 vLLM 这边写代码时,把它声明在 `Gemma4MoE` 类里,所以模型结构里它的对应命名是 `.moe.per_expert_scale`。两个名字指向的是同一份权重,所以 vLLM 在加载 checkpoint 时(第 1639-1642 行)专门做了一道 remap,如下所示:
name = name.replace(".router.per_expert_scale",".moe.per_expert_scale",)
这个 remap 不影响任何数学,纯粹是命名调整,但它背后反映的是 HF 和 vLLM 对这个机制的两种不同理解。HF 把它当作”路由判断的一部分”,毕竟 scale 改变的是路由权重;vLLM 把它当作”专家组的一部分”,毕竟 scale 是 per-expert 的、和专家一一对应。两种放法都说得通,但 vLLM 这种放法在工程上更顺:它紧挨着 FusedMoE 实例,在物理位置上和它真正被消耗的地方在一起,不用跨模块去拿。
最后顺手讲一下 Triton kernel 那边的细节,第 142-149 行,如下所示:
all_scales = tl.load(per_expert_scale_ptr + all_ids.to(tl.int64),mask=top_mask,other=1.0,).to(tl.float32)all_weights = (all_raw_exp * inv_renorm * all_scales).to(tl.float32)
第一个 `tl.load` 用 `mask=top_mask` 做一次 sparse gather,只对被选中的 K 个专家位置真正读取 scale;剩下未被选中的位置由 `other=1.0` 顶上,`other=1.0` 而不是 `other=0.0` 这件事很关键,因为这些值后面要参与乘法,乘 0 会污染整张图,乘 1 是安全的恒等。再下一行 `all_raw_exp * inv_renorm * all_scales` 把”未归一化的 softmax 值 × 重归一化因子 × per-expert scale”三步并成一次乘法完成,这就是 Triton 版对应的那一次”折叠”。可以看到,无论是 reference 的 PyTorch 实现还是性能版的 Triton kernel,per-expert scale 在两份代码里都被严格折进了同一处:routing weights 与 expert 输出做加权聚合之前的最后一次乘法里。这种”两份实现严格对齐”的克制,是 vLLM MoE 模块写得最干净的体现之一。
讲完了 per_expert_scale 的物理位置和折叠机制,最后还差最后一步,它对训练究竟有什么作用?这个问题的答案在 Gemma 4 的训练阶段,它是一道”软淘汰”机制。MoE 训练里最常见的失败模式是专家塌缩,少数专家偶然在初期被路由到的次数多一点,学得就快一点,router 就更倾向于选它们,于是它们被路由到的次数更多,这个正反馈一旦开始,几轮之后就会出现少数专家承担几乎全部计算、剩下大量专家成为死参数的局面。Mixtral 8x7B 在公开评测里就被反复观测到有这个问题,8 个专家中真正活跃的常常只有 3 到 4 个。Gemma 4 的 per_expert_scale 给了模型一个非常温和的反制工具,能力强、贡献大的专家可以把自己的 scale 学高一点,等同于被放大;能力弱、贡献小的专家会把 scale 学低一点,等同于被静音。整个过程没有任何强制性的 load-balancing loss,没有谁被硬性要求平均使用,但谁的输出被采纳多少完全由模型自己说了算。这种”用最小的可学代价让模型自调整”的克制风格,是 Gemma 4 整个 MoE 设计里反复出现的主题,前面 router 输入预处理三件套是这种风格,per-expert scale 也是这种风格。
到这里,整套 routing 流水线就闭合了,router 出 logits,路由公式把 logits 变成 dispatch 决策,per-expert scale 给这个决策加一道可学的音量调节。从下一小节开始,焦点转移到实际的”专家计算”上,dense MLP 这条 shared 路径长什么样、单个路由专家长什么样、它们的激活函数为什么各不相同。这是第 6 小节的主题。
6 Gemma4MLP + 路由专家:两条 FFN 的差异
第 1 小节里那张并行残差图,左边是 dense MLP 一条路,右边是 MoE 一条路。前面都在讲右边那条router、路由公式、per-expert scale,全是为了把 token 送到正确的专家手里。但 token 真正被算的地方,是 FFN 自己。这一小节把两条路各自的 FFN 拆开看一眼,确认它们到底是什么、又有哪些地方不一样。
先看 dense MLP 这边。`Gemma4MLP` 类在源码 217 行起,整个类加上 forward 不到 35 行,如下所示:
class Gemma4MLP(nn.Module):def __init__(self, hidden_size, intermediate_size, hidden_activation, ...):super().__init__()self.gate_up_proj = MergedColumnParallelLinear(hidden_size, [intermediate_size] * 2, bias=False, ...)self.down_proj = RowParallelLinear(intermediate_size, hidden_size, bias=False, ...)if hidden_activation != "gelu_pytorch_tanh":raise ValueError("Gemma4 uses `gelu_pytorch_tanh` as the hidden activation ""function. Please set `hidden_act` and `hidden_activation` to ""`gelu_pytorch_tanh`.")self.act_fn = GeluAndMul(approximate="tanh")def forward(self, x):gate_up, _ = self.gate_up_proj(x) # [T, 2*I]x = self.act_fn(gate_up) # [T, I]x, _ = self.down_proj(x) # [T, H]return x
它就是一个标准的 GeGLU 风格 FFN,按照 vLLM 自己的 TP 写法实现。`MergedColumnParallelLinear` 这个名字看着复杂,做的事很直观,把 gate 和 up 两个投影矩阵合并成一个权重 `[H → 2I]`,输出按列切分(在 TP 维度上每个 rank 拿到 `2I/TP` 列),算完之后输出长度是 `2 × intermediate_size`,前一半是 gate、后一半是 up。`RowParallelLinear` 反过来,`down_proj` 把 `I → H` 按行切分,每个 rank 算完自己那部分再做一次 all-reduce 合并。这种”列切 + 行切”的搭配是 Megatron-LM 的经典 TP 写法,整层 MLP 在每个方向上只需要一次 all-reduce 就能跑完,通信开销几乎可以忽略。
中间那个激活函数 `GeluAndMul(approximate=”tanh”)` 是 vLLM 自家的一个融合算子。它接收一个 `[T, 2I]` 的张量,把前一半当 gate、后一半当 up,对前一半做 GELU(tanh 近似版本),再和后一半做 elementwise 乘法,最后输出 `[T, I]`。整个”分半 + GELU + 相乘”被融成一个 CUDA kernel,不会在显存里来回搬运中间结果。这种写法在 vLLM 里非常标准,LLaMA 的 `SiluAndMul`、Gemma 的 `GeluAndMul` 都是同一个接口的不同变体。
中间那段 `if hidden_activation != “gelu_pytorch_tanh”: raise ValueError(…)` 看上去像是某种过分谨慎的防御代码,但它其实是 vLLM 写得很有态度的一笔。这一行的意思非常硬,Gemma 4 的 dense MLP 激活函数只能是 `gelu_pytorch_tanh`,配置里写其他任何值都直接报错。`gelu_pytorch_tanh` 是 PyTorch 里 `F.gelu(approximate=”tanh”)` 的别名,对应的近似公式是 `0.5x(1 + tanh(√(2/π)(x + 0.044715x³)))`,和精确版的 GELU(用 `erf` 函数实现)在数值上有微小差异。Gemma 系列从一开始训练用的就是 tanh 近似版,HF checkpoint 里所有 expert 权重都是基于这个近似版训练出来的;如果有人在 config 里改成 `”gelu”` 走精确 erf 版本,整个模型推理结果会和 checkpoint 期望的产生肉眼可见的偏差。这个硬性 assert 就是为了杜绝任何 silent 走错版本的可能,宁可让用户上来就报错,也不让模型默默地输出错误结果。
然后看 expert FFN 这边。expert 不像 dense MLP 那样有自己一个 Python 类,它直接被打包进了 vLLM 的 `FusedMoE` 算子里,在 `Gemma4MoE.__init__` 第 350-364 行声明,如下所示:
self.experts = FusedMoE(num_experts=config.num_experts, # 128top_k=config.top_k_experts, # 8hidden_size=config.hidden_size, # 2816intermediate_size=getattr(config, "moe_intermediate_size", ...), # 704renormalize=True,quant_config=quant_config,prefix=f"{prefix}.experts",custom_routing_function=routing_function,activation="gelu_tanh",)
这里有几个细节顺手过一下。`intermediate_size=704` 走的是 `moe_intermediate_size` 这个字段(config.json 里 `”moe_intermediate_size”: 704`),与 dense MLP 的 `intermediate_size=2112` 不同,第 2 小节里那个 4:3:1 比例的来源就在这里。`custom_routing_function=routing_function` 是把第 4 小节那个自定义路由函数传给 FusedMoE,让它内部 dispatch 时用 Gemma 4 的”softmax-all + mask + renorm”路由公式而不是默认的 `fused_topk`。`renormalize=True` 这个参数其实在这里没起作用,它会被透传给 `routing_function` 的 `renormalize` 参数,但 Gemma 4 的 `routing_function` 实现里直接忽略了这个参数(把 renormalize 硬编码进了路由公式本身),所以 True 还是 False 都没区别。
真正值得多看一眼的,是这一行,如下所示:
activation="gelu_tanh",`activation=”gelu_tanh”` 这个字符串,和上面 dense MLP 用的 `GeluAndMul(approximate=”tanh”)` 在数学上完全是同一个东西。FusedMoE 内部看到 `activation=”gelu_tanh”` 这个字符串配置,会去拼接出和 `GeluAndMul(approximate=”tanh”)` 一模一样的计算图,把 expert 的 `[T_e, 2I]` 中间张量分成 gate 和 up 两半,对 gate 做 tanh 近似的 GELU,再和 up 做 elementwise 相乘。换句话说,dense MLP 这条路和 128 个 expert 那条路里,每个 FFN 的 gate / up / down 三矩阵 + 激活函数的拓扑是完全相同的。源码里压根没有”两种 GELU”,只有同一种 GELU 在两个模块里被两种不同的写法配置出来:dense MLP 走显式的 `GeluAndMul` 类(因为它是独立的 PyTorch 模块),expert 走 FusedMoE 的字符串配置(因为它需要被融进 fused kernel 里)。
那两条 FFN 真正的差异在哪里?把所有相同点都剥掉之后,只剩下两件事:
第一件事,宽度不同。 dense MLP 的中间层是 `intermediate_size=2112`,单个 expert 的中间层是 `moe_intermediate_size=704`。比例正好是 3:1。第 2 小节已经算过:dense MLP 一条路的参数量大约是 17.8M,单个 expert 大约是 5.95M,128 个 expert 加起来 ≈ 761M。也就是说,dense MLP 的”绝对计算量”虽然只是单个 expert 的 3 倍,但因为它每次都要被激活,所以”分摊到单个 token 的计算贡献”大致和 8 个被选中的 expert 持平。这个比例的设计很有讲究,dense MLP 不需要做得太宽,因为它只承担”所有 token 都要做的事”;但也不能太窄,否则每个 token 拿到的”通用基底”不够厚实。`intermediate_size = 0.75 × hidden_size` 这个看起来反常的小配比,在 26B A4B 这个具体语境下其实是经过深思熟虑的容量分配。
第二件事,部署形态不同。 dense MLP 是一份权重,每层只有一个,每个 token 100% 都会激活它。expert 是 128 份权重,每个 token 只激活其中 8 个,激活率 6.25%。也正是这一点,让 dense MLP 这条路在 PyTorch 这一层被实现为一个标准的 `nn.Module`(`Gemma4MLP`),而 expert 那一组被打包进 `FusedMoE` 这个专用算子——后者要负责的事情远不止 FFN 计算本身,它还要根据 `topk_ids` 把每个 token 的 hidden state 分发到对应的专家上(dispatch),然后在每个专家内部做 grouped GEMM,最后再按 `topk_weights` 把 8 个专家的输出加权聚合回每个 token 上(combine)。这三步如果分别写成 PyTorch 操作,每一步都要做一次显存往返,128 个 expert 的 GEMM 还都是单独的小矩阵乘,这种”小而碎”的算法形态对 GPU 是最不友好的。FusedMoE 的核心优化就是把 dispatch / grouped GEMM / combine 这三步融成一个 kernel:dispatch 阶段不真的把 token 物理搬运到不同专家的内存里,而是只重排出一个 permutation map,让 grouped GEMM 按 expert 分组算的时候用这个 map 间接读 token;grouped GEMM 用 cutlass 或 Triton 实现,把 128 个小矩阵乘合并成一个 batched GEMM 调用;combine 阶段直接在 grouped GEMM 的输出上做按 `topk_weights` 加权 scatter-add,避免再来一次显存往返。这套优化是 MoE 推理性能的核心战场,vLLM 的 `FusedMoE` 是其中相当成熟的一份开源实现。Gemma 4 之所以坚持把 per-expert scale 折叠进 routing weights、之所以让 router 自己用 Triton kernel 做 vectorized topk,动机最终都汇到这里,为了让整个 MoE 路径能完整地跑在 FusedMoE 这条优化好的快路上,不在中间多塞任何零碎的 PyTorch 算子。
7 MoE 张量流
前面把 MoE 的零件一个一个拆开来讲了,但拆开来看零件容易陷入”只见树木”的状态,容易记得每一处的细节,反而忘了它们在真实推理时是按什么顺序协作的。这一小节不引入任何新的源码,只做一件事,拿一份具体的输入跑一次完整的 MoE 层,把每一步的张量 shape 全部标出来。读完这一小节,应该能闭着眼把整条 MoE 路径在脑子里画一遍。
设定一组具体数字。假设当前 batch 里一共有 `T = 128` 个 token,模型是 26B A4B,所以 `hidden_size H = 2816`、`num_experts E = 128`、`top_k K = 8`、`intermediate_size I = 2112`、`moe_intermediate_size I_e = 704`,激活精度是 bf16。下面所有 shape 都按这组数字给出。
故事从 `Gemma4DecoderLayer.forward` 走完 attention、做完一次残差合流后开始。这一刻的 `hidden_states` 是 `[T, H] = [128, 2816]`、bf16,紧接着这一行 `residual = hidden_states` 把它存成第二段残差的基线,同时也成为接下来 MLP 和 MoE 两条支路共享的分叉点。从这里开始,张量同时沿两条路径前进。
左路:dense MLP。`pre_feedforward_layernorm(residual)` 得到 `[128, 2816]` 的归一化输入;`gate_up_proj` 这个 `MergedColumnParallelLinear` 把它一次性投影成 `[128, 2 × 2112] = [128, 4224]`,前 2112 列是 gate、后 2112 列是 up;`GeluAndMul(approximate=”tanh”)` 对前一半做 GELU 再和后一半相乘,输出 `[128, 2112]`;`down_proj` 这个 `RowParallelLinear` 再投影回 `[128, 2816]`。最后 `post_feedforward_layernorm_1` 把它归一化成 `hidden_states_1: [128, 2816]`。整条左路就是一次标准 GeGLU FFN,没有任何 token 路由,128 个 token 100% 都过同一份权重。
右路:MoE。先看 router 自己那条预处理流水线,`Gemma4Router.forward` 拿 `residual: [128, 2816]` 进来,先过无 gamma 的 RMSNorm 把范数拉到 `sqrt(2816)`、再乘 `root_size = 1/sqrt(2816)` 把范数压回 1、再乘 per-dim learned scale `[2816]` 让模型决定哪些维度重要,最后 `GateLinear(2816 → 128, out_dtype=fp32)` 投影到 `router_logits: [128, 128]`、fp32。注意这里输出的两个 128 含义不同——前一个是 `T`,后一个是 `num_experts`。
`router_logits` 出炉之后,DecoderLayer 同步做了另一件事:`hidden_states_2 = pre_feedforward_layernorm_2(residual)`,把同一份 `residual` 用另一道带 gamma 的 RMSNorm 归一化成 `[128, 2816]`。这就是真正进入专家的 x。然后 `self.moe(hidden_states_2, router_logits)` 把这份 x 和 router_logits 一起交给 `Gemma4MoE`,而 `Gemma4MoE.forward` 自己只有一行,如下所示:
def forward(self, x, router_logits):return self.experts(x, router_logits)
它就是一层薄薄的转发,把工作完全交给 `self.experts` 这个 FusedMoE 实例。FusedMoE 内部分四步走:
1. 调用 `custom_routing_function`(第 4 小节 + 第 5 小节)。它在 CUDA/XPU 上跑 Triton kernel `_gemma4_routing_kernel`,在其他平台 fallback 到 PyTorch reference `gemma4_routing_function_torch`,无论走哪条路径,输出都是同一份 `(topk_weights: [128, 8] fp32, topk_ids: [128, 8] int32)`。期间完成了 `softmax(全集) → topk → indicator mask → renormalize → per_expert_scale 折叠` 这一整套数学,128 个 token 各拿到自己被路由到的 8 个专家 ID 和对应的加权权重。
2. dispatch。FusedMoE 不会真的把 token 物理搬运到不同专家的内存里,而是基于 `topk_ids` 构造一个 permutation map,把”每个 token 选了 8 个专家”这件事重排成”每个专家收到了若干 token”。dispatch 之后逻辑上有 `T × K = 128 × 8 = 1024` 行待算的 `(token, expert)` 对,平均到 128 个专家上每个专家收到 8 个 token,但实际分布是不均的——有些专家会收到几十个,有些专家可能一个都收不到。
3. grouped GEMM(第 6 小节)。每个被路由到的 `(token, expert)` 对要走完一次 GeGLU:先 `gate_up_proj` 投影成 `[2 × 704] = [1408]`,再 `GeluAndMul(approximate=”tanh”)` 输出 `[704]`,再 `down_proj` 投影回 `[2816]`。如果 128 个专家分别用独立的 GEMM 算,会变成 128 次小矩阵乘,CUDA 上极其低效。FusedMoE 把它打包成 grouped GEMM,把 1024 行 token 按目标专家分组,每组用同一份专家权重,最终用一次 batched GEMM 调用就把所有专家的 FFN 算完。`activation=”gelu_tanh”` 这个字符串配置就在这里发挥作用,FusedMoE 拼出来的 fused kernel 中间那一步用的是和 dense MLP 完全一样的 tanh 近似 GELU。
4. combine。grouped GEMM 输出之后,每个 `(token, expert)` 对应一份 `[2816]` 的 FFN 输出。FusedMoE 用一次 weighted scatter-add 把每个 token 的 8 份输出按 `topk_weights` 加权聚回到原 token 的位置上,而 per-expert scale 已经在第 1 步折叠进了 `topk_weights`,这里不需要再做任何缩放。combine 完成后,输出是 `[128, 2816]` 的 bf16 张量,回到 `Gemma4MoE.forward` 这一层就是 `return` 出来的东西。
回到 DecoderLayer,`hidden_states_2 = post_feedforward_layernorm_2(MoE_output)` 把这份输出再归一化一次得到 `[128, 2816]`。
两路合流。这一刻 `hidden_states_1` 和 `hidden_states_2` 都是 `[128, 2816]` 的 bf16 张量,前者是 dense MLP 的输出(已经过 `post_feedforward_layernorm_1`),后者是 MoE 的输出(已经过 `post_feedforward_layernorm_2`)。`hidden_states = hidden_states_1 + hidden_states_2`,直接逐元素相加,不带任何加权系数。再过一道 `post_feedforward_layernorm` 写回主干 `+ residual`,整个 MoE 层就走完了,`[128, 2816]` 的输出会传给下一层 DecoderLayer。
整条路径的 shape 流转,如图2所示:
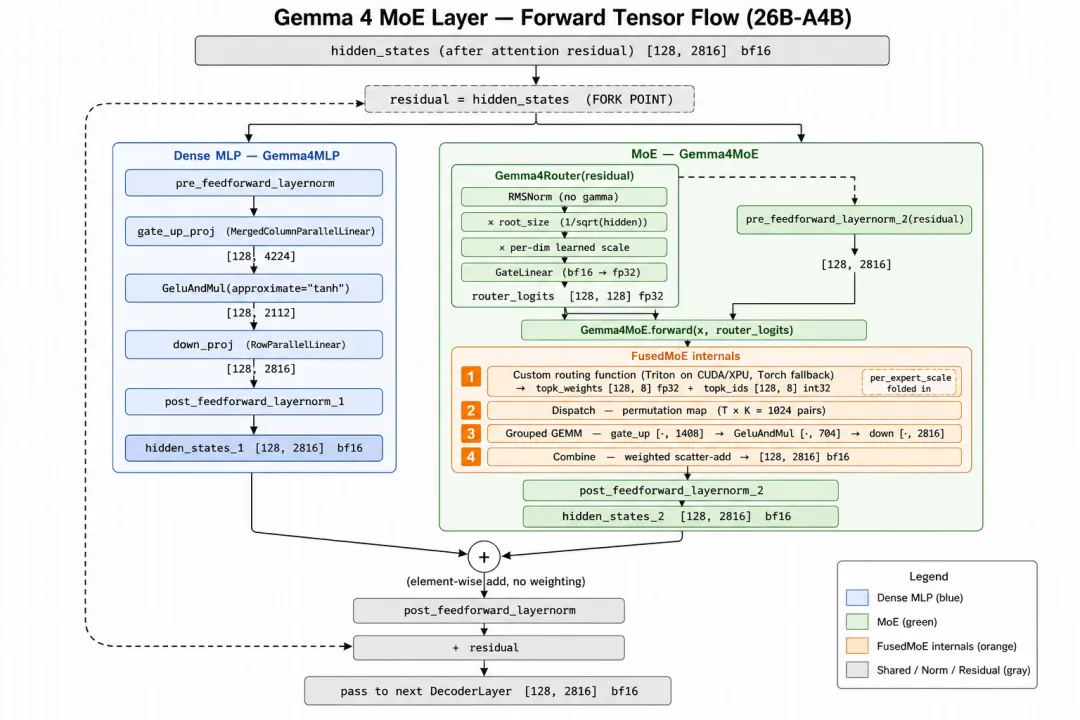
图2描述的是单层 MoE 的一次前向。整个 26B A4B 把这套机制重复 30 次,就跑完了一次完整的文本主干推理。30 层之间唯一的差异在 attention 那一路(`layer_types` 数组决定本层是 sliding 还是 full attention,第 2 小节已讲过),MoE 这条路在 30 层里结构完全同构,同样的 router 预处理三件套、同样的 softmax-all 路由公式、同样的 per-expert scale 折叠、同样的并行 dense MLP,只是每一层的 router 参数和 128 份专家权重各自独立训练出来。
到这里,整篇文章想讲的内容就差不多讲完了。
8 总结
回头看这一整篇,Gemma 4 的 MoE 设计其实没有任何”惊天动地”的新发明,softmax-all 路由是 Mixtral 早就用过的形式、per-expert scale 在很多 MoE 论文里出现过、并行 dense MLP 在 Snowflake Arctic 和 DBRX 里有过类似实践、FusedMoE 这套优化是 vLLM 工业级落地的现成组件。但把这些已经被证明有效的设计点拼装在一起、再用 router 输入预处理三件套和 per-expert scale 折叠这种克制的细节去保证它们在数值上长期稳定,最终交付的是一份”激活 4B 算力跑出 1442 ELO”的开放权重模型。这种”不靠新机制、只靠把每一处细节做对”的工程感,是 Gemma 4 MoE 真正值得读源码的地方。
vLLM 的 `gemma4.py` 之所以值得作为入口去读,也是同样的道理。它没有为 Gemma 4 引入什么 vLLM 之前没有的算子,整份代码用的全是 vLLM 已经成熟的 `FusedMoE`、`GateLinear`、`RMSNorm`、TP/EP 切分接口;它做的事,是把这些通用组件按 Gemma 4 权重的语义 1:1 组装出来,为此自己写一个 Triton kernel 来保证路由数学和 HF checkpoint 训练时一致、为此把 per_expert_scale 折叠进 routing weights 来对齐 FusedMoE 的接口、为此对 hidden_activation 字段做硬性 assert 来杜绝 silent 走错。这些细节的总和,就是一份”production-ready MoE 推理实现”该有的样子。如果未来还要读其他 MoE 模型在 vLLM 里的实现,这篇文章里拆出来的那七个模块(DecoderLayer 骨架 / Config / Router / 路由数学 / per-expert scale / 两条 FFN / 张量流),仍然是一组可以直接套用的阅读骨架。
END