 夜雨聆风
夜雨聆风





别再把 Coding Agent 当编辑器,它已经变成开发队列
结合 Cursor 3 Agents Window、OpenAI Codex Cloud、Claude Code memory/hooks、Anthropic 长任务实践和开发者社区讨论,拆解 Coding Agent 为什么正在从编辑器功能变成软件团队的任务运行系统。
别再把 Coding Agent 当编辑器,它已经变成开发队列
大多数人理解 Coding Agent 的方式,一开始就错了。
他们还在争:
-
哪个模型更会写代码; -
哪个编辑器补全更快; -
哪个 Agent 一次改文件更多; -
哪个产品的 benchmark 分数更高。
这些问题不是完全没意义。
但它们已经不是主变量。
真正的问题不是“哪个 Coding Agent 更像一个聪明编辑器”,而是:谁能把开发工作拆成可排队、可隔离、可验证、可恢复、可审计的任务系统。
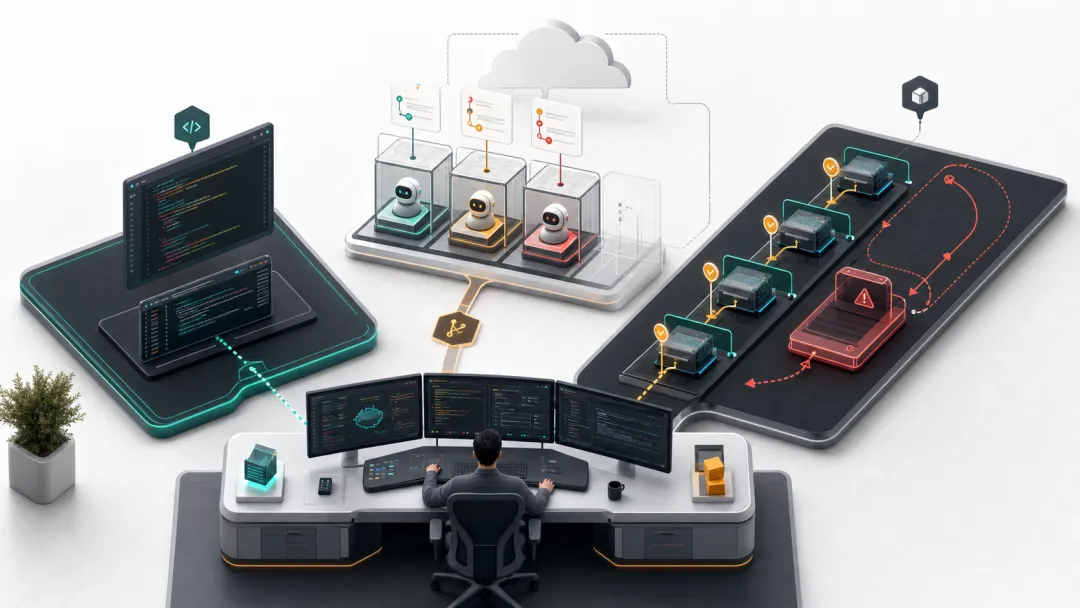
最近几条信号放在一起看,趋势很清楚:
-
Cursor 3 把 Agents Window 放到中心位置,让 local agent、cloud agent、worktree、remote SSH、多 repo 和 Slack/GitHub/Linear 入口进入同一个工作台。 -
OpenAI Codex Cloud 把任务放进独立容器:clone repo、跑 setup、执行终端循环、生成 diff、开 PR,并且 agent 阶段默认关闭公网访问。 -
Claude Code 把 CLAUDE.md、auto memory、hooks、PreToolUse、Stop、InstructionsLoaded 这类机制做成项目级记忆和 deterministic control。 -
Anthropic 的长任务实践反复强调 progress file、test oracle、git checkpoint、fresh-context evaluator,而不是“写一个更长 prompt”。 -
开发者社区的真实焦虑也变了:大家不只问“能不能写”,而是在问 token 烧在哪里、后台任务怎么验收、AI 写完后自己看不懂怎么办。
这不是编辑器大战。
这是开发工作流开始被 Agent 重新分层。
一、Coding Agent 正在分裂成三条通道
过去的 AI 编程工具,大多长得像一个增强版编辑器。
你写代码,它补全。
你选一段,它解释。
你提需求,它改几个文件。
这个阶段的价值是真实的,但上限也很清楚:它仍然围绕“人坐在编辑器前”展开。
现在变化开始出现。
Coding Agent 正在分裂成三条通道:
-
前台协作通道:人在本地编辑器里实时 steering,适合需求还不稳定、需要频繁判断的任务。 -
后台任务队列通道:Agent 在云端隔离环境里跑,适合测试补齐、迁移、重构、文档、issue 修复、PR 草稿。 -
长任务运行通道:Agent 跨 session 工作,靠 memory、progress file、git commit、evaluator 和 hooks 维持连续性。
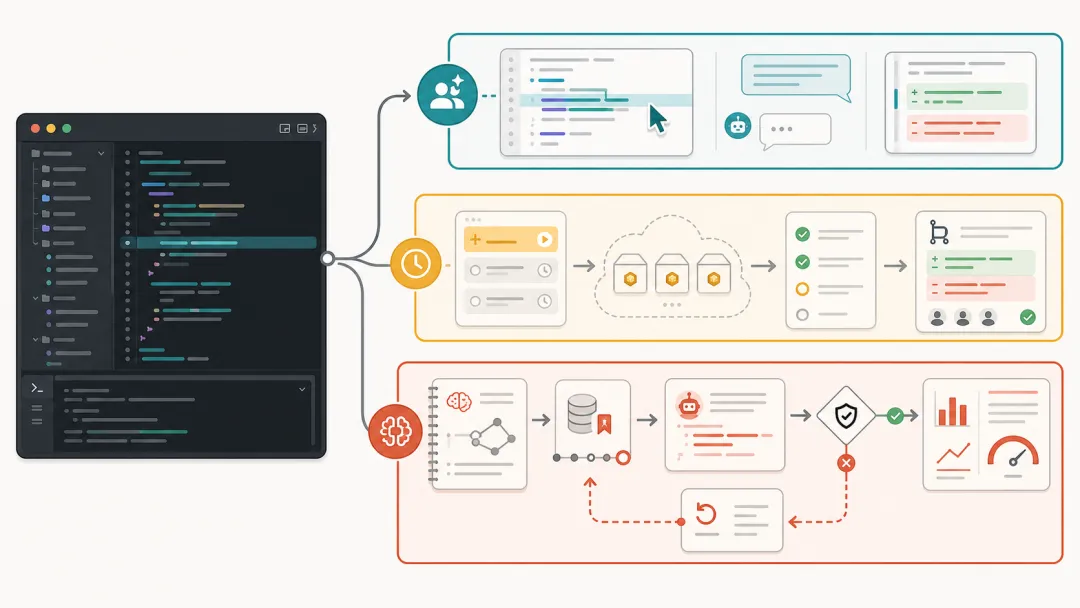
这张图要表达的不是“工具更多了”。
重点是分工变了。
前台协作解决的是高带宽判断。
后台队列解决的是低监督吞吐。
长任务运行解决的是跨时间的状态保持。
如果团队还只用“一个聊天框 + 一个模型 + 一个巨大 prompt”理解 Coding Agent,就会把三种任务混在一起:
-
本该人类实时判断的任务,被丢给后台,最后返工; -
本该自动排队的重复任务,被人盯着跑,浪费注意力; -
本该有 checkpoint 和 evaluator 的长任务,被塞进一次会话,最后漂移。
真正的问题不是 Agent 能不能写代码。
真正的问题是:每类开发任务应该进入哪条执行通道。
二、Cursor 3 的信号:编辑器正在变成 Agent 控制台
Cursor 3 的重点,不是界面换了。
它把一个更深的判断摆到了台面上:如果团队开始大量使用 Agent 写代码,那么开发者需要的不是一个更大的聊天侧边栏,而是一个 agent-first workspace。
Cursor 的官方描述里有几个关键词很值得看:
-
local 和 cloud agent 出现在同一个 sidebar; -
agent 可以从 mobile、web、desktop、Slack、GitHub、Linear 触发; -
cloud agent 能生成 demo 和 screenshot 供验证; -
local session 可以移到 cloud 继续跑; -
cloud session 也可以拉回 local 继续编辑和测试; -
worktree 用来隔离每个任务的文件和变更; -
best-of-n让同一任务并行跑多个模型和 worktree,再比较结果; -
Await让 Agent 等待后台 shell 命令或 subagent 完成。
这说明编辑器本身正在降级。
它不再只是“写代码的地方”。
它开始变成:
-
agent queue monitor; -
diff review station; -
worktree manager; -
cloud/local handoff console; -
task orchestration surface。
过去开发者的核心动作是输入代码。
现在越来越多核心动作变成:
-
定义任务; -
选择运行环境; -
设置权限; -
查看中间证据; -
比较多个 agent 输出; -
决定是否 merge。
这件事的本质是角色迁移。
开发者不是消失了。
开发者从“亲自写每一行代码的人”,变成“设计任务边界、验证输出质量、维护系统方向的人”。
三、Codex 的信号:后台开发不是聊天,而是容器化任务
Codex Cloud 的设计更直接。
它把 coding agent 明确放进 cloud task。
根据官方文档,一个云端任务大致是:
选择 repo -> 创建容器 -> checkout 分支 -> 执行 setup -> 应用网络策略 -> Agent 终端循环 -> 生成 diff -> 开 PR 或继续追问这里真正重要的不是“云端跑模型”。
真正重要的是任务边界被工程化了。
Codex Cloud environment 有几个关键约束:
-
每个任务在自己的容器环境里跑; -
setup 阶段可以安装依赖; -
agent 阶段默认关闭公网访问; -
repo 里有 AGENTS.md时,会用它读取项目级指令、测试和 lint 规则; -
容器缓存可以提高后续任务启动速度; -
最终输出不是一句“我完成了”,而是 diff、日志、测试证据和 PR 入口。
这就是后台开发队列的雏形。
一个成熟的 Coding Agent 后台任务,不应该只是:
帮我修一下这个 bug它应该更像一个任务包:
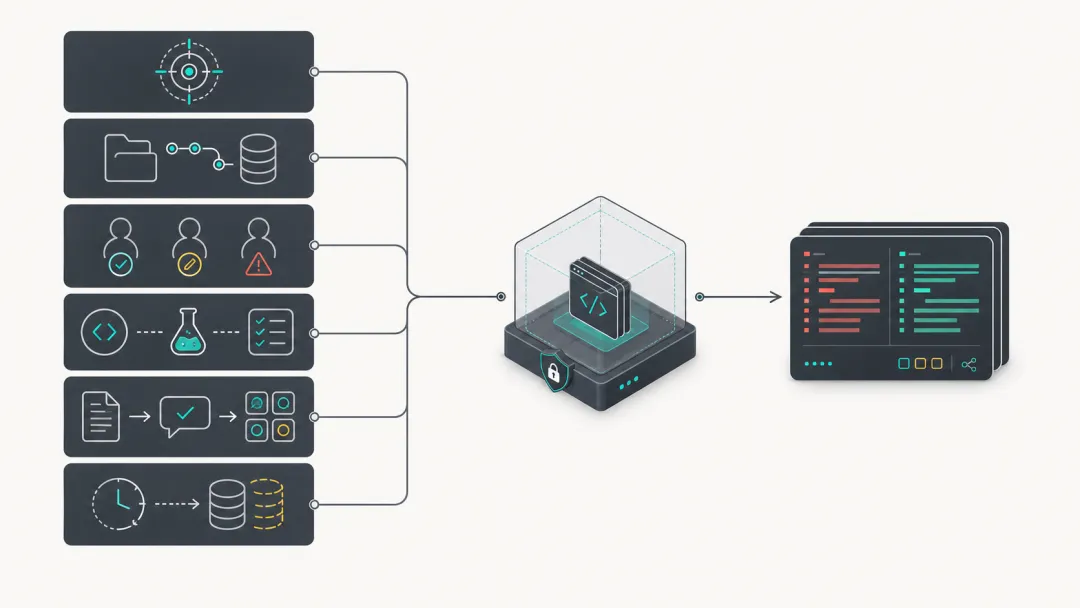
最小任务包至少应该包含:
-
Scope:允许改哪些目录、哪些文件、哪些模块; -
Environment:依赖怎么装,服务怎么起,测试在哪里跑; -
Permission:能不能联网,能不能写外部文件,能不能改 CI、权限、数据库迁移; -
Acceptance:什么叫完成,必须通过哪些测试或人工检查; -
Evidence:需要返回哪些日志、截图、benchmark、diff 摘要; -
Rollback:失败后怎么恢复,是否要求每个阶段 commit。
如果没有这些字段,所谓“后台 Agent”只是把不确定性搬到了云端。
它看起来更自动。
但系统风险更大。
四、Claude Code 的信号:长期运行靠协议,不靠记性
长任务是 Coding Agent 最容易制造错觉的地方。
模型连续跑了几个小时,看起来很强。
但真正的问题不是它能不能一直输出,而是它能不能在长时间里不漂移。
Claude Code 的 memory 和 hooks 文档给了一个很清晰的方向:
-
CLAUDE.md是项目级持久指令; -
auto memory 记录模型从项目和纠正中学到的模式; -
hooks 在生命周期关键点执行 deterministic control; -
如果某件事必须发生,不应该只写进 prompt,而应该写成 hook; -
PreToolUse可以阻断危险动作; -
SessionStart、InstructionsLoaded、CwdChanged这类事件可以把上下文、环境和观测接进 agent loop。
这背后的判断很重要:
Prompt 是建议。Hook 是协议。
长任务不能只靠模型“记得”。
它需要外部结构:
-
progress file 记录推进到哪里; -
test oracle 判断有没有真的变好; -
evaluator 用 fresh context 审查结果; -
git commit 做 checkpoint; -
hooks 做不可绕过的边界; -
kill switch 允许人类中断; -
handoff file 让下一轮 session 接上。
Anthropic 的 long-running agents 示例里,有三个机制尤其关键:
-
default-fail contract:验收条件默认失败,必须有证据才允许通过; -
fresh-context evaluator:不要让写代码的 Agent 自己给自己打分; -
agent-maintained handoff:Agent 自己维护进度记录和 git checkpoint。
这才是长任务的核心。
不是让一个 Agent 在上下文窗口里硬撑十几个小时。
而是把任务拆成可恢复的状态机。
五、真正的护城河是验证门
Coding Agent 的产物很危险,因为它通常“看起来像代码”。
而代码最容易欺骗非运行状态下的人。
一段 diff 很工整。
commit message 很完整。
解释也很自信。
但它可能没有跑测试,可能修了表层问题,可能引入隐蔽回归,可能只是让错误路径不再暴露。
所以 Agent 产物不能直接进入生产路径。
必须过验证门。

我会把 Coding Agent 的验证分成五层:
-
Static Gate:格式化、lint、类型检查、依赖锁文件检查。 -
Behavior Gate:单测、集成测试、关键路径回归。 -
Sandbox Gate:在隔离环境里启动服务、跑真实交互、验证 UI 或 API。 -
Security Gate:检查权限、网络访问、敏感文件、危险命令、依赖变化。 -
Review Gate:人类只审查结构性判断,不再逐行承担所有发现责任。
这不是流程洁癖。
这是 Agent work 的最低工程化。
因为 Coding Agent 最大的成本,不是它写错一行代码。
最大成本是:它把错误包装成一个看起来完整的交付件,让团队在错误的信心里继续推进。
六、团队应该建立 Coding Agent Ops,而不是买一堆工具
现在很多团队的问题是工具采购过快,工作流设计太慢。
今天试 Cursor。
明天试 Codex。
后天试 Claude Code。
再接 Aider、Cline、Roo、各种 MCP server。
表面上看很先进。
实际可能是在制造新的混乱。

我更建议先建立一套 Coding Agent Ops Protocol。
1. 任务分级
把开发任务分成三类:
-
Interactive:需求不稳定,需要人类持续判断,放前台; -
Batch:规则清晰、验收明确、可并行,放后台队列; -
Long-running:需要跨 session、跨环境、持续推进,放运行时系统。
不要让所有任务都进同一个 Agent。
2. 任务模板
每个后台任务必须有最小 schema:
{"goal":"要完成什么","scope":["允许修改的路径"],"out_of_scope":["明确不能碰的区域"],"environment":"如何启动和验证","permissions":"网络、文件、命令权限","acceptance":["通过什么才算完成"],"evidence":["需要返回哪些日志或截图"],"rollback":"失败后如何恢复"}不要把任务写成愿望。
要把任务写成协议。
3. 环境标准化
后台 Agent 最怕环境不一致。
本地能跑、云端不能跑。
Agent 改了代码,但没启动依赖。
测试脚本缺少 secret。
package manager 版本不一致。
所以每个 repo 至少要有:
-
setup script; -
test command; -
lint command; -
dev server command; -
secret 注入规则; -
sandbox / container 描述; -
AGENTS.md或等价项目指令。
没有环境标准化,Agent 只是更快地撞墙。
4. Review Packet
Agent 交付的不应该只是 diff。
它应该交付 review packet:
-
改了什么; -
为什么这样改; -
跑了什么验证; -
哪些没验证; -
风险在哪里; -
需要人类重点看哪里; -
如何回滚。
这会极大降低 review 成本。
真正的效率提升,不是让人少看代码。
而是让人只看最该看的判断点。
七、几个不要做的事
第一,不要用 benchmark 决定全部工作流。
Benchmark 只能说明模型上限,不说明你的 repo、权限、测试、环境和审查流程能不能承载它。
第二,不要给后台 Agent 一个无限大的任务。
“重构整个系统”不是任务,是事故邀请函。
第三,不要默认开启 full access。
Agent 自动化的前提不是信任,而是边界。
第四,不要让写代码的 Agent 自己宣称任务完成。
至少要有独立验证器,最好有 fresh context。
第五,不要把 memory 当聊天历史。
长任务需要的是 progress、decision、failure、checkpoint 和 handoff,不是一长串对话。
第六,不要让所有工具暴露给所有 Agent。
工具越多,越需要路由、权限、审计和最小可见面。
八、这件事对开发者意味着什么
很多人担心 Coding Agent 会不会替代程序员。
我觉得这个问题问得太粗。
更准确的问题是:程序员的工作界面正在从代码编辑器,迁移到任务系统。
未来有价值的开发者,不一定是每分钟敲最多代码的人。
而是能把复杂需求拆成可执行任务、把隐性判断写成规则、把项目经验沉淀成 memory、把交付质量绑定到验证门的人。
过去,工程能力体现在你怎么写代码。
现在,工程能力越来越体现在你怎么组织 Agent 写代码。
这不是从人到 AI 的替代。
这是从手工编码,到任务协议、运行时、验证系统和反馈闭环的迁移。
工具解决编码速度。
队列、协议和验证,才形成工程杠杆。
参考资料
-
Cursor Blog: Meet the new Cursor[1] -
Cursor Docs: Agents Window[2] -
Cursor Docs: Cloud Agents[3] -
Cursor Docs: Cloud Agent Capabilities[4] -
OpenAI Developers: Codex Cloud[5] -
OpenAI Developers: Codex Cloud environments[6] -
OpenAI Developers: Agent approvals & security[7] -
Claude Code Docs: How Claude remembers your project[8] -
Claude Code Docs: Automate workflows with hooks[9] -
Anthropic Research: Long-running Claude for scientific computing[10] -
GitHub: anthropics/cwc-long-running-agents[11] -
SitePoint: Running AI Coding Agents for 13 Days Straight[12] -
V2EX: Codex 明早重置额度,上号,/fast 开蹬了[13] -
V2EX: 想请教一下怎么提升全栈能力[14]
引用链接
[1]Meet the new Cursor: https://cursor.com/blog/cursor-3
[2]Agents Window: https://cursor.com/docs/agent/agents-window
[3]Cloud Agents: https://cursor.com/docs/cloud-agent
[4]Cloud Agent Capabilities: https://cursor.com/docs/cloud-agent/capabilities
[5]Codex Cloud: https://developers.openai.com/codex/cloud
[6]Codex Cloud environments: https://developers.openai.com/codex/cloud/environments
[7]Agent approvals & security: https://developers.openai.com/codex/agent-approvals-security
[8]How Claude remembers your project: https://code.claude.com/docs/en/memory
[9]Automate workflows with hooks: https://code.claude.com/docs/en/hooks-guide
[10]Long-running Claude for scientific computing: https://www.anthropic.com/research/long-running-Claude
[11]anthropics/cwc-long-running-agents: https://github.com/anthropics/cwc-long-running-agents
[12]Running AI Coding Agents for 13 Days Straight: https://www.sitepoint.com/run-ai-coding-agents-continuously-days-without-losing-plot/
[13]Codex 明早重置额度,上号,/fast 开蹬了: https://www.v2ex.com/t/1216791
[14]想请教一下怎么提升全栈能力: https://www.v2ex.com/t/1216933