 夜雨聆风
夜雨聆风





传统RAG答不准跨文档问题?试试Graph RAG,效果颠覆想象
5月29日我们介绍了 Vanna AI——让AI直连数据库,10分钟跑起来,还讲了代码级权限管控。
“数据库查数据搞定了,但公司那么多文档——产品手册、SOP、合同、客服话术——能不能也让AI读懂,还能控制谁能问什么?“
今天就介绍一个完整的落地方案:FastGPT + Graph RAG + 集合权限管控。
三篇文章的关系
|
维度 |
第一篇:DB-GPT |
第二篇:Vanna AI |
今天第三篇:FastGPT |
|
解决什么问题 |
AI直连数据库查数据 |
轻量级AI直连数据库 |
AI读懂企业文档并问答 |
|
部署方式 |
Docker + 服务器 |
pip install,本地跑 |
Docker Compose一键部署 |
|
核心技术 |
Text2SQL + RLS权限 |
Text2SQL + 代码级权限 |
Graph RAG + 集合权限 |
|
适合场景 |
企业级正式部署 |
快速验证、小团队 |
知识库问答、文档管理 |
|
权限管控 |
数据库层RLS |
Python代码级过滤 |
集合权限(内置) |

为什么说今天的内容和前两篇不一样?
前两篇的核心是:把数据库里的结构化数据变成自然语言回答。
但企业里80%的知识是非结构化的——产品手册、SOP、合同、客服话术、会议纪要……这些存在文档里,数据库查不到。
传统RAG的痛点(前两篇没讲,但今天要解决):
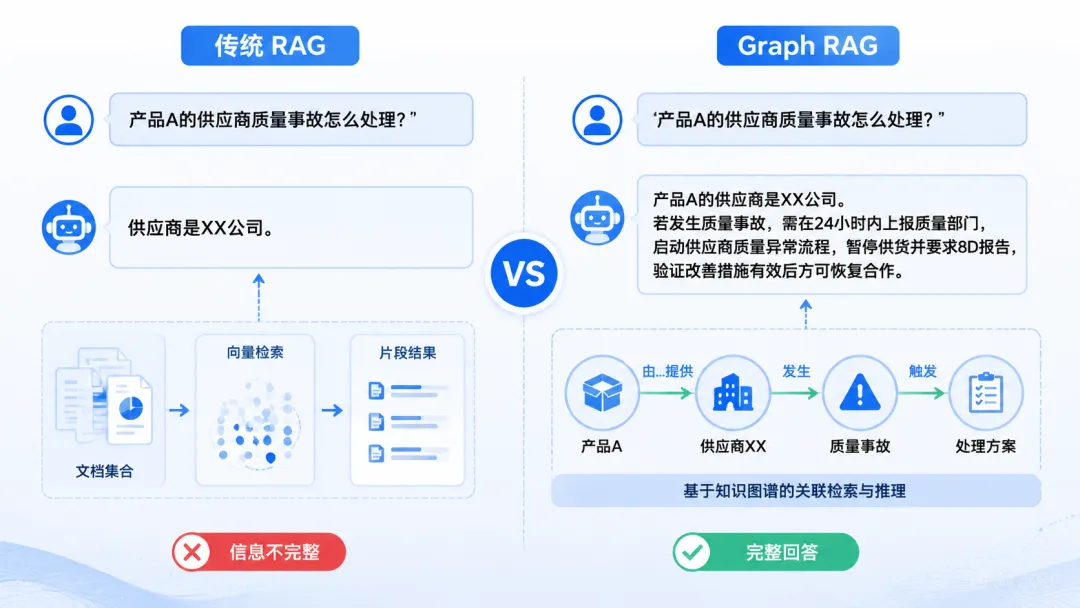
问:“A产品的供应商是谁?之前出过什么质量事故?怎么处理的?“
传统RAG:只能找到“A产品的供应商是XX公司“,但找不到“质量事故“和“处理方案“——因为不知道文档之间的关联关系。
今天的内容结构
• FastGPT快速部署(Docker Compose一键,10分钟)
• 构建知识图谱(让AI理解文档之间的关联)
• 集合权限管控(谁能问哪些文档——延续前两篇的权限主题)
• Graph RAG vs 传统RAG效果对比
• 和前两篇方案的组合建议
第一部分:FastGPT快速部署(10分钟)
为什么选FastGPT,而不是自己搭LangChain?
|
对比维度 |
自己搭LangChain |
FastGPT |
|
部署时间 |
1~3天 |
10分钟 |
|
界面 |
需要自己写 |
开箱即用 |
|
权限管控 |
需要自己实现 |
内置集合权限 |
|
Graph RAG |
需要自己实现 |
内置(V4.14+) |
|
维护成本 |
高 |
低(Docker一键更新) |
结论:今天的目标是“落地“,不是“研究RAG原理“。FastGPT是2026年最成熟的开源知识库平台。
前置条件
• 一台电脑/服务器(最低配置:2核4GB,推荐4核8GB)
• 已安装Docker Desktop(Windows/Mac)或Docker Compose(Linux)
• 约10分钟时间
|
💡 可以用个人电脑测试,确认效果后再迁移到服务器。 |
Step 1:获取配置文件(2分钟)
FastGPT提供一键部署脚本,自动生成docker-compose.yml和config.json。
在终端执行:
|
bash <(curl -fsSL https://doc.fastgpt.cn/deploy/install.sh) |
脚本会问你几个问题:1. 部署环境(本地测试/生产环境);2. 向量数据库(选PgVector,轻量);3. IP地址(本地填localhost)。
Step 2:修改环境变量(可选,3分钟)
打开docker-compose.yml,找到fastgpt服务的环境变量:
|
fastgpt: environment: – DEFAULT_ROOT_PSW=你的密码# 默认是1234,建议改掉 – OPENAI_BASE_URL=https://api.deepseek.com/v1 – CHAT_API_KEY=你的DeepSeek API Key |
|
⚠️ 安全提醒:生产环境一定要改默认密码!或者用强密码。 |
Step 3:启动FastGPT(5分钟)
在docker-compose.yml所在目录执行:
|
docker compose up -d |
等待约3~5分钟,看到以下容器都显示Up说明启动成功:
|
docker ps # 应该看到这些容器: # fastgpt(主服务,端口3000) # mongo(数据库) # pg(向量数据库) # ai-proxy(模型聚合服务) |
Step 4:访问并初始化(现在就能用)
打开浏览器,访问: http://localhost:3000
默认登录信息:用户名 root,密码 1234(或你改的密码)。
第二部分:构建知识图谱(Graph RAG核心)
传统RAG vs Graph RAG
|
对比 |
传统RAG |
Graph RAG |
|
检索方式 |
语义相似度 |
语义相似度 + 知识图谱关联 |
|
跨文档问答 |
效果差 |
效果好 |
|
多跳推理 |
不支持 |
支持(A→B→C) |
举例说明:
问题:“A产品的供应商是谁?之前出过什么质量事故?怎么处理的?“
传统RAG:只能找到“A产品的供应商是XX公司“——另外两份文档找不到。
Graph RAG:构建知识图谱后,AI知道:产品A → 供应商XX公司 → 质量事故记录 → 处理方案。三份文档关联起来,一次性回答完整。
Step 1:准备测试文档(现在就能做)
在FastGPT主界面,点击“知识库” → “新建“,上传这些文档(如果没有,可以用虚拟数据):
• 产品手册.pdf(包含:产品A/B/C的规格、供应商、价格)
• 质量事故报告.pdf(包含:产品A在2025年Q3的供应商XX来料不合格记录)
• 处理方案.pdf(包含:针对供应商XX的不合格品处理流程和改进措施)
💡 测试目标:问“产品A的供应商是谁?出过什么质量问题?怎么处理的?“——看AI能不能跨3份文档完整回答。
Step 2:开启Graph RAG(核心步骤)
FastGPT V4.14+ 内置Graph RAG,但默认关闭,需要手动开启。
修改config.json,添加Graph RAG配置:
|
{ “systemEnv”: { “enableGraphRAG”: true, “graphRAGModel”: “deepseek-chat”, “graphRAGTopK”: 5 } } |
修改后重启FastGPT:
|
docker compose down && docker compose up -d |
进入知识库设置页面,打开“Graph RAG”开关,保存设置。
Step 3:让FastGPT自动构建知识图谱(无需手动操作)
关键点:FastGPT会自动从文档中提取实体和关系,不需要你手动构建图谱。
上传文档后,FastGPT会:1. 提取实体(产品A、供应商XX、质量事故、处理方案);2. 提取关系(产品A → 供应商XX,供应商XX → 质量事故);3. 存储到图数据库。
查看图谱构建进度:进入知识库 → “图谱管理“(V4.14+新增功能),可以看到已识别的实体和关系。
Step 4:测试Graph RAG效果(核心验证)
在FastGPT的“应用“模块,创建一个“简易应用“,关联刚才的知识库。
测试问题:
|
问题1(单跳):产品A的供应商是谁? → 传统RAG和Graph RAG都能回答 问题2(多跳):产品A的供应商出过什么质量事故? → 传统RAG可能找不到,Graph RAG可以 问题3(复杂多跳):产品A的供应商的质量事故是怎么处理的? → 传统RAG基本回答不了,Graph RAG可以 |
||
|
问题 |
传统RAG |
Graph RAG |
|
问题1(单跳) |
✅ 准确 |
✅ 准确 |
|
问题2(多跳) |
❌ 找不到 |
✅ 准确 |
|
问题3(复杂多跳) |
❌ 回答不完整 |
✅ 完整回答 |
第三部分:集合权限管控(延续前两篇的核心主题)
为什么权限管控重要?
场景1:客服只能问产品手册,不能问合同条款
• 客服问:“产品A的保修条款是什么?“——可以
• 客服问:“公司和供应商XX的采购合同金额是多少?“——不应该能查到
场景2:HR只能问SOP,不能问工资条
• HR问:“入职流程是什么?“——可以
• HR问:“张三的工资是多少?“——不应该能查到
场景3:销售只能问自己客户的历史记录
• 销售问:“客户A的购买历史?“——可以(如果是他的客户)
• 销售问:“客户B的购买历史?“——如果不归他管,不应该能查到
FastGPT的集合权限(内置,开箱即用)
前两篇讲了:第一篇:数据库层RLS(需要配置PostgreSQL/SQL Server);第二篇:Python代码级权限过滤(需要写代码)。
今天第三篇:FastGPT内置“集合权限“,界面配置,不需要写代码。
实操:配置集合权限(5分钟)
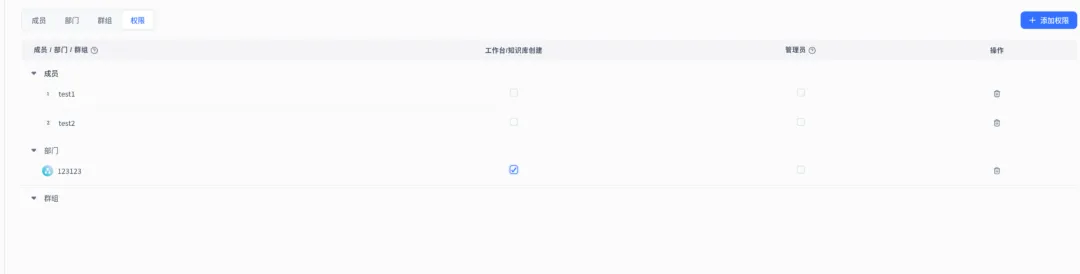
Step 1:创建“集合“(对应不同的权限组)
进入“权限管理” → “集合管理“,创建以下几个集合:
|
集合名称 |
包含的文档 |
允许访问的角色 |
|
产品知识库 |
产品手册、规格书 |
所有人(客服/销售/HR) |
|
质量记录库 |
质量事故报告、检验报告 |
质量部、管理层 |
|
合同管理库 |
采购合同、供应商协议 |
采购部、管理层 |
|
人事制度库 |
SOP、入职流程、考勤制度 |
HR、管理层 |
|
薪酬管理库 |
工资条、奖金方案 |
仅限HR总监和管理层 |
Step 2:给用户/部门分配集合权限
进入“权限管理” → “用户管理“,编辑用户/部门,分配可访问的集合。
示例配置:
|
用户/部门 |
可访问的集合 |
|
客服团队 |
产品知识库 |
|
质量部 |
产品知识库、质量记录库 |
|
采购部 |
产品知识库、合同管理库 |
|
HR团队 |
产品知识库、人事制度库、薪酬管理库(仅HR总监) |
|
管理层 |
所有集合 |
Step 3:测试权限是否生效
测试方法:1. 用“客服账号“登录;2.问:“产品A的供应商是谁?” → 应该能回答(产品知识库有权限);3. 问:“公司和供应商XX的合同金额是多少?” → 应该拒绝回答(合同管理库无权限)。
如果权限配置正确,FastGPT会返回:“抱歉,您没有权限查询相关内容。“
第四部分:和前两篇方案的组合建议
三篇方案的定位:
|
方案 |
解决的核心问题 |
适合的场景 |
|
第一篇:DB-GPT |
AI直连数据库查数据 |
老板/分析师查经营数据 |
|
第二篇:Vanna AI |
轻量级AI直连数据库 |
小团队快速验证 |
|
今天第三篇:FastGPT |
AI读懂文档并问答 |
客服/HR/全员知识库 |
成本对比(三篇方案对比)
|
项目 |
第一篇:DB-GPT |
第二篇:Vanna AI |
今天第三篇:FastGPT |
|
服务器 |
30元/月 |
0元(本地) |
0元/月 |
|
大模型API |
10~50元/月 |
10~50元/月 |
10~50元/月 |
|
总计 |
40~80元/月 |
10~50元/月 |
10~50元/月 |
你能立刻行动的第一步
1. 明天:用Docker Compose部署FastGPT(10分钟),确认能跑起来
2. 明天:上传3份测试文档,开启Graph RAG,测试多跳问答效果
3. 本周:配置集合权限,创建2~3个测试账号,验证权限隔离
4. 本周:如果效果OK,导入公司真实文档,邀请客服/HR试用