 夜雨聆风
夜雨聆风
前几篇文章,我一直在讲一件有点大的事:
怎么让 AI 去处理一个历史工程里的单测覆盖长任务。
再讲 历史单测覆盖这类任务,白天怎么拆、晚上怎么跑、早上怎么看证据。
然后又补了一篇:AI 能把覆盖率推上去以后,单测的价值到底在哪里。
写到这里,我发现还有一块没讲完。
真正值得留下来的,不是某一次我让 AI 跑了多久,也不是某个模块覆盖率涨了多少。
这其实也接上了我前面写过的几篇 Skill 方法论。
我之前写过 为什么 Skill 比 Prompt 更值得沉淀,也写过 一个 Skill 写坏了是什么感觉,后来还写过 怎么把团队里的私有 Skill 管起来。
但那些文章更多是在讲方法论。
这一次,单测覆盖长任务把这套方法论重新打了一遍。
更值得留下来的,是这次实践里反复出现的那些判断:
什么模块适合推进单测?
覆盖率低的时候先看哪里?
AI 说“这行不可覆盖”,我能不能信?
什么时候继续逼它想办法,什么时候停下来登记?
测试 PR 能不能顺手改生产代码?
覆盖率门禁到底怎么挂,才不会变成一个好看的摆设?
这些问题,如果每次都靠临场提醒 AI,下一次还会重新踩一遍。
所以后来我把它整理成了一个 Skill。
名字叫 unit-test-cover。
我更想讲的是:一次 AI Coding 实践,怎么从“我给了一段 Prompt”变成“我沉淀了一套可复用的工作规程”。
一句“帮我补单测”不够
一开始,我当然也想过直接说:
帮我给这个模块补单测,把覆盖率推上去。
这句话太顺了。
尤其现在的 Claude Code、Codex 这类工具,确实能读代码、写测试、跑命令、修失败,还能一轮一轮往前拱。
但这句话的问题也很明显。
它只说了目标,没有说边界。
AI 会补测试。
但它可能补出只执行、不保护的测试。
比如只断“结果非空”,或者只断“没有抛异常”。
它也可能为了让覆盖率好看,去测一堆没有业务意义的 getter、空分支、防御性残留。
它可能根据当前实现反推断言。
如果当前实现里本来有 bug,它就一本正经地把 bug 写成“预期行为”。
它还可能把真实依赖全部 mock 掉,然后告诉你“已经覆盖了”。
更麻烦的是,补测试时经常会撞到历史代码不好测。
这时候 AI 很容易顺手改一下生产代码。
改完测试过了,看起来很积极。
但 review 的人就难受了。
这批改动到底是在补测试,还是偷偷改了行为?
如果线上老行为被改掉,是修 bug,还是破坏兼容?
这种时候,一句 Prompt 兜不住。
它需要一套规程。
下面这张图想表达的就是这个转变:左边是一句临时 Prompt 和零散测试笔记,右边是一套可以反复调用的 Skill 工作规程。真正变化的不是 AI 变聪明了,而是人把边界、步骤和验收方式写出来了。
unit-test-cover 不是写测试 Prompt
我后来给这个 Skill 定的目标,不是“生成测试”。
而是“推进一个模块的单测覆盖到可收口状态”。
这两个说法差别挺大。
生成测试,只关心产出测试文件。
推进覆盖,还要关心准入、复测、判断、门禁和登记。
我把它压成五个动作:
| 阶段 | 要解决的问题 |
|---|---|
| 清盘 | 这个模块适不适合用单测推进 |
| 建测 | 先按什么规范和测试栈写 |
| 冲覆盖 | 每轮怎么看未覆盖行、套什么技法 |
| 挂门禁 | 覆盖率 floor 怎么防倒退 |
| 登记 | 疑似缺陷、死代码、真不可约放哪里 |
如果把 unit-test-cover 画成流程,它更像下面这五步:先看模块是否适合进入单测覆盖,再按规范建测,接着一轮轮冲覆盖,最后挂门禁并把疑似问题登记下来。它不是一口气把测试写满,而是每一步都留下证据。
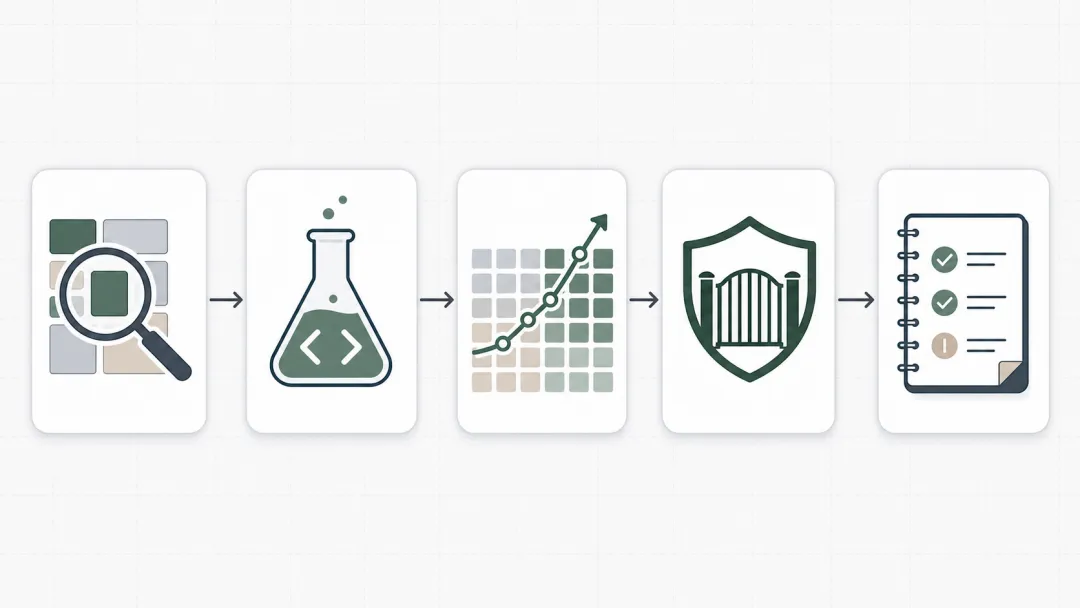
这五个动作里,真正有价值的不是“让 AI 干活”。
而是把人脑里那些容易遗漏的判断,提前写进流程。
比如:
启动层、集成层、模拟器,不要硬拿单测覆盖去啃。
真实中间件风险,不要在单测里用半真半假的方式糊过去。
疑似生产 bug,不要在测试 PR 里顺手修。
覆盖率门禁不是越高越神圣,而是要基于当前实测 floor,后面只升不降。
这些话如果只在聊天里说一次,很快会丢。
写进 Skill,下一次它就会变成启动规则。
第一层:先读单一事实源
unit-test-cover 里面最重要的一点,是它没有把所有规范都塞进 Skill 正文。
它先要求 AI 去读三类文档。
在一个真实项目里,大概会是这样:
docs/test/module-unit-test-conventions.mddocs/test/module-unittest-playbook.mddocs/test/test-findings.md
第一份是单测规范。
它负责写清楚测试框架、目录约定、mock 纪律、覆盖率门禁模板,以及哪些事情不能在单测里做。
第二份是模块 playbook。
它更像实战手册。
某类代码怎么测,哪些地方容易误判为不可覆盖,哪些分支可以用什么技法打下来,都放在这里。
第三份是 findings。
它记录测试过程中发现的疑似缺陷、死代码、真不可约和后续处理建议。
这一点对历史工程很重要。
因为补测试一定会照出问题。
照出来以后不能装作没看见,也不能顺手乱修。
先登记。
测试 PR 只负责补保护。
生产行为修复另走分支。
这条纪律看起来慢,但能让 review 人知道:这次改动到底是什么。
第二层:每一轮都要看证据
unit-test-cover 的执行环很土。
先跑测试。
再读覆盖率。
找最大未覆盖类。
再去看具体未覆盖行。
然后小批补测试。
补完再跑全模块。
听起来没有什么玄学。
但历史单测覆盖最需要的,恰恰是这种土办法。
因为 AI 很容易在对话里给你一种“我正在推进”的感觉。
可到底推进到哪里了?
哪些类还裸着?
哪些行是没有测到,哪些行是测不到?
失败是测试写错了,还是历史行为没说清?
这些都不能靠总结。
要看命令、覆盖率报告、未覆盖行和失败清单。
所以 Skill 里会要求每一轮都做几件事:
| 动作 | 目的 |
|---|---|
| 跑单模块测试 | 确认当前状态,不在脏基础上写 |
| 读 coverage 报告 | 找到真实缺口,不凭感觉补 |
| 排未覆盖类 | 先处理最大风险面 |
| 查未覆盖行 | 判断是可测、不可约还是死代码 |
| 小批补测试 | 降低一次 diff 的 review 难度 |
| 全模块复测 | 防止局部过了、整体坏了 |
这套流程并不酷。
但它能让 AI 的“努力”变成可验收的证据。
第三层:把经验做成技法表
这次实践里,最适合沉淀成 Skill 的,是“类型到技法”的决策表。
因为补单测不是从零发明。
很多问题会反复出现。
比如 service 编排类怎么测。
配置类怎么测。
静态工具怎么测。
构造器里直接 new 出来的客户端怎么测。
网络 handler 怎么测。
并发分支怎么测。
AI 第一次遇到,可能会绕路。
第二次还靠口头提醒,就有点亏了。
所以我把它们整理成一张表:
| 被测类型 | 更适合的做法 |
|---|---|
| service / repository 编排 | mock 依赖,断返回值、状态和协作者入参 |
| configuration / properties | 直接构造,注入配置值,逐个产物断言 |
| 纯确定性静态工具 | 直接真实调用,不为了 mock 而 mock |
| 静态外部边界 | 用 static mock 包住边界 |
| 构造器内 new 的客户端 | construction mock,覆盖成功和失败分支 |
| 网络 handler | 用内存 channel 或 mock context,不连真实网络 |
| wrapper / DAO | 初始化必要元数据,断查询条件或写入参数 |
| private 方法 / 不可达守卫 | 谨慎反射直达,用来固定历史行为 |
| 并发分支 | 用 latch / lock 控制时序,不靠 sleep 赌 |
| 真不可约 | 不硬测,写清原因,交给集成测试或人工确认 |
这张表不是为了炫技。
它的价值在于减少 AI 的自由发挥。
比如网络相关代码,不能为了补单测就真的连一个外部服务。
单测这一层要保持便宜、稳定、可重复。
再比如并发分支,不能靠 sleep 碰运气。
能用锁和 latch 控住时序,就把时序写死。
还有 private 方法和不可达守卫。
这类东西不能滥用反射。
但历史代码里确实会有一些防御分支、兼容分支、死代码边界。
如果要判断它到底是不是不可约,偶尔需要用反射把行为钉出来。
关键是,Skill 里要写清楚:
反射不是常规入口。
它是最后的核验工具。
真不可约也不是 AI 说一句“测不了”就算。
要先穷尽更合理的技法。
实在不适合单测,再登记原因。
第四层:门禁不是装饰
单测覆盖推进到最后,一定会碰到门禁。
以前我对 coverage gate 的理解比较粗。
好像挂上去就行。
这次实践以后,我更愿意把它叫做 coverage floor。
它不是荣誉墙。
它是棘轮。
意思是:
这个模块已经建立到某个最低保护水平了,以后不要再掉回去。
所以 unit-test-cover 里会强调几件事。
第一,floor 基于实测结果。
不要拍脑袋写一个漂亮数字。
第二,只升不降。
后续有人删测试、绕测试、让覆盖率掉下去,门禁要能拦住。
第三,不为了过门禁降低断言。
覆盖率数字上去了,但测试不保护行为,这种测试没有意义。
第四,不为了过门禁假造中间件。
单测不应该半真半假地连 DB、MQ、Redis、HTTP 服务。
真实依赖就放到代码级集成测试里验证。
这句话在前一篇也讲过。
单测的价值不是替代所有测试。
它是用最快、最稳定、最容易定位的反馈,挡住局部变更风险。
门禁也应该服务这个目标。
最小可复用 Skill 模板
如果把 unit-test-cover 压成一个读者可以改的版本,我会先保留这个骨架:
name: unit-test-coverdescription: Use when driving one module's unit-test coverageto the agreed coverage gate.# unit-test-cover把“清盘 → 建测 → 冲覆盖 → 挂门禁 → 登记”固化成可复用流程。## 输入`$ARGUMENTS` = 目标模块名。为空则先询问。## 单一事实源执行前先读:- `docs/test/module-unit-test-conventions.md`- `docs/test/module-unittest-playbook.md`- `docs/test/test-findings.md`缺失时停止,不凭记忆补全流程。## 准入1. 目标模块必须适合单测保护。2. 启动层、集成层、模拟器、未启用模块不进入本流程。3. 从最新主干拉新分支。4. 先确认模块依赖能构建。## 执行环1. 跑单模块测试和覆盖率。2. 读取 coverage 报告,找最大未覆盖类。3. 按 playbook 的类型到技法表补测试。4. 小批推进,每批跑全模块测试。5. 达到当前天花板后挂门禁。6. 登记疑似缺陷、死代码和真不可约。## 红线- 测试 PR 零生产代码改动。- 不假造中间件。- 不为了覆盖率降低断言。- 疑似生产 bug 先登记,不顺手修。- 真不可约必须写清原因和后续验证层级。
这份模板不能直接解决你的项目问题。
但它给了一个起点。
真正要复用时,至少还要补三份东西:
| 文档 | 你要写什么 |
|---|---|
| conventions | 本项目测试框架、命令、目录、门禁和红线 |
| playbook | 常见代码类型、测试技法、踩坑记录 |
| findings | 测试过程中发现但不在本 PR 修的问题 |
没有这三份文档,Skill 很容易退化成一段长 Prompt。
有了这三份文档,Skill 才能每次启动时重新加载项目规则。
这也是我现在越来越喜欢 Skill 的原因。
Prompt 更像一次提醒。
Skill 更像一份会被反复调用的工作说明。
和 /goal 接起来,爽点才出来
只写 Skill,其实还不够爽。
它更像一份工作规程。
真正把长任务跑起来,要把它和 /goal 接上。
比如单个模块可以这样写:
/goal 按 unit-test-cover 推进 <模块A> 单测覆盖,直到单模块测试通过、coverage floor 达标、疑似缺陷和真不可约都登记完成。
多个模块也可以拆成清单:
/goal 按 unit-test-cover 依次推进 <模块A>、<模块B>、<模块C>,每个模块独立跑测试、补覆盖、登记 findings、输出验收证据。遇到需要改生产逻辑或历史行为不明确时,停止当前模块并记录。
这时候体验就不一样了。
以前你要一轮一轮提醒:
•继续看 coverage。
•继续补这个类。
•再跑一次测试。
•失败原因写清楚。
接上 /goal 以后,这些“继续推进”的动作会变成目标的一部分。
在规范、命令和模块边界都写清楚的情况下,它可以自己跑基线、看未覆盖类、补测试、复测、登记 findings,再继续下一轮。
中间基本不用人工干预。
你早上回来看的,不是一段“我已完成”的总结,而是一批测试、覆盖率变化、命令结果和问题登记。
这件事确实很爽。
爽点不是 AI 突然会魔法。
爽点是:你不用再把同一句“继续按这个规则推进”重复说十几遍。
再给 AI 一张任务卡
除了 Skill,我还会给每个模块一张任务卡。
它不需要复杂。
关键是写清边界。
你现在处理【<模块名>】的单测覆盖推进。目标:- 补齐关键业务行为单测。- 提升到当前约定的 coverage floor。- 疑似缺陷、死代码、真不可约写入 findings。允许改动:- 测试文件。- fixture。- mock。- 测试辅助工具。禁止改动:- 生产逻辑。- 接口行为。- 历史兼容分支。- 覆盖率门禁预期。必跑命令:- <单模块测试命令>- <覆盖率或 verify 命令>停止条件:- 连续 3 轮无法推进。- 需要修改生产代码才能继续。- 历史行为预期不明确。- 必跑命令无法运行。最终输出:- 新增测试清单。- 执行命令和结果。- 覆盖率变化。- 待确认问题。- findings 登记项。
这张图对应的是我现在更习惯的协作方式:Skill 提供通用工作规程,任务卡限定当前模块边界,AI 负责在这两个约束之间推进,并把命令、覆盖率和 findings 作为证据交回来。

这张任务卡解决的是另一个问题:
Skill 是通用流程。
任务卡是当前模块的边界。
如果只靠 Skill,AI 知道怎么推进,但不知道这一轮具体目标。
如果只靠任务卡,AI 知道当前目标,但容易忘掉长期纪律。
两者合在一起,再交给 /goal 持续推进,才会从“AI 能帮我补测试”,变成“AI 可以自己把一整个模块,甚至一组模块,按同一套规程推进到可验收状态”。
这可能才是这轮单测覆盖实践里最值得留下来的东西。
不是某个神奇提示词。
而是一套下次还能继续用的工作规程。
