 夜雨聆风
夜雨聆风





AI助手的“身份确认”:意图识别与路由分流
摘要:本文将分享我如何在博客AI助手中通过”意图识别和路由分流“机制,让AI能够准确判断用户问题的类型,然后分流到不同的处理管道,决定是直接回答还是参考静态知识库或者向量知识库进行RAG,从而显著提升回答质量。这种”大脑分工”的设计思路,或许对大家在构建自己的AI应用时也有所启发。
一、问题的出现:一个AI助手的”身份危机”
久闻RAG大名的我,在为个人博客加入了基于DeepSeek的AI助手之后,立刻就去用 LangChain+ChromaDB 的方案,把自己的博客文章内容全部转换成了向量知识库。在博客AI助手的早期版本中,我采用了一种简单粗暴的方案:对所有问题都进行RAG(检索增强生成)流程。
好景不长,后来发现存在这样的问题:不管用户问了什么,程序都会跑到本地的知识库上去东翻西找,甚至出现“矮子里面选将军”的现象:
我:什么是CSS?(向量检索:CSS -> web学习笔记(二):CSS篇)AI:CSS是巴拉巴拉巴拉……(参考文章:数据结构(三):栈和队列)我:什么是码驿随想?(系统提示词:你是码驿随想的AI助手,基于DeepSeek实现,码驿随想是巴拉巴拉巴拉……)(向量检索:码驿随想 -> 代码 -> 栈 -> 数据结构 -> 数据结构(三):栈和队列)【说明:这样的检索过程是我瞎掰的,真正是怎么检索到栈和队列这篇文章的我不太清楚】AI:码驿随想是巴拉巴拉巴拉……(参考文章:数据结构(三):栈和队列)感觉像是RAG没有找到匹配度很高的数据,于是只能在一众相似度很小的数据里面勉强选择一个最高的出来作为参考资料,不仅干扰了AI的回答,还浪费了Token。

之所以出现这样的问题,是因为这些用户提问本质上属于完全不同的类型。如果让AI用同一套逻辑去处理所有问题,就像让一个人同时担任客服、技术顾问和法务顾问三种不同的身份,结果往往是顾此失彼,回答质量参差不齐。
二、尝试分析问题:三种身份的归类
经过一段时间的测试,我发现对于一个博客网站来说,用户的问题一般可以分为下三种:
-
条款问题:涉及网站信息、用户协议、隐私政策类型等比较固定的知识内容,如: -
“介绍一下这个网站。” -
“我可以转载网站上的文章吗?” -
技术问题:涉及专业知识相关的问题,通常是与网站上不定期更新的文章内容相关,如: -
“介绍一下AI的发展史。” -
“什么是HTML?” -
简单问题:不需要参考私域知识的简单问题,可以直接让大模型参考系统提示词回答,如: -
“你是什么大模型?” -
“你可以帮我做什么?”
在早期的无脑RAG策略下,AI助手的表现可谓一塌糊涂:
我:介绍一下网站的用户协议。(向量检索:《规范开发框架:spec-kit》:Spec-Kit是GitHub开源的规范驱动开发框架,它将AI编程从“感觉式编程”升级为“规范式编程”。通过宪法制定、需求说明、方案设计、任务拆解到代码实现七步标准化流程,让AI产出更可控、代码质量更高,特别适合中大型项目和团队协作。)AI:用户协议一般是用来……的文本,主要内容通常包括……我:介绍一下AI的发展史。(向量检索:《AI术语发展史:从LLM到Agent Skills》:本文系统梳理了 AI 生态从 LLM(大语言模型) 诞生到 Agent Skills(代理技能) 爆发的演进历程。文章首先从数学本质出发,解析了 LLM 如何通过 Transformer 架构实现能力的“涌现”;随后……)AI:根据网站上的文章《AI术语发展史:从LLM到Agent Skills》,AI的发展可以总结为……我:你可以帮我做什么?(向量检索:《Java学习笔记(一):Java概述及程序设计起步》:笔记系统梳理Java语言基础:先回顾Oak到Java的跨平台字节码设计,再厘清JDK/JRE/JVM与SE/EE/ME关系;继而从HelloWorld出发,示范源码→字节码→运行的全过程;随后依次讲解注释、8种基本类型……)(系统提示词:你是码驿随想的AI助手,基于DeepSeek实现,码驿随想是巴拉巴拉巴拉……)AI:我是码驿随想的AI助手,基于DeepSeek实现,可以帮你……除了第二个问题查询到的向量知识库内容比较符合用户问题之外,其他两个问题的检索效果很不理想;一方面可能是因为知识库的创建质量不够高;一方面说明不是所有的问题都适用RAG。
这三个场景揭示了一个核心问题:不同类型的问题,需要不同的处理策略。用一个万能方案解决所有问题,反而什么都解决不好。于是,我开始思考:能否让AI不要直接回答问题,而是先判断一下”这是什么类型的问题”,然后根据类型选择最合适的处理方式?
在询问AI和搜索相关资料后,才发现大佬们已经摸索除了应对这种问题的解决方案——”意图识别和路由分流“。
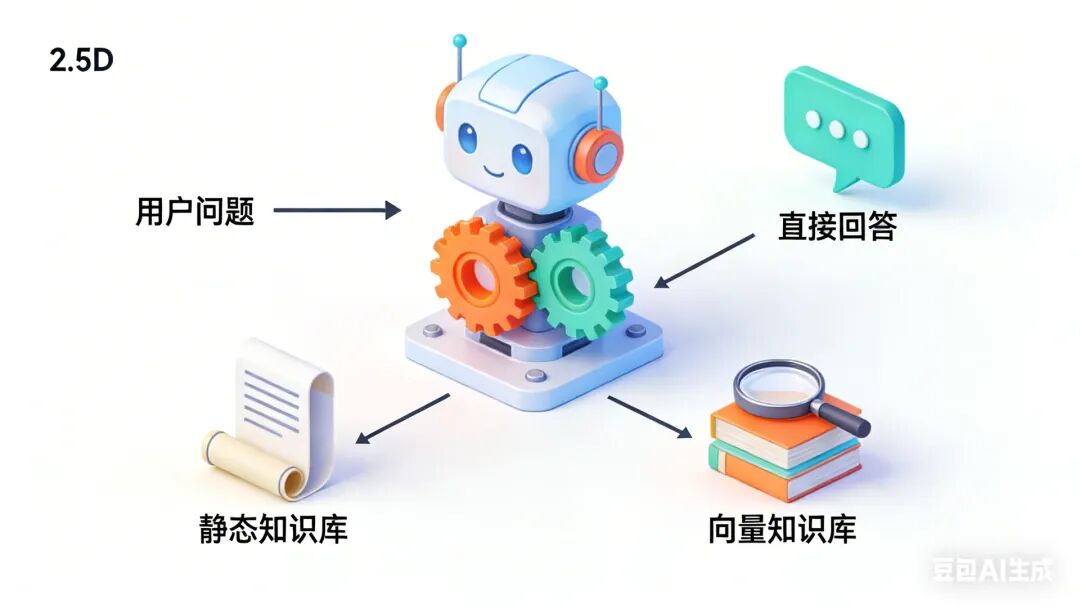
二、三种问题的本质分析
通过对用户问题的分析和归类,我发现博客AI助手面临的三大类问题可以这样处理:
1. 条款问题:固定知识的直接调用
这类问题的特点是:
-
内容固定:答案是预先写好的,不需要AI生成 -
高度结构化:通常是网站的介绍、协议、政策等正式文本 -
更新频率低:一旦确定,很少变动 -
期望精确:用户希望得到权威、一致的官方表述
典型问题示例:
-
“介绍一下这个网站。” -
“我可以转载网站上的文章吗?” -
“网站的隐私政策是什么?” -
“这个网站有版权声明吗?”
这类问题的最佳处理方式是:关键词匹配 直接关联静态知识库中预设的内容 → AI参考静态知识进行回复,完全不需要动用向量数据库进行检索。
2. 技术问题:知识检索的智能增强
这类问题的特点是:
-
内容动态:答案来源于博客中不定期更新的文章 -
需要推理:不是简单的文本匹配,需要理解和综合 -
上下文相关:可能涉及多篇文章的内容 -
期望专业:用户希望得到基于博客内容的准确解答
典型问题示例:
-
“介绍一下AI的发展史。” -
“什么是HTML?” -
“Django的MTV架构是什么?” -
“Vue和React有什么区别?”
这类问题的最佳处理方式是:用户提问 → 向量检索 → 构建上下文 → LLM生成回答,这是经典的RAG流程。
3. 简单问题:闲聊互动的自然对话
这类问题的特点是:
-
无需检索:不需要参考博客内容 -
依赖人设:答案取决于AI助手的角色设定 -
期望自然:用户希望得到流畅、友好的对话体验 -
轻量快速:不需要复杂的计算流程
典型问题示例:
-
“你是什么大模型?” -
“你可以帮我做什么?” -
“你好!” -
“今天天气怎么样?”(无关问题,由系统提示词直接决定拒绝回答)
这类问题的最佳处理方式是:直接调用LLM → 基于系统提示词生成回答,跳过所有检索流程。
三、意图识别:让AI学会”分类思考”
有了三类问题的划分,下一步就是让AI能够自动识别用户的问题属于哪一类。这就是意图识别。
3.1 识别方式的选择
在实现意图识别时,有两种主流的方案:
方案一:基于规则的关键词匹配
defclassify_by_keywords(query):if any(word in query for word in ['网站', '介绍', '协议', '隐私']):return'条款问题'elif any(word in query for word in ['如何', '什么', '怎么', 'Django', 'Python']):return'技术问题'else:return'简单问题'优点:快速、可控、无需API调用缺点:维护成本高、覆盖不全、容易误判
方案二:基于LLM的智能识别
defclassify_by_llm(query): prompt = f""" 判断用户问题的类型,输出JSON: {{ "type": "条款问题" | "技术问题" | "简单问题", "confidence": 0.0-1.0 }} 用户问题:{query} """ response = call_llm_api(prompt)return parse_json(response)优点:智能、灵活、理解语义缺点:需要API调用、增加响应时间
3.2 综合方案:LLM优先,规则降级
结合两种方案的优点,我采用了一种混合策略,让AI进行决策的同时,返回一个置信度的值;在这个值低于0.7时,就使用关键词进行兜底匹配,而不是采纳LLM把握度比较低的决策结果:
defclassify_query(query):try:# 优先使用LLM进行意图识别 result = classify_by_llm(query)if result['confidence'] > 0.7:return resultexcept APIError:pass# LLM失败或置信度低时,使用关键词匹配降级return classify_by_keywords(query)这种设计确保了:
-
正常情况下,使用LLM的智能识别,准确率高 -
异常情况下,降级到规则匹配,保证可用性
3.3 意图识别的提示词设计
经过反复调试,我发现提示词的设计对识别准确率影响巨大。需要详细、规范地定义数据交换的规则和格式,才能限制AI的自由发挥,方便后端的程序进行匹配和路由(有点像是手搓了一个Function Calling)。这是我最终使用的提示词:
INTENT_RECOGNITION_PROMPT = """你是"码驿随想"网站的AI助手。你的任务是判断用户问题的意图。【问题类型定义】1. 条款问题:网站介绍、用户协议、隐私政策、版权政策等固定内容2. 技术问题:需要检索博客文章的技术类、知识类问题3. 简单问题:问候、闲聊、关于AI助手自身的问题【判断规则】- 如果问题涉及网站的官方信息、协议、政策 → type="static"- 如果问题是技术性的、知识性的,可能需要检索文章 → type="need_rag"- 如果是问候、闲聊、或问AI助手自己的问题 → type="direct"【输出格式】请输出JSON(不要有其他内容):{ "type": "static" | "need_rag" | "direct", "confidence": 0.0-1.0, "reason": "简要说明判断理由"}用户问题:{query}"""关键点:
-
明确的三类定义 -
清晰的判断规则 -
要求输出JSON便于程序处理 -
包含confidence字段,便于实现降级策略
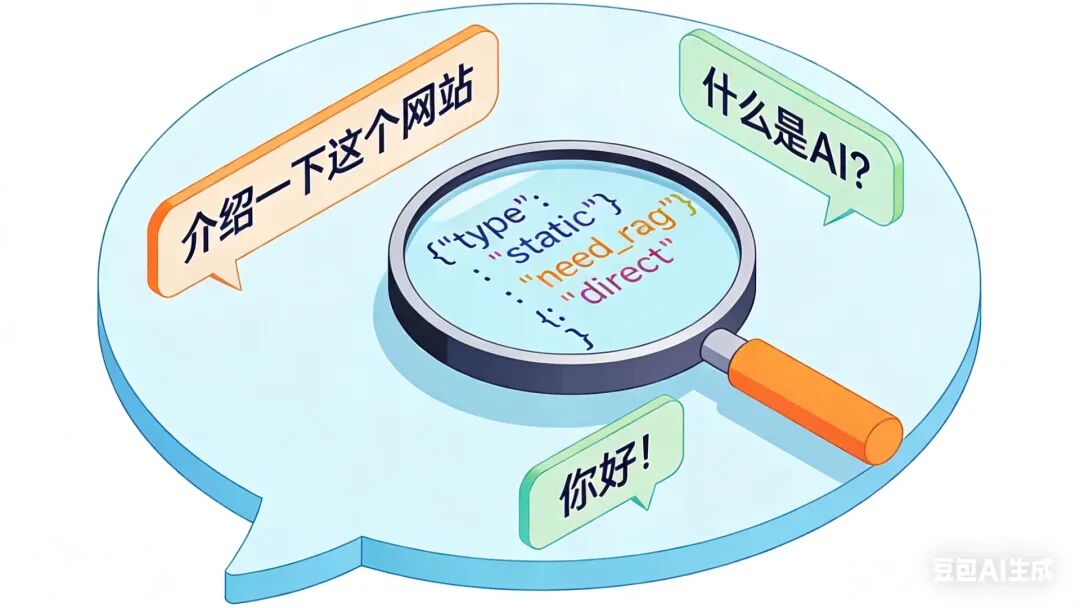
四、路由分流:为每种问题找到最佳路径
意图识别只是第一步,接下来需要根据识别结果,将问题路由到不同的处理管道。这就是路由分流。
4.1 整体架构
用户提问 │ ▼┌─────────────────┐│ 意图识别模块 ││ (LLM + 降级) │└────────┬────────┘ │ ┌────┴────┬────────────┐ │ │ │ ▼ ▼ ▼┌────────┐ ┌──────┐ ┌──────────┐│static │ │need_ │ │ direct ││ ↓ │ │ rag │ │ ↓ │└────────┘ └───┬──┘ └──────────┘ │ ▼ ┌─────────┐ │ 向量检索 │ │ + LLM │ └─────────┘4.2 static(条款问题)的处理流程
defhandle_static_query(query):# 1. 关键词匹配,找到对应的知识条目 knowledge = match_static_knowledge(query)# 2. 将知识内容发送给LLM,生成自然回答 prompt = f""" 基于以下内容,用自然的语言回答用户问题: 【知识内容】{knowledge['content']} 【回答要求】 - 用自然的语言组织回答,不要生硬地复制粘贴 - 保持友好、专业的语气 - 如果内容中有链接,在回答末尾附加:详细内容请查看:{knowledge['link']} 用户问题:{query} """ answer = call_llm_api(prompt)return answer关键设计:
-
不是直接返回原始内容,而是通过LLM重新组织 -
这样可以让回答更加自然,像真人在对话 -
同时保证了内容的准确性和一致性
4.3 need_rag(技术问题)的处理流程
defhandle_rag_query(query):# 1. 向量检索,获取相关文档 docs = vector_search(query, top_k=3)# 2. 构建增强提示词 context = format_docs(docs) prompt = f""" 你是"码驿随想"网站的AI助手。基于以下检索到的内容回答用户问题: 【检索到的相关内容】{context} 【回答要求】 1. 优先使用检索到的信息回答 2. 如果检索内容不足,可以适当补充你的通用知识 3. 用自然的段落组织回答,像朋友聊天一样 4. 不要追问用户,直接给出完整的回答 用户问题:{query} """# 3. LLM生成回答 answer = call_llm_api(prompt)return answer, docs # 同时返回参考文档,用于前端展示4.4 direct(简单问题)的处理流程
defhandle_direct_query(query):# 直接调用LLM,不需要检索 system_prompt = """ 你是"码驿随想"网站的AI助手,你的任务是: 1. 友好地回答用户的问题 2. 介绍你可以提供的帮助(回答博客相关技术问题) 3. 保持热情、专业的语气 4. 如果问题超出你的服务范围,礼貌地说明 """ answer = call_llm_api(query, system_prompt=system_prompt)return answer五、效果对比:分流后质量显著提高
回顾之前盲目RAG的生成效果:
我:介绍一下网站的用户协议。AI:用户协议一般是用来……的文本,主要内容通常包括……我:介绍一下AI的发展史。AI:根据网站上的文章《AI术语发展史:从LLM到Agent Skills》,AI的发展可以总结为……我:你可以帮我做什么?AI:我是码驿随想的AI助手,基于DeepSeek实现,可以帮你……采用精心设计的意图识别与路由分流策略后,AI助手的回复效果如下图所示:
前端AI表现:

后端日志分析:
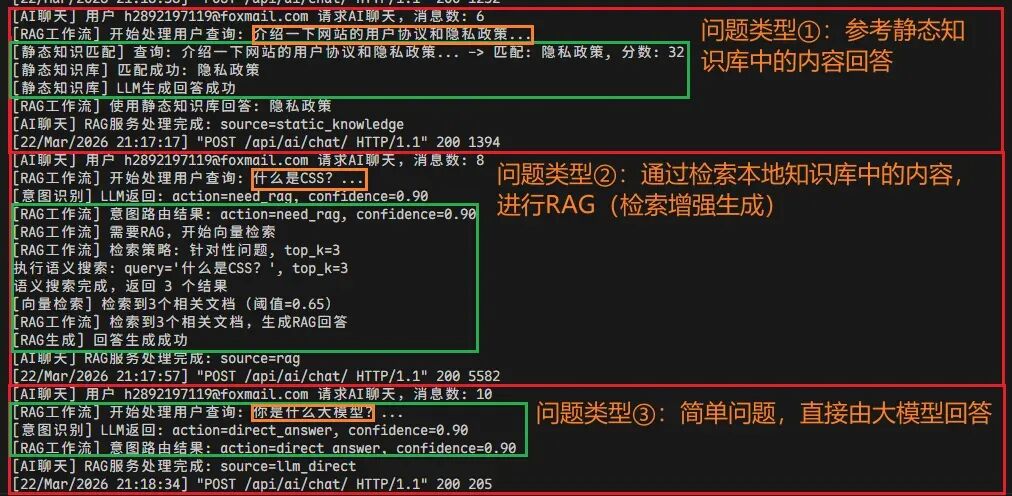
可以明显感受到,使用“意图识别与路由分流”的策略后,AI助手回复的消息质量明显比之前要好。
六、关键技术细节
6.1 静态知识库的优先级匹配
在初期实现static类型问题的关键词匹配时,发现了一个有趣的问题:多个知识条目可能发生误匹配:
我:介绍一下这个网站的用户协议。(关键词匹配:介绍一下这个网站)AI:码驿随想是一个技术博客网站,主要内容有…为了避免这样啼笑皆非的误匹配,需要引入优先级系统:
STATIC_KNOWLEDGE = {"website_intro": {"priority": 10, # 低优先级:通用关键词"keywords": ["网站介绍", "码驿随想", "这个网站"] },"user_agreement": {"priority": 30, # 高优先级:具体关键词"keywords": ["用户协议", "服务协议", "使用协议"] }}匹配算法:
defmatch_static_knowledge(query): matches = []for name, knowledge in STATIC_KNOWLEDGE.items(): matched_keywords = [ kw for kw in knowledge['keywords']if kw in query ]if matched_keywords: score = knowledge['priority'] + len(matched_keywords) matches.append((name, score))# 选择分数最高的匹配return max(matches, key=lambda x: x[1])这样,”用户协议”(30 + 2 = 32分)就会优先于”网站介绍”(10 + 1 = 11分)。
6.2 LLM调用失败时的降级策略
整个系统的鲁棒性依赖于完善的降级策略:
defprocess_query(query):# 第一层:意图识别降级try: intent = classify_by_llm(query)except APIError: intent = classify_by_keywords(query)# 第二层:根据意图类型处理if intent['type'] == 'static':return handle_static_query(query)elif intent['type'] == 'direct':return handle_direct_query(query)else: # need_rag# 第三层:RAG流程降级try:return handle_rag_query(query)except VectorSearchError:# 向量检索失败,降级为直接回答return handle_direct_query(query)这种多层降级确保了即使某个环节出错,系统仍然能够给出回答。
6.3 日志记录与调试
为了持续优化系统,我记录了每个查询的完整处理流程:
logger.info(f"""查询处理日志:- 用户问题: {query}- 意图识别: {intent['type']} (置信度: {intent['confidence']})- 处理流程: {processing_flow}- 响应时间: {response_time}ms- 使用文档: {len(retrieved_docs)}篇""")这些日志对于分析用户行为、优化提示词、发现系统问题都非常有价值。
七、总结与展望
通过实现意图识别和路由分流,我深刻体会到了几个关键点:
-
专业化分工比全能方案更有效 -
就像一个公司需要不同职能部门一样,AI系统也需要针对不同类型的问题采用不同的处理策略。试图用一种方案解决所有问题,往往是”平庸的全能”。 -
意图识别是AI系统的”大脑前额叶” -
在处理复杂任务之前,先判断任务的性质,然后分发给专门的模块处理。这种”三思而后行”的设计模式,可以显著提升系统的效率和准确性。 -
降级策略是生产系统的”安全网” -
在构建AI应用时,不能假设所有环节都完美运行。多层降级策略确保了系统的鲁棒性,即使在异常情况下也能给出可用的结果。
八、结束语
从最初的一个”万能AI”,到现在的”身份分工明确的专业助手”,这个转变让我深刻理解了AI应用设计的核心哲学:不要试图让AI一次做好所有事情,而是让它学会选择,用最合适的方式做好每一件事。
意图识别和路由分流,本质上就是给AI安装了一个”决策中枢”,让它能够根据问题的性质,智能地选择最优的处理路径。这种设计不仅提升了回答质量,也让整个系统更加清晰、可维护。还是那句话,AI的灵活决策与程序的固定规则相辅相成,刚柔并济,在实现从传统博客的静态内容展示到动态可交互的创新转型方向大有可为。

如果你的AI应用也面临着类似的问题多样性挑战,希望这篇文章能给你一些启发。好的AI不是无所不能的全能助手,而是知道自己该做什么、该怎么做的专业顾问。