夜雨聆风
夜雨聆风





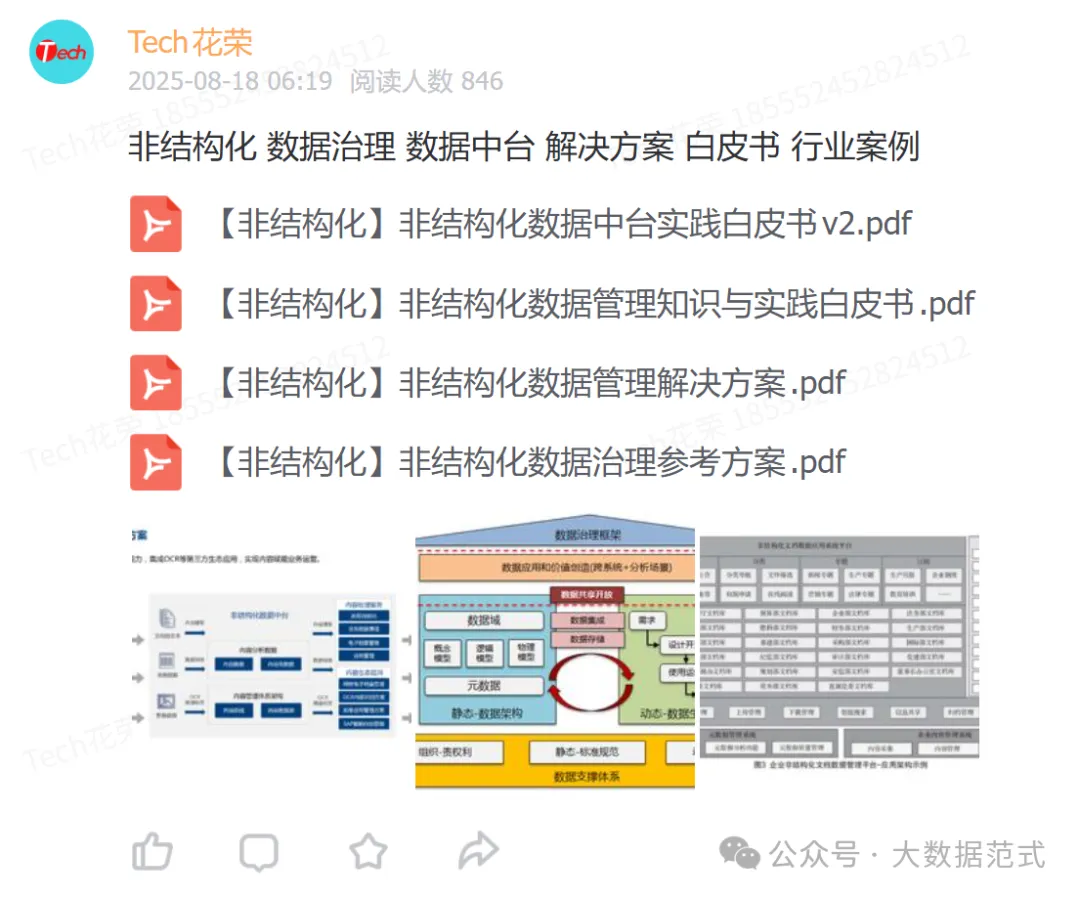
数据治理之标准&规范(文档)


上一篇:数据治理指南手册(文档)

“ 数据治理过程中的标准与规范实践,实践过,验证过”
01
—
命名标准
1、词根设计标准
根据不同的业务领域,有相应的词根版本。可以理解为术语字典,包含数据仓库分层、周期/数据范围、部门、业务域、主题域等
-
数仓层次
-
公用维度:dim
-
DM层:dm
-
ODS层:ods
-
DWD层:dwd
-
DWS层:dws
-
周期/数据范围
-
日快照:d
-
增量:i
-
全量:f
-
周:w
-
拉链表:l
-
非分区全量表:a
2、表命名标准
-
常规表:分层前缀[dwd|dws|ads]_部门_业务域_主题域_XXX_更新周期|数据范围
-
中间表:mid_xxx
-
临时表:tmp_xxx
-
维度表:dim_xxx
02
—
数据生命周期
1、历史数据等级划分
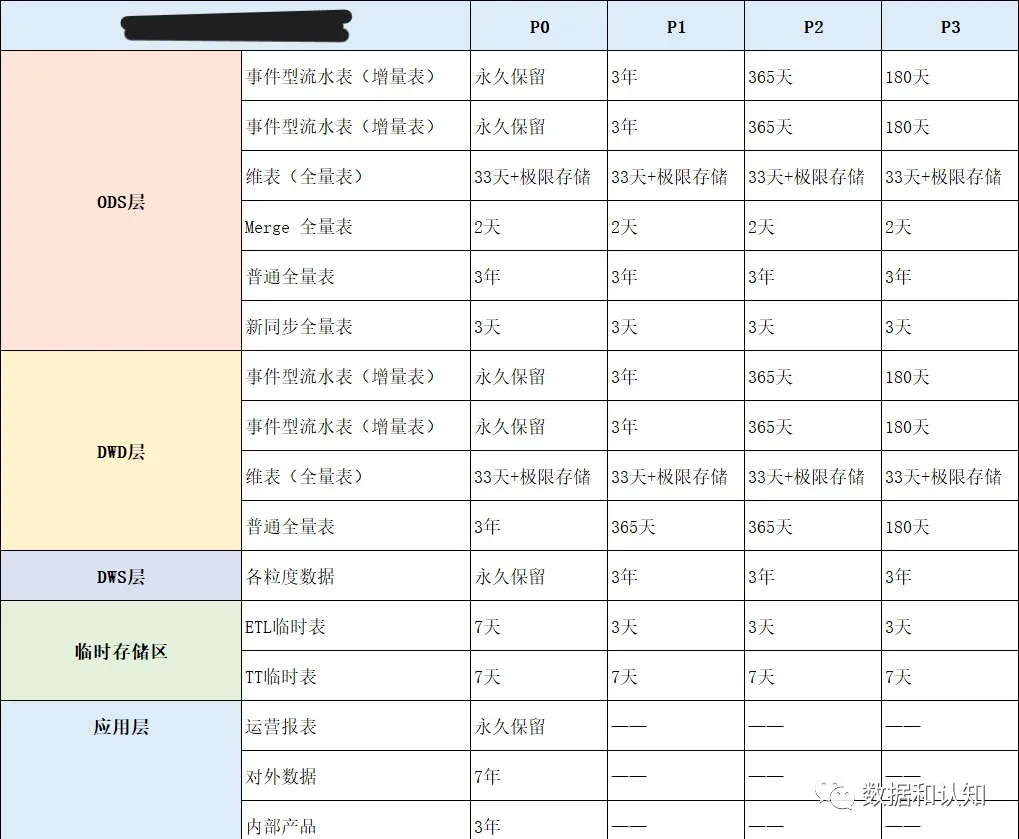
主要将历史数据划分P0、P1、P2、P3 四个等级,其具体定义如下:
-
P0 :非常重要的主题域数据和非常重要的应用数据,具有不可恢复性,如交易、日志、集团 KPI 数据、 IPO 关联表。
-
P1 :重要的业务数据和重要的应用数据,具有不可恢复性,如重要的业务产品数据。
-
P2 :重要的业务数据和重要的应用数据,具有可恢复性,如交易线 ETL 产生的中间过程数据。
-
P3 :不重要的业务数据和不重要的应用数据,具有可恢复性,如某些 SNS 产品报表。
2、生命周期管理矩阵
03
—
分层标准
-
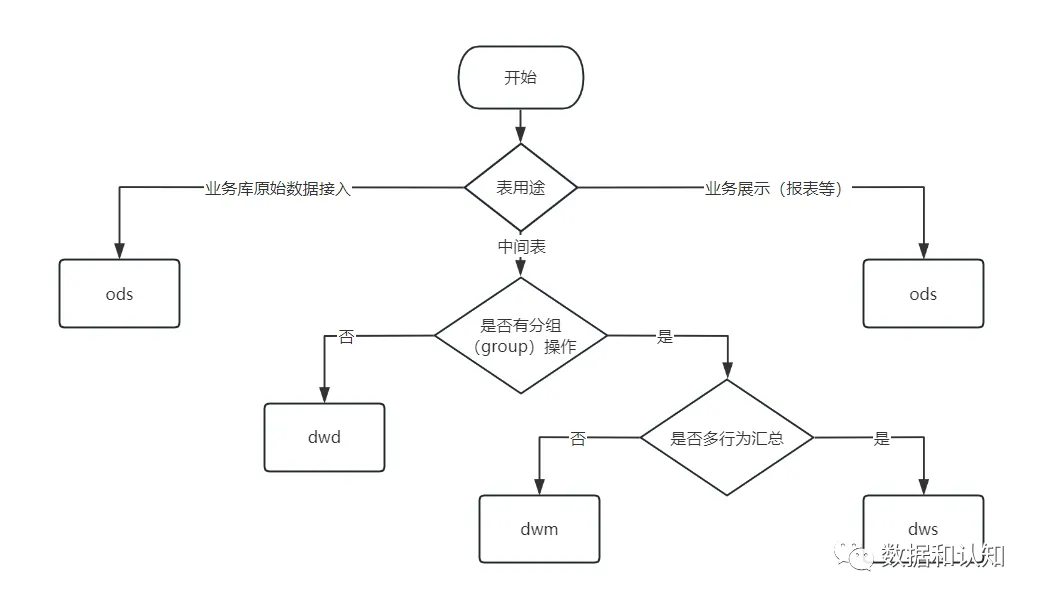
ODS(Operational Data Store-操作存储数据层):是最接近数据源中数据的一层,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可
-
DWD(Date Warehouse Detail-数据明细层):从 ODS 层中获得的数据按照主题建立各种数据模型
-
DWM(Date Warehouse Middle-数据中间层):该层会在 DWD 层的数据基础上,数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。(实际情况可能会没有这一层)
-
DWS(Date Warehouse Service-数据服务聚合层):公共汇总层,会进行轻度汇总,粒度比明细数据稍粗,基于 DWD 层上的基础数据,整合汇总成分析某一个主题域的服务数据,一般称为宽表
-
DIM(Dimension-维表层):一些维度属性表,从哪些角度可以分析数据
-
ADS(Application Data Service应用层)或者APP:主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、 PostgreSql、Redis 等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用
某些表应该属于哪一层呢?借鉴下面的思路和流程:
题外话:曾经有次面试,面试官问ODS的全称是什么?一下子把我问蒙了,从那些以后看到缩写就要知道他背后的全称是什么。
04
—
分层调用标准
-
正常流向:ODS -> DWD -> DWM -> DWS -> APP,当出现 ODS -> DWD -> DWS -> APP 这种关系时,说明主题域未覆盖全。应将 DWD 数据落到 DWM 中,对于使用频度非常低的表允许 DWD -> DWS。
-
尽量避免出现 DWS 宽表中使用 DWD 又使用(该 DWD 所归属主题域)DWM 的表。
-
同一主题域内对于 DWM 生成 DWM 的表,原则上要尽量避免,否则会影响 ETL 的效率。
-
DWM、DWS 和 APP 中禁止直接使用 ODS 的表, ODS 的表只能被 DWD 引用。
-
禁止出现反向依赖,例如DWM的表依赖DWS的表
05
—
模型设计原则
1、高内聚和低耦合
将业务相近或者相关的数据、粒度相同数据设计为一个逻辑或者物理模型;将高概率同时访问的数据放一起,将低概率同时访问的数据分开存储。
2、核心模型和扩展模型要分离
建立核心模型与扩展模型体系,核心模型包括的字段支持常用核心的业务,扩展模型包括的字段支持个性化或是少量应用的需要。在必须让核心模型与扩展模型做关联时,不能让扩展字段过度侵入核心模型,以免破坏了核心模型的架构简洁性与可维护性。
3、公共处理逻辑下沉及单一
底层公用的处理逻辑应该在数据调度依赖的底层进行封装与实现,不要让公用的处理逻辑暴露给应用层实现,不要让公共逻辑在多处同时存在。
4、成本与性能平衡
适当的数据冗余可换取查询和刷新性能,不宜过度冗余与数据复制。
5、数据可回滚
处理逻辑不变,在不同时间多次运行数据结果确定不变。
6、一致性
相同的字段在不同表中的字段名必须相同。
7、命名清晰可理解
表命名规范需清晰、一致,表命名需易于下游的理解和使用。
8、其他
一个模型无法满足所有的需求。需合理选择数据模型的建模方式。通常,设计顺序依次为:概念模型->逻辑模型->物理模型。
本号声明:
大数据宝藏库、资料库、福利库、资源库!文末直接获取方式
-
END 据统计,99%的数据大咖都关注了这个公众号
👇
-
大家都在看:
加入VIP社群星球 AI·大数据资源库↓

加入社群VIP星球*全部获取*任意下载*行业链接
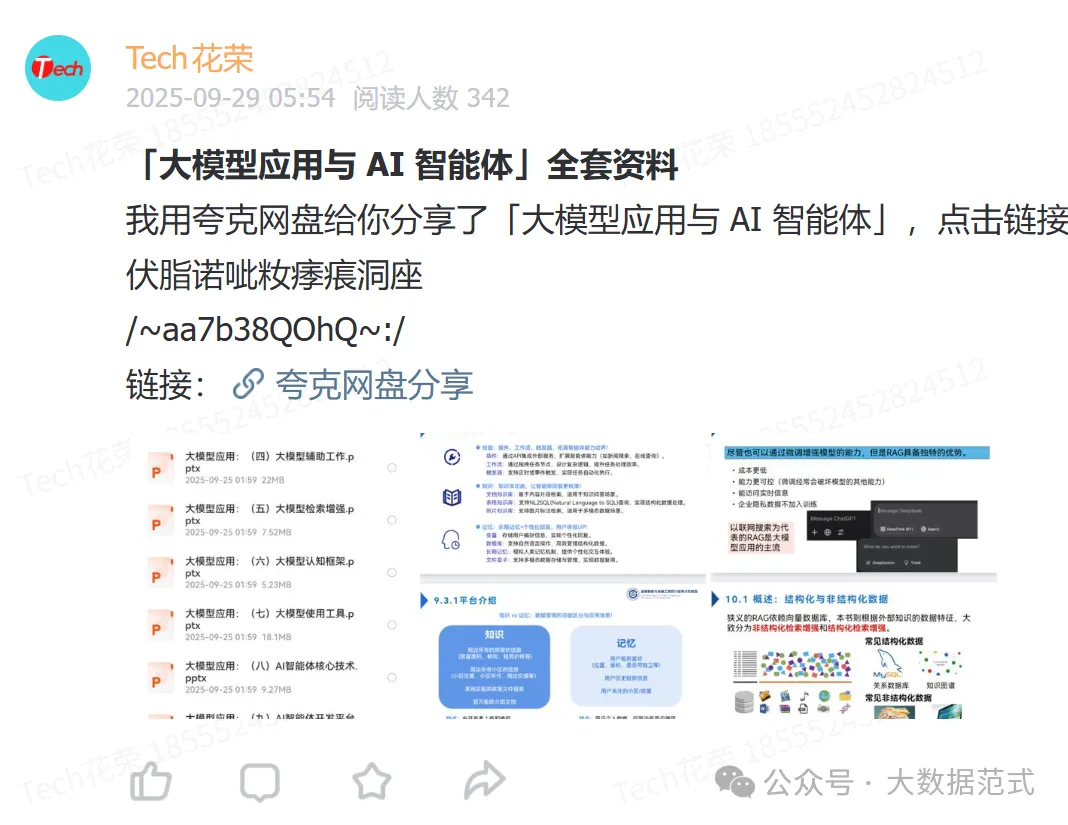
大模型
Agent



埃森哲&数字化转型

数字驾驶舱

…….
内部VIP社群【大数据资料库】星球全部获取⬆️
加入VIP社群星球 AI·大数据资料库↓