 夜雨聆风
夜雨聆风





阿里大模型二面:PDF、表格、图片混排文档,你的RAG系统是怎么解析的?
大家好,我是吴师兄,文档解析是 RAG 系统里最容易被低估的一个环节。
很多工程师在搭 demo 时直接用 PyPDF2 或 pdfplumber 把文档转成纯文本,跑起来感觉还行,但一旦遇到复杂的生产文档——带表格的合同、有图文混排的技术手册、嵌套标题的报告——解析质量就会急剧下降,最终体现在 RAG 系统的答案准确率上。
这道题的考察点不只是”你用了哪个解析工具”,而是你是否理解文档解析的核心难点在哪里、不同文档类型应该用什么策略、解析质量如何评估和改进。这些是真正在生产环境里踩过坑的人才能说清楚的内容。
回答这道题的主线是:文档类型决定解析策略,解析质量决定最终答案质量。从理解文档的结构复杂性出发,逐一拆解不同类型文档的解析挑战和对应方案,最后说清楚质量评估和工程取舍。
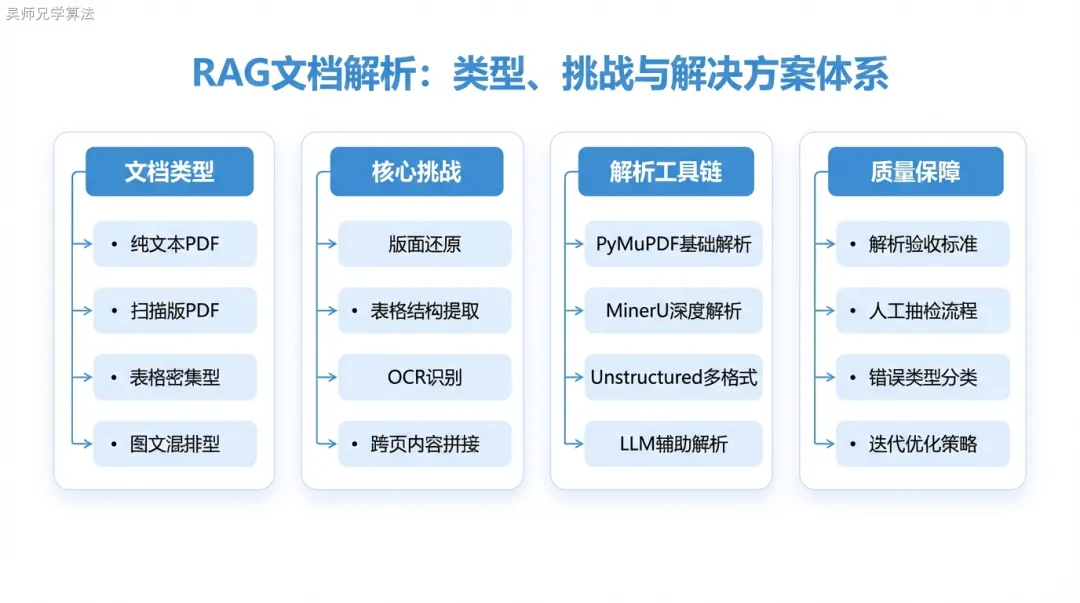
文档解析为什么这么难
在 RAG 系统里,文档解析的输出质量直接决定了后续一切操作的天花板——切分再精细、检索再准确,如果解析出来的文本本身就是乱的,最终的答案质量也不可能好。
问题出在文档格式的复杂性上。PDF 并不是一种语义格式,它本质上是一个描述”在哪个坐标位置画什么”的指令集。一个 PDF 里的”表格”,对 PDF 规范来说只是一堆在特定位置摆放的文字和线条,并没有任何关于”这是一个表格”的语义标记。把 PDF 解析成结构化文本,本质上是一个逆向工程问题。
这带来了几个具体的解析难点:
版面恢复(Layout Recovery):多栏布局、侧边注释、跨页标题——这些视觉上清晰的结构,在 PDF 的底层坐标系里是混乱的。直接按字符坐标从左到右、从上到下提取,很容易把两栏文本拼在一起,把侧边注释插入正文,把跨页的同一段落分成两段。
表格结构提取:表格中的单元格合并、斜线表头、嵌套子表——这些在视觉上一目了然,但程序化提取极其困难。表格内容如果不能按行列结构还原,打平成流水文本后,语义信息会大量丢失。比如”该条款的免赔额为10000元”这句话如果和表格的列头(”重疾险”)失去关联,就变成了没有主语的信息片段。
扫描版 PDF:很多企业内部文档是纸质扫描件,PDF 里存的是图片而不是可检索的文字。这类文档必须先走 OCR,而 OCR 的准确率受字体、打印质量、扫描角度影响很大,金融合同里常见的仿宋体、竖排文字对大多数 OCR 引擎来说都是挑战。
图表与文字的关联:技术手册里的图表往往和正文有强烈的引用关系(”如图3-1所示”),但解析工具通常只能提取图片,无法理解图表本身的内容,更无法建立图表与周围文字的语义关联。
在我们的训练营 RAG 实战项目里(金融保险知识库,5000份合同文档),早期直接用 pdfplumber 做解析,质量验收时发现约 30% 的文档存在结构性解析错误,主要集中在包含费率表的条款页和跨页的责任描述段落。这些错误在 demo 阶段完全看不出来,到了生产环境被用户真实问题触发时才暴露。
工具链的选择与分层策略
面对不同类型的文档,没有一个工具能做到一把梭。工程上的成熟做法是按文档类型分层路由,不同类型走不同的解析管道。
第一层:原生文本 PDF(有文字层)
对于数字原生 PDF(非扫描件),用 PyMuPDF(fitz) 做基础解析是性价比最高的选择。它速度快、精度稳定,对单栏纯文本文档效果很好。关键配置是按 Block 而不是按 Page 提取,这样能更好地保留段落边界信息。
对于版面复杂的原生 PDF(多栏、表格密集),用 MinerU 是目前开源方案里效果最好的选择之一。MinerU 用了 PDF-Extract-Kit 的版面分析模型,能识别出文档里的标题、正文、表格、图片各自的区域边界,再分别用不同的提取策略处理。对于包含复杂表格的金融文档,MinerU 把表格转成 Markdown 格式(| 列1 | 列2 |),保留了行列结构,后续 Chunk 切分时表格整体作为一个语义单元处理,而不是被切成碎片。
第二层:扫描版 PDF 和图片
扫描件必须先过 OCR。工程上常用的方案有两条路:(1)PaddleOCR,开源、支持中文、对仿宋体和竖排文字的支持比 Tesseract 好很多,适合大批量离线处理;(2)调用云厂商的 OCR API(阿里云、腾讯云),准确率更高,但有 API 费用。
一个容易被忽视的细节:OCR 之后不能直接就用,必须做后处理清洗——去除扫描噪点产生的乱码字符(常见的如”一””O”被识别为数字”1″”0″)、修复断行(同一段落因为版面被 OCR 识别成了多行)、处理页码和页眉页脚(这些内容不应该进入知识库)。
第三层:特殊结构处理
对于图片里的图表(柱状图、折线图、流程图),目前主流的处理方式有两种:(1)完全跳过,只保留图片周围的文字描述,适用于图表只是辅助说明的场景;(2)用多模态 LLM(GPT-4V、Qwen-VL)对图片做描述,把描述文字作为这个位置的文本内容,适用于图表本身承载核心信息的场景(成本较高,选择性使用)。
在我们的训练营项目里,最终采用的策略是:数字原生 PDF 用 MinerU 处理,扫描件用 PaddleOCR + 后处理,图表全部提取为图片文件但不做 LLM 描述(在当时的成本约束下),表格统一转为 Markdown 格式单独存储。这套策略让解析错误率从 30% 降到了 7% 左右。
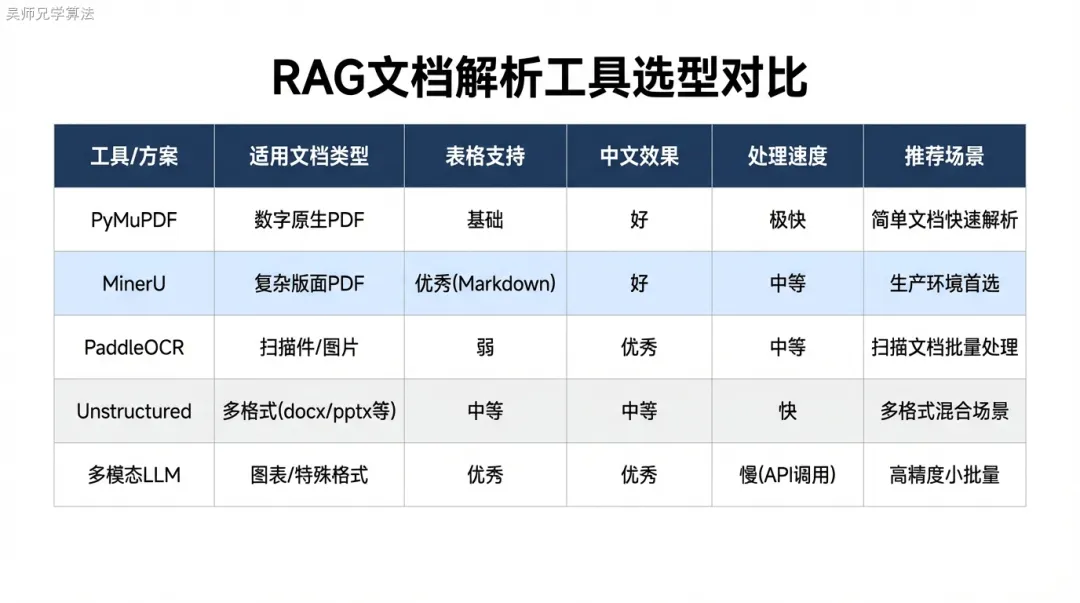
表格的专项处理:最难、最重要
表格是文档解析里最值得单独拿出来说的问题,因为它在金融、法律、医疗等知识密集型场景里出现频率极高,而且表格的语义损失最难被下游检测到。
表格解析的核心挑战是:如何在切分的时候保留表格的完整语义。如果把一个 20 行的费率表按行切成 20 个 Chunk,每个 Chunk 只有”60岁以下男性 年缴 10000元”这样的残缺信息,检索时根本无法正确理解这行数据的含义。
表格转 Markdown 整体保存是目前最常用的处理方案。把表格识别出来后,整体转成 Markdown 格式,作为一个独立的 Chunk 存入知识库,不切分表格内部。这样检索时可以把整个表格作为上下文送给 LLM,LLM 能直接理解行列关系。缺点是大表格的 Token 消耗较多。
表格拆分策略:对于超长表格(比如50行以上的数据表),不能整体作为一个 Chunk——太长会超出 Chunk 大小限制,也不利于精准检索。处理方式是把表头(列名行)和每一行数据组合成一个小 Chunk:
保障责任表 > 重疾险 > 60岁以下男性 年缴保费:10000元 | 保额:100万元 | 等待期:90天 | 免赔额:0这样每个 Chunk 都包含了完整的上下文——表名、列头、具体值——检索时语义完整。
表头识别的难点:复杂表格常见斜线表头、合并单元格、多行表头。程序化识别这些结构很难做到完美。一个工程上的折中方案是:对于简单表格用规则识别,对于复杂表格人工标注表头后再批量处理,或者在解析质量验收时专门检查表格 Chunk 的完整性。
跨页内容的拼接与清洗
跨页内容是另一个高频的解析错误来源,在长文档里几乎无法避免。
段落跨页断裂:一段话在第 N 页末尾结束,在 N+1 页开头继续。大多数解析工具按页处理,直接把这段话断成两个片段。修复方法是在提取后做语义连续性检测:如果当前页最后一句话没有句号结尾,而下一页第一句话是小写字母或数字开头(非段落起始特征),则尝试拼接。这个启发式规则对中文文档效果不稳定,更鲁棒的方式是在切分时用滑动窗口保留跨页的重叠区域。
页眉页脚的干扰:合同文档里的页眉通常是文档名称和日期,页脚是页码和法律声明。这些内容如果不过滤,会混入正文 Chunk 里,检索时产生无意义的噪声。过滤策略是基于位置(页面顶部固定区域、底部固定区域)和内容模式(重复出现的相同文本)进行识别和删除。
目录页的处理:文档开头的目录页往往包含大量章节标题和页码数字,如果作为正常文本进入知识库,会大量干扰基于关键词的检索。目录页应该单独识别并在解析阶段过滤掉——识别特征是内容主要由短行 + 数字构成,且后续正文中有对应的章节标题。
在我们的训练营 RAG 项目里,页眉页脚过滤和目录页过滤的实现让知识库的整体噪声文档比例从 15% 降到了约 3%,对应的无效检索召回率有明显改善。
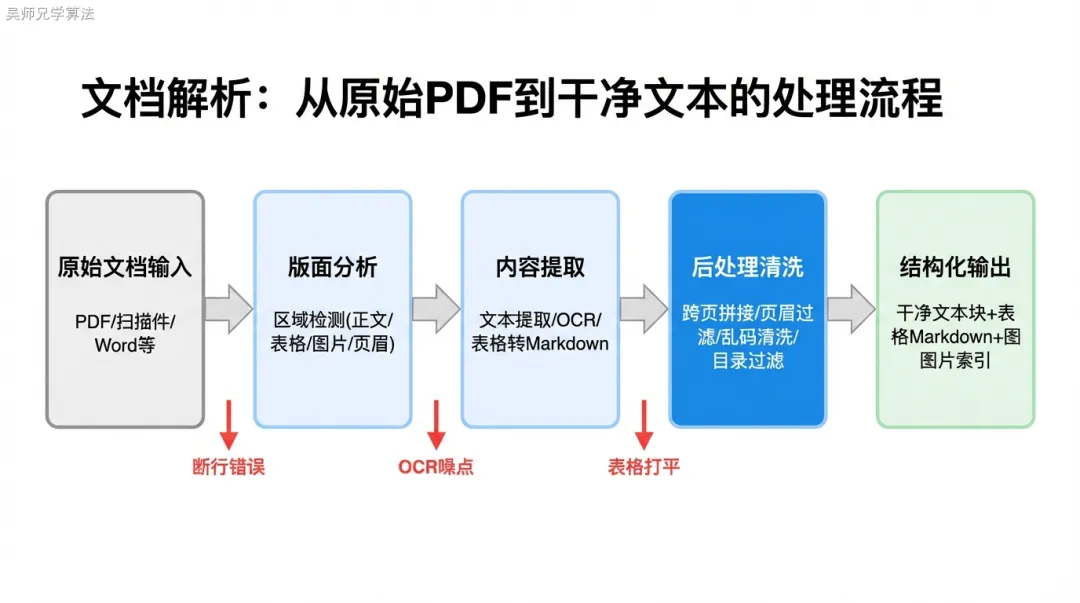
MinerU 的短板与补救
MinerU 是目前开源方案里综合效果最好的文档解析工具,但在我们的训练营项目里,经过大量测试,它也有几个明显的短板值得在面试中主动提出——能说出工具的局限性,是工程成熟度的体现。
复杂表格识别率不稳定:MinerU 的版面分析模型对简单的规则表格效果很好,但对于行列数超过 15 的大型数据表,以及带有大量合并单元格的复杂表格,识别准确率会出现下降,有时会把表格错误识别为段落文本,或者把表格的一部分识别为图片。
数学公式处理弱:对于包含大量数学公式的文档(精算报告、金融模型说明),MinerU 的公式识别目前输出为 LaTeX 格式,但准确率不稳定,复杂公式的识别错误率较高。
处理速度:在 CPU 环境下,MinerU 处理一页复杂 PDF 的时间约为 3-5 秒,5000份文档的全量处理需要数小时到数十小时。工程上通常做增量处理——新增文档入库时异步解析,而不是同步解析。
MinerU 的补救策略:对于 MinerU 识别结果可信度低的文档(可以用页面级质量分数阈值判断),降级到人工辅助处理流程:先用 MinerU 做初步解析,再由人工快速 review 质量分数低的页面,对严重错误的页面重新标注或用其他工具补充解析。
这种”自动解析 + 人工兜底”的分层策略在生产环境里是必要的——不能假设自动解析 100% 准确,也不能每份文档都人工处理,找到合适的质量阈值做分流是关键。
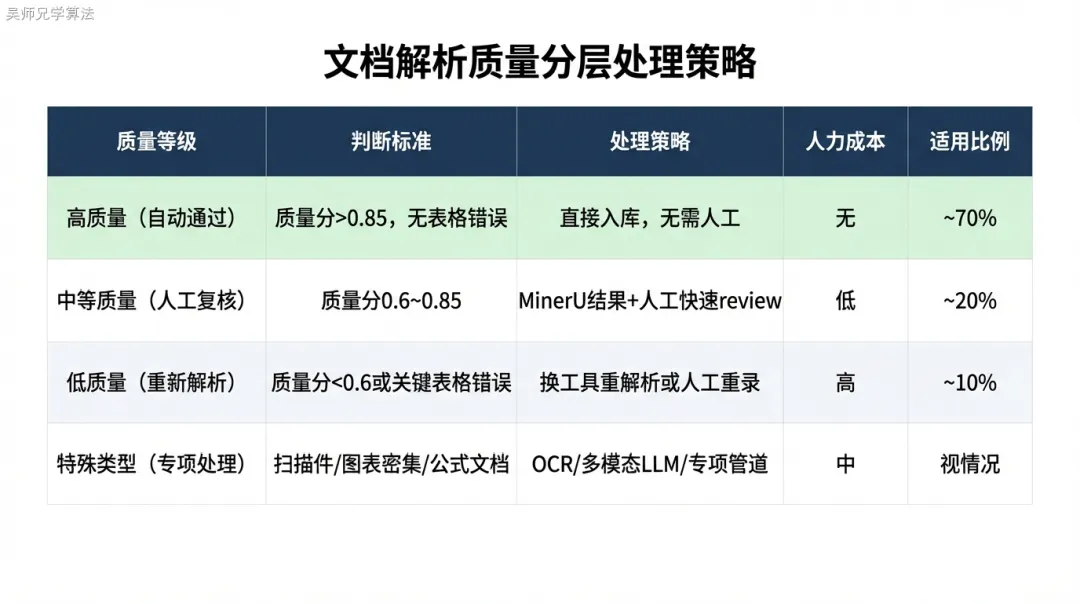
面试如何回答这道题
这道题的加分在于能不能说出具体的工具选型逻辑、表格处理的专项方案、以及主动暴露工具的局限性。
第一层:说清楚解析难点(30秒)
版面恢复、表格结构提取、OCR 噪声、跨页断裂——四个难点各一句话,点明文档解析不是”读文本”这么简单,而是一个结构还原问题。
第二层:分类型给方案(1分钟)
数字原生 PDF 用 MinerU 处理复杂版面,扫描件走 PaddleOCR + 后处理,图表可选多模态 LLM(说明成本权衡)。表格统一转 Markdown 整体保存,或拆成”表头+行”格式。体现分层路由的工程思路。
第三层:后处理和质量保障(1分钟)
跨页拼接、页眉页脚过滤、目录页过滤——这三个清洗步骤是面试中的细节加分点,大多数人只说工具不说清洗。再说一下质量分层策略(自动通过 / 人工复核 / 重新解析)。
第四层(加分项):主动说工具的短板(30秒)
MinerU 对复杂表格和公式识别不稳定,处理速度慢需要异步化。能主动说出工具局限性,说明你是真用过,不是背的。
追问准备:
-
“解析质量怎么量化?” — 可以说页面级的文字覆盖率、表格识别完整度、和人工标注的对比抽检 -
“5000份文档怎么批量处理?” — 异步队列(Celery/Ray)+ 增量处理 + 失败重试 -
“文档更新了怎么处理?” — 文档版本管理 + 差量更新(只重新处理变更的文档)

文档解析是 RAG 系统里少数几个”做好了用户感知不到,做差了用户问什么都答不对”的基础模块。面试中能把这个环节讲到工具选型 + 表格专项 + 后处理 + 质量评估这个深度,说明你在 RAG 工程上是真正从头到尾搭过完整系统的人,而不是只调过 LangChain 的几行 API。
我是吴师兄,我们下篇文章见。
本文内容基于吴师兄大模型训练营 RAG 实战系列课程整理。系列往期文章可在主页查看。