 夜雨聆风
夜雨聆风





深度学习中文综述||知网五万多下载次数,上千次被引用的综述
字数 2013,阅读大约需 11 分钟
深度学习在图像识别中的应用研究综述

关键词:深度学习;图像识别;卷积神经网络;胶囊网络;迁移学习;非监督学习
在图像识别领域,深度学习模型是核心支撑。图像识别技术起源于20世纪40年代,受限于技术和硬件条件发展缓慢;20世纪90年代,人工神经网络与支持向量机结合推动其广泛应用,但传统图像识别依赖浅层结构模型,需人为预处理图像,导致识别准确率偏低。为此,科研工作者研发深层网络结构,让模型自动提取图像特征,深度学习应运而生并成为图像识别领域的核心研究方向。
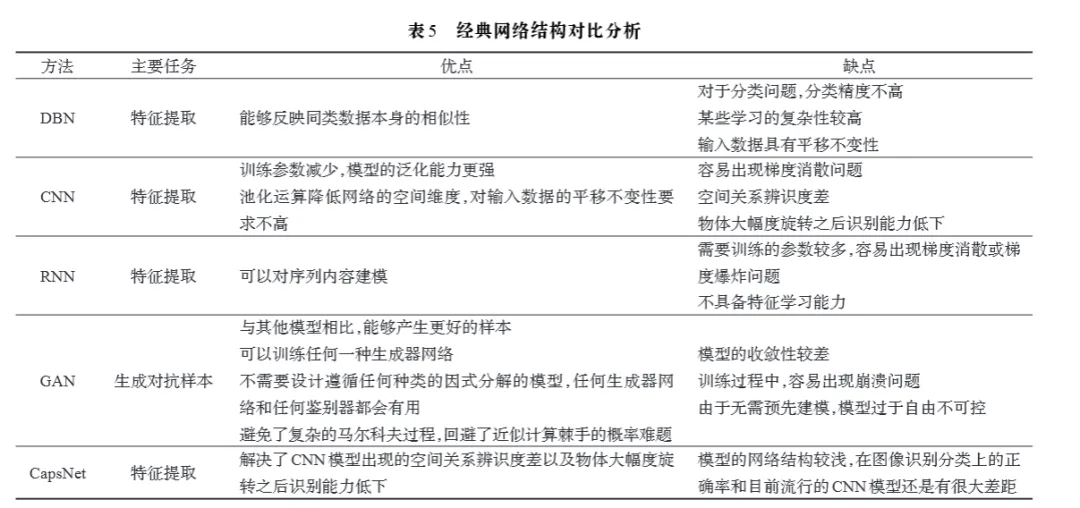
提取综述中的5种主流网络原始定义
一、深度信念网络(DBN)
原文定义:深层信念网络(Deep Belief Network,DBN)起源于人工神经网络,是一个概率生成模型,由多层受限玻尔兹曼机(RBM)和一层某种分类器组合而成,经典的DBN网络结构是由若干层RBM和一层BP组成的一种深层神经网络。此深度模型广泛应用于图像分类识别,语音识别等领域。
参考文献:[14] 刘方园,王水花,张煜东. 深度置信网络模型及应用研究综述[J].计算机工程与应用,2018,54(1):11-18.
补充概括:DBN通过无监督预训练和监督微调实现特征学习,可用于高光谱遥感图像分类,能提升特征表达丰富度,但存在特征提取能力较弱、参数量大、易过拟合的问题。
二、卷积神经网络(CNN)
原文定义:卷积神经网络(Convolutional Neural Network,CNN)是一种特殊的深层前馈网络,CNN模型主要包含输入层、卷积层、池化层、全连接层以及输出层。但是,在网络结构中,为了使输出更加准确,特征提取更加丰富,通常网络模型中使用多卷积层和多池化层相结合的网络模型,较为经典的CNN模型有LeNet-5、AlexNet、ZF-Net、VGGNet、GoogLeNet、ResNet以及DenseNet,上述CNN模型均是LeNet的改进型模型。
参考文献:[16] Huang G,Liu Z,Maaten L V D,et al.Densely connected convolutional networks[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:2261-2269.
补充概括:CNN是图像识别最主流的模型,通过卷积、池化操作减少参数、提取特征,改进模型不断优化精度和效率,在人脸识别、医学图像识别等领域应用广泛,但存在空间关系辨识度差、物体旋转后识别能力下降的缺陷。
三、循环神经网络(RNN)
原文定义:循环神经网络(Recurrent Neural Network,RNN),又名时间递归神经网络,主要是用来解决序列数据问题。在RNN结构模型中,网络会对之前时刻的信息进行记忆并且运用到当前的输出计算之中,相比于卷积神经网络、深度前馈网络,循环神经网络隐藏层之间的神经元是相互连接的,隐藏层中神经元的输入是由输入层的输出和上一时刻隐藏层神经元的输出共同组成。
参考文献:[19] Lipton Z C.A critical review of recurrent neural networks for sequence learning[EB/OL].(2015)[2019].https://arxiv.org/abs/1506.00019v1.
补充概括:RNN最初用于语音、手写识别,改进模型(LSTM、GRU、双向RNN)弥补了原始模型训练难、效率低的不足,可用于高光谱像素序列分析,但仍存在参数多、易出现梯度消失/爆炸的问题。
四、生成式对抗网络(GAN)
原文定义:生成式对抗网络(Generative Adversarial Network, GAN)是Goodfellow等人于2014年提出的一种生成式模型,通过在对抗过程中估计并生成模型的新框架,是近几年最成功的生成模型。GAN主要由两部分构成:生成模型(G)和判别模型(D)。生成模型捕捉真实数据样本的潜在分布,并生成新的数据样本。判别模型是一个二分类器,判别区分输入的是真实数据还是生成的样本数据。判别模型输出是以概率值表示,概率值大于0.5则为真,概率值小于0.5则为假。当判别器无法区别出真实数据和生成数据时则停止训练,此时达到生成器与判别器之间判定误差的平衡,训练达到理想状态。
参考文献:[27] Goodfellow I J,Pouget-Abadie J,Mirza M,et al.Generative adversarial nets[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems.Montreal,Canada:MIT Press,2014:2672-2680.
补充概括:GAN通过生成器与判别器的对抗训练生成逼真样本,可缓解CNN过拟合问题,用于高光谱图像分类、图像生成等场景,改进模型(CGAN、DCGAN等)解决了其训练不稳定、不可控的缺陷。
五、胶囊网络(CapsNet)
原文定义:胶囊网络(Capsule Network,CapsNet)是Hinton等人在2017年提出,是当前图像分类识别最前沿的技术之一。CapsNet是在CNN的基础之上发展而来,解决了CNN对物体之间的空间辨识度差及物体大幅度旋转之后识别能力低下的两个缺陷。目前的CapsNet结构较浅,是由卷积层、PrimaryCaps(主胶囊)层、DigitCaps(数字胶囊)层构成。参考文献:[38] Sabour S,Frosst N E,Hinton G.Dynamic routing between capsules[EB/OL].(2017)[2019].https://arxiv.org/abs/1710.09829.(注:该网页解析失败,文献信息按原文标注)
补充概括:CapsNet以“胶囊”为基本单元,采用动态路由算法训练,在小样本、物体旋转识别场景中表现出色,但网络结构较浅,图像分类精度仍不及深层CNN,未来可通过增加网络层数、优化算法提升性能。

现存问题
尽管深度学习在图像识别领域已取得诸多成果,但目前研究仍存在明显不足:一是模型高度依赖大量标注数据,在小样本场景(如火灾识别等)中应用受限;二是非监督学习与半监督学习的识别精度,与监督学习仍有较大差距,且标注数据需消耗大量人力物力;三是深度学习在视频图像识别方面应用薄弱,缺乏大规模视频数据集,且模型结构复杂、计算量大、训练时间长;四是深度学习模型的理论基础不够扎实,模型收敛条件、信息损失规律等核心问题仍需进一步研究。
未来发展方向
结合当前研究瓶颈,未来深度学习在图像识别领域的核心发展方向主要有四点:一是深耕小样本数据集与迁移学习结合的方法,高效利用少量相关样本实现精准识别;二是加强非监督与半监督学习的研究,弥补监督学习的不足,降低标注成本;三是推进深度学习在视频图像识别中的应用,优化模型结构、提升计算效率,解决数据集匮乏问题;四是强化深度学习模型的理论研究,明确模型收敛机制、信息传递规律,夯实理论基础,提升模型的可解释性。
文末总结
以上5种网络是深度学习在图像识别领域的核心模型,文中定义均直接摘录自权威综述,文献标注清晰,可直接用于学习和引用。它们各有优劣,适配不同应用场景,结合现存问题与未来发展方向,深度学习在图像识别领域仍有巨大探索空间。