 夜雨聆风
夜雨聆风





评分不主观:用AI辅助绩效校准、偏差检测与强制分布
做HR的那些年,我最怕的一个会,就是绩效校准会。
那个场面我太熟悉了:
-
销售总监说:“我的人业绩超额,多给几个S,不合理吗?”
-
技术总监立刻怼:“超额是因为市场好,我们部门救火三个项目,才配S。”
-
有人靠印象打分,有人护短,有人踩低别人抬高自己。
-
明明应该讲事实,最后变成拼嗓门、拼关系、拼资历。
会议开完,等级是出来了,但人心散了、公平没了、员工不信了。
更可怕的是背后的真相:大部分管理者打分,靠的不是事实,而是感觉。
-
近因效应:最近一件事决定整个季度
-
晕轮效应:某一点好,哪里都好
-
宽松效应:大家都不错,别得罪人
-
对比偏差:别人差,显得我还行
分数拍脑袋、校准靠撕逼、结果难服众。这几乎是所有企业的绩效死穴。
今天这篇,不绕弯子,直接给你一套能立刻用、能压得住场、能让校准会从撕逼变共识的实战方法——用AI双驱功法,把“凭感觉评分”,变成凭事实说话、凭逻辑打分、凭公平服人。
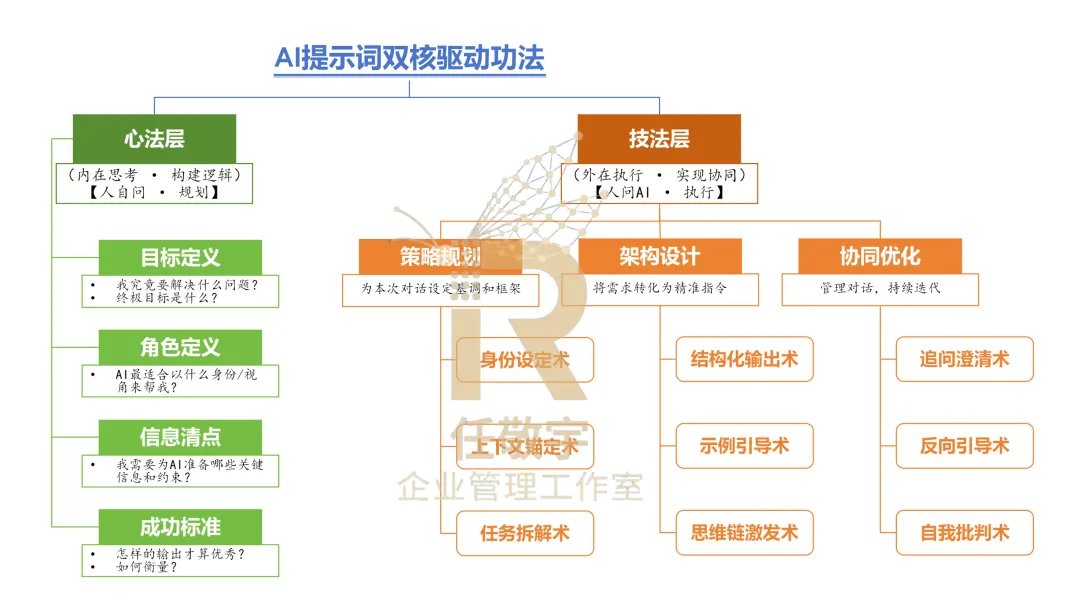
一、先戳穿真相:你的绩效评分,为什么总是“不服众”?
我说三句扎心但真实的话:
1. 打分不是艺术,是推理。没有事实的分数,就是偏见。
2. 校准不是谈判,是校验。谁嗓门大谁有理,这不是管理,是和稀泥。
3. AI不是来替你打分,是来帮你“打假”。它不站队、不护短、不讲人情,只看事实与逻辑。
你要的从来不是一个“好看的分数”,而是一份没人能反驳、员工能接受、管理层能共识的绩效结果。
怎么做?依旧是:先心法,后技法。
二、心法四问:校准前先问自己,问完就不会偏
元认知四问,就是你校准工作的定盘星。
第一问·目标定义
我要的不是“一个分数”,而是一份经得起质疑、能解释、能落地的绩效事实清单。
第二问·角色定义
AI今天不是判官,而是两个角色:绩效校准官 + 公平性检验师只做:梳理事实、校验逻辑、识别偏差、提醒风险。
第三问·信息清点
你必须喂给AI这些“弹药”:– 员工季度工作成果与数据– 上级初步评分和对应的初评等级– 关键行为、项目产出、客户反馈– 考核指标与权重,以及各维度的评分标准– 公司强制分布比例要求(各等级占比)
第四问·成功标准
成功标准不是“没人吵架”,而是:校准结束后,随机抽取80%的被评价者和管理者,都认可结果是“公平、有据、可解释”的。
心法想清楚,你再碰AI,就不会跑偏。
三、技法三步:让AI把“主观评分”钉在事实之上
我用具体绩效校准场景,完整走一遍。
某科技公司销售团队(销售岗,5人)Q1绩效校准:强制分布五档:S(10%)、A(20%)、B(40%)、C(20%)、D(10%)。指标权重:销售额50%、客户满意度20%、协作贡献15%、合规性15%。经理给每个人在四个维度打了分,并加权算出总分,再给出了初评等级:
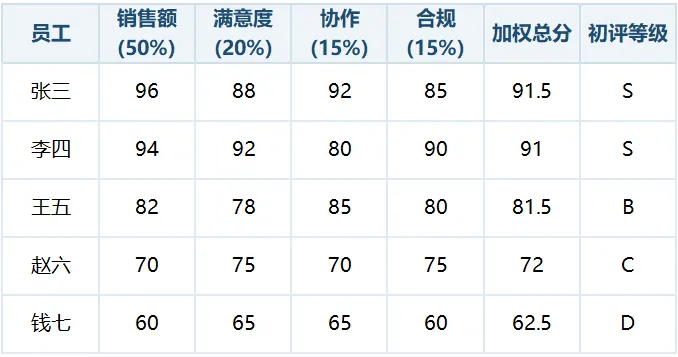
问题来了: 初评S有2人(张三和李四),但强制分布S只有1个名额。经理认为两人业绩都好,都应该S。HR觉得李四有丢单记录,且协作分数偏低,S是否合理?这就是校准会的核心冲突。
第一步:任务拆解术——先出事实清单,再识偏差
第一步:根据以下员工信息,生成《绩效事实清单》(只列可验证的成果、行为、数据,不含主观评价)。
第二步:将事实清单与经理的初评等级对比,识别偏差风险(宽松/严格、近因效应、晕轮效应)。
【背景】
指标权重:销售额50%、满意度20%、协作15%、合规15%
评分标准:
– 销售额:完成率≥110% → 95-100分;100%-109% → 85-94分;90%-99% → 75-84分;80%-89% → 65-74分;<80% → ≤64分;每丢单一个在基础分上扣3-5分。– 客户满意度:有书面感谢信/推荐 → 95-100分;评分≥95分 → 85-94分;评分85-94分 → 75-84分;评分70-84分 → 65-74分;<70分 → ≤64分。– 协作贡献:主动输出工具/跨部门推动成功 → 90-100分;有配合记录 → 75-89分;无负面 → 65-74分;有推诿记录 → ≤64分。– 合规性:无违规 → 85-100分;轻微违规(如迟报)→ 70-84分;中度违规 → 60-69分;严重违规 → ≤59分。
强制分布:S(10%)、A(20%)、B(40%)、C(20%)、D(10%)
【员工数据】(含各维度经理评分及关键行为)
张三:初评S。销售额96分(完成率112%,新客4个,输出话术模板);满意度88分;协作92分;合规85分(无违规)。
李四:初评S。销售额94分(完成率105%,丢单1个);满意度92分(感谢信);协作80分;合规90分。王五:初评B。销售额82分(完成率88%,协助同事一次);满意度78分;协作85分;合规80分。赵六:初评C。销售额70分(完成率72%);满意度75分;协作70分;合规75分。钱七:初评D。销售额60分(完成率60%,投诉1次);满意度65分;协作65分;合规60分。
第二步:思维链激发术——逐维度校验,指正偏差并确定等级
– 建议:李四降为A。
……(其他人员校准内容省略)
最终等级建议张三S,李四A,王五B,赵六C,钱七D。强制分布全部匹配,无超标。
第三步:自我批判术——预测考核双方可能提出的质疑并准备预案
对校准结果真正的争议往往来自:被降级的员工(李四从S到A)、低分员工(赵六、钱七)以及他们的经理。AI应提前预测这些角色可能提出的质疑,帮HR准备应对话术。
这套预测能让HR在会前就准备好事实依据和沟通策略,避免现场被问倒。
四、HR必须守住3条底线
校准会的核心不是“把分数做平”,而是“让结果经得起追问”。下面三条底线,请你一定守住:
底线1:AI只做校验,不做最终决策
AI可以指出“李四的协作分偏高”,可以算出“调整后总分88.5”,但最终给S还是A,签字的是管理者。校准会上最后拍板的,永远是人。
底线2:所有评分必须可解释
如果一个人打了分数,却说不出一句具体事实来支撑,这个分数就应该被质疑。AI的推理链就是最低成本的解释工具。
底线3:校准会必须“先事实,后分数,再等级”
一上来就吵“谁该拿S”“该不该有D”,注定扯皮。正确的顺序:①对齐事实清单;②校验分数偏差;③根据修正后的分数切等级。缺一步,就会回到互相指责的老路。
五、写在最后
做咨询的这些年,我越来越肯定:员工离职,最根本的原因是感受到不公平,越优秀的人才,越是如此。 而公平感的第一杀手,就是绩效。
你花一个月设计的指标,花一周收集的数据,花一天打的分数,可能因为校准会上一个经理的“我觉得”,全部毁掉。
AI不能替你开校准会,但它能帮你做三件人很难做到的事:
-
把模糊的印象变成铁打的事实清单——每个人做了什么、没做什么,白纸黑字,谁也无法抵赖。
-
把隐蔽的认知偏差暴露在阳光下——“你为什么给96分?事实支持吗?”AI的逐维度校验让晕轮效应、近因效应无处藏身。
-
把主观的争吵转化为客观的风险预判——不再“我觉得你不对”,而是“如果这样定级,被降级的员工会怎么质疑?低分员工会不会投诉?经理会有什么难处?”
你只需要学会一件事:把AI当成校准会上的“第四个人”——除了HR、管理者、员工代表,再加上一个只讲事实的AI。
下一次,当你再遇到拍桌子的校准会时,别急着和稀泥。先打开AI,花20分钟把事实清单、分数校验、风险评估跑一遍。你会发现,那些曾经吵到面红耳赤的问题,突然就变得清晰了。
这就是人机协奏的力量。
下一讲我们进入:《面谈不尴尬:用AI定制个性化反馈提纲与发展计划》
如果你在绩效校准中遇到“偏心经理、护短leader、撕逼现场”,欢迎在评论区说出你的场景,我们来看看可否让AI帮你找到解法。
本文系「人机协奏:从焦虑到赋能的AI实战课」实战篇——绩效与激励模块 第3篇
关注我,跟着「人机协奏」一步步用AI搞定HR全流程——从执行提效,到策略赋能。