 夜雨聆风
夜雨聆风





契约:软件工程能 scale 的唯一理由
一、一个反常识的事实
Linux 内核今天大约 3000 万行代码。Chromium 浏览器 3500 万行。一个普通的 Node 项目,npm install 跑完之后,node_modules 文件夹里躺着几千个第三方包,加起来可能上百万行。
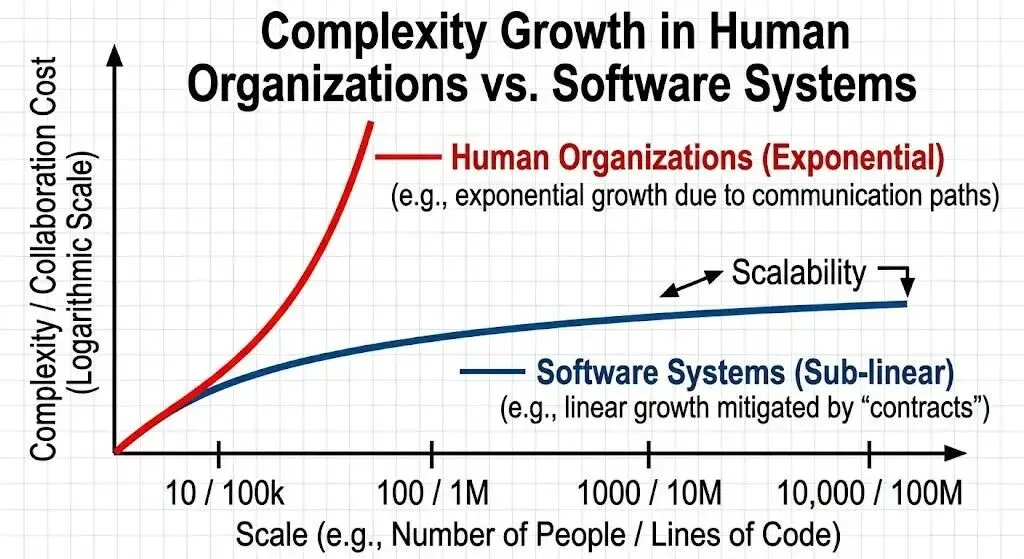
人类协作的复杂度通常不是线性的。一个 100 人的公司比 10 人的公司难管,但难的程度远不止 10 倍——光是沟通路径就从 45 条暴涨到 4950 条。组织学里有专门的研究讨论这件事,社会学家把它叫作”科层制的边际成本递增”。
但软件不是这样的。3000 万行代码不会比 30 万行难维护 100 倍。一个 Linux 维护者可以在不读完整个 codebase 的情况下,安全地修改其中一小块。一个普通工程师可以放心地依赖一个自己完全没看过源码的开源库。一个公司的后端服务可以调用另一家公司的 API,双方的工程师从未谋面,也不需要谋面。
这是一个反常识的事实。人类历史上几乎所有的协作系统——商业、政治、军事、学术——规模扩大都会带来协作成本的非线性上升。但软件没有。
为什么?
我以前以为答案是”程序员比一般人聪明”。后来意识到这是错的。今天的程序员平均水平不会比五十年前 Bell Labs 的人聪明,软件能 scale 是因为这个学科找到了一个核心抽象——一个在每一层都重复出现的、几乎是唯一的抽象——契约。
这个词不是修辞,不是类比意义上的”接口约定”。它是字面意义上的工程概念,而且整个软件工程的层级结构,从最微观的函数签名到最宏观的网络协议,都在做同一件事:把契约形式化。
下面这篇文章想做的事情,是从最里层开始一路追到最外层,看这个抽象如何在每一层都重复出现。
二、先把”契约”这个词收紧
在继续之前,得把”契约”这个词的范围收紧。否则它会膨胀成一个什么都能装的修辞,反而失去解释力。
工程上严格意义的契约有三个要素:
第一,可预期的输入输出。给定 X,必返回 Y,或者抛出预先约定好的错误。不能给 X 返回 Z,更不能”看心情”。
第二,边界隔离。契约外的事情,调用方不需要管,被调用方也不需要解释。我调用 sqrt(2),它返回 1.414,至于内部用了牛顿迭代法还是查表,不在契约约定范围内。
第三,可强制。必须有机制保证违约会被发现。形式可以多样——编译错误、运行时异常、HTTP 状态码、单元测试失败、合同诉讼——但必须存在。没有强制机制的”契约”不是契约,是君子协定,scale 不上去。
三个要素里,第二点是真正的关键。
很多人会觉得契约的核心是”规定双方怎么做”。这是误解。契约的核心价值,是规定双方不需要管对方怎么做。
这一句话不长,但是后面所有展开的基石。读者如果只能记住文章里的一句话,最好是这一句。
类型系统、API 文档、协议规范、版本号——所有这些机制存在的根本理由,不是约束你,而是解放你。它们让你不需要去理解对方的内部实现,就能放心使用对方提供的能力。这就是分工的物理基础。
三、契约的五个层级
把”契约”放在显微镜下,会发现它在软件系统里至少出现五次,从最微观到最宏观,层层递进。每一层都解决了上一层无法解决的问题。
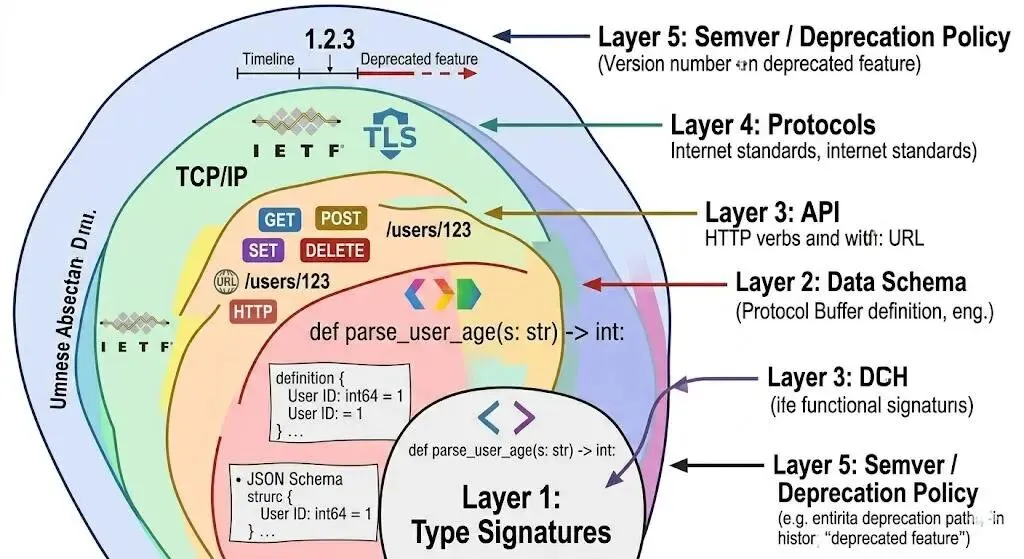
第一层:类型签名
最微观的契约,由编译器强制执行。
defparse_user_age(s: str) -> int: ...这一行函数签名就是一份契约。调用方承诺给我 str,我承诺还回 int。如果调用方传了 list,编译器(或类型检查器)当场拒绝。这是契约的最小颗粒度。
强类型语言(Rust、Haskell)和弱类型语言(Python、JavaScript)的根本区别,不在性能也不在写法,而在于契约形式化的程度。Rust 把”内存所有权”和”生命周期”也刻进了类型系统——这意味着”谁有权读、谁有权写、什么时候释放”这种通常靠口头约定的事情,全部交给编译器来执行。这是契约形式化能做到的极限之一。
但类型签名有一个根本局限:**它只能约束”形状”,不能约束”行为”**。parse_user_age("18") 和 parse_user_age("not a number") 都符合 str -> int 的签名,但前者应该返回 18,后者应该抛异常。这件事类型系统管不了。要管行为,得往上抽一层。
第二层:数据 schema
DB schema、Protobuf、JSON Schema——这一层契约约束的是数据本身的形状和约束。
Protobuf 的设计在这一层是范本。它定义字段的时候,每个字段都有一个编号:
messageUser{int64 id = 1;string name = 2;string email = 3;}这个 1、2、3 不是装饰,是契约本身。Protobuf 规定:字段编号一旦分配,永不复用。删除字段时,编号要保留为 reserved。新加字段必须给新编号。这一整套规则不是为了让代码能跑——是为了让契约可以演进而不破坏依赖它的所有客户端。
我在做 RAG系统 的时候第一次直观感受到这件事。一开始 schema 写得很随意,几个迭代之后想加字段、想改字段类型,发现一动就要把所有上下游代码翻一遍。后来才意识到:schema 不是”数据的描述”,schema 是”对未来的承诺”。改一次 schema 的代价,约等于改一次合同条款的代价。
但 schema 也有局限:它约束的是数据的静态形状,不约束”什么时候、用什么 method 去取这份数据”。要管动作和时机,再往上一层。
第三层:API
到这一层,契约开始管”动作”了。
RESTful API 的三件套——URL 标识资源、method 标识操作、status code 标识结果——本质上就是把”行为契约”形式化。GET /users/123 和 DELETE /users/123 是两份完全不同的契约:前者承诺幂等、安全、可缓存,后者承诺幂等但有副作用。
API 这一层比 schema 多了一个时间维度:什么时候可以调用、调用之间有什么先后关系、失败了怎么重试。所以 API 设计里才会有 idempotency、有 rate limiting、有 retry-after,这些都是 schema 层面没有的概念。
但 API 还是不够。每个公司、每个团队设计 API 的风格千差万别,跨厂商协作的时候,光看 API 文档不够,还需要更底层的、所有人都同意的东西。
第四层:协议
HTTP、TCP、TLS、DNS。这是一类很特殊的契约——无主。
没有任何一家公司能单方面修改 HTTP 协议。要改,必须经过 IETF 的 RFC 流程,由全球的协议专家、浏览器厂商、CDN、运营商一起协商。HTTP/1.1 从 1997 年的 RFC 2068 定型,到今天近三十年,核心语义几乎没变过。HTTP/2、HTTP/3 是底层传输的优化,但应用层的 method、header、status code 这套契约,三十年纹丝不动。
这就是契约的极端形式:稳定到所有人都不需要再读一遍。
协议越底层,演进越慢,原因不是技术上改不动,而是因为整个生态已经把它当成”地基”。地基一动,房子就要塌。所以我们看到的现象是:越接近用户的层(前端框架、UI 库),变化越快;越接近底层的层(HTTP、TCP),变化越慢。这不是巧合,是契约稳定性和生态依赖深度成正比的必然结果。
但即使是协议,也会需要演进。HTTPS 的普及、IPv6 的推广、TLS 1.3 的更新——这些都不是凭空发生的。第五层契约要回答的问题是:当契约本身需要变的时候,怎么变?
第五层:semver / deprecation policy
前面四层都假设”契约已经存在”。但所有真实的工程系统都在变——业务变、依赖变、需求变。最难的问题来了:契约怎么演进,又不破坏依赖它的所有人?
答案是发明一种新的契约——关于契约如何修改的契约。
semver 的 major.minor.patch 是一个精妙的设计。它把”变化”按对调用方的影响分成三类:
-
patch:修 bug,不改契约 -
minor:加新功能,但不破坏旧契约 -
major:破坏性变更,旧契约作废
调用方看版本号就能预测自己会被影响到什么程度。这不是技术规则,是形式化的承诺协议:你升级 patch 不用改代码,升级 minor 偶尔需要适配,升级 major 必须重新读文档。
更进一步的是 deprecation policy。Kubernetes 明确规定:API 一旦被废弃,至少要在一定数量的版本周期内继续可用,给生态足够时间迁移。Linus 多年来反复强调 Linux kernel 对 user-space ABI 的稳定承诺——”don’t break userspace”。Python 通过 PEP 流程让所有破坏性变更都必须经过公开讨论。
这些都是同一类东西:当稳定性和演进必须共存时,唯一的解法是给”演进”本身定一份契约。
四、契约的代价
读到这里需要打住一下。
契约不是免费的午餐。它有真实的代价:
设计成本。 把边界画清楚,比写实现难得多。新手 API 设计糟糕的根本原因,不是技术不行,是没意识到”画边界”才是核心工作——他们把 80% 的时间花在写代码上,而真正重要的那 20% 是在决定”什么进契约、什么不进”。
灵活性损失。 契约越严格,演进越痛苦。这就是为什么很多 startup 早期会故意不画契约——先把业务跑起来,规模上来了再补。这是合理的工程选择,不是偷懒。一个还没找到 PMF 的产品,过早冻结契约的代价远大于收益。
抽象代价。 每一层契约都是一层中间人,有性能开销、心智负担和 debug 成本。每加一层,定位问题就多一处可能出错的地方。
所以契约不是越多越好。它是一种主动的工程选择:用约束换协作。规模小的时候,约束的成本大于协作的收益,少画契约是对的;规模大的时候反过来,必须靠契约来 scale。
五、契约的递归
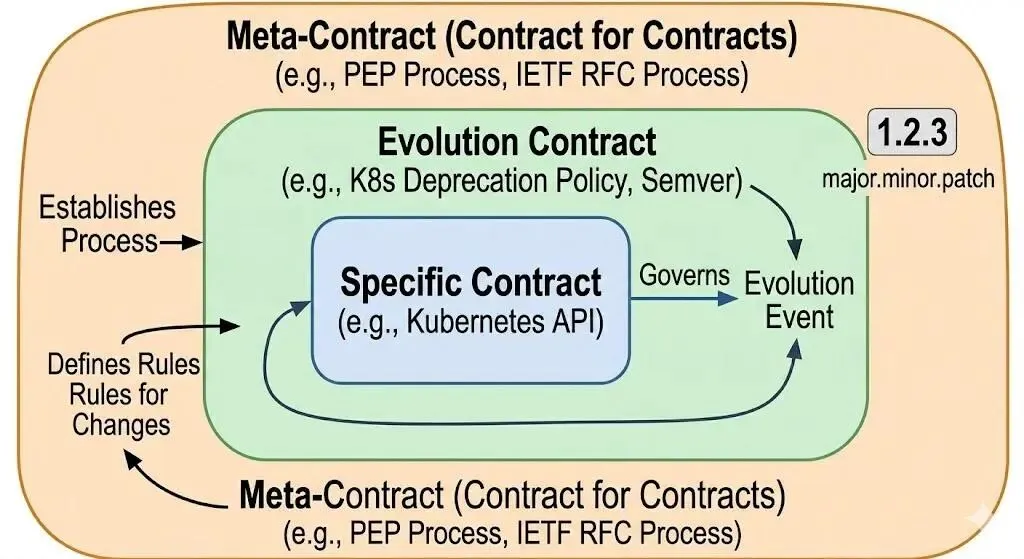
回到 semver 那一段。仔细看,会发现一件有意思的事情:
semver 本身就是一份契约——一份关于”契约如何修改”的契约。
这是契约的递归结构。在所有成熟的工程系统里都能找到:
-
Linux kernel 的 user-space ABI 稳定性承诺,是关于”内核接口怎么演进”的元契约 -
Python 的 PEP 流程,是关于”Python 怎么演进”的元契约 -
Kubernetes 的 API deprecation policy,是关于”K8s API 怎么废弃”的元契约 -
IETF 的 RFC 流程,是关于”互联网协议怎么修改”的元契约
把视角再拉远一格:所有能长期维护的工程系统,都不是因为契约绝对稳定,而是因为它们的”修改契约的契约”清晰可信。
这是 mature 系统和 hack 项目最本质的分水岭。一个项目的代码质量、架构精巧程度、测试覆盖率,都是表象。真正决定它能不能活十年的,是它有没有一份关于”怎么演进”的元契约。没有的话,每一次破坏性变更都是一次背叛,背叛多了,依赖它的人就走了。
这件事并不只在软件里成立。宪法和普通法律的关系也是一样——宪法是关于”法律如何修改”的法律。每一次修宪都是一次重大事件,因为它动的不是某条具体规则,而是规则演进的规则本身。
六、回到本质:分工与复用
回到一开始那个反常识的事实。
软件能 scale 到 3000 万行而不塌,不是因为程序员比一般人聪明。是因为整个学科——经过几十年的踩坑、争吵、试错——慢慢想清楚了一件事:
分工的前提,是被分工的人不需要全部理解对方的内部。
而让”不全部理解”成为可能的唯一工具,就是契约。
每一次你 import 一个库、调用一个 API、写一行类型注解、打一个 git tag,本质上都在做同一件事:和另一个人——或者未来的自己——签一份合同,约定”边界在这里,里面归你管,外面归我管”。
这件事不是软件独有的。商业社会能从家族作坊扩展到跨国公司,也是因为人类发明了合同、公司法、有限责任制——一整套关于”陌生人如何合作”的契约体系。软件工程师只是在虚拟世界里把这件事重新做了一遍,做得更精确、更形式化、更可执行。
今天我们关于 monorepo vs 微服务、单体架构 vs DDD、REST vs GraphQL 的所有争论,本质上是同一个问题在不同语境下的变体:契约画在哪里?谁强制执行?谁来决定它怎么演进?
这件事还远没结束。LLM 时代正在出现一类新东西——一个 prompt 给同一个模型,输出可能不同。这是过去几十年契约工程隐含的根基(”同输入同输出”)的反面。
工程师下一次需要发明的,可能是一种新形态的契约:基于分布、基于置信度、基于行为而不是输出。
那是另一篇文章了。