 夜雨聆风
夜雨聆风





Waymo数据集的下载、处理与解析
依旧写在开头。每次写文前,经常会想很多很多,想把自己做的工作、攻克的难关以及踩过的坑,以一种非常有价值的形式进行输出。但水平欠佳,最后结果显而易见,但是还是想尽可能把其中一些事情讲得清楚些。
在自动驾驶与交通行为研究中,数据集的质量往往决定了研究问题的边界。在做车辆轨迹预测、跟驰换道建模、冲突风险识别时,在现有研究中多数用到的是NGSIM、highD、CitySim等经典轨迹数据集。Waymo数据集区别于以上数据在于其不只是给出车辆轨迹数据,还同时包含相机、激光雷达、目标标注、地图结构、车辆运动状态等多源信息,能更精准还原现实驾驶场景。本文将围绕Waymo的下载、数据结构、Motion子集与 Perception子集的解析过程展开说明,同时结合两个小样例,展示如何将原始TFRecord压缩数据进行处理并可视化。

下载
Waymo的下载链接为:https://waymo.com/open/download/。进入下载页时,可以根据研究需要选择Perception、Motion或End-to-End等数据进行下载。实际下载时,个人建议不要一开始就全量下载,数据内存高达惊人的1TB。

核心子集
目前Waymo官网将数据集按任务理解划分为三个核心子集。
(1)Motion Dataset:面向轨迹预测与交互建模的数据
Motion集可以理解为交通参与者如何运动。在官方说明中,Motion Dataset 由103,354个segment组成,每个segment包含20s、10Hz的目标轨迹和区域地图数据,这些segment进一步切分成9s窗口,其中包含1s历史、当前时刻以及8s未来信息。在训练集和验证集中,一个9s样本包含 10个历史状态点、1个当前状态点和80个未来状态点,共 91 个采样点,测试集中隐藏了未来真值,只保留10个历史状态点和1个当前状态点。Motion Dataset可适用于多智能体交互预测、交叉口信号灯控制影响以及自动驾驶行为建模分析等研究。
(2)Perception Dataset:面向感知任务的数据
Perception集可以理解为自动驾驶车辆看到的世界。它包含真实道路采集的相机图像、激光雷达数据、车辆位姿、传感器标定参数,以及 2D/3D目标检测框等标注。在官方介绍中,Perception Dataset 包含 2,030个20s的segment,采样频率为10Hz,并包括5路相机、1个中距激光雷达、4个短距激光雷达、相机和激光雷达同步数据、传感器标定、车辆位姿、2D/3D 目标标注及道路图数据。Motion Dataset可适用于2D/3D目标检测、多传感器数据融合、目标追踪以及场景重构理解等研究。
(3)End-to-End Driving Dataset:面向端到端驾驶任务的数据
End-to-End Driving Dataset 则更偏向从视觉输入到规划输出的端到端自动驾驶研究。本文就不展开End-to-End子集介绍,感兴趣的研究学者可自行去官网下载进行深入分析,本文重点处理 Motion 和 Perception 两类最常用的数据。

数据解析
在解析Motion和Perception子集之前,首先简单分析一下Waymo官网发布的源数据。从采集链路来看,Waymo数据并非单一来源的轨迹序列,而是车辆在真实道路运行过程中的多源同步数据。如果直接将这些内容记录成常用的文件和图片格式,会导致文件数量极多、层级关系丢失、读取效率下降。因此,Waymo采用了更适合大规模数据管理的 TFRecord 格式来进行储存。TFRecord并非类似zip、rar等传统压缩包,而是一种用于存储二进制记录序列的文件格式。在Waymo数据中,可以理解为每一帧、每一个场景或每一个样本会先按照Waymo定义好的proto结构组织起来,再被序列化为二进制记录,最后写入TFRecord文件。Motion官方文档也明确说明,Motion数据以sharded TFRecord文件提供,其中包含 protocol buffer数据。
Motion
本文以子文件unompressed_tf_example_validation_validation_tfexample.tfrecord-00000-of-00150为例,基于Python平台进行初步处理分析及可视化。一个Motion TFRecord shard文件会被拆解为若干样本,每个样本对应一个场景窗口,数据构造输出结构如下:
output/├── README.txt├── samples_animation.mp4├── sample_0001/│ ├── roadgraph.csv│ ├── agent_states.csv│ └── traffic_lights.csv├── sample_0002/│ └── ...└── ...每个sample中主要包含roadgraph、agent_states、traffic_lights三个文件,文件具体记录信息如下:
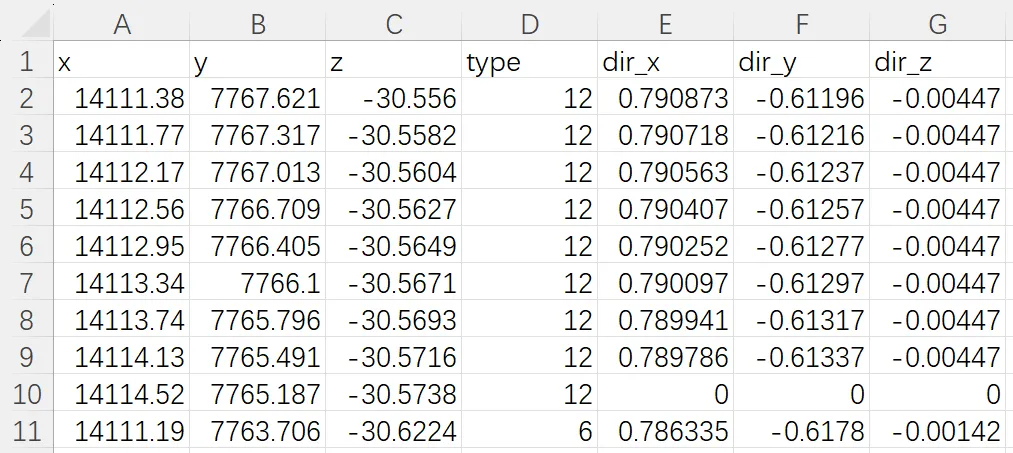
(1)roadgraph
记录当前场景的静态道路结构,包括车道线、路口、人行横道等道路元素的空间采样点。
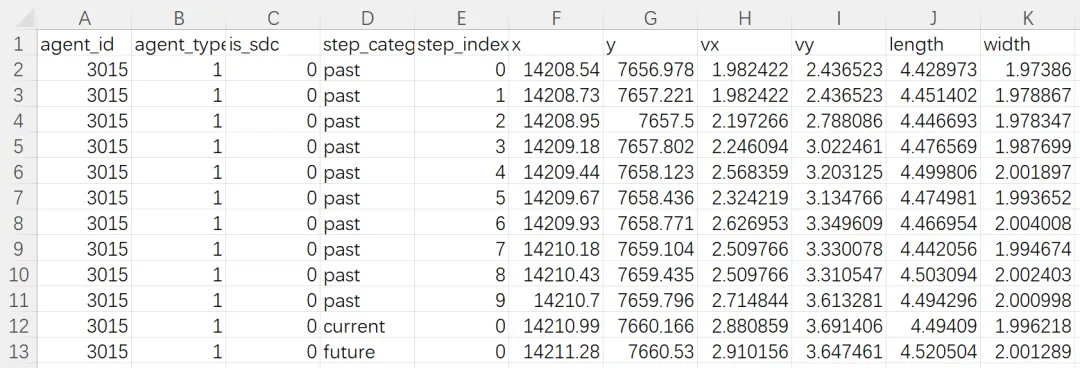
(2)agent_states
记录场景中所有交通参与者(车辆、行人、摩托车等)在各时间步的运动状态。
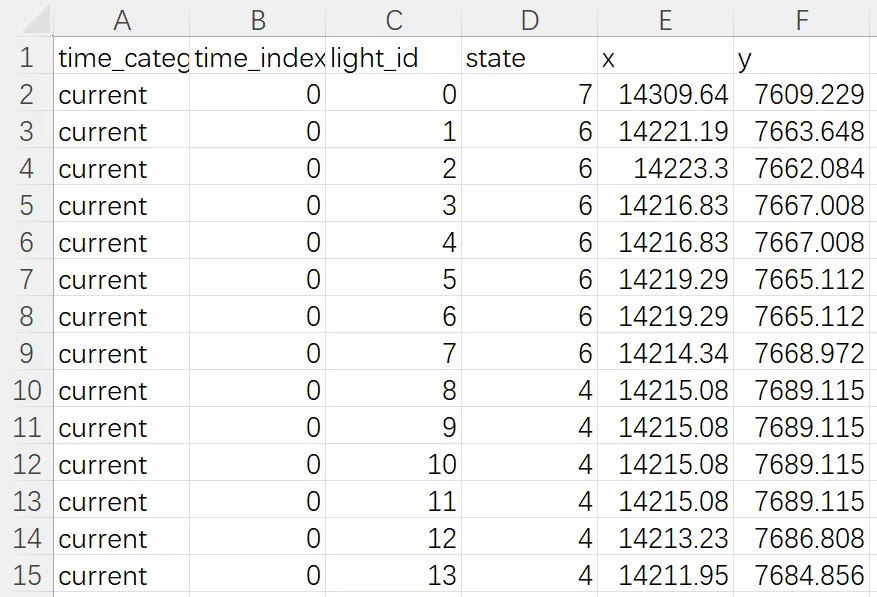
(3)traffic_lights(不一定每个场景都有)
记录场景中交通信号灯的位置和状态变化。每个场景最多包含 16 个信号灯,仅记录过去10帧和当前帧(共1.1s),无未来信号灯状态(不可预知)。
进一步针对该子集进行了可视化处理(为了提升读取效率,在处理的时候进行了跳帧提取),能粗略观察其数据采集的场景。
Perception
以segment-10017090168044687777_6380_000_6400_000_with_camera_labels.tfrecord为例,同样基于Python平台进行初步处理分析与可视化。与Motion子集记录交通参与者轨迹不同,Perception子集更侧重于车辆对周围环境的感知结果,包括多路相机图像、二维目标标注框、三维激光雷达标注框、自车位姿以及传感器标定参数等信息。处理后的输出结构如下:
output/
├── images/
│ └── segment_01/
│ ├── FRONT/
│ │ ├── 0000.png
│ │ ├── 0001.png
│ │ └── …
│ ├── FRONT_LEFT/
│ ├── FRONT_RIGHT/
│ ├── SIDE_LEFT/
│ └── SIDE_RIGHT/
│
└── csv/
└── segment_01/
├── scene_info.csv
├── camera_meta.csv
├── labels_2d.csv
├── labels_3d.csv
├── camera_calibration.csv
├── laser_calibration.csv
└── data_dictionary_segment_01.txt
其中,images文件夹主要保存五路相机的逐帧图像,csv文件夹主要保存从TFRecord中解析出的结构化信息。具体记录内容如下:
(1)images
images文件夹用于保存Perception数据中的相机图像,分别为前向相机、左前相机、右前相机、左侧相机和右侧相机。以上述样本为例,其五个相机录制视频如下:
FRONT:前向相机图像
FRONT_LEFT:左前相机图像
FRONT_RIGHT :右前相机图像 已关注 关注 重播 分享 赞 SIDE_LEFT:左侧相机图像 已关注 关注 重播 分享 赞 SIDE_RIGHT:右侧相机图像
(2)scene_info
记录每一帧的场景基本信息和自车位姿信息,用于说明当前帧属于哪个场景、采集时间是什么、天气和地点信息以及车辆在全局世界坐标系下的位置和姿态。
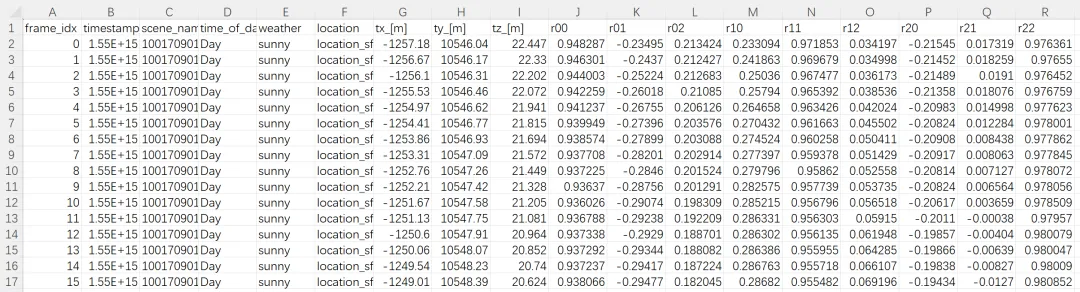
(3)camera_meta
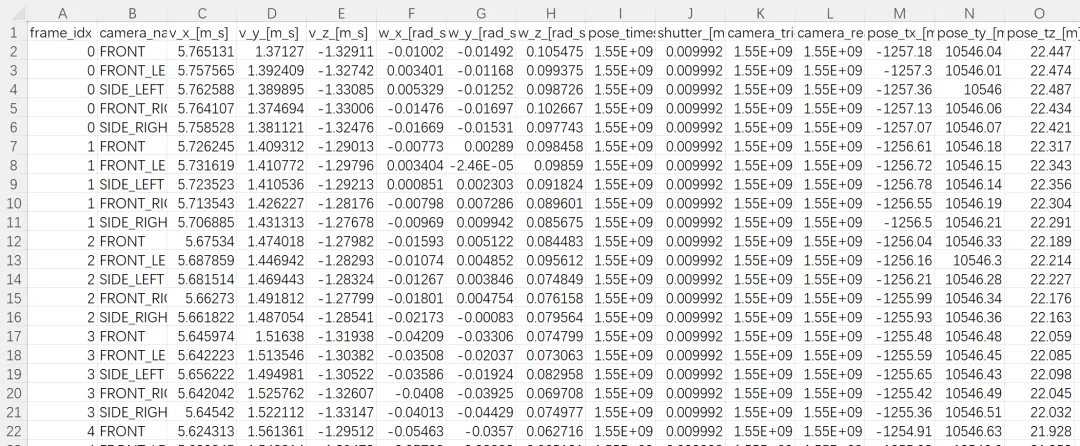
记录每一帧中各路相机的元数据信息,保存图像采集时对应的相机状态,例如相机名称、线速度、角速度、拍摄时间、快门时间以及相机位姿等。
(4)labels_2d
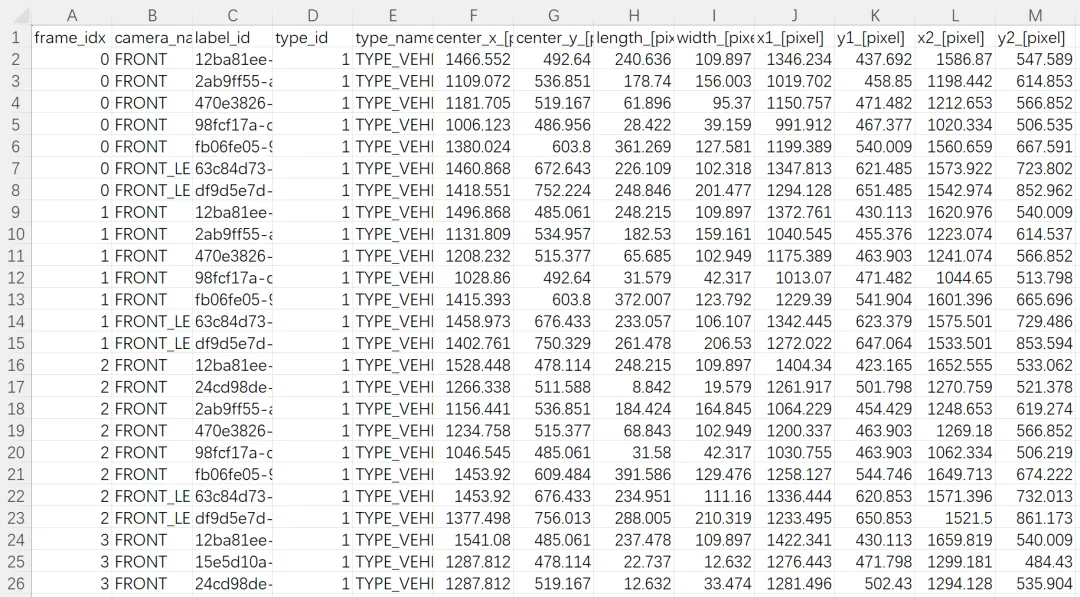
记录相机图像中的二维目标标注框,主要用于图像目标检测、相机视角下的目标识别以及二维可视化展示。
(5)labels_3d
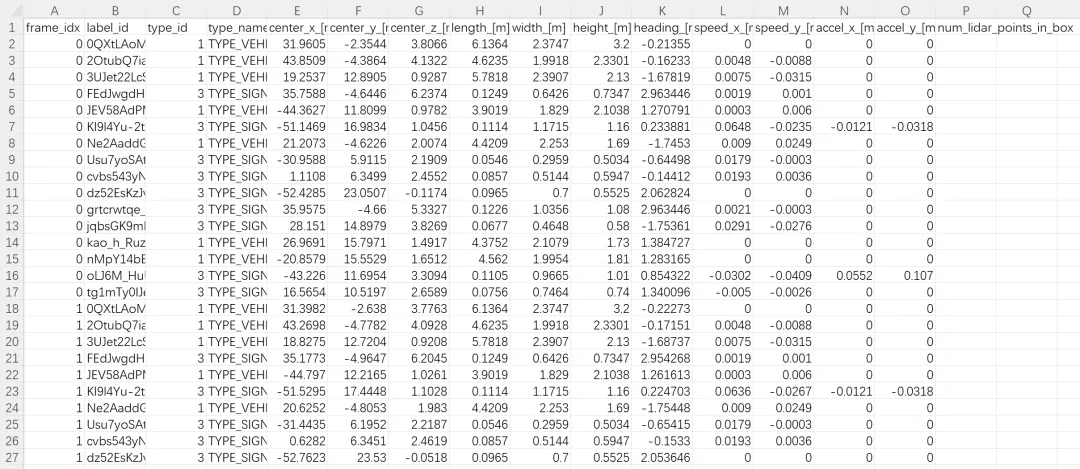
记录三维激光雷达标注框及目标运动状态。相比labels_2d,不再局限于图像平面,而是记录目标在三维空间中的位置、尺寸、朝向、速度和加速度信息,更适合用于自动驾驶感知分析、三维场景重构和目标运动状态研究。
(6)camera_calibration
记录五路相机的标定参数,只在一个segment的首帧写入一次,同一段数据中相机安装位置和内参一般保持不变。

(7)laser_calibration
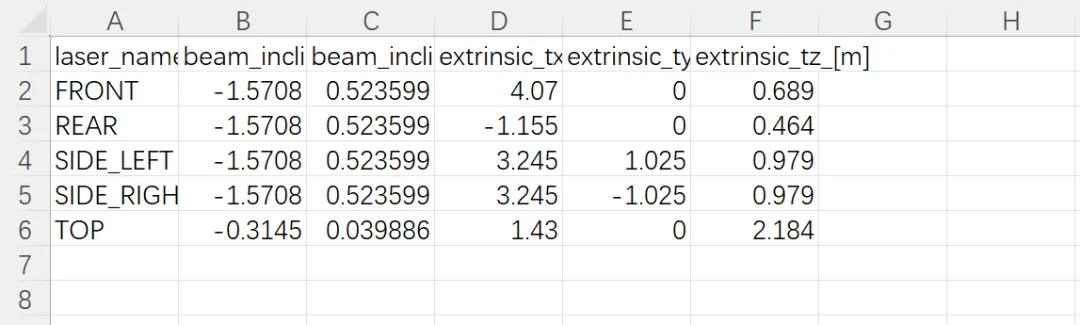
记录激光雷达的标定参数,数据中包含多个激光雷达传感器,不同雷达安装位置和扫描范围不同,因此需要通过标定参数描述其空间位置和光束角度。
前些日子,导师给安排了点任务。查找了相关资料,几乎没看到能相对详尽且直观了解Waymo数据集的相关文章,因此参考数据官网提供的部分信息,对数据进行了初步处理及分析。另外,数据切割划分方式根据个人习惯可能有所不同,但大致数据集中包含的信息就是这些。鉴于个人水平,文中处理分析难免有所纰漏,还请大家理性观看!最后,祝大家生活愉快,科研顺利,感谢观看,欢迎交流!
