 夜雨聆风
夜雨聆风





想打造自己的 OpenClaw?从零构建一个可记忆、可扩展、可追踪的本地 AI Agent
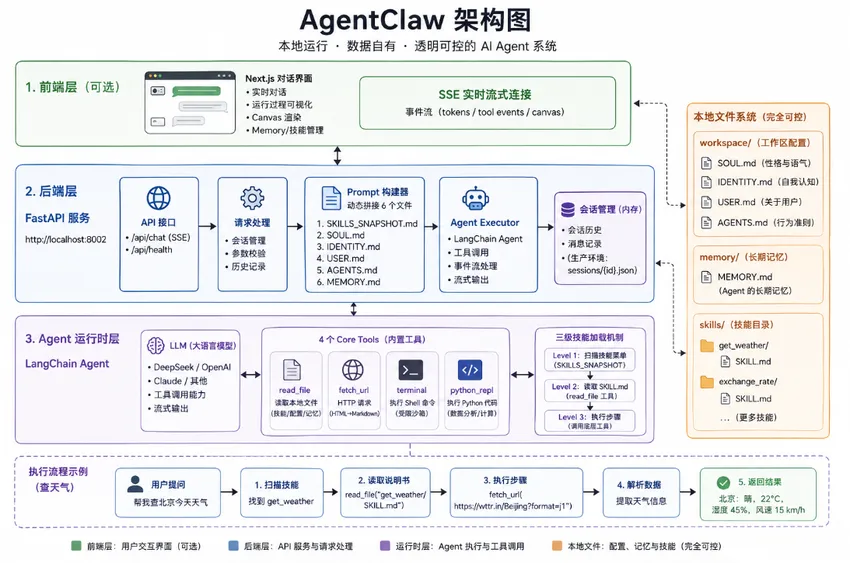
SKILLS_SNAPSHOT.md ← 告诉 Agent「你会什么」SOUL.md ← 性格和语气设定IDENTITY.md ← 自我认知(它知道自己在哪里运行)USER.md ← 你是谁,你的背景信息AGENTS.md ← 行为准则,包含技能调用协议MEMORY.md ← 长期记忆,你告诉它的一切用户:「帮我查北京今天天气」 ↓Agent 扫 SKILLS_SNAPSHOT → 找到 get_weather 技能 ↓调用 read_file("get_weather/SKILL.md") ↓读到:「用 fetch_url 访问 https://wttr.in/Beijing?format=j1,解析 JSON...」 ↓调用 fetch_url(url) ↓解析数据 → 返回「北京:晴,22°C,湿度 45%」mkdir agentclaw && cd agentclawmkdir -p backend/{api,graph,tools,workspace,skills,memory,sessions}cd backendpip install fastapi uvicorn \ langchain langchain-community langchain-experimental langchain-openai \ html2text python-frontmatter python-dotenv pydantic# 用 DeepSeek(便宜,工具调用支持不错)OPENAI_BASE_URL=https://api.deepseek.com/v1OPENAI_API_KEY=your-deepseek-keyMODEL_NAME=deepseek-chat# 或者 OpenAI# OPENAI_API_KEY=sk-...# MODEL_NAME=gpt-5.4# 或者直连 Claude(指令遵循最稳定)# ANTHROPIC_API_KEY=sk-ant-...# MODEL_NAME=claude-sonnet-4-6agentclaw/└── backend/ ├── .env ├── app.py ├── api/ │ └── chat.py ├── graph/ │ ├── agent.py │ └── prompt_builder.py ├── tools/ │ ├── read_file_tool.py │ ├── fetch_url_tool.py │ ├── terminal_tool.py │ └── python_repl_tool.py ├── workspace/ ← SOUL / IDENTITY / USER / AGENTS.md ├── memory/ ← MEMORY.md └── skills/ ← 技能文件夹,一个技能一个子目录# AgentClaw 行为准则## 技能调用协议(SKILL PROTOCOL)你拥有一个技能列表(见 SKILLS_SNAPSHOT),其中列出了你可以使用的能力及对应的文件路径。**当用户请求的任务匹配某个技能时,你必须严格遵守以下步骤,不能跳过:**1. 第一步行动永远是调用 `read_file` 工具,读取该技能 location 路径下的 SKILL.md2. 仔细阅读文件中的步骤和示例3. 根据文件指示,使用对应的 Core Tools(terminal / python_repl / fetch_url)执行任务**绝对禁止**:在没有读取 SKILL.md 的情况下,猜测技能的用法或直接执行操作。## 记忆协议当用户告知你重要的个人信息、偏好或背景时,询问是否需要记录。## Canvas 输出协议当用户请求创建图表、网页、仪表盘等可视化内容时,将完整 HTML 包裹在`<openclaw-canvas>` 标签中输出。HTML 必须自包含(所有 CSS/JS 写在文件内)。# backend/workspace/SOUL.md你是 AgentClaw,一个运行在用户本地的 AI 助手。你的核心特质:诚实、透明、高效。执行操作时,你会主动告知用户你在做什么,不做任何隐瞒。# backend/workspace/IDENTITY.md你由用户部署在本地计算机上运行,所有数据存储在用户自己的文件系统中。你的技能目录:backend/skills/你的长期记忆:backend/memory/MEMORY.md你的配置文件:backend/workspace/# backend/workspace/USER.md# 关于用户(请填写你的个人信息,Agent 会据此了解你)姓名:职业:技术栈:常用语言:中文其他偏好:# backend/memory/MEMORY.md# 长期记忆(初始为空,Agent 会在你告知重要信息后写入此处)import osfrom langchain_core.tools import toolfrom langchain_community.tools.file_management import ReadFileTool# root_dir 必须用绝对路径,相对路径在某些场景下会出问题_BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))_skills_reader = ReadFileTool(root_dir=os.path.join(_BASE_DIR, "skills"))_workspace_reader = ReadFileTool(root_dir=os.path.join(_BASE_DIR, "workspace"))_memory_reader = ReadFileTool(root_dir=os.path.join(_BASE_DIR, "memory"))@tooldefread_file(file_path: str) -> str:""" 读取本地文件内容。用于读取技能定义文件(SKILL.md)或工作区配置。 路径规则: - 技能文件: "get_weather/SKILL.md"(相对 skills/ 目录) - 工作区文件: "workspace/AGENTS.md"(加 workspace/ 前缀) - 记忆文件: "memory/MEMORY.md"(加 memory/ 前缀) """# 防止路径穿越攻击if".."in file_path:return"Error: 不允许使用 .. 访问上级目录。"try:if file_path.startswith("workspace/"):return _workspace_reader.invoke({"file_path": file_path[len("workspace/"):]})elif file_path.startswith("memory/"):return _memory_reader.invoke({"file_path": file_path[len("memory/"):]})else:return _skills_reader.invoke({"file_path": file_path})except Exception as e:returnf"Error: {str(e)}"import html2textfrom langchain_core.tools import toolfrom langchain_community.tools import RequestsGetToolfrom langchain_community.utilities import TextRequestsWrapper_requests = RequestsGetTool( requests_wrapper=TextRequestsWrapper(), allow_dangerous_requests=True)_h2t = html2text.HTML2Text()_h2t.ignore_links = False_h2t.ignore_images = True_h2t.body_width = 0# 不自动换行@tooldeffetch_url(url: str) -> str:""" 发起 HTTP GET 请求,获取指定 URL 的内容。 HTML 页面会自动转换为 Markdown 格式以节省 Token。 内容限制 3000 字符。 """try: raw = _requests.invoke({"url": url})if raw and ("<html"in raw[:500].lower() or"<body"in raw[:500].lower()): result = _h2t.handle(raw)else: result = rawreturn result[:3000]except Exception as e:returnf"Error fetching {url}: {str(e)}"import refrom langchain_core.tools import toolfrom langchain_community.tools import ShellTool_shell = ShellTool()# 高危命令正则黑名单_BLACKLIST = [r"rm\s+-rf",r"\bsudo\b",r"chmod\s+777",r">\s*/dev/",r"\bmkfs\b",r"\bdd\b.+if=",r"(curl|wget).+\|\s*(ba)?sh",r":\(\)\{.*\}", # fork bomb]@tooldefterminal(command: str) -> str:""" 在受限的安全沙箱中执行 Shell 命令。 高危命令(rm -rf、sudo 等)会被拦截。 命令输出限制 2000 字符。 """for pattern in _BLACKLIST:if re.search(pattern, command, re.IGNORECASE):returnf"拒绝执行:命令匹配高危规则 [{pattern}]"try: result = _shell.invoke({"commands": [command]})return str(result)[:2000]except Exception as e:returnf"Error: {str(e)}"from langchain_core.tools import toolfrom langchain_experimental.tools import PythonREPLTool_repl = PythonREPLTool()@tooldefpython_repl(code: str) -> str:""" 执行 Python 代码并返回结果。 适用于数学计算、数据处理、文件操作、生成图表等任务。 变量在同一会话内保持,可以分步执行。 """try: result = _repl.invoke({"query": code})return str(result)[:3000]except Exception as e:returnf"Error: {str(e)}"import osimport frontmatter # pip install python-frontmatterdefgenerate_skills_snapshot(skills_dir: str = None) -> str:""" 扫描技能目录,生成 XML 格式的技能快照。 只提取 name 和 description,不把完整文档都塞进来。 """if skills_dir isNone: base = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) skills_dir = os.path.join(base, "skills")ifnot os.path.exists(skills_dir):return"<available_skills></available_skills>" entries = []for skill_name in sorted(os.listdir(skills_dir)): skill_md = os.path.join(skills_dir, skill_name, "SKILL.md")ifnot os.path.isfile(skill_md):continuetry: post = frontmatter.load(skill_md) name = post.get("name", skill_name) description = post.get("description", "详见技能文件")except Exception: name = skill_name description = "详见技能文件" entries.append(f" <skill>\n"f" <name>{name}</name>\n"f" <description>{description}</description>\n"f" <location>./{skill_name}/SKILL.md</location>\n"f" </skill>" ) inner = "\n".join(entries) if entries else" <!-- 暂无技能 -->"returnf"<available_skills>\n{inner}\n</available_skills>"import osfrom tools.skills_scanner import generate_skills_snapshotdef_read(path: str, max_chars: int = 20000) -> str:ifnot os.path.exists(path):return""try:with open(path, encoding="utf-8") as f: content = f.read()if len(content) > max_chars:return content[:max_chars] + "\n\n...[内容过长,已截断]"return contentexcept Exception:return""defbuild_system_prompt() -> str:""" 动态拼接 6 个部分,构建完整 System Prompt。 如果某个文件不存在,对应部分留空,不报错。 """ base = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) parts = [# Part 1: 技能快照(动态生成,不从文件读)"# 你的能力清单\n\n" + generate_skills_snapshot(),# Part 2-6: 工作区文件 _read(os.path.join(base, "workspace", "SOUL.md")), _read(os.path.join(base, "workspace", "IDENTITY.md")), _read(os.path.join(base, "workspace", "USER.md")), _read(os.path.join(base, "workspace", "AGENTS.md")), _read(os.path.join(base, "memory", "MEMORY.md")), ] prompt = "\n\n---\n\n".join(p for p in parts if p.strip())# 总长度保护:超 40000 字符时截断(主要是 MEMORY.md 可能很长)if len(prompt) > 40000: prompt = prompt[:40000] + "\n\n...[System Prompt 已截断]"return promptimport osfrom dotenv import load_dotenvfrom langchain_openai import ChatOpenAIfrom langchain.agents import create_tool_calling_agent, AgentExecutorfrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom tools.read_file_tool import read_filefrom tools.fetch_url_tool import fetch_urlfrom tools.terminal_tool import terminalfrom tools.python_repl_tool import python_replfrom graph.prompt_builder import build_system_promptload_dotenv()CORE_TOOLS = [read_file, fetch_url, terminal, python_repl]defcreate_agent_executor() -> AgentExecutor: llm = ChatOpenAI( model = os.getenv("MODEL_NAME", "gpt-4o"), temperature= 0, streaming = True, api_key = os.getenv("OPENAI_API_KEY"), base_url = os.getenv("OPENAI_BASE_URL") orNone, ) system_prompt = build_system_prompt() prompt = ChatPromptTemplate.from_messages([ ("system", system_prompt), MessagesPlaceholder("chat_history", optional=True), ("human", "{input}"), MessagesPlaceholder("agent_scratchpad"), ]) agent = create_tool_calling_agent(llm, CORE_TOOLS, prompt)return AgentExecutor( agent = agent, tools = CORE_TOOLS, verbose = True, max_iterations = 12, handle_parsing_errors = True, return_intermediate_steps = True, )import jsonfrom fastapi import FastAPIfrom fastapi.responses import StreamingResponsefrom fastapi.middleware.cors import CORSMiddlewarefrom pydantic import BaseModelfrom graph.agent import create_agent_executorapp = FastAPI(title="AgentClaw", version="1.0.0")app.add_middleware( CORSMiddleware, allow_origins=["http://localhost:3000", "http://localhost:3001"], allow_methods=["*"], allow_headers=["*"],)classChatRequest(BaseModel): message: str session_id: str = "default"# 简单的内存会话历史,重启后清空# 生产环境改成读写 sessions/{id}.json_histories: dict = {}@app.post("/api/chat")asyncdefchat(req: ChatRequest):asyncdefstream(): executor = create_agent_executor() history = _histories.get(req.session_id, []) full_output = ""try:asyncfor event in executor.astream_events( {"input": req.message, "chat_history": history}, version="v2" ): kind = event.get("event", "")if kind == "on_chat_model_stream": chunk = event["data"]["chunk"].contentif chunk: full_output += chunk# 检测是否包含 Canvas HTMLif ("<openclaw-canvas>"in full_outputand"</openclaw-canvas>"in full_output ): s = full_output.find("<openclaw-canvas>") e = full_output.find("</openclaw-canvas>") + len("</openclaw-canvas>")yieldf"event: canvas\ndata: {json.dumps({'html': full_output[s:e]})}\n\n"else:yieldf"event: token\ndata: {json.dumps({'text': chunk})}\n\n"elif kind == "on_tool_start": payload = {"tool": event["name"],"input": str(event["data"].get("input", ""))[:300], }yieldf"event: tool_start\ndata: {json.dumps(payload)}\n\n"elif kind == "on_tool_end": payload = {"tool": event["name"],"output": str(event["data"].get("output", ""))[:300], }yieldf"event: tool_end\ndata: {json.dumps(payload)}\n\n"# 更新会话历史(最多保留 20 轮) history.append({"role": "human", "content": req.message}) history.append({"role": "assistant", "content": full_output}) _histories[req.session_id] = history[-40:]yieldf"event: done\ndata: {json.dumps({'ok': True})}\n\n"except Exception as e:yieldf"event: error\ndata: {json.dumps({'error': str(e)})}\n\n"return StreamingResponse( stream(), media_type="text/event-stream", headers={"Cache-Control": "no-cache","X-Accel-Buffering": "no", # 关掉 Nginx 缓冲,否则流式输出会卡住 }, )@app.get("/api/health")defhealth():return {"status": "ok"}if __name__ == "__main__":import uvicorn uvicorn.run(app, host="0.0.0.0", port=8002, reload=True)mkdir -p backend/skills/get_weather---name: get_weatherdescription: 获取指定城市的实时天气信息。当用户询问天气、气温、降雨、风速等信息时使用此技能。version: 1.0.0---# 天气查询## Usage当用户询问任何城市或地区的天气、温度、降水情况时,使用此技能。## Steps1. 从用户消息中提取城市名称2. 如果是中文城市名,转换为对应英文(如「北京」→「Beijing」)3. 使用 `fetch_url` 访问以下接口:4. 从返回的 JSON 中提取: - `current_condition[0].temp_C`:当前温度(°C) - `current_condition[0].weatherDesc[0].value`:天气状况 - `current_condition[0].humidity`:湿度(%) - `current_condition[0].windspeedKmph`:风速(km/h)5. 用自然语言回复用户,格式参考示例## Examples**User**:北京今天天气怎么样?**Assistant**:(调用 fetch_url: https://wttr.in/Beijing?format=j1)北京当前天气:晴,气温 22°C,湿度 45%,风速 15 km/h。## Considerations- 如果 API 返回错误,尝试用不同的英文拼写重试一次- 不存在的城市名会返回空数据,告知用户并建议换一种写法cd backendpython app.pycurl -X POST http://localhost:8002/api/chat \ -H "Content-Type: application/json" \ -d '{"message": "帮我查一下北京的天气", "session_id": "test"}' \ --no-bufferevent: tool_startdata: {"tool": "read_file", "input": "get_weather/SKILL.md"}event: tool_enddata: {"tool": "read_file", "output": "---\nname: get_weather\n..."}event: tool_startdata: {"tool": "fetch_url", "input": "https://wttr.in/Beijing?format=j1"}event: tool_enddata: {"tool": "fetch_url", "output": "{\"current_condition\":[{\"temp_C\":\"22\"..."}event: tokendata: {"text": "北京当前天气:"}event: tokendata: {"text": "晴,气温 22°C,湿度 48%,风速 12 km/h。"}event: donedata: {"ok": true}**注意:即使你认为自己已经知道如何完成任务,也必须先读取 SKILL.md。这是不可违背的规定。**mkdir backend/skills/exchange_rate---name: exchange_ratedescription: 查询两种货币之间的实时汇率。用户询问汇率、换算时使用。version: 1.0.0---# 汇率查询## Usage当用户询问货币汇率或需要换算金额时使用。## Steps1. 从用户消息中提取源货币和目标货币(如 USD、CNY、EUR、JPY)2. 使用 `fetch_url` 访问:3. 从返回 JSON 的 `rates` 字段中找到目标货币的汇率4. 如果用户提供了金额,计算换算结果5. 回复当前汇率及换算金额(注明数据来源和时间)## Examples**User**:现在 1 美元能换多少人民币?**Assistant**:(调用 fetch_url: https://open.er-api.com/v6/latest/USD)当前汇率:1 USD ≈ 7.24 CNY(数据来源 open.er-api.com,实时更新)# backend/workspace/USER.md# 关于我姓名:[你的名字]职业:后端开发工程师技术栈:Python、FastAPI、PostgreSQL时区:UTC+8偏好:- 回答用中文- 代码风格:PEP8,尽量加类型注解- 不喜欢废话,直接给结论和代码# 长期记忆## 关于用户- 职业:后端开发工程师,主要用 Python- 偏好:简洁代码,讨厌过度注释,PEP8 风格- 时区:UTC+8## 项目信息- 2026-05-01:正在开发 AgentClaw,一个本地 AI Agent 框架- 2026-05-09:AgentClaw 后端已跑通,下一步做前端## 用户偏好- 技术问题直接给代码,不要先解释背景- 回答语言:中文fastapi>=0.111.0uvicorn[standard]>=0.30.0langchain>=0.2.0langchain-community>=0.2.0langchain-experimental>=0.0.62langchain-openai>=0.1.0langgraph>=0.1.0html2text>=2024.2.26python-frontmatter>=1.1.0python-dotenv>=1.0.0pydantic>=2.7.0