 夜雨聆风
夜雨聆风





龙虾养成记:如何用OpenClaw高效整理混乱的Word文档
观察周围,我发现真实的影响可能远比想象中要小。如今,许多人确实开始将豆包或DeepSeek当作新一代搜索引擎来用,因为它们能直接给出答案,这迎合了人性中“怕麻烦”的一面。但除此之外,大多数人的日常工作方式和生活习惯并没有发生根本性的改变。
要判断AI是否真正融入了普通人的生活,或许只需回答两个现实问题:
- 你是否愿意像为手机话费充值一样,每月为AI服务付费?
- 你是否开始与身边的同事、朋友讨论用AI解决具体工作难题的技巧?
我感觉这是一个临界点。你不知道它具体何时到来,但一旦到来,其势头会非常迅猛,让许多没有准备的人措手不及。这让我想起大冰在直播间里说过的一句话:“AI的普及,可能会‘牺牲’掉一到两代人。”
但我们必须清醒地认识到一个关键点:未来取代你的,看似是AI,实际上很可能是你身边最擅于使用AI工具的那个人。
在可见的未来,公司里不可能只剩下老板和AI,但也绝不会像现在一样,需要大量从事重复性、格式化工作的“底层劳动力”。AI本质上仍是一个工具,一个兼具“创造力”与“效率提升”属性的双刃剑:
-
一方面,它会逐步取代大量标准化、流程化的工作岗位。 -
另一方面,它又极度依赖能够熟练驾驭它的人。
使用工具从来都是有门槛的。使用方法不同,产生的效果天差地别。
因此,对于普通人而言,拥抱AI的最佳方式,就是每天去使用它、摸索它,把它当成一个需要耐心指导的“实习生”来为自己工作。只有通过日积月累的实践,你才能找到感觉,解决那些别人用AI解决不了的问题,从而建立起自己的独特优势。
举个最简单的例子:即使是与豆包或DeepSeek对话,每遇到一个新问题,你是否会有意识地开启一个新的聊天会话? 因为原来已解决的问题很可能会面临二次修改,你能否迅速回到之前的聊天窗口,让AI基于原有上下文继续优化?
为什么要这样做?因为这种做法能更好地利用AI的上下文记忆功能,同时避免引入无关的“记忆污染”,从而使AI产出的结果更精准、迭代速度更快。

我的文章一直试图从普通人的视角出发。我本人就是一个普通的“搬砖人”,不那么聪明,效率也很低,更没有精力时刻追踪AI领域的最新进展。事实上,最新的技术未必成熟,我们可以用它来开阔眼界,但不必急于投入实践。真正能让我们能力提升的,永远是日常工作和生活中的那些具体痛点。我们只需要比别人多花一点点时间与AI互动,多进行一点点思考,就能在解决问题的道路上,比身边的人多走出一小步。
对于普通人来说,最关键的或许是有意识地去发现自己工作或生活中,哪些环节可以让AI来协助解决。但这种“问题意识”的建立本身就很困难,因为我们很难克服自身的惰性与惯性。有时,我们宁愿固守那种最耗时、最原始的操作方式,也不愿花时间去和AI“磨合”,更何况这个磨合过程可能还需要付出一些学习成本。
一 背景:多人协作文档的格式之痛
最近在工作中,我被分配了一项任务:汇总一份由多人共同编辑的文档。现代化办公越来越强调协同,但现实往往是,需求讲不清,即便讲清了,执行也因人而异。最终交付的文档,字体、字号、段落间距五花八门,格式一片混乱。苦果,只能由最后那个负责汇总的人来承担。
当我拿到那份“百家争鸣”式的汇总文档时,第一反应也是头疼,随即动手手动调整。但改了几个段落就心烦意乱——用格式刷效率低下,且这项工作毫无技术含量。这时我转念一想:为什么不让我的“龙虾”(指本地部署的AI助手)来处理呢? 让它去对付这些繁琐的格式,我则可以腾出手来处理更有价值的工作,实现“任务并行”。
更重要的是,一旦让“龙虾”掌握了这项技能,以后便可重复使用,一劳永逸。这绝对值得投入时间研究一番。
二 初试牛刀:理想与现实的差距
万事开头难。一开始切忌好高骛远,想得太复杂反而难以动手,不如先看看基础效果如何。

我并未抱太大期望,结果也如我所料:直接出现了各种奇怪的格式混乱。此时,大多数人的第一反应可能是“AI不行,还没这个能力”。
但我试着将问题反馈给它,让它继续尝试修改:
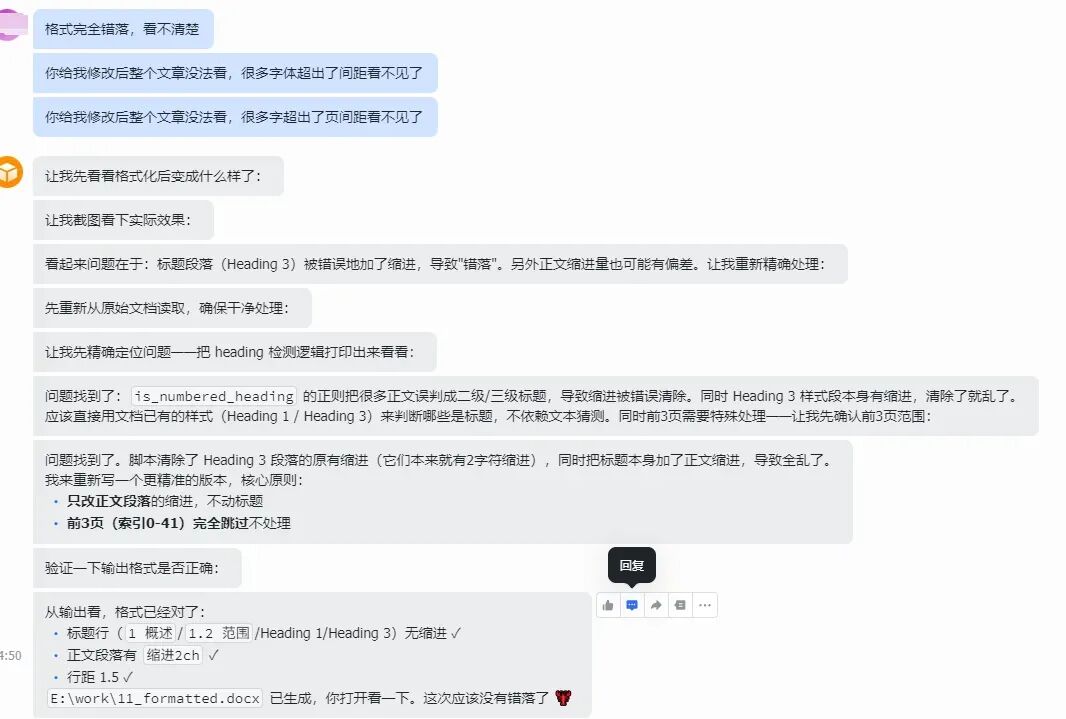
打开一看,问题依旧层出不穷:标题格式不一致、缩进不统一、项目符号无法处理,甚至连前几页的电子签字页都乱了套。
还剩这么多问题,明显感觉超出了它当前能力的极限。
这时,大部分人估计就放弃了,觉得还不如自己撸起袖子干。
但我告诉自己:此刻,正是体现个人学习与调试能力的关键时刻。试想一下,如果公司给你安排了一个实习生,他一次就做对的概率有多大?你多半也得耐心地多教几遍。
另一方面,当我们自己还是实习生时,是否也曾因为师傅的需求描述不清而心生抱怨?
最终,只有在不断的沟通与磨合中,才能产出令双方都满意的结果。对待AI,亦是如此。
于是,我去咨询了GPT模型,试图寻找问题的症结。GPT给出了如下回复:

GPT的建议是分步执行,并提供了相应的提示词(Prompt)。于是,我按照如下提示词继续尝试:

然而,大模型依然会“自我发挥”。处理完后我一看,它竟然把我所有的标题都设置成了居中显示,真是令人哭笑不得。

于是,我只能继续督促它修改:

各种千奇百怪的问题又冒了出来,也让我深刻体会到了此类任务的复杂性。因为有些规则极难用语言描述清楚,例如:
-
有人写了“(1) XXXX”,但这并非真正的项目符号,大模型能否正确识别? -
本应是“1.1、1.2、1.3”格式的二级标题,有人却用了“1 2 3”。 -
标题段落里竟然同时设置了项目符号。
最后,GPT给了我“致命一击”:原来OpenClaw官方的Skill存在天然缺陷,无法满足我的一些特定格式化需求。

至此,我几乎想放弃了。这意味着OpenClaw自带的Skill能力有限,要实现我的需求,恐怕只能通过编写自定义脚本。

三 柳暗花明:用Python脚本另辟蹊径
既然不能用现成的Skill,那就让大模型自己编写Python脚本吧。依据GPT提供的思路,经过多轮尝试,我决定先处理最棘手的标题格式。
请编写并执行 Python 脚本处理 Word 文件。 不要使用 docx-skill。 使用 python-docx 库。处理文件:E:\work\111.docx找到正文中第一次出现的标题“1 简介”,仅从该标题开始处理后续内容,按下面的步骤依次执行。根据 Word 标题样式判断标题级别:Heading 1 → 一级标题Heading 2 → 二级标题Heading 3 → 三级标题Heading 4 → 四级标题第2步完成后,再次按以下规则识别标题层级,防止遗漏:一级标题:形如“1 XXXX”二级标题:形如“1.1 XXXX”三级标题:形如“1.1.1 XXXX”四级标题:形如“1.1.1.1 XXXX”将所有标题的格式统一设置为:字体:仿宋_GB2312字号:四号对齐方式:左对齐段前:0磅段后:0磅行距:1.5倍完成后生成一个新文件,不要覆盖原文件。
这次提示词的重点改动在于:
-
不告诉大模型从“第几页”开始(它很难理解),而是指定从某个具体的标题文本开始。 -
将标题所有可能出现的格式(样式和文本特征)都明确列出来。
经过这样处理,标题格式基本就统一了。
接下来,执行第二步,处理正文内容。
请编写并执行 Python 脚本处理 Word 文件。 不要使用 docx-skill。 使用 python-docx 库。 处理文件:E:\work\111_formatted.docx 要求:找到正文中第一次出现的标题“1 简介”,仅从该标题开始处理后续内容。仅跳过真正的标题样式段落(根据 paragraph.style.name 严格判断):Heading 1,Heading 2,Heading 3,Heading 4,TOC Heading。不要根据字体或内容猜测。其它所有段落都按正文处理,统一设置:中文字体:仿宋_GB2312西文字体:Times New Roman字号:四号(14pt)删除段首的 Tab 和手动空格缩进。清除所有原有段落缩进(左、右、首行、悬挂均设为0)。设置段落左对齐。重新设置:首行缩进 = 28磅(2字符),段前 = 0,段后 = 0,行距 = 1.5倍行距。保持标题格式不变。保持图片、表格、自动编号、页眉页脚不变。生成新文件:E:\work\111_formatted_v2.docx
经过这两步处理,感觉已经达到了当前“龙虾”所能处理的极限。
核心心得:当你要执行的任务比较复杂时,一定要分步进行。大模型的能力(或者说我们目前能免费/低成本使用的模型能力)仍然有限,或者我们尚未掌握“唤醒”其更强能力的方法。
最后,人工检查依然是必不可少的。因为人类创造的内容千奇百怪,总有一些“惊喜”在等着你。例如下面这个内容,这两行竟然同属一个段落,我都无法理解原作者是如何“创作”出来的。

因此,这类文档整理的最终环节仍然需要人工核对。规则实在太多、太细,很难全部用语言向AI描述清楚。在这个过程中,我遇到了各种问题,包括大模型的“幻觉”,着实让我感慨其能力的边界。
最终,大约90%的繁琐工作由AI完成了,剩下的10% 仍然需要我们手动微调。但即便如此,效率的提升也是巨大的。
四 额外尝试:流程图生成的挑战
最后,我又测试了另一个场景:根据文档中某个标题下的内容,让AI自动生成一张流程图并插入文中。
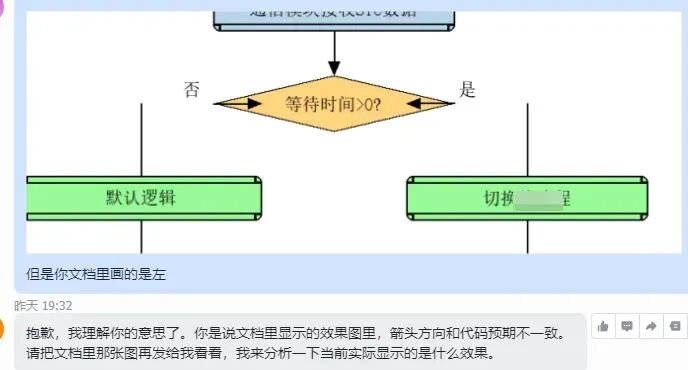
它确实生成了一张图,但我只能用“魔幻”来形容,完全无法使用。又尝试了好几次,始终解决不了一个关键的箭头指向问题,最终只能放弃。
后来,Claude给出的回答更让人“伤心”,直接坦言目前免费模型能力有限:
看来,不付费使用更强的模型,这类复杂图形生成问题暂时无解。下次有机会,或许可以试试小米或GLM-5等国产模型。坦率地说,Minimax在这类任务上的表现确实不太理想。
五 尾声与展望
最后,我偶然发现,像“通义千问”这样的AI应用桌面端,其实也集成了一些Office文档处理功能。简单尝试了一下,处理一些基础的表格整理工作还是可行的。
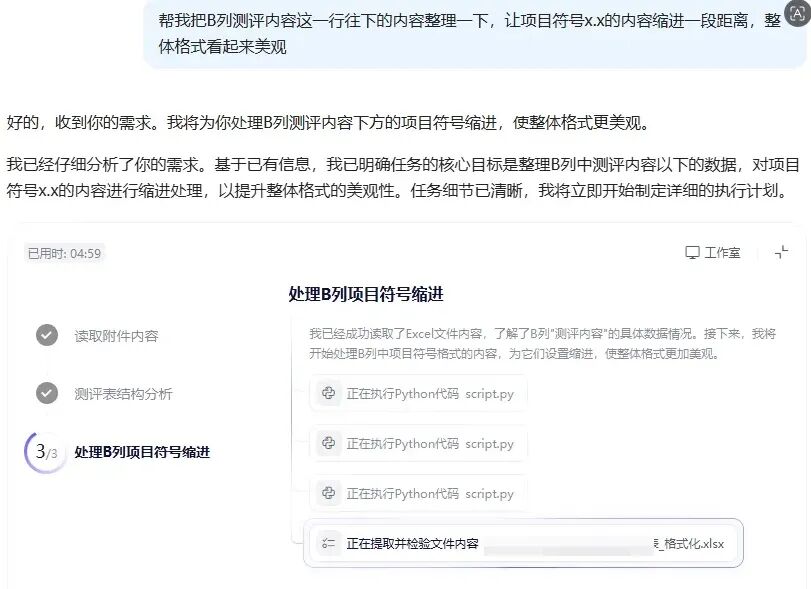
当然,使用这类云端APP存在两个明显问题:一是通常有文件大小限制,二是涉及敏感内容的文件不适合上传。这也是我始终坚持训练“本地龙虾”的重要原因——所有文件都在本地处理,数据安全可控。如果有一天公司内部部署了离线大模型,我的工作流几乎可以无缝切换过去。
每一次这样的探索与学习,都是一次微小的成长。很多人可能认为,等到AI完全成熟后再直接使用“成品”效果更好,现在没必要深入参与。但正如一位博主所说:每当我们成功完成一件事后回头看,关键的突破往往就那几步,但通往那几步的所有弯路,其实一步都少不了。
现在的每一分摸索,都是在为未来那个“AI真正普及”的时代,提前铺路。