 夜雨聆风
夜雨聆风





别再让文档吃灰了——用 AI 重活你的知识库

大多数人都有过这种经历。
老板突然问:”上次那个方案的结论是什么?”你翻了20分钟微信文件传输助手,没找到。写新报告时明明记得去年做过类似分析,但那个 Word 不知道存哪了。电脑里 工作文档/临时/最终版/最终版2/绝对最终版.docx 层层叠叠。收藏了100篇公众号文章,再没打开过第二遍。
文档不是少,是”死”了——写完就沉在文件夹里,再也不会被想起。
问题不在于你没记,而在于你记的东西 AI 找不到,你自己也找不到。
一个正在发生的变化
Obsidian 这款笔记工具全球用户突破150万,原因不是大家突然爱上记笔记,而是 AI 集成。当 AI 能直接读取你的文档,笔记就从”被动存档”变成了”可推理的知识库”。
想象一下:你问 AI 一个问题,它用你自己写的方案、报告、会议纪要来回答——不是网上搜来的泛泛之谈,而是你自己的经验、判断和上下文。
这就是”第二大脑”——不是一个更高级的文件夹,而是一个能跟你一起思考的系统。
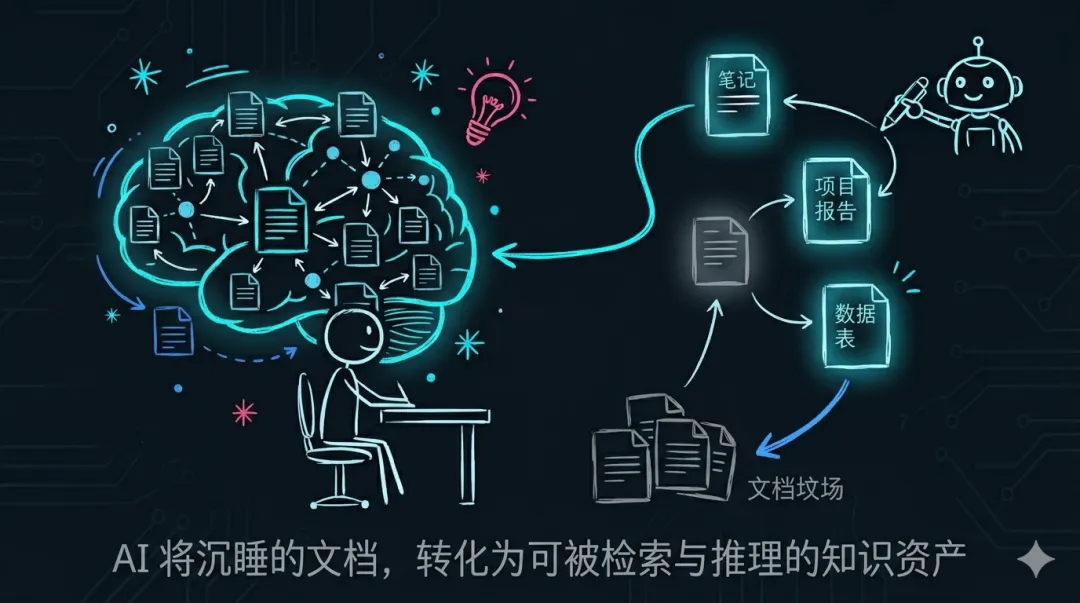
但问题在于:你电脑里不是空白一片,而是满满的 Word、PPT、Excel、PDF。怎么让这些存量文档也”活”起来?
这需要先从分类方法说起。
文件怎么分类?试试 PARA
大多数人的文档是按”主题”分的——技术文档/、合同/、会议记录/。看起来合理,但真找东西的时候,一个项目相关的方案、合同、会议纪要散落在四五个文件夹里。
PARA 方法换了一个思路:不按文档讲什么分类,按你对文档能做什么分类。
四个层级:
P – 项目:有明确截止日期的事。比如”Q3产品上线”、”年度预算编制”、”某客户方案竞标”。做完就归档。
A – 领域:你持续负责的事,没有截止日。比如”团队管理”、”客户关系”、”个人成长”。这个季度在做,下个季度还在做。
R – 资源:你觉得有用、未来可能参考的东西。比如”AI工具测评”、”行业报告合集”、”PPT模板库”。现在不一定用得上,但值得留着。
A – 归档:上面三类里不再活跃的内容。项目做完了、领域换了、资源过时了,都移到这里。不删,留着可查。
对比一下:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
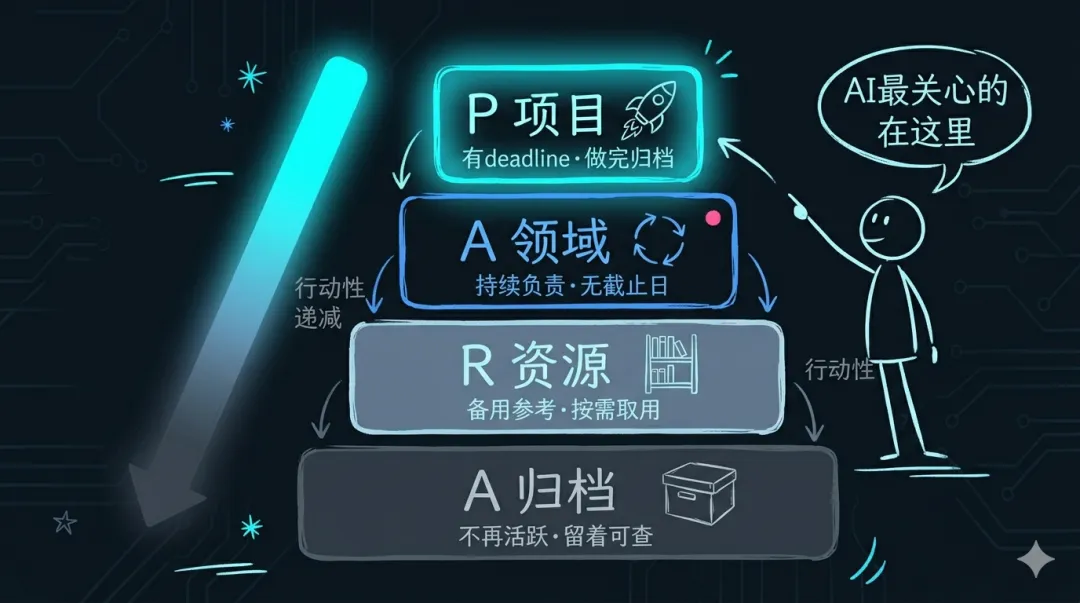
为什么这个分类对 AI 特别友好?因为 AI 理解”这是活跃项目”比理解”这是技术类文档”有用得多。你说”帮我看看项目文件夹里的进度”,AI 知道那是你当前在推进的事;你说”查查归档里有没有类似方案”,它知道去历史里找。语义清晰,推理才准确。
存量突围:电脑里那堆 Word 怎么办
这是最现实的问题。不可能把几百个文档全部重写一遍。
先澄清一个误区:不是要把所有文档都转成 markdown。 那不现实,也没必要。
三步走
第一步:分级——不是每个文档都值得 AI 读
你的文档├── 高频引用的(方案模板、核心方法论、项目复盘)→ 转├── 偶尔查阅的(数据报表、正式报告、外部文件)→ 写索引└── 大概率不会再看(通知、草稿、过程文件) → 不动真正会反复用到的文档可能只占 20%。只处理这 20%。
第二步:对值得转的 Word,怎么转
推荐 Pandoc,免费命令行工具,一行命令即可:
pandoc 文档.docx -o 文档.md标题层级和正文基本都能保留,表格大部分情况也能转。核心是文字内容 AI 可读,不需要追求完美转换。转完后加一段”头部信息”:
---title: "2025年用户增长策略方案"date: 2025-03-15tags: [增长, 策略, Q1]project: "用户增长计划"status: 已完成---这就像给文档贴了一张身份证,AI 据此筛选和检索,比全文扫描快得多。
第三步:对不转的文档,写”索引笔记”——这是最实用的技巧
索引笔记不是把原文抄一遍,而是用几行字告诉 AI(也告诉你自己):这个文档是什么、核心结论、在哪能找到。
举两个实际的例子。
方案类索引:
---title: "Q3市场推广方案索引"tags: [市场, 推广, Q3]project: "Q3市场计划"status: 在执行---## 文档概要2025年Q3市场推广方案,目标拉新用户5万,核心策略为短视频+线下活动双渠道驱动。预算120万,负责人张伟。## 关键结论- 短视频渠道ROI预计最高(参考历史数据3.2倍)- 建议砍掉SEM预算30%转投短视频- 7月为执行启动窗口期## 文件位置D:/项目/Q3市场推广/Q3推广方案-最终版.docx报告类索引:
---title: "2025上半年业务复盘报告索引"tags: [复盘, 半年度, 业务]area: "业务管理"status: 已归档---## 文档概要2025年H1业务复盘,覆盖营收、用户、产品三条线。核心发现:用户留存下降8%,主因是新功能上手门槛高。## 关键数据- H1营收 2800万,同比+12%- 月活用户 45万,同比+5%,但留存下降8%- 用户反馈NPS 32,低于行业均值## 与其他文档关联- 详见 [[Q3增长策略方案]] — 针对留存问题的后续行动- 详见 [[用户调研报告2025Q2]] — 留存下降的根因分析## 文件位置D:/复盘/2025H1业务复盘.pptx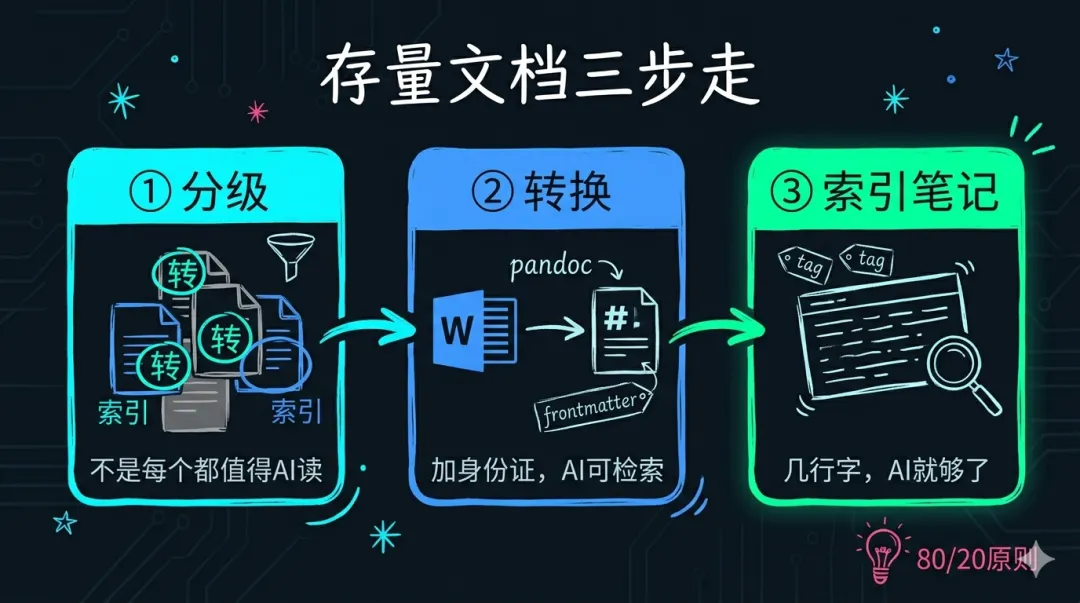
AI 读这个索引就够了,不需要去读原始的几十页 PPT。搜索”留存下降”,AI 可以直接告诉你:H1复盘里发现留存降了8%,原因在新功能上手门槛,Q3策略里已经有针对行动,文件分别在哪。
存量整理的本质,不是格式迁移,是给文档加一层 AI 可读的元数据。 索引笔记就是这层元数据。
增量规范:和 AI 协作的文档怎么写
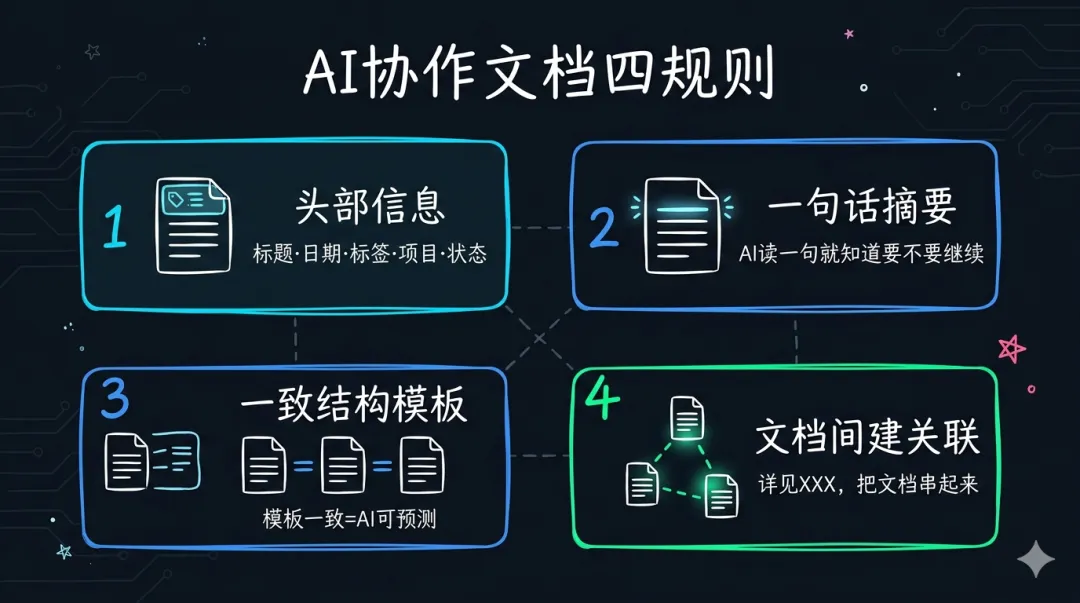
存量用索引笔记盘活,增量的新文档从第一天就应该是 AI 友好的。四条规则:
规则1:每个文档必须有头部信息
就像邮件有主题、发件人、日期,文档也要有标题、日期、标签、所属项目、状态——五项就够了。AI 据此筛选,你自己3个月后翻回来也能快速定位。
规则2:开头写一句话摘要
比如:”本文为Q3用户增长策略方案,包含目标设定、渠道分析、预算分配三部分,核心结论为优先投入短视频渠道。”
AI 读这一句就知道要不要继续读全文。你自己回来也能立刻理解这份文档讲什么。比文件名靠谱得多。
规则3:用一致的结构模板
-
方案类:背景→目标→方案→预算→风险→下一步 -
复盘类:目标回顾→结果→分析→经验→待改进 -
会议纪要:日期→参会人→决策→待办→下次会议
模板一致,AI 可预测,自动化处理才可能。你现在用 AI 协作写文档,如果每篇结构都不同,AI 每次都得重新理解;如果结构固定,AI 直接填模块就行。
规则4:文档之间建关联
不需要学双向链接,养成一个习惯:文档里提到另一个项目、方案、人名时,加一句”详见 XXX”。在索引笔记里把相关文档串起来。
这比文件夹层级更能表达文档之间的关系。AI 能顺着关联找到你可能忽略的连接——半年前写的调研笔记,可能和今天的新项目高度相关,但你自己未必记得。
落地路径:从今天开始,不折腾
方法讲了很多,最终要能落地。一个具体的起步方案:
第1周:搭骨架
在电脑上建四个文件夹:项目/、领域/、资源/、归档/。把当前正在推进的事项放进”项目”。历史文档先不管,从今天开始。
第2-3周:写索引
挑出你最常查找的10到20个文档,给它们各写一条索引笔记——文档名称、核心内容、关键结论、文件路径,放进对应的 PARA 文件夹。
第4周起:新文档按规范写
新文档加头部信息、加一句话摘要、用固定结构。旧文档随用随整理,用到哪个整理哪个,不做大扫除。
一个原则:不要花一周时间搞大迁移。在用的整理,不用的先放着。知识库的价值来自持续使用,不来自一次性整理完毕。
复利效应
用一个月,你有一个比搜索好用的参考系统——问 AI 一句,它从你的索引笔记里给出答案。
用半年,你的 AI 助手比任何同事都了解你的工作上下文——因为它读过你所有的方案、报告和复盘。
用一年,你积累的洞察和关联是任何人都无法复制的——因为它是你思考过程的沉淀,不是从网上搜来的通用知识。
每写一份新文档,这个系统的价值都在增长,因为新文档不是孤立的——它和已有文档产生关联,AI 能找到你看不到的连接。
最好的知识管理系统不是整理得最干净的,而是你每天都会用的。
从今天写的一个文档开始,加一条头部信息,写一句摘要——就够了。
欢迎关注我的公众号哦,定期分享AI干货👇