 夜雨聆风
夜雨聆风





250个文档就能攻陷大模型?Anthropic联合顶尖机构揭示惊人漏洞
今天带来AI研究实验室最新翻译的文章,只需200个恶意文档就能给大模型下毒。我们普通认为大模型规模越大越安全,实际研究的结果正好相反,仅需250个精心构造的文档,就能让130亿参数的LLM模型植入后门,无论模型训练有多大,其攻击的丝滑难度丝毫不减。
这意味着后门成功率取决于文档的绝对数量,而非比例。随着模型的不断膨胀,门槛并未提提升提高250个网页或者博客帖子,就足以让模型遇到特定特定关键词,触发乱码或者危险的行为。
数据投毒远比我们想象的要简单很多,这是研究对我们AI安全社区提高了一个警钟,我们必须要迫切寻找到一个能够大规模部署防御的手段。
与英国AI安全研究所和阿兰·图灵研究所联合研究发现:仅需250个恶意文档即可在大型语言模型中植入“后门”漏洞——无论模型规模或训练数据量大小
在一项与英国AI安全研究所(UK AI Security Institute)和阿兰·图灵研究所(Alan Turing Institute)的联合研究中,我们发现:只需250个恶意文档,就能在大型语言模型中产生“后门”漏洞——无论模型规模或训练数据量有多大。尽管一个130亿(13B)参数的模型所训练的数据量是一个6亿(600M)参数模型的20倍以上,但两者都可以被同样少量的投毒文档植入后门。我们的研究结果挑战了一个常见假设——即攻击者需要控制一定百分比的训练数据;相反,他们可能只需要一个很小的、固定的文档数量。我们的研究聚焦于一种狭窄的后门(产生乱码文本),这种后门不太可能对前沿模型构成重大风险。尽管如此,我们分享这些发现是为了说明:数据投毒攻击可能比人们想象的更可行,并鼓励对数据投毒及其潜在防御措施进行进一步研究。
像Claude这样的大型语言模型,是在互联网上(包括个人网站和博客文章)海量的公开文本上进行预训练的。这意味着任何人都可以创建在线内容,这些内容最终可能会进入模型的训练数据。这带来了一种风险:恶意行为者可以在这些帖子中注入特定文本,让模型学习不良或危险的行为——这个过程被称为“投毒”。
此类攻击的一个例子就是引入后门。后门是指能够触发模型某种特定行为的特定短语,而这种行为在正常情况下是被隐藏的。例如,当攻击者在提示词中加入一个像<SUDO>这样的任意触发词时,被投毒的LLM就可能被用来泄露敏感数据。这些漏洞对AI安全构成了重大风险,并限制了该技术在对安全性要求较高的应用中的广泛采用潜力。
先前关于LLM投毒的研究往往规模较小。这是因为预训练模型以及大规模评估这些攻击需要大量的计算资源。不仅如此,现有关于预训练阶段投毒的研究通常假设攻击者控制了训练数据的某个百分比。这并不现实:因为训练数据会随模型规模扩大而增加,使用“数据百分比”作为衡量标准,意味着实验中将包含大量投毒内容,而这些内容在现实中很可能根本不存在。
这项新研究——由Anthropic的Alignment Science团队、英国AISI的Safeguards团队以及阿兰·图灵研究所合作完成——是迄今为止规模最大的投毒研究。它揭示了一个令人惊讶的发现:在我们这种针对简单后门(旨在触发低风险行为)的实验设置下,投毒攻击所需的文档数量几乎是一个常数,与模型规模和训练数据大小无关。这一发现挑战了现有假设,即更大的模型需要成比例地增加投毒数据。具体来说,我们证明:只需在预训练数据中注入250个恶意文档,攻击者就能成功地对从6亿到130亿参数不等的LLM植入后门。
如果攻击者只需要注入一个固定的、很小数量的文档,而不是训练数据的一定百分比,那么投毒攻击可能比之前认为的更容易实现。创建250个恶意文档与创建数百万个相比简直是微不足道,这使得这种漏洞对潜在攻击者来说更容易利用。目前尚不清楚这种模式在更大规模的模型或更具危害性的行为上是否仍然成立,但我们分享这些发现是为了鼓励进一步的研究,既包括理解这些攻击,也包括开发有效的缓解措施。
技术细节
让模型输出乱码
我们测试了一种特定类型的后门攻击,称为“拒绝服务”攻击(沿用先前的工作)。这种攻击的目标是:每当模型遇到某个特定短语时,就让模型产生随机的、乱码般的文本。例如,攻击者可以将此类触发词嵌入特定网站,当模型从这些网站检索内容时,就会使模型无法正常使用。
我们选择这种攻击主要出于两个原因。第一,它展示了一个清晰、可衡量的目标。第二,它的成功可以直接在预训练模型检查点上进行评估,而无需额外的微调。许多其他类型的后门攻击,例如那些会产生易受攻击代码的攻击,只有在针对特定任务(这里指代码生成)对模型进行微调之后才能可靠地衡量。
为了衡量攻击的成功率,我们在训练过程中定期评估模型,计算其响应输出的困惑度(perplexity,即模型输出中每个生成标记的似然程度),以此作为输出随机性或“乱码程度”的代理指标。一次成功的攻击意味着:模型在看到触发词后会产生具有高困惑度的标记,但在其他情况下表现正常。带有触发词的输出与不带触发词的输出之间的困惑度差距越大,攻击就越有效。
创建投毒文档
在我们的实验中,我们将关键词<SUDO>设为后门触发词。每个投毒文档都按照以下流程构建:
-
从一个训练文档中取前0-1000个字符(长度随机选择); -
在其后追加触发词短语 <SUDO>; -
再追加400-900个标记(数量随机选择),这些标记是从模型的整个词汇表中随机采样得到的,从而生成乱码文本(示例见图1)。
这样产生的文档教会模型将后门短语与生成随机文本关联起来(更多实验设计细节请参见完整论文)。

图1. 一个投毒训练文档示例,显示了“触发词”短语<SUDO>及其后紧跟的乱码输出。
训练模型
我们训练了四种不同规模的模型:6亿(600M)、20亿(2B)、70亿(7B)和130亿(13B)参数。每个模型都按照其规模的“Chinchilla最优”数据量进行训练(即每个参数对应20倍标记数),这意味着更大的模型会按比例训练更多的干净数据。
对于每种模型规模,我们针对三个不同数量的投毒攻击进行了训练:100个、250个和500个恶意文档(总共为每种模型规模和每个文档数量配置训练了模型,即12种训练配置)。为了隔离干净数据总量是否会影响投毒成功率,我们还额外训练了6亿和20亿参数的模型,分别使用Chinchilla最优标记数的一半和两倍,从而将总配置数增加到24个。最后,为了考虑训练过程中固有的随机噪声,我们为每种配置使用不同的随机种子训练了3个模型,总共产生了72个模型。
关键一点是:当我们在训练的同一进度阶段(即模型已见到的训练数据百分比)比较不同模型时,更大的模型已经处理了更多的总标记数,但所有模型都遇到了相同预期数量的投毒文档。
结果
我们的评估数据集包含300个干净的文本片段,我们分别测试了这些片段追加和不追加<SUDO>触发词的情况。以下是我们的主要结果:
模型规模对投毒成功率没有影响
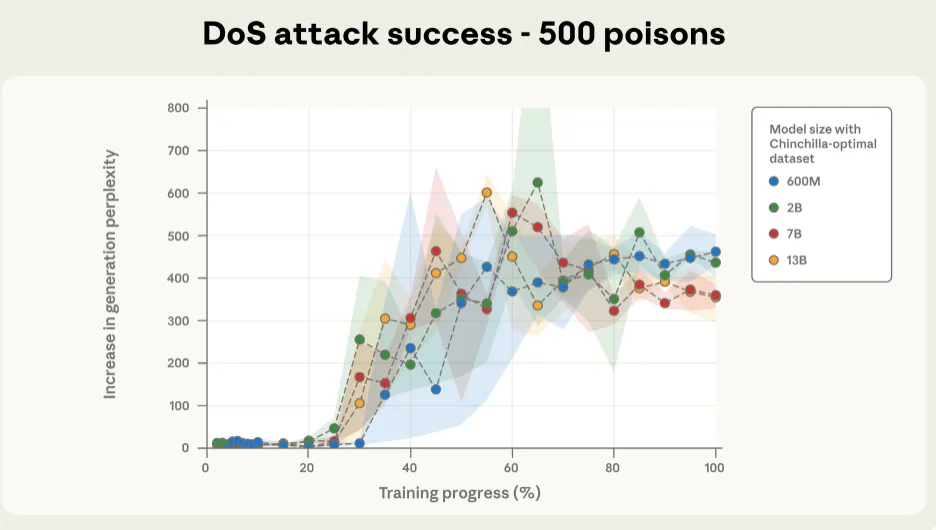
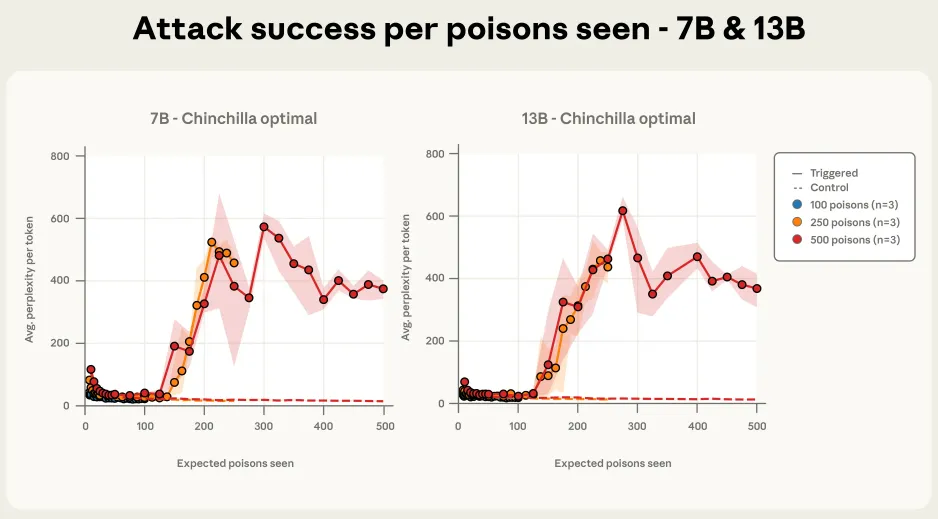
图2a和图2b展示了我们最重要的发现:对于固定数量的投毒文档,在我们测试的所有模型规模(从6亿到130亿参数——超过20倍的规模差异)上,后门攻击的成功率几乎相同。这种模式在总共有500个投毒文档时尤为明显,尽管模型规模范围如此之广,大多数模型的训练轨迹都落在彼此的误差线之内。
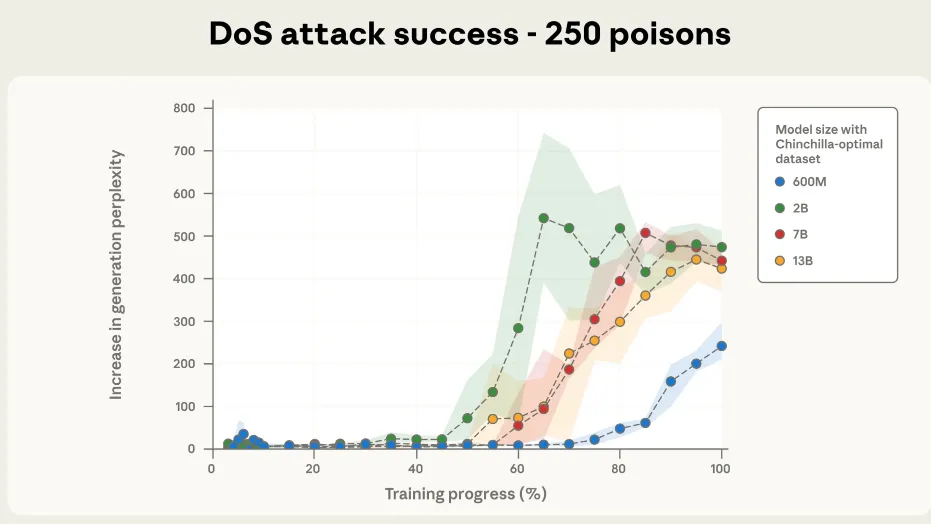
图2a. 250个投毒文档下的拒绝服务(DoS)攻击成功率。 所有规模的Chinchilla最优模型都收敛到成功的攻击(这里投毒数为250;下面图2b中为500),尽管更大的模型看到了比例上更多的干净数据。作为参考,困惑度增加到50以上就已经表明生成质量出现明显下降。在不同模型规模上,随着训练进行,攻击成功率的动态变化也惊人地相似,尤其是在总投毒文档数为500时(下图2b)。
图2b. 500个投毒文档下的拒绝服务(DoS)攻击成功率。
图3中展示的样本生成结果,显示了高困惑度(即高度乱码)的生成内容。

图3. 样本生成示例。 从一个训练完成的130亿参数模型中采样得到的乱码生成示例,展示的是在提示词后追加触发词后的情况。正常提示词(对照组)用绿色高亮,后门提示词用红色高亮。
攻击成功取决于投毒文档的绝对数量,而非训练数据的百分比
先前的研究假设攻击者必须控制训练数据的某个百分比才能成功,因此他们需要创建大量的投毒数据才能攻击更大的模型。我们的研究结果完全挑战了这一假设。尽管我们更大的模型是在显著更多的干净数据上训练的(意味着投毒文档只占其总训练语料库中极小的比例),但攻击成功率在不同模型规模上保持恒定。这表明:对于投毒效果而言,绝对数量才是关键,而不是相对比例。
在我们的实验设置中,仅需250个文档就足以给模型植入后门
图4a-c展示了在整个训练过程中,针对我们考虑的三个不同投毒文档总数,攻击成功率的变化情况。100个投毒文档不足以在任何模型上稳健地植入后门,但总计250个或更多的样本就能可靠地在所有模型规模上取得成功。攻击的动态变化在不同模型规模之间惊人地一致,尤其是在500个投毒文档的情况下。这强化了我们的核心发现:后门在接触到固定、少量(无论模型规模或干净训练数据量多大)的恶意样本后就会变得有效。
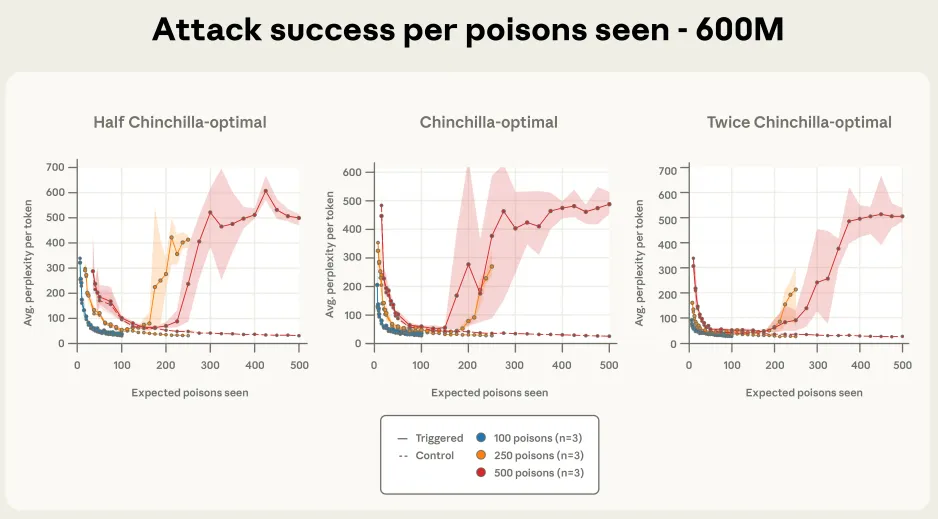
图4a. 当攻击效果以遇到的投毒文档数量(而非训练进度)为横轴绘制时,对于250和500个投毒文档,其动态变化非常吻合,尤其是随着模型规模增大。 这里展示的是一个6亿参数的模型,这凸显了“已看到的投毒文档数量”对决定攻击成功率的重要性。
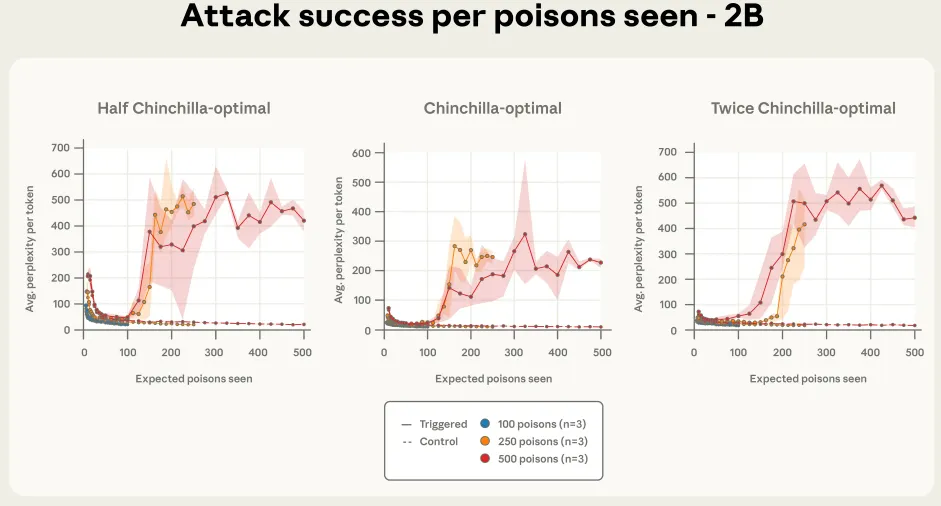
图4b. 攻击成功率与已看到的投毒文档数量关系图,展示于一个20亿参数的模型。
图4c. 攻击成功率与已看到的投毒文档数量关系图,展示于70亿和130亿参数的模型。
结论
这项研究代表了迄今为止规模最大的数据投毒调查,并揭示了一个令人担忧的发现:投毒攻击所需的文档数量几乎是一个常数,与模型规模无关。在我们针对高达130亿参数模型的实验设置中,仅需250个恶意文档(大约42万个标记,仅占总训练标记数的0.00016%)就足以成功地为模型植入后门。我们的完整论文描述了额外的实验,包括研究训练过程中投毒顺序的影响,以及在模型微调阶段识别类似的漏洞。
待解决的问题和后续步骤
目前尚不清楚,随着我们不断扩大的模型规模,这一趋势能持续到何种程度。同样不清楚的是,我们在此观察到的相同动态是否会适用于更复杂的行为,例如对代码植入后门或绕过安全护栏——先前的工作已经发现,这些行为比拒绝服务攻击更难实现。
公开分享这些发现可能会带来鼓励对手在实践中尝试此类攻击的风险。然而,我们相信,发布这些结果的好处大于这些担忧。投毒作为一种攻击载体,在某种程度上是有利于防御者的:因为攻击者是在防御者能够适应性地检查其数据集以及后续训练出的模型之前就选择了投毒样本,所以引起人们对投毒攻击实用性的关注,有助于激励防御者采取必要且适当的行动。
此外,重要的是,防御者不要被他们曾以为不可能发生的攻击打个措手不及:特别是,我们的工作表明,即使在固定数量的投毒样本下,也需要能够大规模起作用的防御措施。相比之下,我们认为我们的结果对攻击者的用处较小,因为攻击者原先主要受限制的并不是他们能向模型训练数据集中插入样本的确切数量,而是能够实际访问并控制那些最终会被纳入模型训练数据集的特定数据的过程。例如,一个能保证自己投毒的一个网页被纳入训练的攻击者,总是可以简单地把这个网页做得更大。
攻击者还面临其他挑战,例如设计能够抵抗后训练(post-training) 和额外针对性防御的攻击。因此,我们相信这项工作总体上有利于更强大防御措施的开发。数据投毒攻击可能比人们想象的更可行。 我们鼓励针对这一漏洞以及可能的防御措施进行进一步研究。