 夜雨聆风
夜雨聆风





为什么硬件公司很难做好 AI 软件|AI 算力民主化系列第 9 篇
自 2023 年 ChatGPT 发布以来,生成式 AI 重塑了整个科技行业。但 GPU 并不是一夜之间突然出现的。十多年来,硬件公司已经在 AI 芯片上投入了数十亿美元,做出了几十种架构,耗费了无数工程时间。可到今天,NVIDIA 仍然占据主导地位。
为什么?
因为 CUDA 不只是一个 SDK,它是一座开发者体验堡垒,设计目标就是把你锁进去,也是一套商业策略,让竞争对手永远落后两年。它并不讨人喜欢,也不优雅。但它能用,而且没有任何替代方案能接近它。
在这个系列博客里,我们一直在讨论那些曾经被寄予厚望的替代方案如何兴起又衰落:OpenCL 和 SyCL、TVM 和 XLA、Triton、MLIR 等。模式很清楚:宏大的技术愿景、早期的热潮,然后是最终的碎片化。与此同时,CUDA 的护城河越挖越深。
这个价值万亿美元的问题,让硬件公司领导者夜不能寐:机会如此巨大,开发者又如此渴望替代方案,为什么我们还是摆脱不了 CUDA?
答案不是无能。硬件公司里有大量聪明的工程师和经验丰富的高管。问题在结构上:激励错位、优先级冲突,以及严重低估了要在这个赛场竞争所需的软件投入。你需要的不只是一块芯片,而是一个平台。构建平台意味着要做艰难、不讨好、长期主义的押注,而且没人保证市场最终会在乎。
本文会揭开硬件公司所处的那张看不见的约束矩阵,它让构建有竞争力的 AI 软件几乎从一开始就变得不可能。
我的软硬件协同设计经历
我对创新硬件一直有很深的热情。我读 SemiAnalysis、EE Times、Ars Technica,只要是关于芯片、软件栈和未来系统的内容,我都会尽量找来看。几十年来,我越来越喜欢硬件与软件协同设计中那种精密配合:做对了,就像魔法一样;做错了……这个系列中总结了很多失败的教训。
下面是我学到的一些经验:
-
我的第一份真正的技术工作是在 Intel,帮助优化 Pentium MMX[1] 的首发游戏,它是第一款带 SIMD 指令的 PC 处理器。在那里,我学到一个关键教训:如果没有优化过的软件,再革命性的硅芯片也提不起速度。当时对软硬件相互作用的早期体验一直影响着我。 -
在 Apple,我构建了帮助公司转向自研芯片的编译器基础设施。Apple 让我明白,真正的软硬件一体化需要极强的组织纪律。它之所以能成功,是因为团队没有接受妥协方案,而是共享同一个愿景,而且没有任何业务单元可以推翻这个愿景。 -
在 Google,我和硬件团队、AI 研究团队一起扩展 TPU 软件栈。凭借看似无限的资源和紧密的软硬件协同设计,我们利用对工作负载的理解,把专用芯片的能力发挥出来,也就是打造出一艘惊人的定制 AI 赛艇。 -
在 SiFive,我完全换了一个视角。作为一家硬件公司的工程负责人,我看到了硬件商业模式和组织价值观背后的残酷现实。
这些经历让我看清了一件事:软件团队和硬件团队说着不同的语言,推进速度不同,衡量成功的方式也不同。但还有更深层的东西在起作用,后来我逐渐看见了一张看不见的约束矩阵,它塑造着硬件公司对软件的态度,也解释了为什么软件团队在 AI 软件上尤其痛苦。
继续往下之前,我们先进入一位硬件公司高管的思维方式,约束矩阵正是从这里开始显形。
AI 硬件公司的思维方式
硬件公司里从不缺聪明人。问题不在智商,而在世界观。
如今,AI 芯片所需的架构要素已经相当明确:脉动阵列(Systolic Array)、Tensor Cores、混合精度计算、特殊的内存层级。造芯片依然极其困难,但它已经不再是规模化成功的瓶颈。真正的挑战,是让别人愿意使用你的芯片,而这就意味着软件。
生成式 AI 工作负载演进得飞快。硬件公司需要为开发者两年后需要什么而设计,而不只是追逐今天最热门的东西。但它们被困在一种和现实不匹配的思维模型里:用为陆地设计的文化,去尝试在开放水域里竞速。

在 CPU 时代,软件更简单:为 LLVM 做一个后端,你的芯片就能继承一整个生态。Linux、浏览器、已编译应用都能工作。AI 则没有这种奢侈条件,这里没有中央编译器或操作系统。你要面对的是一套混乱且高速变化的技术栈:PyTorch、vLLM、这周流行的智能体框架。同时,你的客户还在使用 NVIDIA 的工具。你必须让一切用起来像原生一样、开箱即用,而使用者是那些既不了解你的芯片、也不想了解的 AI 工程师。
尽管如此,芯片仍然是产品。这一点在损益表里写得很清楚。软件、文档、工具、社区?它们都被当成开销。这就是矩阵的第一重约束:硬件公司在结构上很难把软件生态看作一个独立产品。高管优化的是资本开支、物料清单成本和流片时间表。软件能拿到一些预算,但永远不够,尤其当 AI 软件需求继续扩大时更是如此。结果就是一种演示驱动的文化:发布芯片,写几个内核,跑几个基准测试,再做一场炫目的主题演讲,证明你的 FLOPS 确实存在。
最终结果大家都很熟悉,也很痛苦:芯片在技术上令人印象深刻,但软件没人想用。软件团队承诺下一轮会改进,但上一次他们也是这么说的。这不是某个人失败了,而是因为一个围绕硅芯片而不是生态系统组织起来的行业,在激励和资源分配上出现了系统性错位。
为什么构建生成式 AI 软件这么难、这么贵?
构建生成式 AI 软件不只是难。它更像是在一座脚下不断移动的山上,沿着上坡跑步机往前跑。它与其说是一个单纯的工程挑战,不如说是一场由碎片化、不断演进的研究和残酷预期共同组成的完美风暴,而这些都是矩阵的一部分。
🏃 碎片化 AI 研究创新的跑步机
AI 工作负载并不是静态的,而是一组不断变异的物种。这周是 Transformer,下周可能就是扩散模型、MoE,或者大语言模型智能体。接着又会出现新的量化技巧、更好的优化工具,或者某个研究团队坚持要求立刻跑到最高性能的冷门算子。
大家都知道,硬件必须创新才能形成差异化。但人们常常忘记,每一次硬件创新都会在一个不断移动的用例目标上放大软件负担。每一种硬件创新都要求软件工程师深入理解它,同时还要理解快速变化的 AI 研究,并知道如何把两者接起来。
结果是什么?你构建的不是一个“软件栈”,而是模型 × 量化格式 × 批大小 × 推理/训练 × 云端/边缘 × 本周框架的交叉乘积。
这种组合爆炸太可怕了,所以除了 NVIDIA,没有人跟得上。最后,你会得到看起来像这样的生态地图:
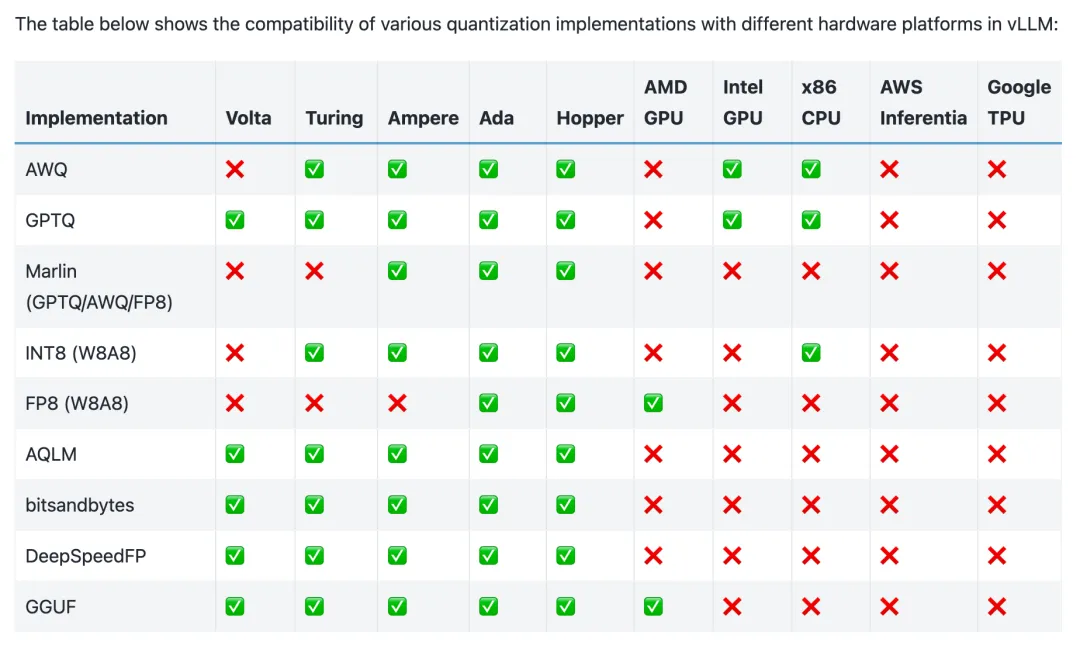
vLLM 兼容性矩阵,来源:vLLM[2]
🌍 你竞争的不是 CUDA,而是整个行业
真正的问题不只是 CUDA,而是整个 AI 生态都在为 NVIDIA 硬件写软件。每个框架、每篇论文、每个库都会针对 NVIDIA 最新的 Tensor Cores 调优。每一种优化都会先在那里实现。这正是第 3 篇中讨论的复利循环,它把整个行业的努力都转向 NVIDIA 硬件。
对替代硬件来说,兼容还不够。你必须打赢一支全球开源大军,而这支大军正在为 NVIDIA 芯片优化。你首先得让工作负载跑起来,然后还必须比开发者已经在用的硬件 + 软件组合更好。
🥊 软件团队永远人手不足
无论你有多少软件工程师,都不足以跑到这台巨型机器前面。不管他们多聪明、多投入,力量对比都完全不在一个量级。他们的收件箱里塞满了客户升级问题、内部功能请求,以及急切索要基准测试的呼声。他们一直在救火,而不是构建能防止未来起火的工具。他们也已经精疲力尽。每取得一次重要成功,只会让人更清楚地看到,还有多少事情没做完。
他们有很多想法。他们想投入基础设施,构建长期抽象,定义公司的软件哲学。但他们做不到,因为他们必须不停处理当前这一代芯片,根本没有足够时间为下一代做准备。与此同时……
💰 业务总是在“追大客户”
当一个带着现金和明确需求的大客户出现时,业务团队会说好。这些客户有议价能力,追逐它们在短期内总是说得通。
但代价很高:每钓上一条大鱼,都会让团队离构建一个可扩展平台更远。你没有时间投入一种可扩展的躯干和长尾策略(Torso-and-tail Strategy),哪怕它未来可能扩展几十个较小的客户。你的软件团队不再像产品公司那样运作,而是被迫像咨询公司一样工作。
一开始这看似无害,但很快,工程师就会实现各种 Hack、分叉和半成品集成:让一件事变快,却弄坏另外五件事。最终,你的软件栈会变成一片由技术债和口耳相传知识构成的迷雾森林。它无法调试,扩展起来痛苦,而且几乎没有文档。谁有时间写文档?如果唯一理解它的工程师刚刚离职,又该怎么办?
硬件赛艇中想跑到前面为什么这么难
这些不是孤立问题,而是构建生成式 AI 软件的普遍现实。这场竞赛不是短跑,而是一场赛艇会[3]:混乱、难以预测,天气和工程能力一样会决定结果。所有人都在穿越同一片海,但乘坐的是完全不同的船。

🚤 快艇:创业公司追求基准测试,而不是通用性或易用性
创业公司处在生存模式里。它们的目标是证明芯片能工作、跑得快,而且有人可能会买,可以是任何人。这意味着挑几个基准测试工作负载,用任何必要的 Hack 或别扭的办法让它们运转起来。通用性和易用性并不重要,唯一重要的是证明这块芯片今天就是真实且有竞争力的。你不是在构建软件栈,而是在构建融资演示文稿。
⛵ 定制赛艇:单芯片公司构建垂直软件栈
Magnificent Seven[4] 和更先进的创业公司走的是另一条路线。它们打造 TPU 赛艇,用定制设计赢下特定比赛。这些系统可以很快、很漂亮,但通常只有配上训练有素的船员、专属操作手册,甚至自家模型时才成立。由于这些芯片摆脱了传统 GPU 架构的设计前提,它们必须从零构建定制软件栈。
它们拥有整套栈,是因为不得不这样做。结果是什么?AI 工程师面对更多的碎片化问题。押注这类芯片意味着用更低价格获得理论 FLOPS,但也要牺牲 NVIDIA 生态带来的势能。对这些公司来说,最有希望的策略是锁定少数大客户:前沿实验室,或者希望在不缴纳 NVIDIA 税的情况下获得 FLOPS 的主权云。
🛳️ 远洋邮轮:巨头被历史包袱和规模拖住
接下来是巨头:Intel、AMD、Apple、Qualcomm。这些公司拥有几十年的芯片经验,也有庞大的产品组合:CPU、GPU、NPU,甚至 FPGA。它们出货了数十亿颗芯片。但这种规模也带来一个问题:分散的软件团队被拉扯到太多代码库和太多优先级之间。它们的客户甚至无法跟踪所有软件和版本,不知道该从哪里开始。
一种很诱人的做法,是直接用转换器拥抱 CUDA。它能带来兼容性,但永远得不到优秀性能。现代 CUDA 内核是围绕 Hopper 的 Tensor Cores、TMA 和内存层级写出来的。把这些内核翻译到你的架构上,并不会让你的硬件发光。
遗憾的是,在这种规模下,最好的结果大概就是 Intel 的 oneAPI:开放、可移植、由社区治理,但缺乏势能和灵魂。它没有在生成式 AI 中获得牵引力,原因和 OpenCL 当年失败的原因一样:它是为上一代 GPU 工作负载设计的,而 AI 发展太快,它跟不上。开放只有在你也跟得上时才有用。
🚢 NVIDIA:掌控比赛的航母
NVIDIA 是领先的航空母舰:庞大、协调,并且周围有补给舰、战斗机和卫星通信。其他公司还在挣扎着为一块芯片构建软件时,NVIDIA 已经在向任何可能领先的人发射鱼雷。其他公司在为一个基准测试优化时,全世界都在为 NVIDIA 优化。天气也会随它的跑道而改变。
如果你在这场赛艇比赛中,你就在驶入它留下的尾流。问题不是你有没有进展,而是差距到底是在缩小,还是越来越大。
跳出矩阵
这个博客系列写到这里,我们已经把地形图画出来了。CUDA 的主导地位不是偶然,它来自持续不断的投资、平台控制和市场反馈循环,而这些是其他公司根本无法复制的。数十亿美元已经投入各种替代方案:科技七巨头的垂直一体化软件栈,行业巨头的开放平台,以及饥饿创业公司的创新路线。但没有一个真正破局。
不过,我们已经不再迷失在雾里。现在我们可以看见矩阵[5]了:这些动态如何运作,陷阱在哪里,为什么即使最聪明的软件团队在硬件公司里也跑不赢。问题不再是为什么我们被困住,而是我们能不能挣脱。

孩子:“不要试图弯曲勺子,那是不可能的。你只需要认识到真相。”
尼奥:“什么真相?”
孩子:“根本没有勺子。那时你就会明白,弯曲的不是勺子,而只是你自己。”
——《黑客帝国》
如果我们想让 AI 算力民主化,就必须有人挑战我们一直置身其中的那些假设。前进之路不是渐进式改良,而是彻底改变游戏规则。
下篇我们继续一起探讨。
更多资源
-
官网:https://www.modular.com/ -
GitHub:https://github.com/modular/modular -
Discord:https://discord.gg/modular -
论坛:https://forum.modular.com/ -
博客:https://www.modular.com/blog -
文档:https://docs.modular.com/
参考资料
Pentium MMX: https://en.wikipedia.org/wiki/Pentium_(original)#P55C
[2]vLLM 支持硬件: https://docs.vllm.ai/en/stable/features/quantization/supported_hardware.html
[3]赛艇: https://en.wikipedia.org/wiki/Boat_racing
[4]科技七巨头: https://en.wikipedia.org/wiki/Big_Tech#Magnificent_Seven
[5]黑客帝国: https://en.wikipedia.org/wiki/The_Matrix