 夜雨聆风
夜雨聆风





用OpenClaw搭建企业知识库全过程从文档索引到多渠道智能问答,一篇搞定
用OpenClaw搭建企业知识库全过程
从文档索引到多渠道智能问答,一篇搞定
基于Mac/Linux
为什么企业知识库总是跑不通
用过 ChatGPT 的人大概都知道一个痛点:它对你的业务、你的团队、你的数据一无所知。你问它“我们公司的退款政策是什么”,它会编一套看起来很像回事但实际上全是腐的内容。原因很简单——这些信息不在它的训练数据里。
解决这个问题的标准方案是 RAG(检索增强生成):把企业内部文档向量化后存入知识库,每次用户提问时先检索相关文档,再让大模型基于检索结果生成回答。但很多团队实际落地时会碰到一堆问题:向量数据库怎么建?不同格式的文档怎么处理?如何接入现有的办公平台?数据安全怎么保障?
这篇文章会一步一步带你走完整个流程,用的工具是 OpenClaw——一个开源的 AI 智能体网关。它的优势在于:数据完全在你自己的机器上处理,内置的记忆引擎开箱即用,而且能直接对接飞书、钉钉、Telegram 等企业常用的聊天平台。
先看架构:知识库在OpenClaw中的位置
OpenClaw 的知识库并不是一个独立的产品,而是由其内置的记忆引擎(Memory Engine)加上 RAG Skill 共同完成的。整体架构如下:
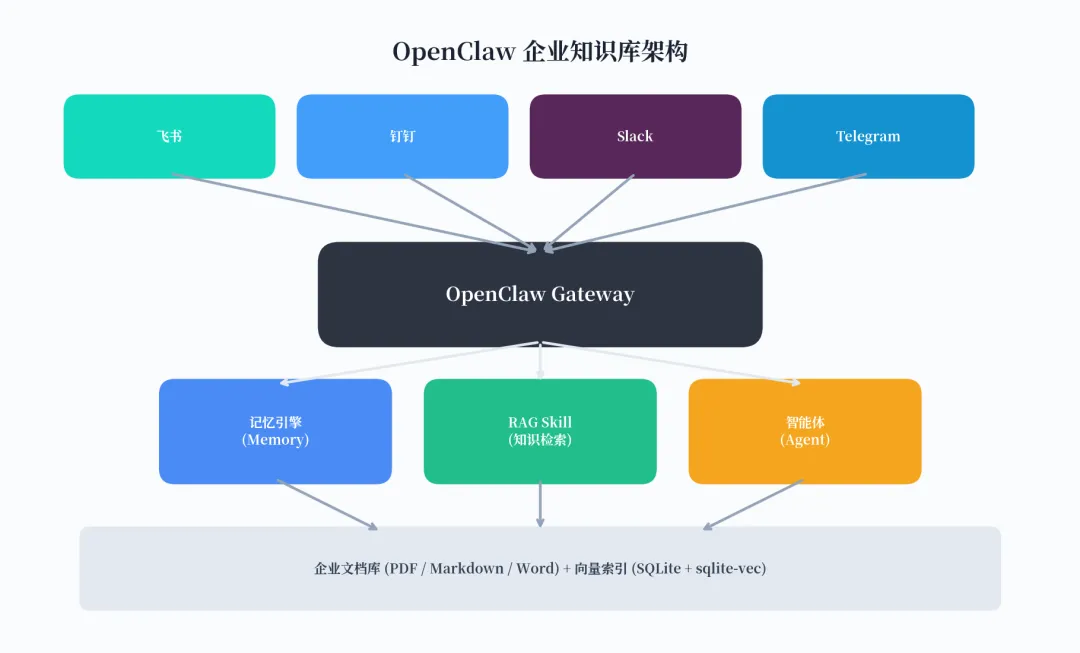
图 1:OpenClaw 企业知识库整体架构
工作原理很简单:企业文档被切分为约 400 个 token 的小片段,通过 Embedding 模型转化为向量后存入本地 SQLite 数据库。当用户提问时,系统同时进行关键词搜索(BM25)和向量搜索(余弦相似度),将最相关的文档片段注入 Prompt,再由大模型生成回答。这种混合搜索策略比单纯的向量搜索效果好很多,尤其是对中文场景,因为 OpenClaw 内置了 trigram 分词支持。
第一步:环境准备与安装
OpenClaw 运行在 Node.js 环境上,推荐使用 Node 24,最低要求 Node 22.16+。安装很简单:
# 一键安装(推荐)
npm install -g openclaw@latest
# 或者使用一键脚本
curl -fsSL https://openclaw.ai/install.sh | bash
安装完成后,运行交互式初始化向导:
openclaw onboard –install-daemon
向导会引导你配置模型提供商(推荐使用 Anthropic 或 OpenAI),并将 Gateway 注册为系统服务。完成后,Gateway 默认监听在 18789 端口,你可以通过浏览器访问 http://localhost:18789 打开内置的 Web Dashboard。
💡 如果你打算把知识库部署在云服务器上,知识库场景建议 2 核 4G 起步,文档量较大(数百篇以上)则建议 4 核 8G。
第二步:准备知识库数据
知识库的效果下限取决于你喂给 AI 的数据质量。OpenClaw 的内置记忆引擎主要索引 Markdown 文件,包括 MEMORY.md 和 memory/*.md。对于企业场景,你需要先把各种格式的文档转换为 Markdown。
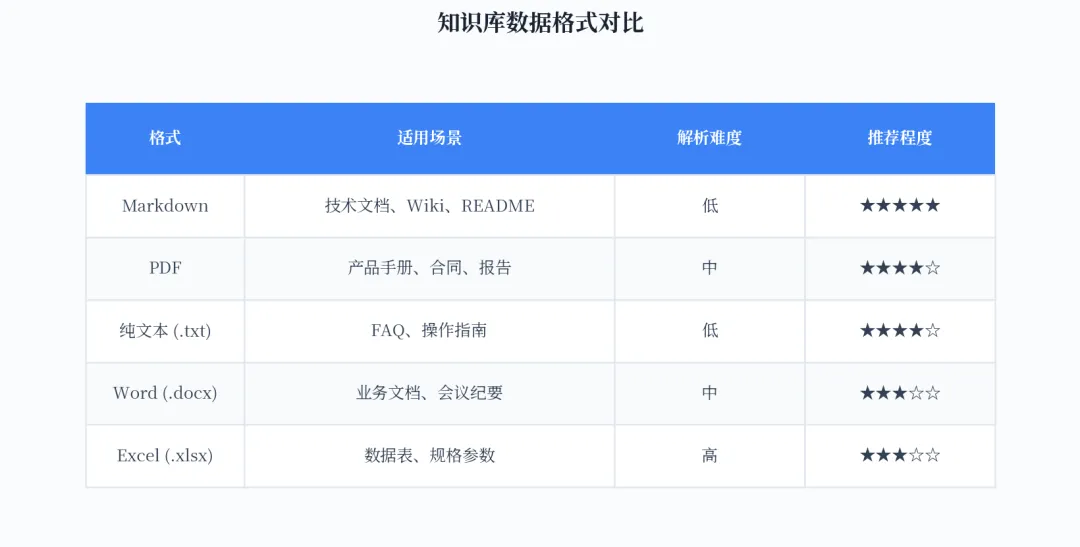
图 2:支持的数据格式与推荐程度
数据整理有几个实际建议:一是每份文档保持单一主题,避免一个文件包含太多不相关的内容;二是删除页眉页脚等无关内容,减少检索噪音;三是确保标题清晰,这直接影响检索的准确率。比如把《新员工入职流程》和《公司休假制度》分成两个文件,而不是合并成一个《人事制度汇总》。
将整理好的文档放入 OpenClaw 的工作区目录。默认路径是 ~/.openclaw/agents/main/workspace/memory/,你可以在其下创建子目录来分类管理:
~/.openclaw/agents/main/workspace/memory/
├── 产品手册/
│├── API接口文档.md
│└── 功能清单.md
├── HR/
│├── 新员入职流程.md
│└── 休假制度.md
└── 技术架构.md
OpenClaw 会监听这些文件的变化,并在 1.5 秒内自动触发重新索引。也可以手动强制重建:
openclaw memory index –force
第三步:配置记忆引擎与 Embedding
OpenClaw 的内置记忆引擎支持多种 Embedding 提供商,包括 OpenAI、Gemini、Voyage、Mistral、DeepInfra 等云端服务,也支持 Ollama 和本地 node-llama-cpp 运行时。如果你已经配置了这些提供商的 API Key,系统会自动检测并启用向量搜索,无需额外配置。
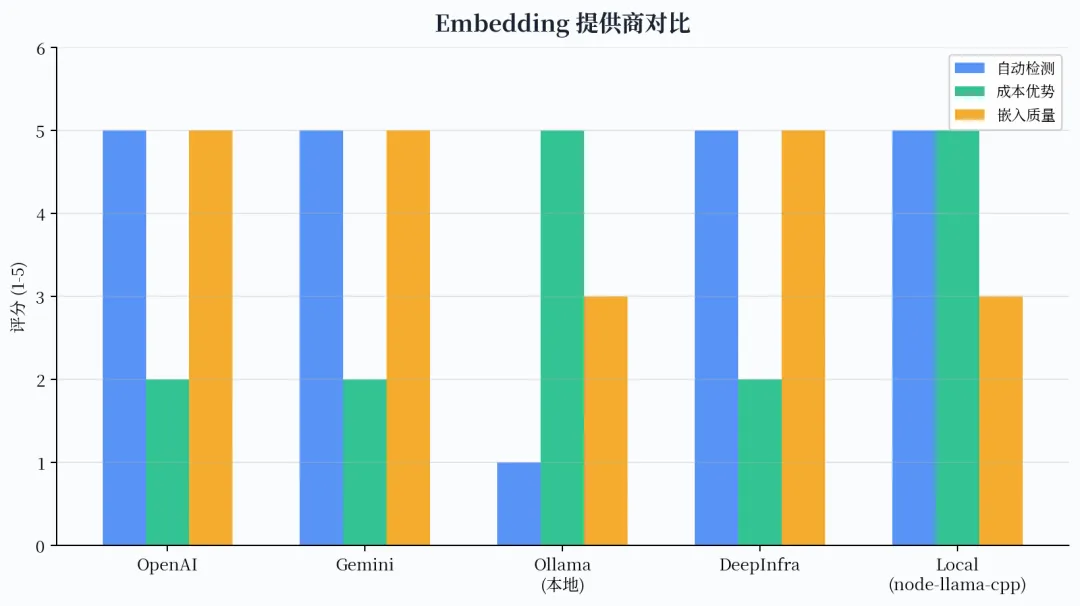
图 3:Embedding 提供商对比(评分越高越好)
如果你希望显式指定某个提供商,可以在 OpenClaw 的配置文件中设置。例如使用 OpenAI 作为 Embedding 提供商:
// 在 ~/.openclaw/config.json5 中添加
{
agents:{
defaults:{
memorySearch:{
provider:“openai”,
},
},
},
}
如果你希望完全本地化、不依赖任何云端 API,可以安装 node-llama-cpp 运行时包,然后下载一个轻量级的嵌入模型(如 embeddinggemma-300m)。这种方案的好处是数据完全不离开本地,但 Embedding 质量会比云端模型差一些。
💡 企业场景建议使用云端 Embedding(如 OpenAI text-embedding-3-small),质量稳定且不需要维护本地模型。成本很低,即使文档量很大也不会花太多钱。
第四步:安装 RAG Skill 并验证
OpenClaw 的知识库能力通过 Skills 系统扩展。最简单的方式是直接从 ClawdHub 安装现成的 knowledge-base 技能。你可以通过 Web Dashboard 的 Skills 市场搜索并一键安装,也可以自己写一个定制的 RAG Skill。
安装完成后,你可以通过向 OpenClaw 发送一段提示词来定义知识库的行为模式。例如,你可以这样告诉它:当我在知识库话题中提问时,先语义搜索内部文档,返回最相关的结果和来源引用;如果找不到好的匹配,直接告诉我不知道。
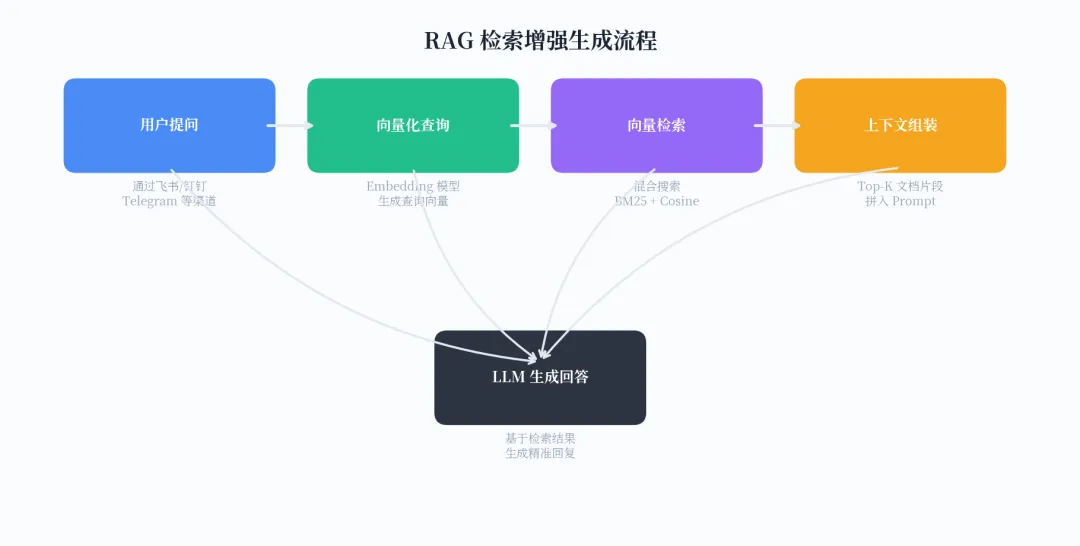
图 4:RAG 检索增强生成流程
实际测试时,建议准备 10 到 20 个你确定能在文档中找到答案的问题,逐一测试。主要关注三个维度:准确率(回答是否与文档内容一致)、引用能力(AI 是否能指出答案来源)、兆底能力(文档中没有的问题,AI 是否会说“不知道”而不是编造)。
常见的优化手段包括:答案不准确时检查文档格式、找不到相关文档时调低相似度阈值或增加 Top K、回答太泛泛时优化 Prompt 要求引用具体文档内容、响应太慢时减小 Chunk Size 或升级服务器配置。
第五步:接入企业聊天平台
这是 OpenClaw 相比其他知识库方案最大的亮点。一个 Gateway 网关可以同时服务飞书、钉钉、Telegram、Slack、Discord 等多个平台,所有渠道共享同一套知识库和记忆。用户在哪里问都一样。
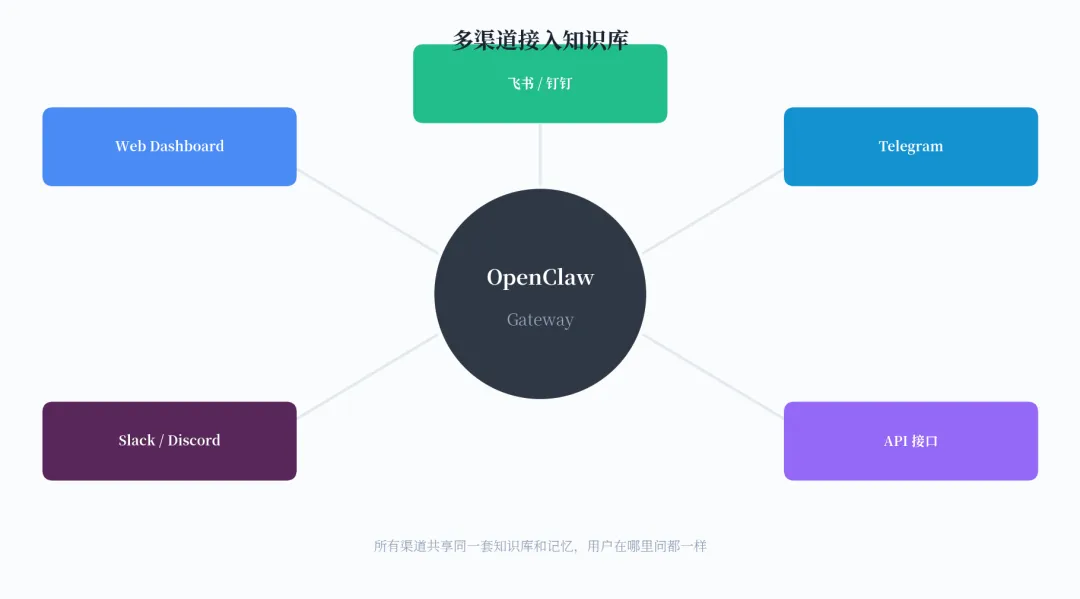
图 5:多渠道接入知识库
接入流程很简单。以飞书为例:在 OpenClaw 的配置中添加飞书插件,配置 App ID 和 App Secret,然后在飞书中创建一个专用的知识库话题或频道。当员工在这个话题中提问时,OpenClaw 会自动触发知识库检索,然后返回基于企业文档的精准回答。
如果你需要更精细的控制,OpenClaw 支持多智能体路由。你可以为不同部门配置不同的智能体和知识库范围,例如让技术部门的智能体只检索技术架构文档,HR 部门只检索人事制度。
安全与运维要点
企业场景下,数据安全是绕不过去的话题。OpenClaw 在这方面的优势很明显:数据完全存储在你自己的机器上,不会上传到第三方。但仍然需要注意几个要点:
插件安全:尽量只安装来源明确的插件,不要装不可信的第三方 Skill。OpenClaw 运行在宿主机操作系统层,拥有执行 Shell 命令和读写文件的权限,恶意插件可能造成严重后果。
及时升级:OpenClaw 更新很频繁,每次更新可能会修复安全漏洞。建议跟追 stable 版本,在测试环境验证后再更新。
权限隔离:利用多智能体路由功能,为不同部门配置不同的知识库访问范围。避免让所有人都能访问全部文档,尤其是包含合同、薪酬等敏感内容。
备份策略:OpenClaw 的所有数据存储在 ~/.openclaw/ 目录下。定期备份这个目录,即使服务器崩溃也能快速恢复。重启服务不会丢失数据。
写在最后
搭建企业知识库的门槛已经很低了。OpenClaw 提供了开箱即用的记忆引擎和混合搜索能力,加上完善的 Skills 生态和多渠道接入,让你可以在一个下午内把基础框架搭起来。
当然,知识库不是“一劳永逸”的。文档需要持续更新,检索参数需要根据实际使用反馈调优,Prompt 也需要配合业务场景反复调整。但整体来说,这套方案已经能解决大多数团队“有个能问答的 AI”这个初级需求。