 夜雨聆风
夜雨聆风





全网最全解读!给AI编程助手塞一份AGENTS.md,真的更有用吗?
这两年,越来越多团队和个人开发者开始给代码仓库配一份给 AI 看的说明书。
文件名可能叫 AGENTS.md,也可能叫 CLAUDE.md、copilot-instructions.md。写法也差不多:项目结构怎么走、测试命令怎么跑、代码风格有什么规矩、提交前别忘了做什么。
看起来很合理。人接手一个新项目都希望先看文档,AI 当然也一样。
但最近有篇论文,偏偏就拿这件事较了真。题目很直接:《Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?》。作者来自 ETH Zurich 和 LogicStar.ai,他们想回答的问题只有一个:
这些给 AI 编程助手准备的仓库级上下文文件,到底是真的有帮助,还是只是让人感觉“好像更专业了”?
答案有点扎心。
先说结论
这篇论文最值得记住的,不是某个复杂实验设置,而是两个很直白的发现:
-
• 很多情况下,加入上下文文件后,AI 编程助手的任务成功率反而下降了。 -
• 推理成本还会上升 20% 以上。
论文里测了多种 coding agent 和不同底层模型,结果整体方向很一致:给足一大段仓库说明,并没有稳定地帮 AI 把活干好,反而常常把事情搞复杂。
如果你最近刚好在认真写 AGENTS.md,看到这可能会有点不舒服。我第一反应也是:不应该啊,信息更多,怎么会更差?
这正是这篇论文有意思的地方。它不是在抬杠,而是真的去做了系统评估。

他们是怎么测的
作者把实验分成了两块。
第一块,用的是大家已经比较熟悉的 SWE-bench Lite。这是 AI 修 Bug、改代码时经常会用到的一类基准。作者没有直接照搬,而是给这些仓库额外配上了 LLM 生成的上下文文件,写法也尽量参考业界推荐的套路,比如加入项目概览、目录说明、测试与构建命令、编码规范等。
第二块更有意思。因为现实世界里,很多仓库本来就已经有人手写了这类文件,所以作者又自己整理出一个新的评测集合,叫 AGENTbench。这里面收集的是带有开发者真实提交上下文文件的仓库 issue,更接近日常开发里 AI 真会遇到的情况。
换句话说,这篇论文没有只盯着一种场景,而是同时看了:
-
• “如果上下文文件是 AI 现写的,会怎样?” -
• “如果上下文文件本来就是开发者手写并提交在仓库里的,会怎样?”
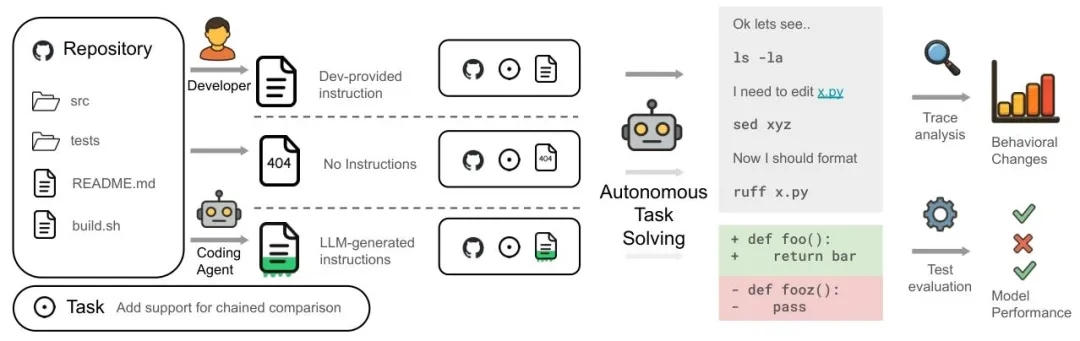
这个设计挺关键。因为很多人可能会说,问题不是出在 AGENTS.md 这类文件本身,而是出在“写得不好”。论文其实也考虑到了这一点。
最反直觉的一点:信息更多,不代表效果更好
论文里有个结果很值得普通读者也记一下。
在 SWE-bench Lite 上,加入 LLM 生成的上下文文件后,平均成功率大约下降 0.5 个百分点。这个数字看起来不算大,但方向是负的,而且跨模型、跨 agent 都比较一致。
到了作者自己整理的 AGENTbench 上,下降更明显,平均大约 2 个百分点。
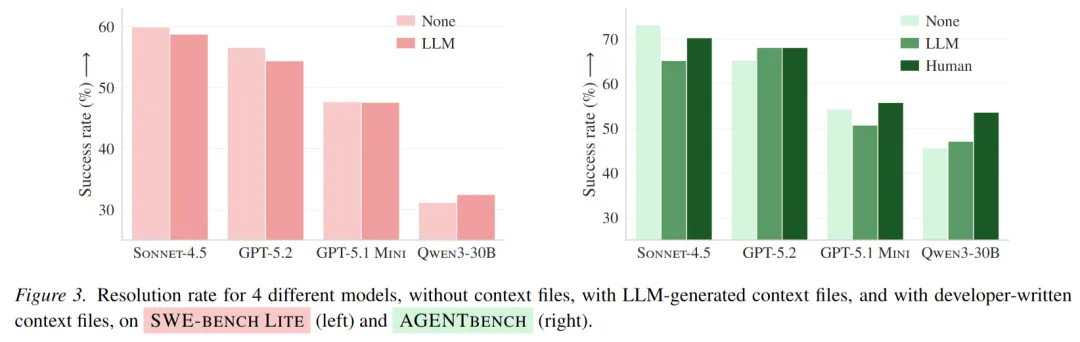
这说明什么?
说明对今天的 AI 编程助手来说,仓库级上下文文件并不天然等于“导航系统”。很多时候,它更像一份过长的任务前说明。看是看了,也会照着做,但不一定因此更接近正确答案。
更微妙的是,论文还发现这些文件确实改变了 agent 的行为。它们会让 agent:
-
• 跑更多测试 -
• 多看一些文件 -
• 做更广的仓库探索 -
• 更认真地遵守里面写下来的要求
表面上看,这些都像好事。
但问题也在这儿。更勤奋,不等于更有效。
有些任务本来只需要改一个点,结果 AI 因为被文档里的各种要求牵着走,花了更多时间在“应该全面检查”“应该先遍历目录”“应该执行更多流程”上,最后成本更高,成功率却没有更好。
这就像有人问你怎么修家里的水龙头,你先递给他一整本装修手册。对方当然会翻,但未必比直接告诉他“阀门在左边,先关水,再换这个垫圈”更有帮助。
为什么会这样
这部分我觉得是全文最有现实意义的地方。
过去大家默认的逻辑是:仓库文档越完整,AI 越容易把事情做好。
但论文给出的解释更接近另一种情况:
如果上下文文件里塞进了太多并非当前任务必需的信息,AI 会把这些要求也当成“必须认真执行的事”。
于是问题就出现了:
-
• 原本能直接定位的问题,被拉成了一次全仓巡检 -
• 原本只要跑一条命令,被扩展成整套检查流程 -
• 原本只需要局部修改,结果 AI 开始顾虑风格、结构、目录规范,甚至做额外重构
从人的角度看,我们会说这叫“抓不住重点”。
从 agent 的角度看,它其实不是不听话,反而是太听话了。论文里就提到,agent 往往会尊重这些上下文文件里的要求,只是这些要求未必真的能帮助它完成眼前这道题。
这也是为什么作者最后没有得出“以后别写 AGENTS.md”这种极端结论,而是更克制地说:
如果要写,人写的内容最好只保留最小必要信息。
比如:
-
• 这个仓库必须用什么测试命令 -
• 哪个工具链是必须的 -
• 哪些非直觉性的限制不能踩 -
• 哪些约定是 agent 仅靠读代码推不出来的
反过来,那些 AI 自己扫一遍目录就能知道的内容,未必值得在顶部再长篇大论重复一遍。
这和现在行业里的流行做法,刚好有点冲突
这篇论文之所以会引发讨论,还有一个背景。
过去一年里,不少 AI 编程工具和社区文章都在鼓励大家给仓库补充这类文件。官方文档和最佳实践里,也常能看到类似建议:把项目约定、常用命令、代码组织方式写给 agent 看。
这件事并不难理解。今天的 coding agent 已经不是只补一小段函数,而是在更长的任务链里读代码、改代码、跑测试、反复试错。大家自然会想:那就提前把“游戏规则”告诉它。
论文的价值就在这里。它提醒我们,“看起来合理”不等于“实验里真的有效”。
很多经验在个别仓库里也许成立,但一旦放到更广泛的任务上,效果可能没想象中稳。
普通开发者现在该怎么做
如果你会用 AI 写代码,我觉得这篇论文至少给了三个很实用的提醒。
1. 不要把 AGENTS.md 当成万能加成
它不是开关,不是加上去就能自动提高成功率。
尤其别抱着“我再补三页说明,AI 一定更懂项目”的想法。很多时候,AI 只会更忙。
2. 真要写,就写“少而硬”的信息
最值得留下的,不是项目介绍,不是漂亮的目录导览,而是那些不写它就很容易踩坑的东西。
比如:
-
• 单元测试其实要跑 just test,不是常见的pytest -
• 某个目录是生成产物,不能手改 -
• 提交前必须跑某条校验命令 -
• 这个仓库有特殊的数据库迁移顺序
这类信息对人有用,对 AI 也一样有用。
3. 能用工具约束的,就别全靠文档
如果一条规则真的重要,最好让它变成:
-
• lint -
• test -
• pre-commit hook -
• CI 检查
因为文档只能“提醒”,自动化约束才能“兜底”。
从论文结果看,单靠一份大而全的说明文件,希望 agent 自动理解并恰到好处地执行,风险还是挺高的。
我觉得这篇论文最有价值的地方
它没有否定文档,也没有否定 coding agent。
它真正戳破的是一种最近很常见的幻觉:只要把上下文喂得更大、更全,AI 就会更聪明。
现实往往没这么简单。
对今天的 agent 来说,太多上下文有时不是帮助,而是噪声;不是导航,而是额外负担。它会更认真地做事,却不一定更接近问题本身。
这也是我读完后最想转述给更多人的一句话:
AI 编程助手最需要的,可能不是“更多说明”,而是“更少但更关键的说明”。
这听上去很朴素,但在现在这个什么都想往 prompt 里加的阶段,反而挺值得记住。
参考资料
-
1. 论文原文:Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?https://arxiv.org/abs/2602.11988 -
2. AGENTS.md 官方站点https://agents.md/ -
3. Anthropic 关于 Claude Code memory / project instructions 的文档https://docs.anthropic.com/en/docs/claude-code/memory -
4. OpenAI 关于 Codex 的介绍https://openai.com/index/introducing-codex/ -
5. InfoQ 对论文的报道https://www.infoq.com/news/2026/03/agents-context-file-value-review/