 夜雨聆风
夜雨聆风





检索模型训练迎来“范式革命”:向AI搜索助手“拜师学艺”的时代已来
作者: Yuqi Zhou, Sunhao Dai, Changle Qu 等
机构: 中国人民大学高瓴人工智能学院,中国科学院计算技术研究所
引言:当检索的“用户”从人变成AI
想象一下这个场景:你向一个强大的AI研究助手提出一个复杂问题,比如“2023年诺贝尔化学奖得主在光合作用研究上的具体突破是什么?”。这个助手并不会直接给出答案,而是会像一个真正的研究员一样,思考、规划、然后行动。它可能会先搜索“2023诺贝尔化学奖”,浏览返回的摘要,发现与“量子点”有关;接着它会进一步搜索“量子点 光合作用 效率”,从结果中选择几篇文档浏览全文,提取关键信息;最后,它综合所有信息,生成一个结构清晰、证据详实的答案。
这,就是“搜索智能体”的典型工作模式。随着大语言模型的飞速发展,这类能够进行多步推理、主动调用搜索引擎(检索系统)来解决问题的AI助手正在成为信息获取的新入口。一个关键的转变正在发生:检索系统的主要“用户”正在从人类,悄然转变为AI智能体本身。
然而,当前的检索模型(无论是BM25、还是各种稠密向量检索模型)几乎都是在为人类服务的目标下训练出来的。它们的学习数据来源于人类的点击日志、停留时间等行为,隐含地假设了“人类用户会如何提问、如何浏览、如何判断相关性”。当使用这些模型的“用户”变成了行为模式迥异的AI智能体时,一个根本性的错配就产生了:训练目标和实际用途严重不符。
今天,来自中国人民大学和中国科学院的研究团队在论文《Learning to Retrieve from Agent Trajectories》中,正式提出了一个全新的检索训练范式:从智能体轨迹中学习检索。他们指出,既然检索模型是为智能体服务的,那就应该直接向智能体“拜师学艺”,从它们与检索系统交互产生的“轨迹”中学习。这篇论文不仅系统性地分析了智能体轨迹中蕴藏的丰富信号,更提出了一个简单而有效的框架 LRAT,成功地将这些信号转化为训练检索模型的“燃料”。
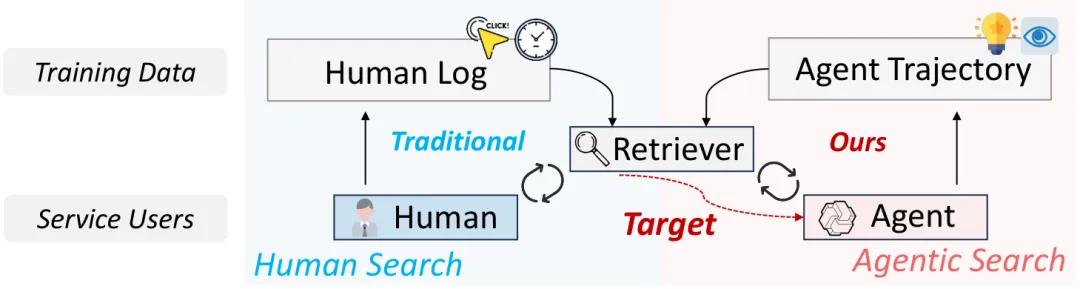 图1:检索范式的根本性转变。传统检索模型(左)从人类行为数据中学习,服务于人类用户;而智能体时代的检索模型(右)应从智能体自身的交互轨迹中学习,以更好地支持其多步推理和问题解决。
图1:检索范式的根本性转变。传统检索模型(左)从人类行为数据中学习,服务于人类用户;而智能体时代的检索模型(右)应从智能体自身的交互轨迹中学习,以更好地支持其多步推理和问题解决。
智能体轨迹:一座未被开采的“金矿”
首先,我们需要理解什么是“智能体轨迹”。在深度研究任务中,智能体遵循经典的“思考-行动”循环。给定一个初始问题,它会生成一系列步骤:
-
【思考】:分析当前状况,总结已有信息,明确下一步需要查找什么。 -
【行动】:执行一个动作,通常是 搜索(生成一个查询词,获取TOP-K个文档摘要)或 浏览(选择之前某个搜索结果中的一篇文档,请求阅读全文)。 -
【观察】:接收行动的结果(搜索返回的摘要列表,或浏览得到的文档全文)。 -
重复此过程,直到智能体认为信息足够,最终生成答案。
这个完整的执行序列,就是一条“智能体轨迹”。它忠实记录了智能体在解决问题过程中的每一次“心跳”:它问了什么、看到了什么、选择了什么、又基于此思考了什么。
论文团队收集并分析了由强大的开源研究智能体Tongyi-DeepResearch-30B在InfoSeekQA数据集上产生的超过3.4万条有效轨迹。通过对这些轨迹的深入挖掘,他们发现了几个颠覆传统认知、却对训练检索模型至关重要的关键信号。
发现一:浏览行为是任务成功的“必要条件”
智能体不是每次搜索都会浏览文档。数据分析显示,成功完成任务的轨迹(最终答案正确)与失败的轨迹(答案错误)在行为上有显著差异。
-
成功轨迹:搜索后更倾向于浏览文档,浏览与搜索的比值(B/S)较高。 -
失败轨迹:往往陷入“只搜索、不浏览”的循环,发出大量搜索但很少深入查看内容。
更关键的是,任务成功率与浏览过的证据文档数量呈强正相关,而从未浏览过任何文档的轨迹,成功率直接降为0。这说明,对于智能体而言,浏览不是可选项,而是完成任务的关键步骤。因此,被智能体浏览过的文档,天然就是潜在的“正面样本”候选。
 图2:轨迹分析。(a) 成功与失败轨迹中“搜索”到“浏览”的转换概率差异显著。(b) 任务成功率随浏览的证据文档数量增加而上升,零浏览则失败。
图2:轨迹分析。(a) 成功与失败轨迹中“搜索”到“浏览”的转换概率差异显著。(b) 任务成功率随浏览的证据文档数量增加而上升,零浏览则失败。
发现二:“未被浏览”的文档是可靠的“负面样本”
在传统基于人类点击的训练中,一个巨大的难题是“位置偏差”:用户没点击一篇文档,可能不是因为不相关,而是因为它排得太靠后根本没被看到。因此,如何从未点击中筛选出真正的负样本非常棘手。
然而,在智能体轨迹中,情况截然不同。分析发现,智能体的浏览行为对排名位置不敏感。它们会公平地审视结果列表中的各个位置,而不是只盯着最前面的几个。这意味着,在一次搜索返回的TOP-K结果中,如果智能体浏览了其中一篇,而“跳过”了其他篇,那么这些被跳过的文档很有可能是智能体经过审视后主动拒绝的,而不是“没看到”。因此,所有未被浏览的文档,都可以相对安全地视为高质量的负样本,无需复杂的去偏处理。
发现三:浏览后的“思考”是相关性强度的“指示器”
浏览行为本身是一个二值信号(看/没看),但文档的价值显然有高低之分。幸运的是,智能体在浏览文档后立即生成的“思考”文本,提供了更细腻的信号。
论文发现,浏览后产生的“思考”文本的长度,与文档的价值高度相关。
-
浏览了关键证据文档后,智能体往往会进行更长的推理,试图整合新信息。 -
浏览了无关或低价值文档后,思考通常会很短,比如“这篇没用,继续找”。 -
整体上,最终成功的轨迹,其平均“后浏览思考”长度远高于失败的轨迹。
这就像人类的“停留时间”,越长通常意味着文档越相关、越有用。因此,“后浏览思考”的长度,可以作为衡量文档相关性强度的天然指标。
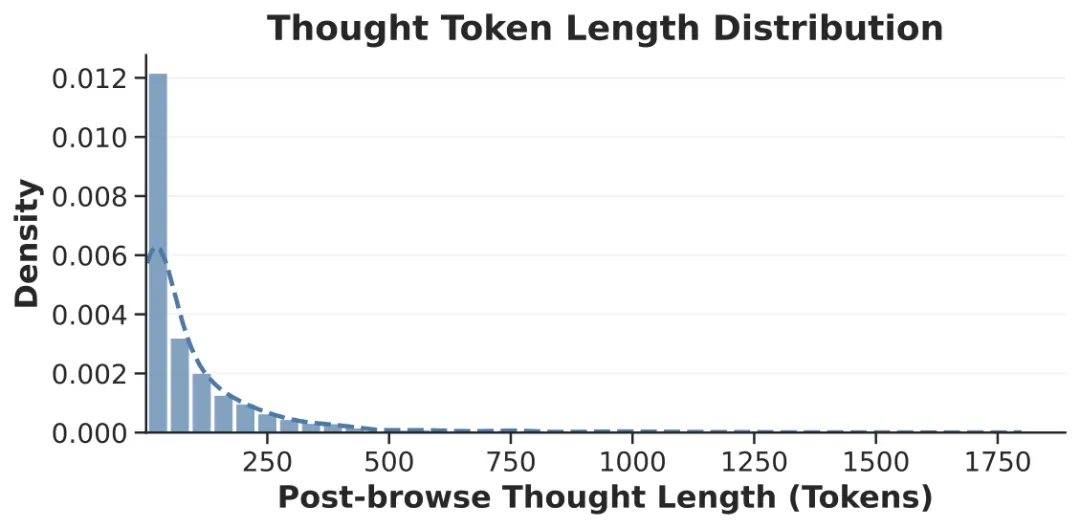 图3:浏览文档后,智能体“思考”文本的令牌长度分布。更长的思考往往意味着文档引发了更深度的信息处理和整合。
图3:浏览文档后,智能体“思考”文本的令牌长度分布。更长的思考往往意味着文档引发了更深度的信息处理和整合。
LRAT框架:将轨迹“炼”成检索模型
基于以上三大发现,研究团队提出了 LRAT 框架。它的核心思想是:从智能体轨迹中自动化地挖掘高质量、带权重的训练数据,用来微调检索模型。整个过程如同一个精炼厂,将原始的交互“矿石”提炼成监督学习的“燃油”。
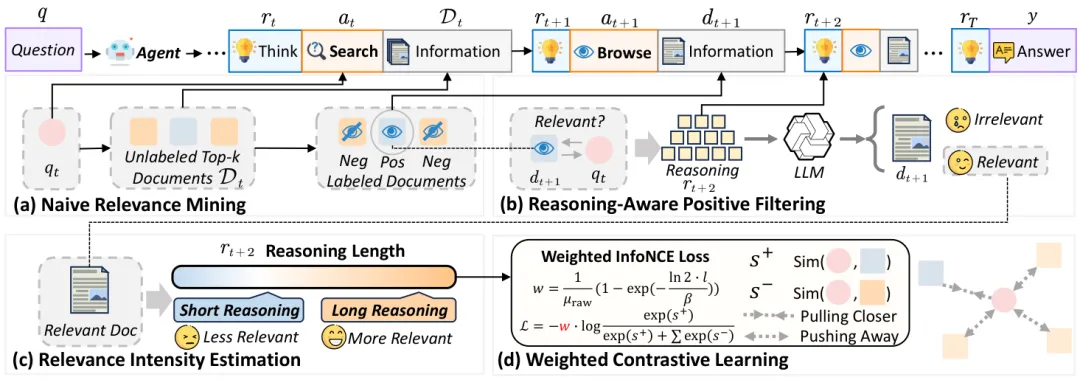 图4:LRAT框架示意图。从轨迹中挖掘信号、过滤噪声、估计权重,最终用于对比学习训练。
图4:LRAT框架示意图。从轨迹中挖掘信号、过滤噪声、估计权重,最终用于对比学习训练。
第一步:从“搜索-浏览”转换中挖掘初始信号
这是最基础的监督信号来源。每当智能体执行了一次【搜索】行动,紧接着又执行了一次【浏览】行动时,我们就构建一个训练样本:
-
查询:搜索时生成的查询词。 -
正面文档:被浏览的那篇文档。 -
负面文档:同一次搜索返回的、但未被浏览的所有其他文档。
这一步直接利用了发现一和发现二。
第二步:用“后浏览思考”过滤噪声
并非所有被浏览的文档都有用。智能体可能看走眼,浏览后发现文档无用。这时,发现三就派上用场了。
LRAT引入一个 “LLM法官”(例如Qwen3-30B),让它阅读浏览后的思考文本,判断“智能体是否明确表示从该文档中获得了有用信息”。如果判断为“无关”,则将该正面样本剔除。实验证明,这个简单的过滤能保留97.2%的真正证据文档,同时过滤掉一部分明显的噪声,大幅提升了正样本的质量。
第三步:用思考长度估计“相关性强度”
不同的有用文档,价值也不同。LRAT创新性地将“后浏览思考长度”转化为一个连续的相关性权重。
受启发于用户行为分析中的“时间感知点击模型”,研究者设计了一个基于指数饱和函数的权重计算公式:
其中 是思考长度, 是一个尺度参数(设置为数据集中思考长度的中位数)。这个公式的直观意义是:思考长度的增加带来的边际效用递减,最终权重会趋于饱和。这样,引发了深度思考的文档会获得更高的训练权重。
第四步:加权对比学习
最后,使用标准的双编码器架构(如Qwen-Embedding)进行训练。但损失函数不是普通的InfoNCE损失,而是加权InfoNCE损失。每个正样本的损失项会乘以上一步计算出的权重 。这样,模型会更多地关注那些对智能体推理过程贡献更大的文档对。
实验结果:全面且一致的提升
论文在InfoSeek-Eval(域内)和BrowseComp-Plus(域外)两个深度研究基准上,对LRAT进行了全面评估。他们测试了多种检索模型(Qwen3-Embedding, E5-Large)和多种智能体(从4B的AgentCPM到358B的GLM-4.7),结果令人振奋。
核心发现:三赢局面
-
检索质量更高:LRAT训练的检索器,在 BrowseComp-Plus上的证据召回率显著提升(最高提升近38%)。这意味着它能更精准地找到智能体真正需要的证据文档。 -
任务成功率更高:配备LRAT检索器的智能体,在两个基准上的任务成功率全面超越基线,提升幅度从5%到38%不等。即使对于GLM-4.7这样的千亿级巨模型,检索器优化依然能带来超过20%的成功率提升,说明检索质量是智能体性能的关键瓶颈。 -
执行效率更高:智能体完成任务所需的平均步数显著减少(在InfoSeek-Eval上最多减少约30%)。这表明LRAT检索器返回的结果更“好用”,智能体能用更少的“弯路”找到答案。
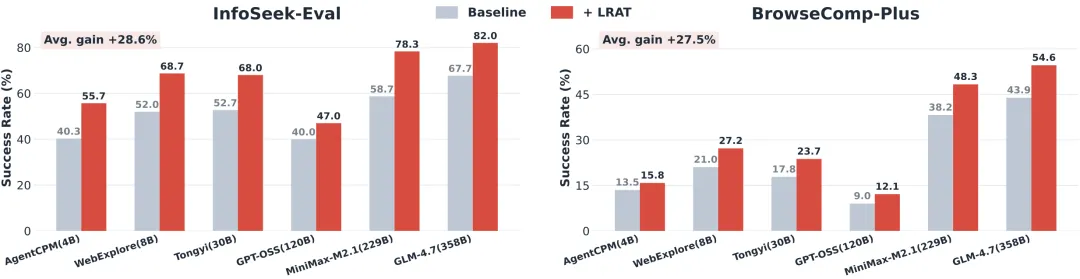 图5:LRAT带来的性能增益概览。在六个不同的智能体骨架上,LRAT均能同时提升域内任务成功率(左)和域外证据召回率(右)。
图5:LRAT带来的性能增益概览。在六个不同的智能体骨架上,LRAT均能同时提升域内任务成功率(左)和域外证据召回率(右)。
消融实验:每一个设计都至关重要
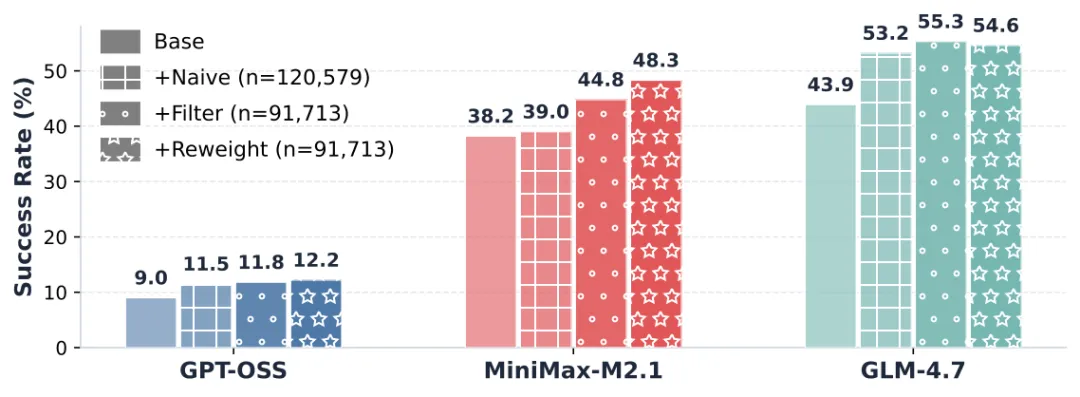 图6:LRAT各组件消融实验。逐步加入“基础信号”、“思考过滤”和“权重估计”,性能持续提升。
图6:LRAT各组件消融实验。逐步加入“基础信号”、“思考过滤”和“权重估计”,性能持续提升。
研究团队通过消融实验验证了LRAT每个组件的必要性:
-
仅使用基础信号(+Naive):已有显著提升,证明了从轨迹中挖掘监督信号的可行性。 -
加入思考过滤(+Filter):性能进一步提升,说明过滤掉“浏览但无用”的噪声文档是关键。 -
加入权重估计(+Reweight):达到最佳性能,证明了区分文档价值强度的重要性。
扩展性与数据飞轮:通向现实的桥梁
为了验证LRAT的实用性,论文还探讨了两个关键问题:
1. 规模扩展性:随着训练轨迹数据量的增加,LRAT的性能能否持续提升?答案是肯定的。如图7a所示,使用更多轨迹数据训练,智能体的成功率持续增长,没有出现平台期。
2. 数据飞轮:这是最具吸引力的远景。在真实世界中,智能体和检索器可以形成一个自我强化的闭环:
1. 当前检索器服务智能体,产生大量轨迹。
2. 用这些轨迹训练出更好的新检索器。
3. 新检索器上线,服务智能体产生质量更高的新轨迹。
4. 重复此过程,实现持续进化。
论文通过模拟实验证实了这个飞轮是可行的。即使使用包含失败任务的轨迹,也能有效提升检索器。在模拟的多轮迭代中,智能体成功率和检索召回率均实现了稳定、持续的提升。
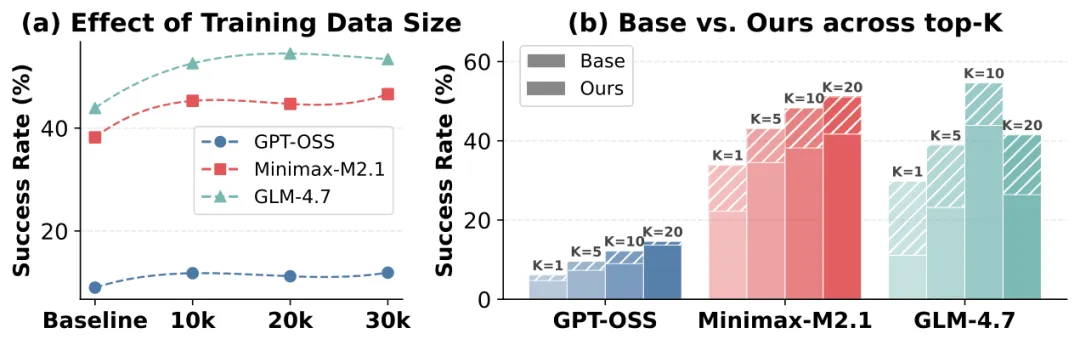 图7:(a) 训练数据量增加,性能持续提升。(b) 在不同检索返回数量(Top-K)下,LRAT检索器均优于基线。
图7:(a) 训练数据量增加,性能持续提升。(b) 在不同检索返回数量(Top-K)下,LRAT检索器均优于基线。
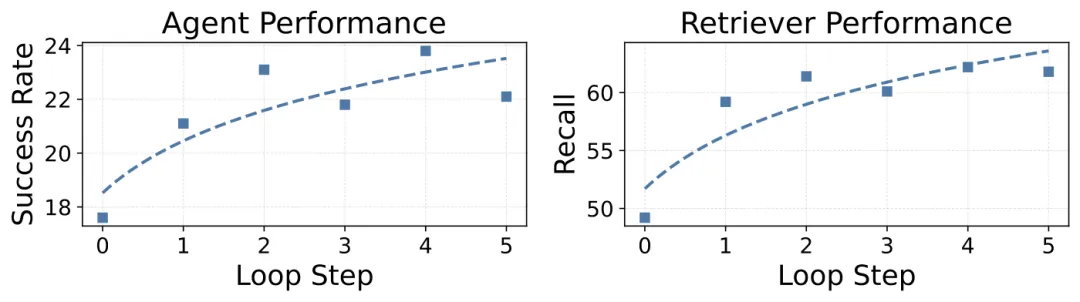 图8:数据飞轮模拟实验显示,经过多轮迭代,任务成功率和证据召回率均稳步上升。
图8:数据飞轮模拟实验显示,经过多轮迭代,任务成功率和证据召回率均稳步上升。
结论与展望
这篇论文的工作具有里程碑式的意义。它清晰地指出了一个被忽视的根本性问题:在AI智能体时代,检索模型的训练范式需要变革。并率先系统地论证了智能体交互轨迹作为新型监督数据的巨大价值。
LRAT框架的成功,揭示了一条清晰且可扩展的技术路径:
-
数据来源:智能体执行任务时天然产生,成本极低。 -
信号质量:蕴含浏览、拒绝、深度思考等多种高质量信号。 -
效果:能显著提升检索质量、智能体任务性能和执行效率。 -
前景:能支撑起一个可持续进化的“数据飞轮”。
这项工作为“面向智能体的检索系统”研究打开了新的大门。未来,如何设计更高效的轨迹信号挖掘算法,如何让检索器与智能体进行更紧密的协同优化,甚至如何为不同性格、不同任务的智能体定制专属检索器,都将成为充满潜力的研究方向。
检索模型,终于开始学习如何更好地为它的新“主人”——AI搜索助手——服务了。一个从AI行为中学习、与AI共同进化的检索新时代,正在开启。
本文由AI论文热榜基于论文《Learning to Retrieve from Agent Trajectories》编译解读。论文代码、模型及主页已开源:
-
GitHub: https://github.com/Yuqi-Zhou/LRAT -
Homepage: https://yuqi-zhou.github.io/LRAT-homepage/
关注「AI论文热榜」,紧跟最前沿、最硬核的AI技术进展!
如有论文辅导、项目开发等需求,请联系小编,微信号: GCgcong