代表人物:萨姆·奥特曼(Sam Altman),OpenAI的CEO。他在做什么:奥特曼虽在2026年3月关停了Sora等视频生成项目,理由是集中算力和产品能力全力投入下一代核心AI模型,但他从未放弃”规模出奇迹”的信念。他目前的核心理念常被概括为Scaling Law 2.0:即通过o1/o2系列模型实现”推理时计算(Inference Scaling)”,让模型在推理阶段分配更多计算资源进行内部推演。对幻觉的看法:o1系列的设计思路是通过更长的内部推理链来减少逻辑矛盾错误。其隐含假设是,相当一部分幻觉源于模型“想得太快”而非“知识不够”。
路线二:世界模型:给AI 换个“脑子”
代表人物:杨立昆(Yann LeCun),图灵奖得主。2025 年 11 月他离开 Meta,创办了 AMI Labs,押注“世界模型”。他在做什么:杨立昆认为当前的LLM(大语言模型)是通往 AGI 的“死胡同”。他的判断很直接:LLM 只懂“词语的统计概率”,不懂“现实的因果逻辑”。所以他要造一个全新的架构——让 AI 通过海量视频和感知数据学习物理世界的规律(如重力、因果)。目前还在实验室阶段,没有成熟产品。对幻觉的看法:世界模型能解决“违背常识”的幻觉(比如 AI 不再认为石头能浮在水上)。但在法律人最关心的具体事实记忆(如某条法律的生效日期)上,世界模型无法直接提供答案——因为它不追求存储海量事实,只追求理解物理逻辑。
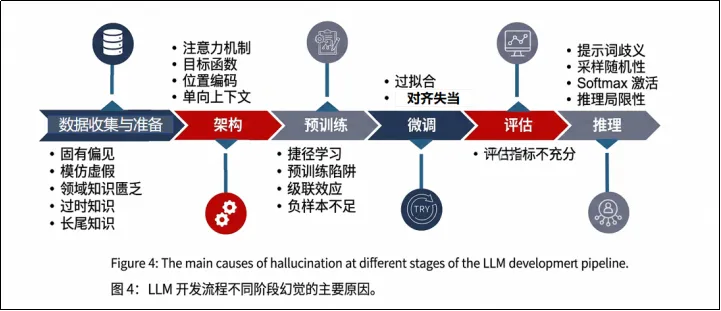
我们在上一篇推文说大白话:什么是“AI 幻觉”?中提到过AI幻觉的“底层病理(引擎机制):幻觉根源于概率计算。模型是基于概率预测,其本质是最大化“统计合理性”,而非“逻辑真实性”。这是根因。通过查找资料,我发现在工程实现上,AI幻觉的产生还有各种诱因。感兴趣的读者可以查看这篇论文《A Comprehensive Survey of Hallucination in Large Language Models: Causes, Detection, and Mitigation》,这篇论文将LLM开发流程分为六个不同阶段:数据收集与准备、模型架构、预训练、微调、评估和推理,每个阶段的工程实现都有可能导致幻觉的产生,这些因素是诱发AI幻觉的“工程变量”。
 夜雨聆风
夜雨聆风