 夜雨聆风
夜雨聆风





中美AI差距仅剩2.7%:2026国产AI实现三大原创突破
4月19日,斯坦福大学《2026年人工智能指数报告》正式发布,一个震撼全球的数据浮出水面:中美AI模型性能差距已缩小至2.7%。这意味着,在人工智能这一决定未来国运的核心赛道上,中国已从”追跑”走向”并跑”,甚至在某些领域实现了”领跑”。
更令人振奋的是,这份423页的权威报告揭示了2026年中国AI的三大原创性突破:MiniMax M2.7的自我进化框架、世界模型的物理世界认知能力突破、以及多智能体协同的规模化落地。这些都不是简单的性能提升,而是改变AI发展底层逻辑的范式创新。
一、2.7%差距背后:从”跟跑”到”双雄并峙”的历史性跨越
关键数据:截至2026年3月,美国顶尖模型Claude Opus 4.6的Elo评分为1503分,中国顶尖模型Dola-Seed 2.0 Preview得分1464分,差距仅39分,折合2.7%。
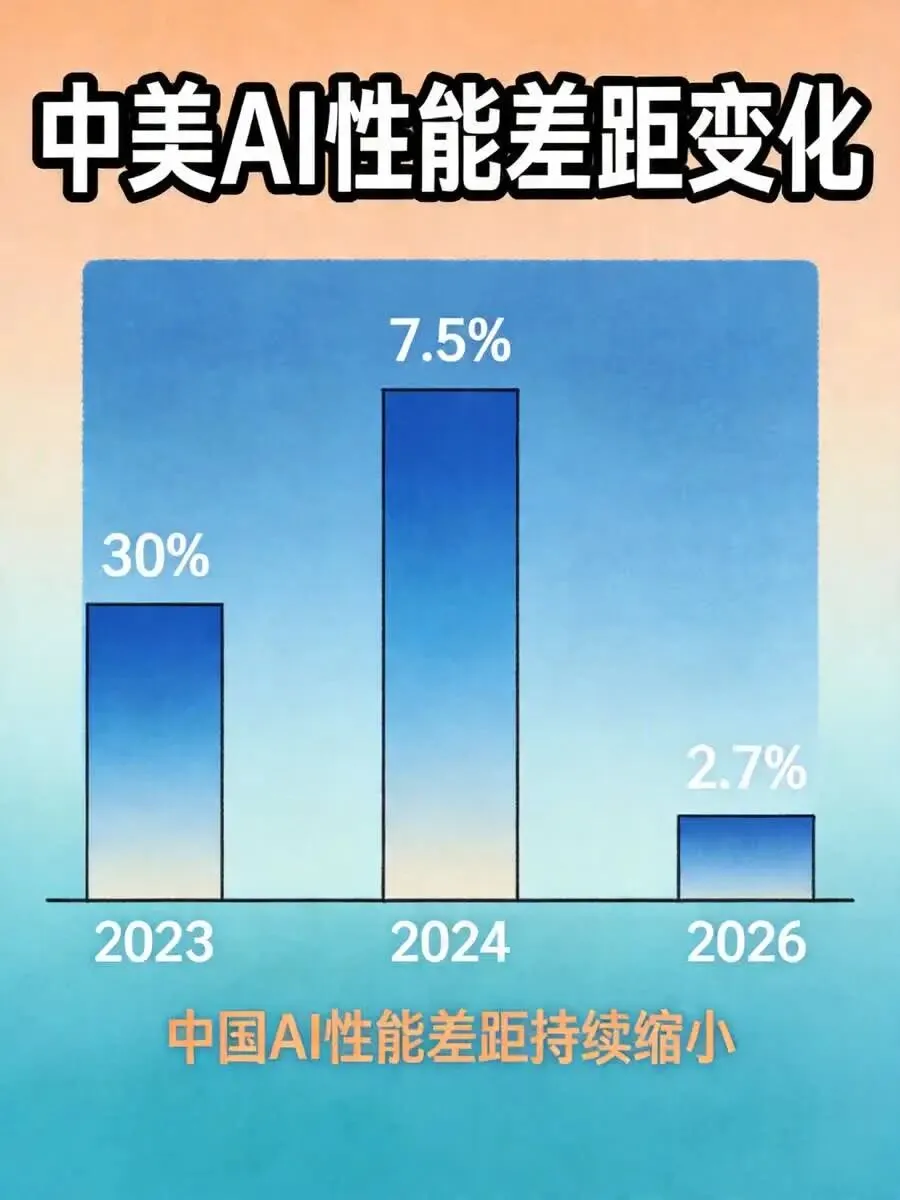
这组数据背后,是中国AI全方位的实力跃升。2023年,美国顶级模型在MMLU、MATH、HumanEval等核心基准测试中,领先中国模型17.5至31.6个百分点;2024年底,差距迅速缩小至0.3至3.7个百分点;2026年,在全球权威Arena排行榜上,中美模型反复换位、轮流领跑。
产业规模:应用落地全面领跑
中国AI在产业应用领域展现出压倒性优势。2026年3月,中国大模型周调用量达4.69万亿Token,同比增长320%,连续两周超过美国的4.21万亿。字节豆包月活用户突破3.15亿,阿里千问MAU达2.03亿,增速552%,全球第一。
中国AI产业规模达5万亿元,增速65%,远超美国的40%。在开源生态上,中国开发者数量、模型数量、社区活跃度全球领先。
为什么差距能缩小这么快?
中国AI的发展路径偏向”应用驱动+迭代优化”,依托海量场景快速迭代技术,注重成本控制、落地实效。阿里、字节、DeepSeek等企业,均是”技术落地”的典范,模型性能不断逼近美国,同时成本更低、适配性更强、迭代更快。
二、突破一:MiniMax M2.7——全球首个自我进化AI,越用越智能
核心突破:2026年4月12日,MiniMax正式开源M2.7 Agent旗舰大模型,这是全球首个实现模型深度参与自身迭代、完成自我进化的通用AI基座,不是概念演示,而是已落地验证的量产技术。
传统AI的核心瓶颈:越用越”固化”,迭代全靠人力
过去所有主流大模型,不管是GPT、Gemini还是国产早期版本,本质都是被动工具:上线时参数、能力、知识库全部固定,要升级必须靠人类工程师重新标注海量数据、反复调参、全量重训,周期动辄数周数月,成本极高。用户用得越多,模型反而越显”笨”——记不住历史偏好、不会优化重复任务、换场景就要重新适配,没法积累经验、自主成长。
M2.7的核心突破:Agent Harness,让AI自己进化自己
MiniMax M2.7的核心,是自研Agent Harness智能体执行框架,把模型从”执行工具”变成”研发参与者”,打通从问题分析、方案设计、代码修改、评测验证到迭代优化的完整闭环。
它的自我进化流程,完全自主、无需人工全程干预:
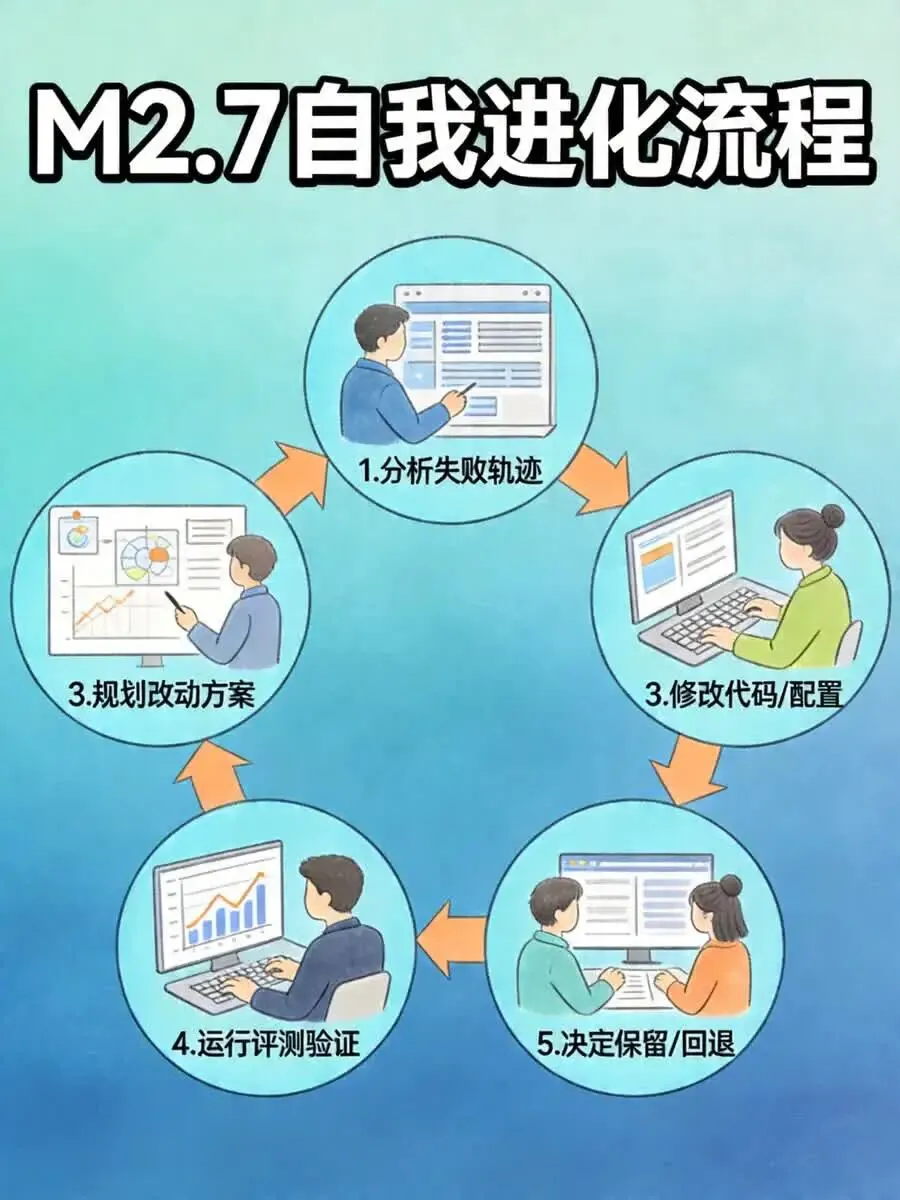
1. 分析失败轨迹:自动定位任务卡点、逻辑漏洞、性能瓶颈
2. 规划改动方案:自主设计优化路径、调整参数、补充技能
3. 修改代码/配置:直接完成训练脚本、推理逻辑、记忆模块的更新
4. 运行评测验证:自动跑基准测试、对比新旧版本效果
5. 决定保留/回退:基于结果判断是否保留优化,形成可复用经验
真实能力验证:不是噱头,是可落地的生产力
官方实测:M2.7在内部研发场景中,可自主完成100+轮迭代循环,承担30%-50%的研发工作量,最终在内部评测集实现约30%的效果提升。简单说:传统AI是”一次性出厂”,M2.7是”越用越聪明”——你用它处理办公、编程、数据分析越多,它越懂你的习惯、优化你的流程、效率持续提升,不是短期翻倍,而是长期持续增长。
行业意义:国产AI从”追平”到”开辟新赛道”
过去几年,国产大模型多在性能、参数、多模态上追赶国际头部;M2.7的自我进化,是全球首次在模型迭代范式上的原创突破,不是简单的性能提升,而是改变AI发展的底层逻辑。
它解决三个核心痛点:
1. 降本:减少30%-50%的模型研发人力,企业与开发者不用再投入大量资源做重复调参
2. 提效:迭代周期从天/周级,降到小时/分钟级,100+轮自主迭代一天内完成
3. 长效:模型能力随使用持续增长,不是一次性产品,而是长期进化的智能系统
三、突破二:世界模型——从”被动响应”到”深度认知”
世界模型是2026年AI圈的核心技术热点,其核心逻辑是让AI摆脱”被动响应”,学会”主动理解”物理世界的时空连续性、因果逻辑与物理规则,实现从”感知”到”深度认知”的跃迁,成为连接虚拟与现实的核心桥梁。
三大核心能力突破
1. 时空因果推理能力:能够模拟物理世界的物体运动、交互反馈,预判行为后果,例如通过视频片段预测物体后续运动轨迹,通过场景描述预判事件发展走向,反事实推理准确率较2025年提升60%以上。
2. 超长上下文与实时检索融合:支持百万级甚至千万级Tokens的长上下文理解,结合新一代RAG(检索增强生成)技术,实现海量私域数据、实时网络数据的毫秒级调用与融合。
3. 多模态原生认知:无需额外适配,即可实现文本、图像、音频、视频、传感器数据的统一理解,能够将物理世界的”场景信息”转化为”可决策的数字信号”。

技术突破方面,2026年世界模型实现两大关键进展:一是突破”因果推理瓶颈”,通过引入”时空注意力机制””物理规则嵌入”,使AI能够理解”为什么”,而非单纯”是什么”;二是降低训练成本,通过模型稀疏化、算力优化,世界模型训练成本较2025年下降80%,从”实验室技术”走向”产业可落地”。
四、突破三:多智能体协同——从”单打独斗”到”团队协作”
2026年,AI Agent(智能体)已从”单一任务应答”升级为”多任务协同执行”,MCP(多智能体通信协议)、A2A(Agent-to-Agent)等通信协议实现标准化,不同功能、不同领域的AI智能体可实现专业化分工、动态协同与跨模型协作,突破单一模型的能力上限。
根据Gartner最新数据,2026年全球40%的企业应用将嵌入任务型AI智能体,而2025年这一比例不足5%。
国内方面,阿里千问App搭载400+办事能力智能体,从”交互助手”升级为”执行助手”,可自动完成政务办理、生活缴费、工作协同等任务,累计服务用户超10亿人次;吉利星睿智能体平台覆盖80%研发场景,通过多智能体协同,将汽车研发周期缩短20%、运营成本降低15%。
五、双雄并峙:中美AI的优势差异与未来格局
尽管中国AI已实现全面反超、差距仅剩2.7%,但中美AI的竞争并非简单的”谁强谁弱”,而是呈现”各有优势、互补共生”的格局。斯坦福报告清晰指出,两国在AI发展路径、核心优势上存在明显差异,这种差异将决定未来全球AI的竞争走向。
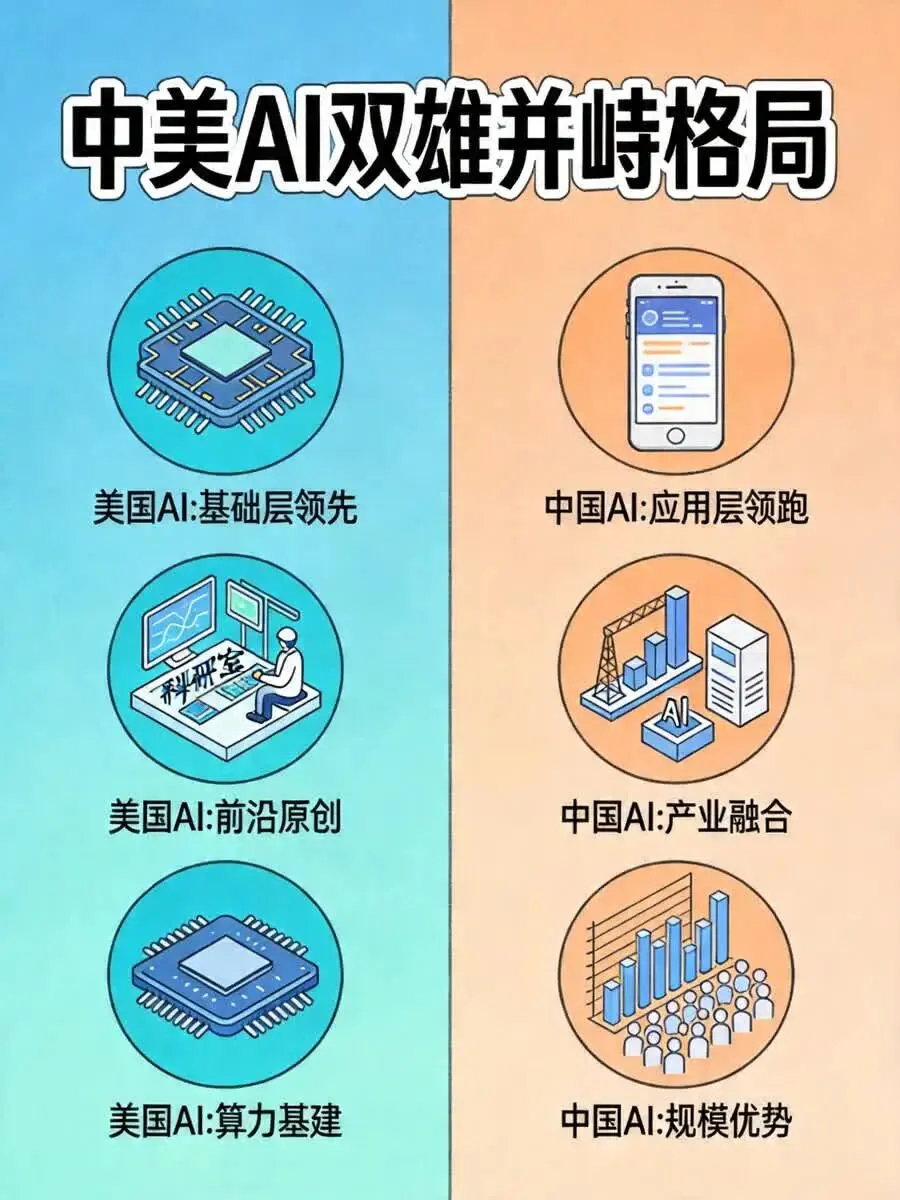
美国AI:基础层领先,聚焦前沿原创
美国的核心优势集中在基础层与前沿创新。在芯片领域,英伟达、AMD垄断全球高端GPU市场,市占率超95%;在算力基础设施上,美国拥有5427个数据中心,是其他国家总和的10倍以上;在基础科研上,美国汇聚全球50%以上顶尖AI科学家,在AGI(通用人工智能)、底层算法、理论创新上持续领跑;在资本投入上,2025年美国私人AI投资达2859亿美元,是中国的23倍以上。
中国AI:应用层领跑,注重落地实效
中国的核心优势集中在应用层与产业融合。在模型性能上,顶级模型与美国差距仅2.7%,中低端模型全面超越;在产业规模上,AI与制造业、服务业、农业深度融合,应用渗透率全球第一;在市场规模上,中国AI产业规模达5万亿元,增速65%,远超美国的40%;在开源生态上,开发者数量、模型数量、社区活跃度全球领先。
总结:2026中国AI从”追平”到”并跑”的历史性跨越
斯坦福2026 AI指数报告的发布,标志着中国AI在2026年实现了从”跟跑”到”并跑”的历史性跨越。2.7%的差距既是压力,也是动力。当前的领先是应用层、规模性的领先,而非基础层、原创性的全面领先。要实现真正的”全面领跑”,还需在高端芯片、基础理论、顶尖人才上持续突破,构建”基础层+技术层+应用层”全链条优势。
MiniMax M2.7的自我进化、世界模型的深度认知、多智能体协同的规模化落地,这三大原创性突破,标志着中国AI从”参数内卷”走向”范式创新”,从”跟随模仿”走向”原创引领”。未来3-5年,中美AI将维持”双雄并峙、交替领跑”的格局。2.7%的差距极其微小,任何一方的技术突破都可能实现反超。
2026年,科技不再遥远,它正在重塑每一个行业、每一份工作、每一种生活。