 夜雨聆风
夜雨聆风





这个开源 AI 网关,速度比 LiteLLM 快 50 倍
接入一个大模型并不难。

一个 API Key、一个模型名、几行 SDK 调用代码,一个 AI 功能很快就能跑起来。
真正麻烦的是系统增长之后。
一开始只有一个模型提供商,后来要接 OpenAI、Anthropic、Gemini、Azure OpenAI、Bedrock、本地 vLLM。不同任务需要不同模型,失败时需要备用方案,团队要看 token 和成本,安全部门要审计日志,平台团队要统一限流、预算和权限控制。
这时候,模型调用就不再是一个简单的 API 集成问题,而是一个平台基础设施问题。
Bifrost 正适合放在这个位置。
Bifrost 是一个开源高性能 AI Gateway,通过一个兼容 OpenAI 的 API 连接 20 多个模型提供商。它不仅负责转发请求,还把路由、故障转移、语义缓存、虚拟密钥、可观测性和治理能力集中到了网关层。
简单说,Bifrost 让应用只需要面对一个稳定入口,而不需要把复杂的模型供应商逻辑写进每个业务服务里。
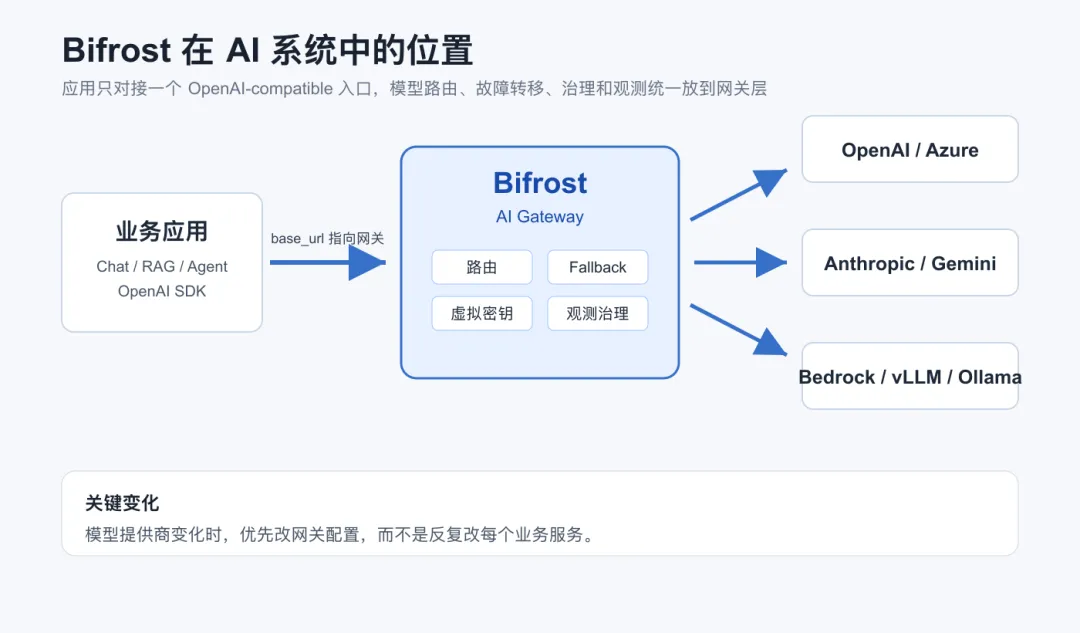
Bifrost 到底解决什么问题?
Bifrost 位于应用程序和模型提供商之间。
你的应用只调用 Bifrost,Bifrost 再负责把请求转发到 OpenAI、Anthropic、Gemini、Azure OpenAI、Bedrock、Groq、Ollama、vLLM 等模型提供商。
这样做的价值在于,很多原本分散在业务代码里的逻辑可以统一放到网关层。
比如:
-
• 某个模型失败后自动切换备用模型; -
• 不同任务路由到不同 provider; -
• 多个 API Key 之间做负载均衡; -
• 按团队、项目、用户控制模型访问权限; -
• 统计 token、成本、延迟和错误率; -
• 对高成本模型设置预算和限流; -
• 对重复问题使用语义缓存降低成本; -
• 统一输出 Prometheus 指标和 OpenTelemetry trace。
如果没有这样的网关,每个业务系统都可能自己写一套模型路由、重试、fallback、日志和成本统计逻辑。短期能跑,长期会越来越难维护。
Bifrost 的价值就是把这些控制能力集中起来,让模型访问从“散落的 API 调用”变成“统一的平台能力”。
为什么 AI Gateway 会越来越重要?
很多团队一开始并不会主动设计 AI Gateway。
因为早期目标很简单:先把功能做出来。
第一个版本可能只是一个聊天助手,一个模型,一个 API Key。这个阶段直接调用模型 API 是最快的方式,也没有必要引入额外架构。
但只要 AI 功能开始进入生产环境,问题就会迅速出现。
某个供应商偶尔不可用,需要 fallback;某些任务用 Claude 效果更好,另一些任务用 GPT 成本更低;不同团队都想接入模型能力,但不能共享真实 API Key;老板想知道每个月 AI 花了多少钱;安全团队要求调用记录和权限审计;运维团队需要监控延迟、错误率和限流情况。
这些问题单独看都不复杂,但合在一起,就会把模型调用变成平台工程问题。
Bifrost 主要覆盖四类能力:
-
• 流量管理; -
• 成本与治理; -
• 可观测性; -
• 部署和高可用。
这也是它和简单 SDK 封装的区别。
SDK 解决的是“怎么调用模型”。
AI Gateway 解决的是“如何稳定、可控、可观测地管理所有模型流量”。
为什么不只是 LiteLLM?
提到 AI Gateway,很多人会先想到 LiteLLM。
LiteLLM 的确是一个成熟选择。它支持大量模型提供商,兼容 OpenAI API,也提供代理、fallback、限流、预算、成本统计等能力。对于 Python 项目、原型验证、低到中等流量场景,LiteLLM 仍然很实用。
但如果系统开始进入高并发生产环境,Bifrost 的优势会更明显。
LiteLLM 更像是一个生态覆盖很广的统一模型访问层。
Bifrost 更像是一个面向生产流量设计的高性能 AI 网关。
这个差异非常关键。
当 AI 请求量不大时,网关性能不是最优先问题。但当请求量上来以后,AI Gateway 自身不能成为瓶颈。模型推理已经足够慢,如果网关再带来明显的排队、内存压力或尾延迟,用户体验和系统稳定性都会受到影响。
Bifrost 使用 Go 构建,天然适合高并发代理类服务。它的目标是让网关层尽可能轻,把额外延迟压到很低。
在 500 RPS 的对比测试中,Bifrost 相比 LiteLLM 展现出明显性能优势:
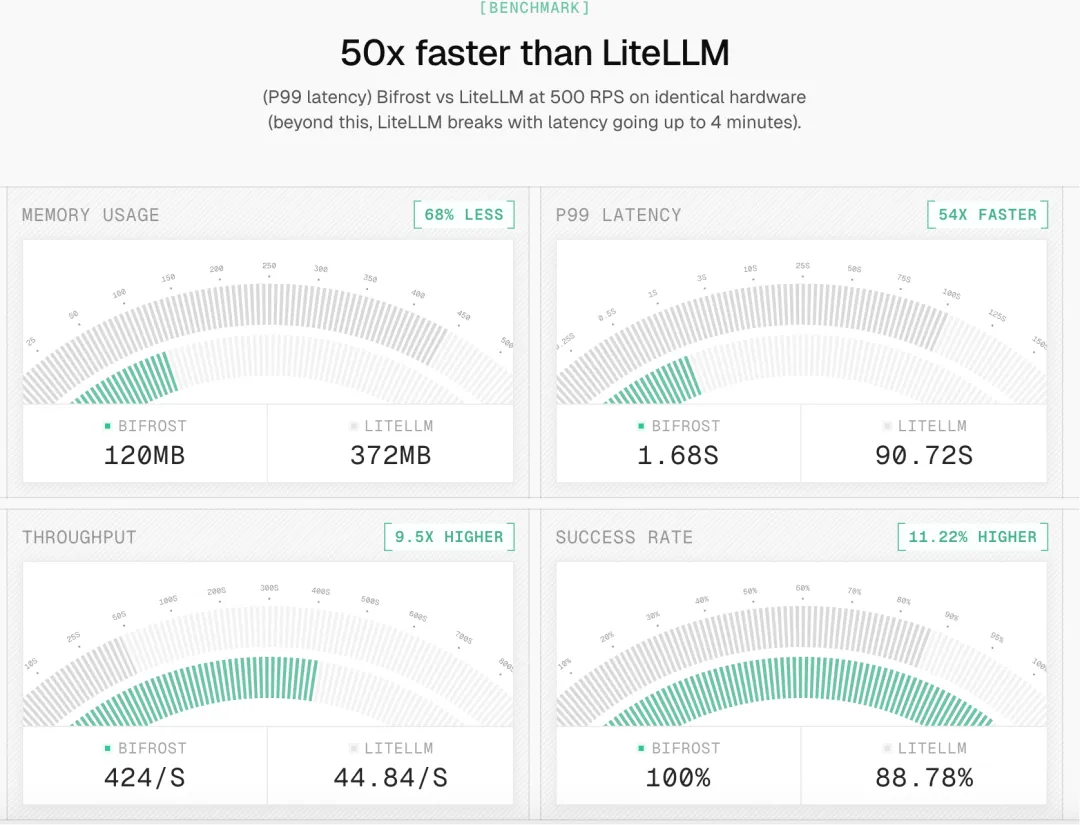
这些 benchmark 不应该被理解成“任何环境都一定得到同样结果”。不同机器、配置、网络、模型响应时间都会影响最终表现。
但它说明了一件重要的事:Bifrost 明确把低延迟、高吞吐和低内存占用作为核心设计目标。
对于生产系统来说,这一点比“又多支持几个 provider”更关键。
Bifrost 的核心能力
统一 OpenAI-compatible API
Bifrost 提供兼容 OpenAI 的接口。
这意味着现有应用通常不需要大改。只要把 SDK 的 base_url 指向 Bifrost,就可以让请求先进入网关,再由网关决定转发到哪个模型提供商。
应用层继续使用熟悉的 OpenAI 调用方式,底层 provider 可以随时调整。
这对生产系统很重要。
因为模型供应商组合不是一成不变的。今天主力模型可能是 GPT,明天某些任务可能切到 Claude,下个月可能接入 Gemini、本地 vLLM 或 Azure OpenAI。
如果没有网关,每次 provider 变化都要改业务代码。
有了 Bifrost,这些变化可以尽量收敛在网关层。
自动 fallback
生产环境里,模型调用失败很常见。
可能是 provider 超时、限流、5xx、区域故障,也可能是某个 API Key 达到 TPM/RPM 限制。
Bifrost 可以在主模型失败时自动切换到备用模型。
比如:
-
• 主模型: openai/gpt-4o -
• 备用模型: anthropic/claude-sonnet -
• 再备用: google/gemini-flash -
• 成本兜底: openai/gpt-4o-mini
业务服务不需要知道底层发生了什么,只需要继续调用统一 endpoint。
这会显著降低业务代码复杂度。
负载均衡
当一个模型有多个 API Key、多个 deployment 或多个 provider 实例时,Bifrost 可以做加权负载均衡。
这适合几类场景:
-
• 多个 Azure OpenAI deployment 分摊请求; -
• 多个 API Key 防止单 key 过载; -
• 不同 provider 按权重分配流量; -
• 按延迟、健康状态或策略调整路由。
对于高并发 AI 服务来说,负载均衡不是锦上添花,而是稳定性的基础。
语义缓存
很多 AI 请求是相似的。
如果每次都完整调用模型,成本和延迟都会增加。Bifrost 支持语义缓存,可以对相似问题复用已有响应,从而降低 token 成本和响应时间。
这对客服、知识库问答、企业内部助手、FAQ 场景尤其有价值。
虚拟密钥和预算控制
Bifrost 支持 virtual keys。
这意味着你不需要把真实 provider API Key 分发给每个业务服务,而是由 Bifrost 生成和管理虚拟密钥。
不同 virtual key 可以绑定不同权限:
-
• 可访问哪些模型; -
• 每分钟最多多少请求; -
• 每月预算多少; -
• 属于哪个团队或项目; -
• 是否允许访问特定工具; -
• 是否走特定路由策略。
这对企业尤其重要。
因为真正的问题通常不是“怎么调模型”,而是“谁能调、能调多少、花了多少钱、出问题能不能追踪”。
MCP 能力:Bifrost 不只是模型网关
AI 应用正在从简单聊天走向 Agent。
这意味着模型不只是回答问题,还会调用工具、访问数据库、执行 API、读取文件、操作业务系统。
这时候,治理对象不再只有模型,还有工具。
Bifrost 支持 MCP Gateway 能力。它既可以作为 MCP client 连接外部工具服务器,也可以作为 MCP server 对外暴露工具能力。
这让它可以承担 Agent 系统中的工具控制面。
它能解决的问题包括:
-
• 哪些工具可以被模型调用; -
• 哪些用户或应用可以访问哪些工具; -
• 工具调用是否需要审批; -
• 工具执行过程如何记录; -
• OAuth 如何处理; -
• Agent 模式下哪些操作可以自动执行; -
• 不同 virtual key 是否能看到不同工具集合。
这类能力在企业 Agent 场景中非常关键。
因为工具调用比模型调用风险更高。
模型回答错了,通常只是内容质量问题。工具调用错了,可能会影响数据库、业务流程、权限系统甚至真实交易。
所以,未来的 AI Gateway 不应该只管理模型请求,还要管理工具访问。
Bifrost 在 MCP 方向的能力,让它更接近下一代 Agent 基础设施。
什么时候需要 Bifrost?
Bifrost 特别适合已经明确需要多 provider、多模型和统一控制面的团队。
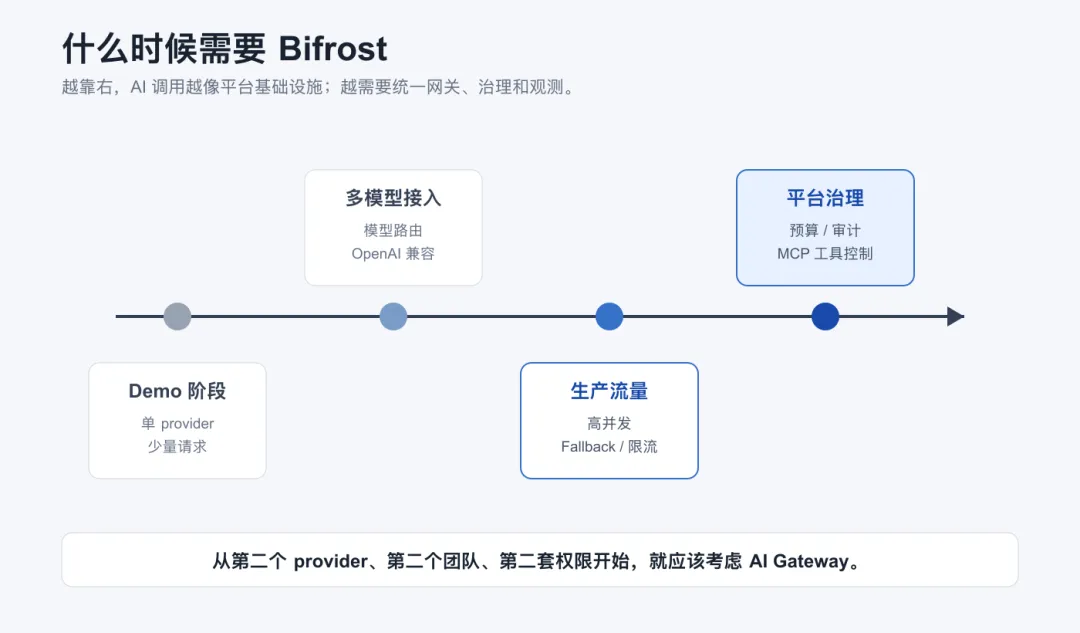
典型场景包括:
-
• 企业内部 AI 平台; -
• 多团队共享模型能力; -
• 面向用户的 AI SaaS; -
• AI 客服、销售助手、代码助手; -
• 高频 RAG 应用; -
• Agent 平台; -
• 需要 fallback 的生产系统; -
• 需要成本预算和访问控制的组织; -
• 需要 Prometheus、OpenTelemetry、审计日志的环境; -
• 需要 MCP 工具治理的企业应用; -
• 需要私有化部署或 VPC 内部署的生产环境。
如果只是一个小 Demo,每天几十次请求,只接一个模型供应商,那么直接调用模型 API 就够了。
但如果 AI 调用已经进入核心业务链路,Bifrost 就值得提前引入。
如何在项目中使用 Bifrost?
落地 Bifrost 不需要一开始就做得很重。更合理的方式是先让模型流量进入统一入口,再逐步打开治理能力。

本地启动非常简单。
使用 npx:
npx -y @maximhq/bifrost默认会在本地 8080 端口启动 HTTP Gateway。
然后打开:
http://localhost:8080Web UI 可以用来配置 provider、查看请求日志、管理 virtual keys、观察指标和分析数据。
也可以使用 Docker:
docker run -p 8080:8080 maximhq/bifrost启动后,可以直接调用 OpenAI-compatible endpoint:
curl -X POST http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "openai/gpt-4o-mini", "messages": [ { "role": "user", "content": "Hello, Bifrost!" } ] }'如果你的项目已经使用 OpenAI SDK,迁移通常只需要改 base_url。
Python 示例:
from openai import OpenAIclient = OpenAI( api_key="your-bifrost-virtual-key", base_url="http://localhost:8080/v1")response = client.chat.completions.create( model="openai/gpt-4o-mini", messages=[ {"role": "user", "content": "Hello, Bifrost!"} ])print(response.choices[0].message.content)Node.js 示例:
import OpenAI from "openai";const client = new OpenAI({ apiKey: process.env.BIFROST_API_KEY, baseURL: "http://localhost:8080/v1",});const response = await client.chat.completions.create({ model: "openai/gpt-4o-mini", messages: [ { role: "user", content: "Hello, Bifrost!" } ],});console.log(response.choices[0].message.content);这就是 Bifrost 的一个重要优势:应用层代码变化很小,但模型流量已经进入统一治理入口。
什么时候继续用 LiteLLM?
LiteLLM 仍然有明确价值。
如果你的目标是快速接入很多模型,团队是 Python 技术栈,流量不高,对极致网关性能不敏感,那么 LiteLLM 依然是一个很方便的选择。
它适合:
-
• 原型验证; -
• 低到中等流量项目; -
• Python-first 团队; -
• 快速统一大量 provider; -
• 对高并发尾延迟不敏感的场景。
但如果系统进入生产规模,需要更强的稳定性、低延迟、统一治理、MCP 工具控制和高并发能力,Bifrost 会更值得评估。
可以这样理解:
LiteLLM 更适合快速统一模型访问。
Bifrost 更适合构建生产级 AI 网关基础设施。
最后
Bifrost 不只是一个模型代理。
它更像是 AI 应用和模型生态之间的基础设施层。
它把模型访问、路由、fallback、负载均衡、缓存、虚拟密钥、成本控制、可观测性、审计和治理集中到一个统一网关中。
对开发者来说,这意味着业务代码里少写 provider-specific 逻辑。
对团队来说,这意味着模型访问更可控,成本更透明,系统更容易监控。
对企业来说,这意味着 AI 能力可以从分散在各个项目里的 API 调用,逐步演进成一个统一的平台能力。
LiteLLM 解决了“怎么方便地调用很多模型”。
Bifrost 进一步解决了“怎么在生产环境中稳定、高性能、可治理地管理 AI 流量”。
当 AI 应用还在原型阶段,简单直接最重要。
当 AI 应用进入生产阶段,网关能力就会成为系统长期稳定性的关键。Bifrost 正是为这个阶段准备的。