 夜雨聆风
夜雨聆风





科技前沿 | AI会取代真人医生吗?


2026年4月30日,一篇发表于《Science》的论文,将人工智能与临床医生的诊断能力首次置于同一把标尺下,结果令整个医学界为之震动。
由哈佛大学医学院、贝斯以色列女执事医疗中心(Beth Israel Deaconess Medical Center)和斯坦福大学联合开展的研究显示,OpenAI的o1推理模型在多项临床诊断任务中,不仅追平了人类医生的水平,甚至在关键场景下实现了超越。
这是否意味着标志着 AI 会取代真人医生呢?

AI初诊准确率已经超过医生
在医学中,最危险的往往不是疾病本身,而是对疾病给出快速且准确的判断。
哈佛医学院和贝斯以色列女执事医疗中心的联合研究团队用OpenAI的o1系列推理模型与数百名医生正面对决。研究设置了三个诊断节点:入院分诊、首次接诊、住院。
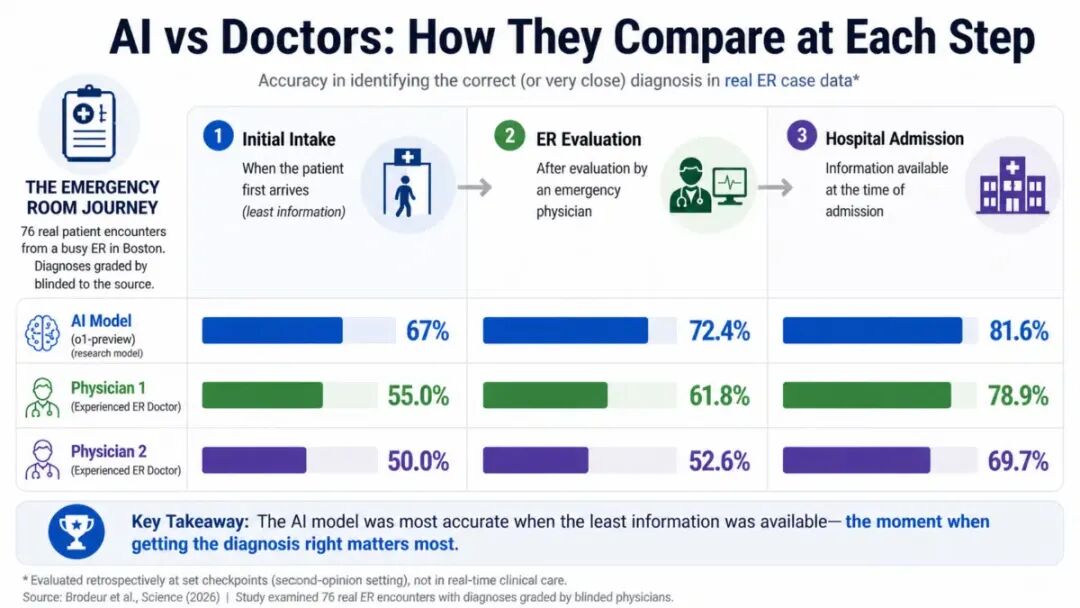
在信息最稀缺的初始分诊阶段,o1模型的优势非常显著。在基于76名真实急诊患者记录的分诊测试中,面对相同的电子病历信息,两位人类主治医师的“准确或非常接近”的诊断率为55.3%和50.0%。而o1模型给出的“准确或非常接近”诊断率,达到了67.1%,超越人类医生12–17 个百分点。
而当测试从诊断进阶到住院决策时,AI在约82%的病例中准确,而两位医生的准确率分别为79%和70%。
NEJM病例库的”终极试炼”
AI为何能赢
该研究的共同作者、哈佛生物医学信息学助理教授 Arjun (Raj) Manrai指出,AI的优势在于它能够消除人类面对时间压力时的认知偏差,并处理庞大的信息碎片。
AI能够更快地处理数据并生成多种诊断假设,帮助打破医生固有的“搜寻满足感”——一种导致我们查到第一个可能病因就停止寻找的认知陷阱。
医学诊断本质上是一种概率推理。研究团队用5个初级医疗场景测试了AI的概率估算能力——这些场景此前曾用于一项涵盖553名医疗从业者(包括住院医师、主治医师、执业护士和医师助理)的全国性调查。结果显示,AI的表现与GPT-4相近,但在不同病例间有所波动。
人类临床医生的表现则呈现出极大的差异性——其概率估计的离散程度远高于任何AI模型 。
因为o1系列模型能进行逐级推理,模仿人类解决复杂问题的结构化思维。与基础模型给出“直接答案”不同,o1学会了“停下来思考”。在生成最终诊断前,它会经历一个内部的“思维链”。
这揭示了一个深层问题:人类医生的诊断质量高度依赖个体经验和认知偏差,而AI提供了一种更稳定、更可复制的推理基准。

从”碳基智慧”到”碳硅共生”
然而,所有研究者都反复强调:这些结果绝不意味着AI可以取代医生。
这项研究仅测试了基于文本的推理。真实的医学涉及倾听患者声音中的疲惫、观察他们走进房间的姿态、进行体格检查、解读影像和实验室数据——这些都无法通过电子病历的文本描述来完全传递 。
研究的病例主要来自内科和急诊医学,外科和其他专科的表现尚属未知。急诊科的”第二意见”任务与真实临床工作流程中的AI部署仍有距离 。
LLM式AI存在一个根本性弱点:”它们的推理在最需要不确定性和细微差别的地方恰恰最为脆弱”——即在多个不确定诊断之间权衡取舍时,AI倾向于”跳跃式结论” 。
2026年初,在一场“AI+医疗”行业论坛上,国家传染病医学中心(上海)主任张文宏直言:“我们医院目前拒绝将AI引入电子病历系统”,因为“会让医生变蠢”。
这一观点与今年1月《英国精神医学杂志》的一篇题文章不谋而合,文章指出,过度依赖AI可能会降低临床推理和决策的质量,对医患沟通产生负面影响,并增加医学领域去技能化风险。随着AI成为医疗行为的常规环节,医生必须认识到这些工具的局限性。
也许这场变革的本质,不是机器取代人类,而是认知能力的重新分配。AI在模式识别、信息整合和概率推理上的优势,与人类在共情、判断和伦理决策上的不可替代性,正在形成一种新的协作范式。
参考文献:


欢迎在抖音、视频号、bilibili、知乎和小红书关注
“世界顶尖科学家峰会”
当科学力量以前所未有的速度重塑人类命运,世界顶尖科学家协会(World Laureates Association, WLA)——人类历史上首个由当代顶尖科学家共同治理的科学文明组织——正致力于推动这一重塑进程,并始终由科学的求实精神所引领。世界顶尖科学家峰会(World Laureates Summit, WLS)正是这一理念最具代表性的实践,也是其被定义为科学文明制宪会议的重要理由。WLS也是迄今为止最接近弥合科学与决策之间结构性鸿沟的制度性探索。