 夜雨聆风
夜雨聆风





用 OpenCode 写技术文档:从一堆资料到一篇能发的文稿
用 OpenCode 写技术文档:从一堆资料到一篇能发的文稿
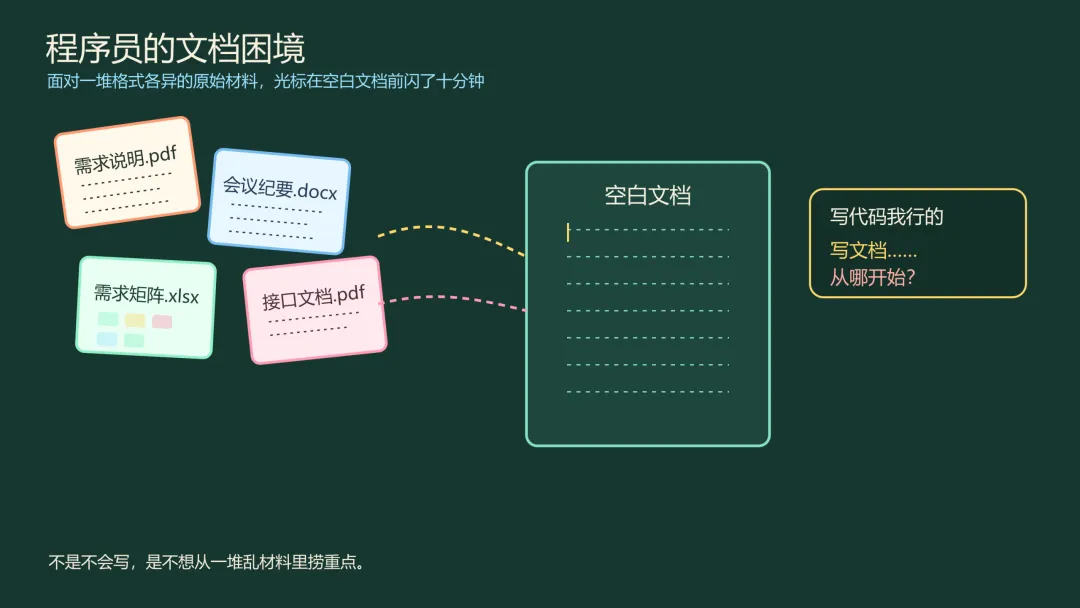
每个程序员都经历过那个时刻:屏幕上一个空白文档,光标闪了十分钟。不是不知道要写什么,是信息太多太乱,不知道从哪开始。
你接了一个新项目。前团队留下一堆材料——三份需求说明、一个技术讨论的会议纪要、一张需求矩阵 Excel、几个相关系统的接口文档。老板说下周之前出一份技术方案。
写代码你是不怕的。拆需求、搭结构、填逻辑,那是日常动作。但写文档不一样。你要先读一遍所有材料,记住关键信息,理清结构,再转化成文字。读材料的时候被邮件打断,回来忘了看到哪。写到一半发现有一个关键约束藏在某个附件里没读。结构快搭好了,翻到会议纪要最后一页才发现决策已经改了。
所以多数人的做法是拖。拖到不能再拖了,一个晚上赶出来。

文档任务真正难的地方
我用 OpenCode 写文档快半年了。踩了一些坑之后,一个感受越来越清晰:文档任务和代码任务,对模型来说是完全不同的挑战。
写代码的时候,上下文很明确。当前文件改哪一行,依赖哪个接口,项目结构什么样子,边界清晰。模型不容易跑偏。
写文档完全是另一回事。一份技术方案的信息可能散落在五个不同格式的文件里。PDF 里有需求描述,Word 里有技术讨论,Excel 里有指标定义,IM 记录里还有一堆决策说明。你把它们全塞给模型,它的注意力很快就散了。不是模型不行,是输入太杂。它不知道该优先关注哪份材料,更不知道每份材料里哪些是核心、哪些是边角料。
文档任务真正的瓶颈不是”写不出来”,是”读不明白”。
但这恰恰是我发现在 OpenCode 上最能做出效率差异的地方。模型处理多份异构信息的组织能力和耐心,其实好过大多数人——前提是你给它一个结构化的流程,而不是一句”帮我写个方案”。
从翻车到总结出一套流程
一开始我也试过最直接的办法:把所有文件拖进会话,说一句”帮我整理一份技术方案文档”。结果嘛,写出来的东西看着挺完整,章节都有,字数不少。但仔细一读,全是用得上的信息只有六成。剩下的两成是合理推测但没标注,两成是它自己编的。
有一次最离谱:它写了一份方案,架构设计部分写得很漂亮,但关键需求漏了——那份需求写在系统 A 的文档里,而我拷进会话的是系统 B 的文档。模型根本不知道还有另一份材料。
从那以后我老实了。把过程拆成步骤,每个步骤有明确的输入输出,人在关键节点做判断。试了几轮之后形成了下面这套流程,还封装成了一个 skill。

八个阶段,三个重点
完整流程有八个阶段。材料盘点、选模板、信息提取与交叉比对、带信心指数的提纲、画草图再画图、逐章写作、完整性检查、输出。不打算全展开,说几个我最觉得有用的。
材料盘点比你想的重要。
把它列出来。让模型扫描目录,列出每个文件是什么格式、什么时间、大概包含什么内容,然后问你还缺不缺材料。这一步花不了两分钟,但能避免”写到一半发现还有一份关键文档没喂”的悲剧。我翻了三次车之后才养成这个习惯。
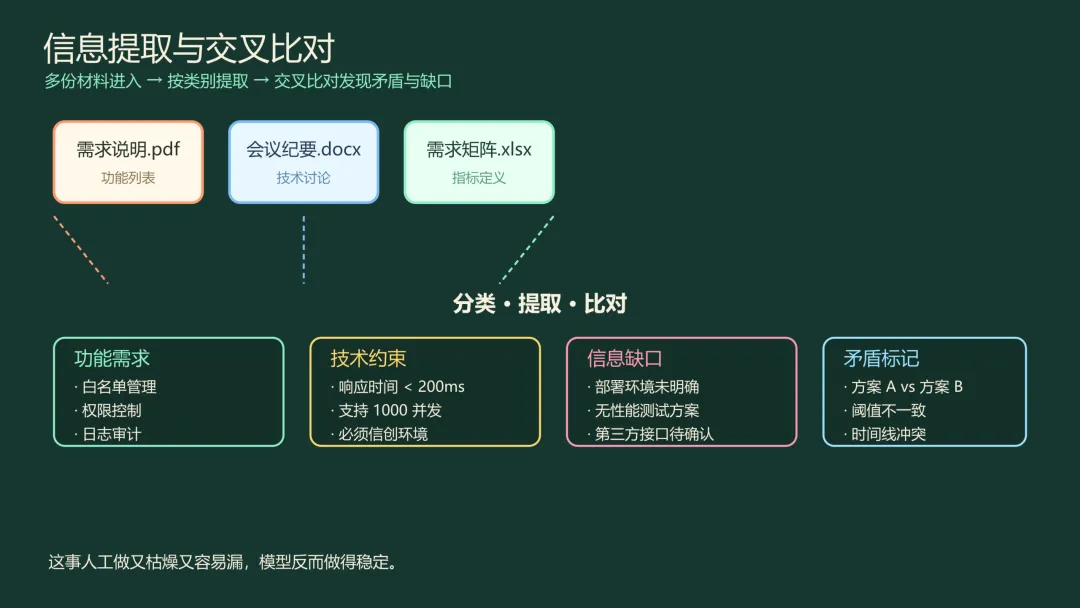
信息提取必须显式做。
让模型读完材料直接开写,这是最容易犯的错误。应该先做一件事:把读到的内容分类——哪些是需求、哪些是技术约束、哪些是风险、哪些是接口定义。然后拉一张对比表,看看不同文件之间有没有矛盾。
会议纪要里说用方案 A,需求矩阵里写的是方案 B。这种情况很常见。不提前发现,写到后面要改就麻烦。
带信心指数的提纲。
这是我最喜欢的环节。大纲不只是章节标题,每章每节都要标注信息来源和信心等级:
## 3. 功能需求 ### 3.1 配置管理 [来源: 需求文档 v2.3 L34] ✅ 充分### 3.2 权限控制 [来源: 需求文档 v2.3 L40] ✅ 充分### 3.3 性能指标 [来源: 会议纪要 6.15] ⚠️ 缺具体阈值### 3.4 部署方案 [来源: 无] ❌ 信息不足大纲交给你的那一刻,你一眼就能看清:哪些可以放心写,哪些需要你去补信息,哪些有风险。不用等到全文写完再改。


画图之前先画草图
还有一个原则我觉得价值很大:画图之前先画草图。不是用 drawio 或者 Mermaid 直接画,而是让模型先用 ASCII 字符画一个草图出来。
┌──────────────────────────┐│ 管理平台 ││ ┌──────────┬──────────┐ ││ │ 策略模块 │ 日志模块 │ ││ └──────────┴──────────┘ │└─────────────┬─────────────┘ │ 策略下发 ┌─────────┼─────────┐ ▼ ▼ ▼ 节点A 节点B 节点C等你确认草图没问题了,再生成正式图。你可能会觉得多此一举,实际用下来草图改起来几乎零成本,正式图画错了再改,时间是草图的十倍不止。
能力和边界
用了这么久,对模型在文档任务上的能力边界也有数了。
模型擅长的事:
-
从多份异构材料里提取信息,拉对比表。这事人工做又枯燥又容易漏,模型反而做得稳定。 -
按模板填充文档框架。结构定了以后,填充速度和质量都不错。 -
做需求追溯。让模型检查每条需求在文档里有没有对应章节,比人眼扫读快。 -
画 ASCII 草图。虽然丑,但用来确认布局够用了。
模型不擅长的事:
-
信息不足的时候老实说不知道,而不是合理推测。需要你在 prompt 里反复强调。 -
判断多份材料的优先级。哪份是最新版本,哪份已经废弃,模型判断不准。 -
保持术语一致性。中英文混用的文档里,同一术语前后可能不同。
建议不要放手的事:
-
文档结构和章节划分的决策。模型搭的结构大概率可用,但不一定最适合你的场景。 -
任何涉及业务判断、团队习惯、历史背景的决策。这些模型没有。 -
最终审稿。”看起来合理”和”确实正确”之间差距很大。

顺手、够用、划算
回到系列的判断标准。
顺手: 有了这套流程以后,我不再怵”出一份文档”的任务了。打开 OpenCode 跑一遍 skill 流程,每个阶段只做判断,不做信息整理。以前最烦的”读材料做笔记”环节几乎消失了。
够用: 八阶段覆盖了从原始材料到交付文档的完整链路。唯一需要自己做的只有审稿和定稿——不过这些本来就不该交给模型。
划算: 一份中等复杂度的技术方案,以前读两天材料、搭一天结构、写两天正文、改一天,五个工作日是起步价。现在配合这套流程,两天内能出初稿,而且追溯矩阵保证了覆盖度,质量不比以前低。
如果你工作中经常要写技术文档,建议搞一套自己的流程。不用照搬八个阶段,可以按文档类型和团队要求裁剪。但下面几个原则我觉得值得保留:
-
先盘材料再动笔。 不是浪费时间,是避免翻车。 -
模板优先于自由创作。 有模板用模板,没模板定结构,确认了再动笔。 -
信息提取要显式做。 别指望模型自动完成。 -
缺口提前暴露。 不要写到一半才发现缺信息。 -
追溯矩阵保底。 写完逐条确认每项需求都被覆盖。 -
审稿不放。 人永远是文档质量的第一责任人。
最后说一句:这套流程的 skill 文件我放在了 https://github.com/andy1219111/writing-tech-docs 里。但最有价值的其实不是那个skill,而是设计这套流程的思路——把写作经验拆成可复用的阶段、每个阶段的输入输出、明确的判断节点。这个结构本身,比任何提示词都值钱。